Technical report of KAG, the first professional domain knowledge enhancement service framework in China, which helps big models land in vertical domains.

Recently, Liang Lei, the head of knowledge engine of Ant Group, shared the team's work progress in the past six months in the research of fusion of knowledge graph and large-scale language model at the Bund Conference, and released KAG, the first knowledge enhancement service framework for professional domains in China, which helps build professional intelligences with knowledge enhancement functions. This article is the textual organization of the report content.
Related Technical Reports arXiv Address:https://arxiv.org/pdf/2409.13731
This time we have announced the KAG of the overall technical report. We hope to truly merge the advantages of symbolic computation and vector retrieval of knowledge graphs, as they are complementary in many ways. At the same time, we will utilize the understanding and generating capabilities of large language models to build a knowledge-enhanced large language model generating system.The KAG technical framework will continue to be iterated and the technical report will be continuously updated.
We're about to be in OpenSPG The KAG framework is published in the open source project, GitHub address:
https://github.com/OpenSPG/KAG
Key Issues in the Application of Large Modeling Verticals
After nearly two years of research and practice, the industry has generally recognized the advantages and limitations of Big Language Models, as well as their challenges in industry-specific applications. Although Big Language Models have demonstrated strong comprehension and generation capabilities, there are still problems such as lack of domain knowledge, difficulty in making complex decisions, and lack of reliability in professional domains. We believe that "trustworthiness" is a key prerequisite for the implementation of big language models in real-world scenarios.

1.1 LLM does not have the ability to think critically
First, large language models do not provide rigorous reasoning capabilities. For example, we used the question "Who is the common star of "1989 A Thought" and "Excellent Match"?" This question, we tested several large language models in China separately, and the results show that the accuracy and consistency of the responses are low. Even if some models can give an answer, there are logic errors or improper problem disassembly. As the conditions become more complex, such as changing the conditions to "male lead actor" and "female lead actor" or adding time constraints, the accuracy and stability will continue to decline.

In order to solve these problems, many explorations have been carried out in the industry. For example, by constructing the Chain-of-Thought (COT) model and defining the Multiple/Tree/Graph chain-of-thinking template, LLM is guided to rationally disassemble the problem. This year, more and more research has been focused on integrating the RAG techniques into the big language model to compensate for its lack of factual information. Further developments involve GraphRAG, which employs graph structures to optimize retrieval mechanisms.
The introduction of external knowledge bases is widely used today, but even when techniques such as RAG are introduced to make domain-specific knowledge bases or fact files available for re-generation in large language models, the accuracy of the generated answers is still not fully guaranteed.
1.2 Errors of fact, logic, and precision
The left side of the figure below shows an example of using a big model to interpret a certain indicator of a government report. Although the business staff has marked it in advance, the big model will still add its own understanding, resulting in distorted information or lack of basis for the error. For example, it is mentioned that a certain city ranks first in a certain province, but this is incorrect when judged from a business perspective. Similarly, information about an $80 million stake in a bank that went to auction does not exist in the original document. Worse, the model also produces numerical and logical errors, where the original document provides business metrics for 2022, but the generated content is labeled as 2023.

Inaccuracies in the recall process remain a problem even when an external knowledge base is provided. The example on the right illustrates the shortcomings of the RAG approach based on vector computation. For example, when querying how to find a pension, the direct use of vectors to compute the recalled documents does not correlate with the knowledge defined by the business experts.
In vertical domains, many knowledge is closely related to each other even though they seem to be dissimilar on the surface. For example, "pension" belongs to the category of "five insurance and one pension", which is closely related to the national policy, and the large model cannot generate such information arbitrarily. Therefore, a predefined domain knowledge structure is needed to constrain the model's behavior and provide effective knowledge input.
1.3 Generic RAGs also struggle to solve LLM illusions
As shown in the figure below, the original text mentions that the vitamins and minerals in functional drinks are beneficial to replenish the body and eliminate fatigue after exercise, but after the model is rewritten, it may be incorrectly described as "having a certain effect on increasing fatigue", which is misleading information that may cause distress to users.

In addition, there are problems with entity reversals, such as rewriting the original sentence from "15-18 days after becoming a pupa" to "25-32 days after becoming a pupa". These types of detail errors become more difficult to detect when the model generates hundreds or even thousands of words of content.
According to the evaluation results, even with the incorporation of the RAG technique, the large language model still suffers from a phantom rate of 30%-40%, which is a rather high percentage. Therefore, when applying large-scale language models in vertical domains, it is important to meet extremely high professionalism requirements.
1.4 Challenges and requirements for specialized knowledge services
In real business decision-making scenarios, whether it is generating a research report or handling an auto insurance claim, solving complex problems requires a rigorous step-by-step process that includes problem planning, data collection, executing the decision, and generating and giving feedback. There must also be a rigorous and controlled decision-making process when applying Big Language Models to specialized domains.

When providing expertise services based on a large model, the following conditions must be met in order to better serve the community and a specific domain:
- First, it is important to ensure the accuracy of knowledge, including the integrity of knowledge boundaries and the clarity of knowledge structure and semantics;
- Secondly, logical rigor, time sensitivity and numerical sensitivity are required;
- Finally, complete contextual information is needed to facilitate access to complete supporting information when making knowledge-based decisions;
The above are also the capabilities that most current large models lack. In view of this, in the first half of this year, we have conducted a lot of exploration and formally started to build a controlled generation framework based on knowledge enhancement and oriented to vertical domains.
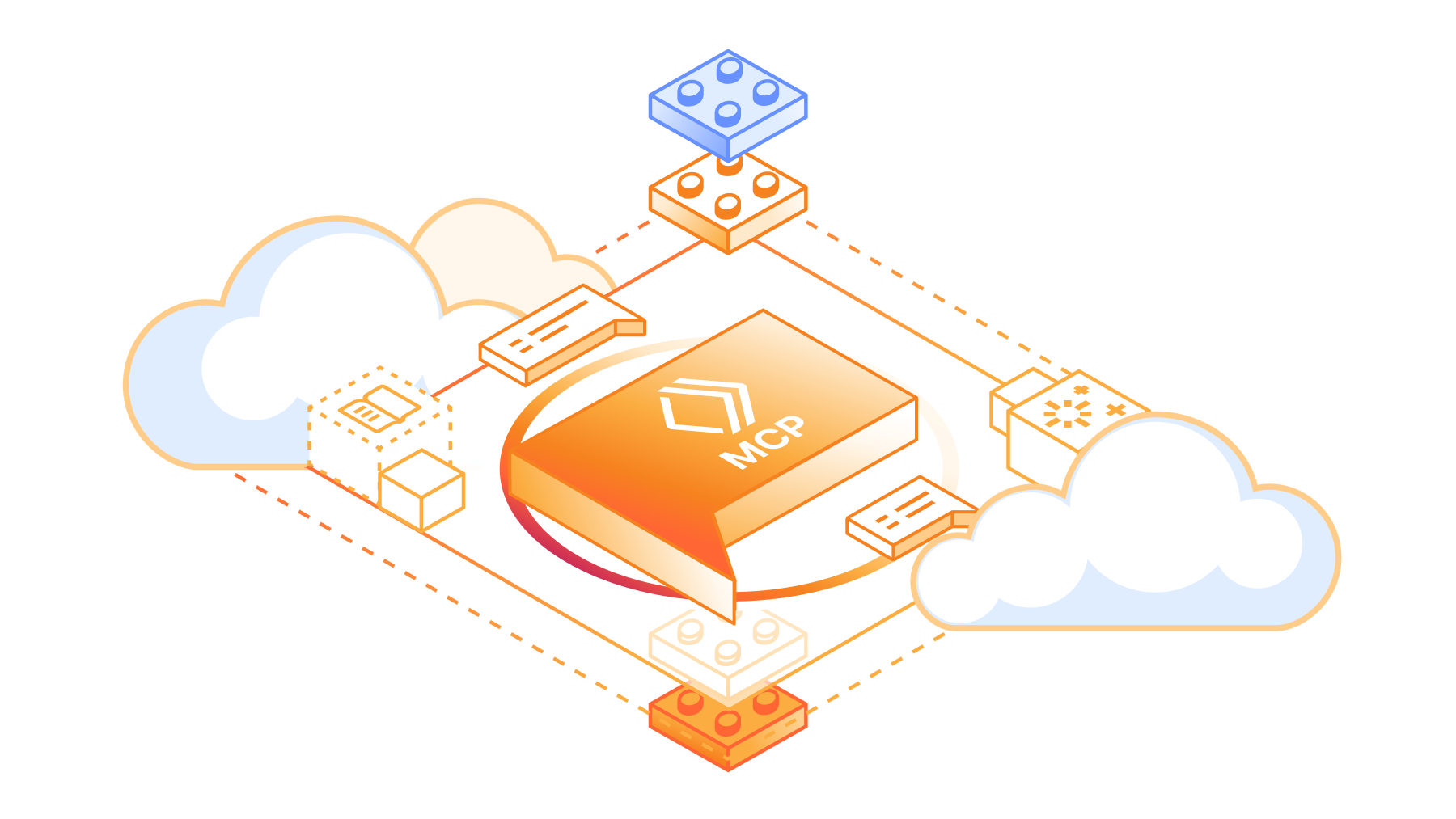
KAG: Knowledge Augmentation Service Framework for Areas of Specialization
The following figure illustrates the principle of our overall Knowledge-Enhanced Generation (KAG) framework, which is based on the OpenSPG Upgrades based on open source projects. We have made enhancements to address five current aspects of combining large language models with knowledge graphs:

First, we realize the enhancement of knowledge representation. The original knowledge graph is constrained by a strong Schema, which leads to a high application threshold and sparse data, making it often unsolvable when answering questions in vertical domains. For this reason, we optimized and upgraded the knowledge representation for large language models, so that the knowledge graph can better support the application of large language models.
Second, graphs serve as an excellent integration tool to better connect all types of knowledge, whether it is rigorous academic knowledge or information in a text. Thus.We created a mutual index structure, upgrading the term-based inverted index to a graph-based inverted index.This not only indexes documents efficiently, but also maintains semantic associations between documents and coherence between entities.
Third, during the reasoning process, we employ symbolic disassembly to ensure logical rigor. It is difficult to ensure logical consistency in language model-generated languages, so we introduce LogicForm-driven Solver and Reasoning for symbol-based disambiguation.
Fourth, in order to bridge the gap between the cost of knowledge graph construction and the efficiency of practical application, we draw on the open information extraction method to construct knowledge graphs, which greatly reduces the construction cost, but also introduces more noise. Therefore, we introduce the knowledge alignment mechanism, which utilizes conceptual knowledge to complete the alignment between open information and domain knowledge, aiming to balance the needs of open information extraction and semantic alignment.
Finally, we developed the KAG model with the aim of better integrating the capabilities of large-scale language models and knowledge graphs to achieve more effective synergy. The organic interaction between the two is facilitated through instruction synthesis, with the ultimate goal of fully integrating the advantages of symbolic computation and vector retrieval, and giving full play to the comprehension and generative capabilities of the language model, thus promoting its application and capability enhancement in vertical domains.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...