


The GTR framework: a new approach to cross-table Q&A based on heterogeneous graphs and hierarchical retrieval

1. Introduction
In today's information explosion, a large amount of knowledge is stored in the form of tables in web pages, Wikipedia, and relational databases. However, traditional Q&A systems often struggle to handle complex queries across multiple tables, which has become a major challenge in the field of artificial intelligence. To cope with this challenge, researchers have proposed GTR (Graph-Table-RAG) Framework. The framework enables more efficient cross-table Q&A by organizing tabular data into heterogeneous graphs and incorporating innovative retrieval and inference techniques. In this paper, we disassemble the core approach of the GTR framework in detail and show its key hints design.
2. MUTLITABLEQA: the first cross-table Q&A benchmark dataset
To evaluate the effectiveness of the cross-tabular question-and-answer model, the researchers constructed the MUTLITABLEQA, which is the first cross-table Q&A benchmark dataset built from real-world forms and user queries. Here are the key steps in the construction of the dataset:
2.1 Data set construction methods
- Table source: Collect raw single-table data from real-world, human-labeled datasets such as HybridQA, SQA, Tabfact, and WikiTables, and filter out oversimplified tables, resulting in 20,000 tables.
- Table Breakdown: Row/column splitting of collected tables into 60,000 sub-tables as multi-table data. Specific methods include:
- line split: Divide the table entries into multiple disjoint subsets along the row dimension, each preserving the same table schema and metadata as the original table.
- column splitting: Keep the first column (usually the primary key or major attribute) and divide the remaining entries into multiple disjoint subsets along the column dimension.

Figure 1: MUTLITABLEQA dataset construction flowchart showing the direct construction of a multi-table dataset and the MUTLITABLEQA construction process. - Search Combination: To enhance the complexity of query retrieval, the researchers combine existing simple queries to generate complex queries that require multi-step reasoning. Specific steps include:
- Query de-duplication and filtering: Filter out ambiguous and contextually repetitive queries using common linguistic and context-aware heuristics (e.g., deactivation word ratio analysis, minimum query length thresholding, and similarity-based redundancy detection).
- Query Merge: For complex or sequential queries from the same single table, combine them into a single extended query using concatenation terms (e.g., "AND", "furthermore", "Based on [previous query]"). ") to combine them into a single extended query.
- Query decontextualization: In order to improve clarity and self-containment, a decontextualization approach is used, replacing vague indicative pronouns and discourse markers with explicit references.
- Task type definition::
- Table-based Fact Verification (TFV): Determine whether a statement provided by a user is supported by tabular data.
- Single-hop TQA: The answer to the question needs to be obtained from only one table cell, but reasoning across multiple tables is required to find the correct cell.
- Multi-hop TQA: The answers to questions require complex reasoning from multiple cells in multiple tables.
Figure 2: Examples of the three different task types in the MUTLITABLEQA dataset.
3. The GTR framework: an innovative approach to cross-table Q&A
The GTR framework is designed to address the core challenges in cross-table Q&A in the following ways:
3.1 Table-to-figure construction
The core idea of GTR is to transform tabular data into heterogeneous hypergraphs to better capture relational and semantic information between tables.
- Table Linearization: Convert tables into linear sequences, preserving their structural information and semantic content. For example, join the headings and column headings of a table into a sequence and use special markers to identify the structural position of the table.
s = [ [Table], ⊕( [Caption], C ), ⊕( [Header], h_k ) ]where ⊕ denotes the sequence concatenation and h_k denotes the kth column heading.
- Multiplexed feature extraction: Compute three eigenvectors for each linearized sequence:
- Semantic features (x^(sem)): Generated using a sequence encoder that captures the semantic content of the form.
- Structural features (x^(struct)): Use spaCy to extract key formatting features such as token counts, lexical tag frequencies, and punctuation counts.
- Heuristic features (x^(heur)): Generated by heuristics, e.g., using TF-IDF vectors to generate bag-of-words representations.
- hypergraphic construction (math.): Construct a heterogeneous hypergraph by clustering tables with similar features through a multiplexed clustering algorithm and defining each cluster as a hyperedge.
Figure 3: Overview of the GTR framework showing the table-to-graph construction process.
3.2 Coarse-grained multiplexed search
- Representative scoring: Define representative scores between nodes for comparing node-to-node and node-to-query similarity.
- Query-Cluster Assignment: After embedding the query, the representative score between it and each node is computed and the most relevant clusters are selected for each feature type.
- Typical Node Selection: A small number of nodes are selected that best represent each cluster, and the final multiplexed optimal clustering is the concatenation of all feature types.
3.3 Fine-grained subgraph retrieval
- Local Subgraph Construction: Based on the coarse-grained retrieval results, a densely connected local subgraph is constructed and the similarity matrix between nodes is computed using semantic features.
- Iterative Personalized PageRank: Calculate the similarity matrix of the candidate nodes and perform row normalization to get the transfer matrix. The personalized PageRank vector is computed by iterative formula, the nodes are ranked and finally the top ranked node is selected as the final retrieved table node.
3.4 Figure Perception Cues
In order to enable downstream LLMs to effectively interpret the retrieved tables and make inferences, GTR employs a graph-aware hinting approach. The following is a detailed design of the hints used in the GTR framework:
3.4.1 Figure information insertion
- Node Indexing and Relational Embedding: Number the retrieved table nodes and embed them in the hints so that LLM can recognize different table sources. Also, similarity relationships between nodes are embedded in the hints in a structured JSON format that describes the semantic similarity or other relationships between different forms.
## Retrieved Tables: <table1>Table 1: ...</table1> <table2>Table 2: ...</table2> ... ## Graph-Related Information: { "source_node": "Table 1", "target_node": "Table 2", "relationship": { "type": "similarity", "score": 0.674 } }
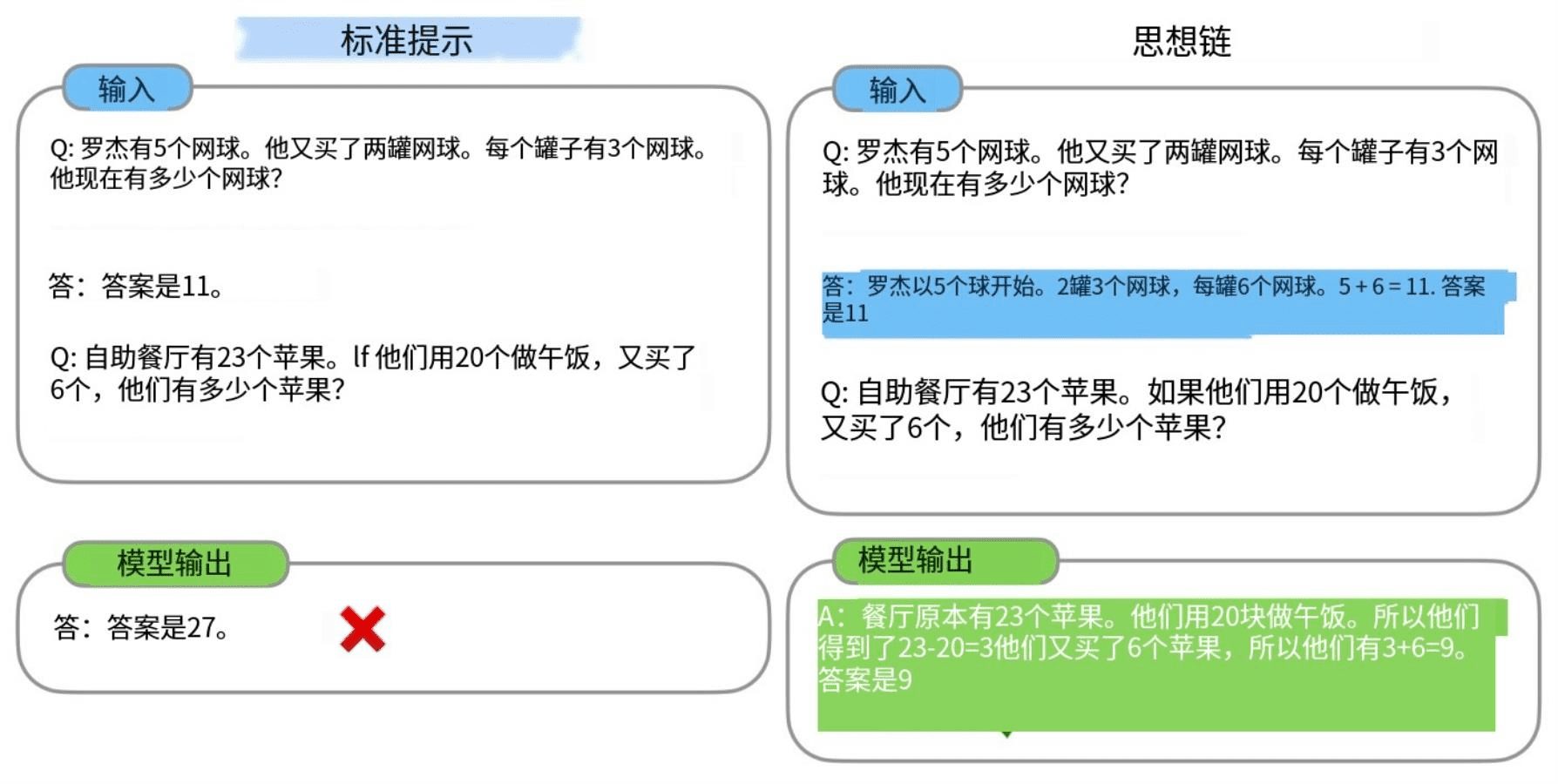
3.4.2 Hierarchical Long-Chain Thinking (CoT) Generation
- Identify relevant forms: Prompts LLM to identify the most relevant form to the query from the set of forms provided.
1. Identify the most relevant tables from the provided table set <V_final^*>. - Clarify the link between queries and tables: Prompts LLM to explain the connection between the query and the selected forms, explaining why the forms are critical to answering the query.
2. Elucidate the connection between the query and the selected tables. - Detailed reasoning process: Hint LLM examines each row and column entry in detail, extracting the most relevant information to the query and reasoning step-by-step to arrive at the final answer.
3. Conduct a detailed examination of each row and column entry to extract the information most pertinent to the query. - Final answer output: Hints LLMs separate the reasoning process and the final answer with a
<reasoning>cap (a poem)</reasoning>,<answer>cap (a poem)</answer>Tab wrapped.# Now Output Your response below: <reasoning> [Detailed reasoning steps] </reasoning> <answer> [Final answer] </answer>
3.4.3 Example output
The following is sample output generated by the GTR framework:
<reasoning>
1. The query asks for the release date of a game called "Mario Kart Advance".
2. From Table 1, we can find that "Mario Kart Advance" is listed under the "Game Title" column.
3. The corresponding entry in the "Release Date" column is "December 16, 2011".
4. Therefore, the release date of "Mario Kart Advance" is December 16, 2011.
</reasoning>
<answer>
December 16, 2011
</answer>
4. Experimental results
Experimental results on the MUTLITABLEQA dataset show that GTR excels in both retrieval and downstream generation and inference. Compared with traditional table retrieval methods, GTR shows significant improvement in both accuracy and recall. For example, in the TFV task, GTR's recall @50 is improved by 9.4%In the multi-hop TQA task, the recall @10 improved by 8.2%The
The following are the main experimental results of GTR with other baseline methods on the MUTLITABLEQA dataset:
| form | methodologies | TFV Accuracy @10 | TFV Accuracy @20 | TFV Accuracy @50 | ... | Multi-hop TQA Recall @50 |
|---|---|---|---|---|---|---|
| table search | DTR | 21.1 | 27.8 | 36.2 | ... | 62.0 |
| Table-Contriever | 23.4 | 30.1 | 40.1 | ... | 68.9 | |
| ... | ... | ... | ... | ... | ... | |
| GTR | GTR | 36.1 | 47.9 | 59.4 | ... | 76.8 |
5. Conclusion
The GTR framework demonstrates its power in handling complex cross-table queries by organizing tabular data into heterogeneous graphs and combining it with innovative multiplexed retrieval and graph-aware hinting methods. This new approach brings new ideas and possibilities to the field of cross-table querying.
6. Future prospects
The researchers plan to further extend the MUTLITABLEQA dataset and explore more advanced graph neural network (GNN) and LLM optimization techniques to further improve the performance of cross-table Q&A models. In addition, they plan to apply the GTR framework to other domains, such as knowledge graph inference and cross-modal Q&A.
Paper address: https://arxiv.org/pdf/2504.01346
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts




No comments...