GLM-4.5 - Smart Spectrum Open Source SOTA Model for Reasoning, Code and Intelligentsia

What is GLM-4.5
GLM-4.5 is an open source SOTA model from Smart Spectrum, designed for intelligent body applications, incorporating reasoning, code generation and intelligent body capabilities. The model is based on the Mixed Expert (MoE) architecture and consists of two versions, GLM-4.5 with 355 billion parameters and GLM-4.5-Air with 106 billion parameters and 32 billion and 12 billion activation parameters, respectively. The model performs well in reasoning, code generation, and other tasks, supports multimodal inputs and outputs, and provides "thinking mode" and "non-thinking mode" to adapt to complex tasks and immediate response needs. The model has high parameter efficiency, low API call cost, fast generation speed, and is suitable for full-stack development, programming assistance, content creation and other scenarios, making it the best open-source model at present.

Main functions of GLM-4.5
- reasoning ability: GLM-4.5 is capable of handling complex reasoning tasks, such as logical reasoning, mathematical problem solving, etc. The reasoning capability is excellent in a number of benchmarks and reaches the top level of open source models.
- code generation: The model generates high-quality code snippets, supports multiple programming languages, and helps developers quickly generate code frameworks, fix code errors, optimize code structure, and so on, to be competent in full-stack development tasks.
- Intelligent Body Applications: Support for tool invocation, web browsing, and other features that support access to code intelligence body frameworks such as Claude Code and Roo Code for intelligent body tasks for complex intelligent body applications.
- Content generation: It can generate various types of content, such as articles, news reports, creative copy, etc. It is suitable for content creation, copywriting and other scenarios, providing users with rich text generation support.
GLM-4.5 official website address
- GitHub repository:: https://github.com/zai-org/GLM-4.5
- HuggingFace Warehouse: https://huggingface.co/collections/zai-org/glm-45-687c621d34bda8c9e4bf503b
- ModelScope Warehouse:: https://modelscope.cn/collections/GLM-45-b8693e2a08984f
- Online Experience Demo::
- HuggingFace: https://huggingface.co/spaces/zai-org/GLM-4.5-Space
- ModelScope:: https://modelscope.cn/studios/ZhipuAI/GLM-4.5-Demo
How to use GLM-4.5
- Online Platform Experience::
- Wisdom Spectrum Clear Speech Platform: Accesslit. record wisdom and say clearlywebsite to experience the full functionality of GLM-4.5 directly, free of charge, including dialog generation, code generation, and reasoning tasks.
- Z.ai platform: By Z.ai Platform to experience the features of GLM-4.5 for quick trial and testing.
- API Calls: Smart Spectrum AI provides an API interface, which users can access through the BigModel. The platform makes API calls. the API supports a variety of functions, including text generation, code generation, and inference tasks.
- Deployment through open source code::
- GitHub Repositories: Visit the GitHub repository for GLM-4.5 to get the model code and related resources to deploy and use on your own.
- HuggingFace Warehouse: Visit the HuggingFace repository for GLM-4.5 to deploy and test with the tools and environment provided by HuggingFace.
- ModelScope Warehouse: Access to the ModelScope repository of GLM-4.5 for model deployment and application development using ModelScope's platform functionality.
- HuggingFace Experience Space: Visit HuggingFace's GLM-4.5 Experience Space for a quick trial of the model's features.
- ModelScope Experience Space: Visit ModelScope's GLM-4.5 Experience Space for online experience and testing.
Technical specifications of GLM-4.5
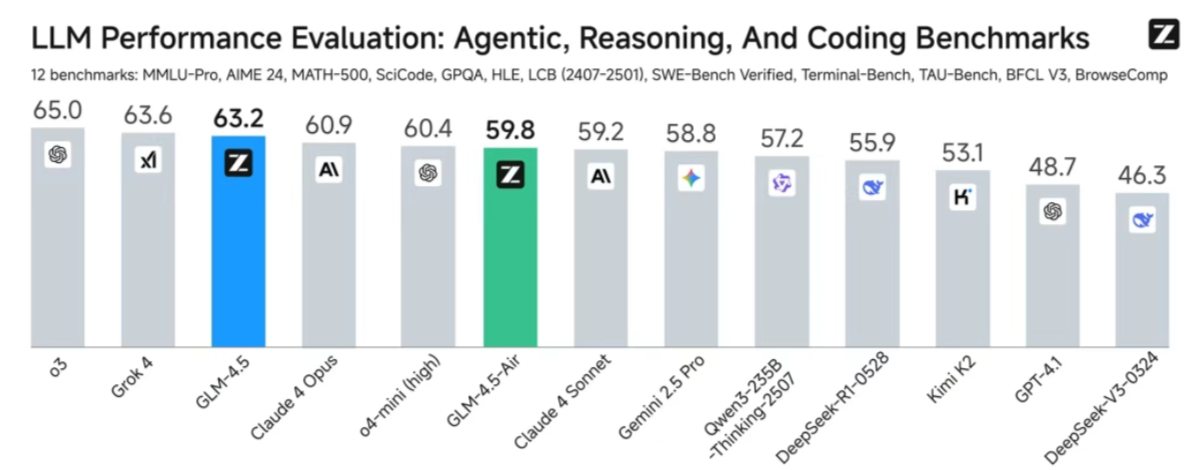
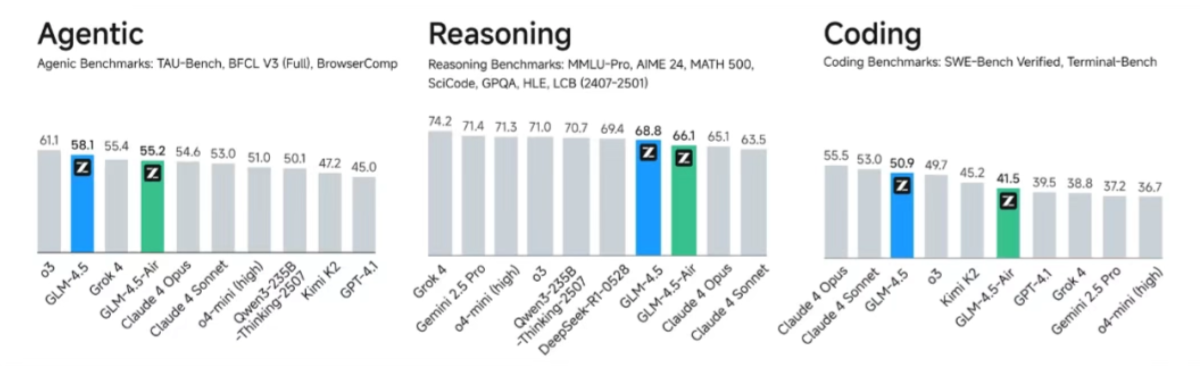
- Overall performance SOTA: Among 12 representative evaluation benchmarks, GLM-4.5 achieved the third place in global models, the first place in domestic models and the first place in open source models. The evaluation benchmarks include MMLU Pro, AIME 24, MATH 500, SciCode, GPQA, HLE, LiveCodeBench, SWE-Bench Verified, Terminal-Bench, TAU-Bench, BFCL v3, and BrowseComp, which fully proves that GLM-4.5 can be used for multiple inference, code generation and intelligent body application. 4.5's excellent performance in multiple scenarios such as inference, code generation and smart body applications.
- Higher parameter efficiency: GLM-4.5 has only 1/2 the number of parameters of DeepSeek-R1 and 1/3 the number of Kimi-K2, and performs much better in many standard benchmarks. On the SWE-bench Verified list, which measures the capability of the model code, the GLM-4.5 series is located at the performance/parameter ratio Pareto frontier, indicating that the GLM-4.5 series achieves the best performance at the same scale.
- Low cost, high speedGLM-4.5 series achieves breakthroughs in cost and efficiency while optimizing performance: the API call price is as low as $0.8/million tokens for input and $2/million tokens for output, which is far lower than mainstream model pricing. The high speed version can generate up to 100tokens/sec, which supports low latency and high concurrency deployment, taking into account the cost-effectiveness and interactive experience.
Core Benefits of GLM-4.5
- Multi-competency integration: GLM-4.5 is the first model that natively fuses reasoning, code generation, and intelligent body capabilities to simultaneously meet the diverse needs of complex reasoning, code development, and intelligent body tasks.
- Excellent inference performance: GLM-4.5's performance in multiple reasoning benchmarks is at the top level of open source models, capable of handling complex reasoning tasks, such as logical reasoning, mathematical problem solving, etc., with very powerful reasoning capabilities.
- Efficient hybrid reasoning model: The model provides two modes of reasoning: "Thinking Mode" and "Non-Thinking Mode". Thinking mode is suitable for complex tasks that require in-depth analysis, while non-thinking mode can respond quickly to meet immediate needs, balancing efficiency and performance.
- High parameter efficiency: GLM-4.5 has a small parameter count, but performs better in many standard benchmarks. For example, GLM-4.5 leads the performance/parameter ratio in the code generation capability test.
- Low cost and high speedGLM-4.5's API calls are very affordable, with input costs as low as $0.8/million tokens and output costs of $2/million tokens, and generation speeds of up to 100 tokens/second, supporting low-latency and high-concurrency deployments.
- multimodal support: GLM-4.5 supports multimodal inputs and outputs, and is capable of handling multiple data types such as text, images, etc., which makes it more comfortable in handling complex intelligent body tasks, for example, it performs well in multimodal interaction scenarios such as web browsing and tool invocation.
People for whom GLM-4.5 is intended
- Developers and programmers: Quickly generate code frameworks, fix bugs, optimize structures, and improve development efficiency with the help of code generation and programming assistance features.
- content creator: Quickly generate first drafts of articles, news, creative copy, etc., providing creative inspiration and helping to break through creative bottlenecks.
- Academic researchers: serve as a research tool to help explore cutting-edge issues in natural language processing and artificial intelligence for model comparison and improvement.
- business user: Used to build intelligent customer service, generate data analysis reports, and develop automation tools to improve the efficiency of business operations.
- Educators and students: Teachers generate instructional materials and students draw on their learning support functions, such as generating notes and explaining concepts.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...