GLM-4.1V-Thinking - A Series of Open Source Visual Language Models from Smart Spectrum AI

What is GLM-4.1V-Thinking?
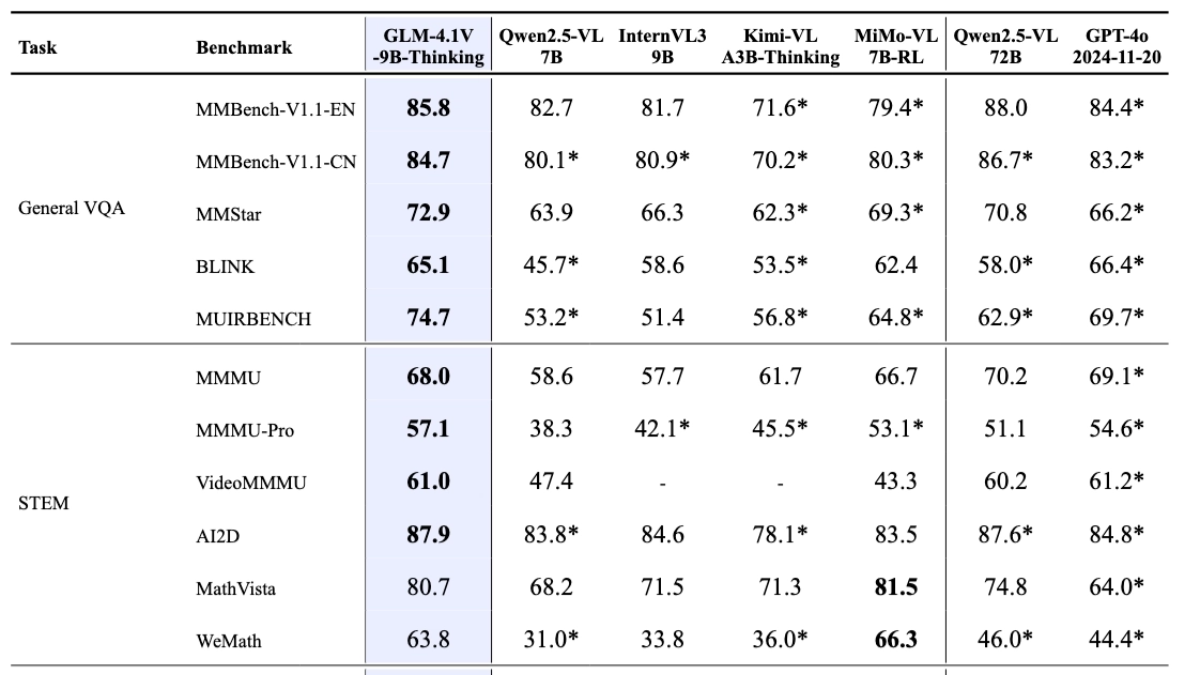
GLM-4.1V-Thinking is an open source visual language model launched by Smart Spectrum AI, designed for complex cognitive tasks, GLM-4.1V-Thinking supports multimodal inputs, covering images, videos and documents. Based on the GLM-4V architecture, the model introduces a chain-of-thinking reasoning mechanism, reinforces learning strategies with course sampling, and significantly enhances cross-modal causal reasoning and stability. The lightweight version of GLM-4.1V-9B-Thinking (GLM-4.1V-9B-Base base model and GLM-4.1V-9B-Thinking with deep thinking and reasoning ability) has 10B parameter counts, and in 28 authoritative reviews, 23 of them have obtained the best scores of the 10B-level model, of which 18 are on par with the 72B parameter counts of Qwen- 2.5-VL, fully demonstrating the excellent performance of the small-size model. The model has a wide range of application prospects in various fields such as educational counseling, content creation, intelligent interaction, industry applications, as well as entertainment and life.
Key Features of GLM-4.1V-Thinking
- Strong visual comprehension: Accurately recognizes and analyzes a wide range of content in images, including simple target detection, more complex image classification tasks, or visual quizzes that require a comprehensive understanding of the image and answering questions.
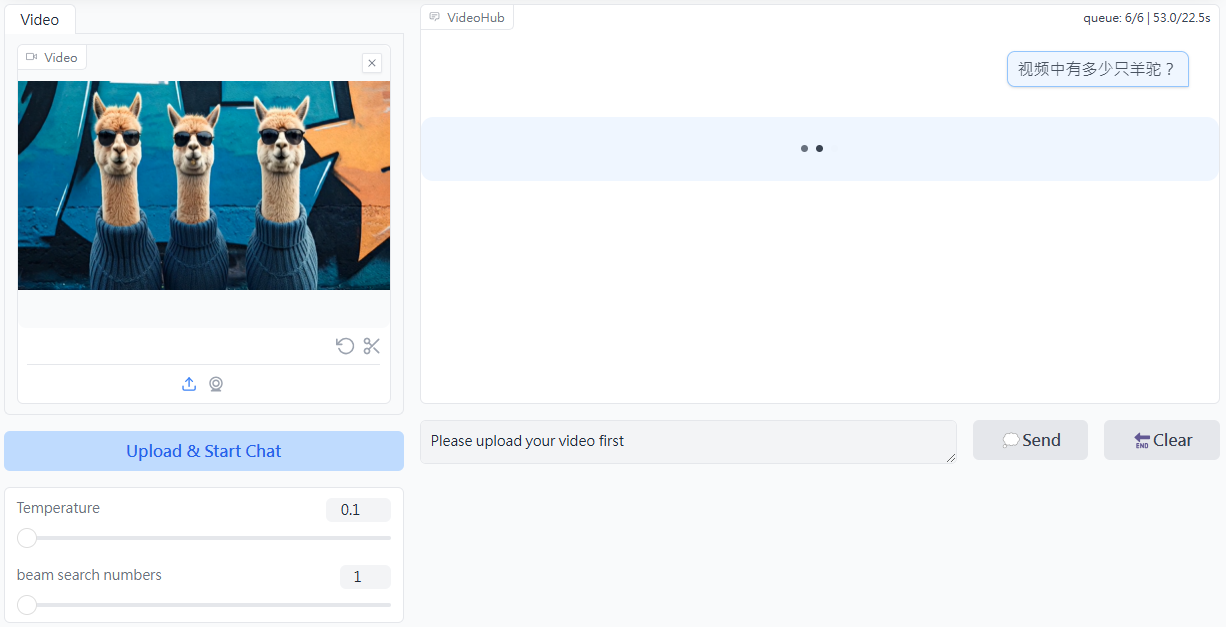
- High level of video processing: Excellent timing analysis and event logic modeling capabilities to support in-depth processing of video inputs for video understanding, generating accurate video descriptions and answering questions related to video content.
- Full-featured document parsingIt supports simultaneous processing of images and text content in documents, long document comprehension, accurate parsing of charts and graphs, and Q&A based on document content, all done efficiently.
- Excellent reasoning skills: In math and science, solving complex reasoning problems, including multi-step math problem solving, formula comprehension, and logical reasoning in science, providing strong support for learning and research in related disciplines.
- Logical reasoning is precise: Support for performing complex logical reasoning and cause-and-effect analysis, responding to tasks such as multi-step reasoning and logical judgments, and helping users to better understand and analyze a variety of complex situations.
- Cross-modal reasoning is efficient: Organically combining visual and verbal information for efficient cross-modal reasoning, accomplishing tasks such as graphic comprehension, visual quizzing and visual anchoring, and providing powerful support for the integrated processing of multimodal information.
Performance Advantages of GLM-4.1V-Thinking
In 28 authoritative evaluations such as MMStar, MMMU-Pro, ChartQAPro, OSWorld, etc., the GLM-4.1V-Thinking has achieved excellent results, of which 23 items have reached the best performance of 10B class models, and 18 items have equal or even surpassed the Qwen-2.5-VL, which has a parameter count as high as 72B, fully demonstrating the powerful performance of small volume models. This fully demonstrates the powerful performance of a small-size model.
GLM-4.1V-Thinking's official website address
- GitHub repository:: https://github.com/THUDM/GLM-4.1V-Thinking
- HuggingFace Model Library:: https://huggingface.co/collections/THUDM/glm-41v-thinking-6862bbfc44593a8601c2578d
- arXiv Technical Paper:: https://arxiv.org/pdf/2507.01006v1
- Online Experience Demo:: https://huggingface.co/spaces/THUDM/GLM-4.1V-9B-Thinking-Demo
How to Use GLM-4.1V-Thinking
- API Interface Usage::
- Get API Key: Create an app to get an exclusive API Key on the Smart Spectrum AI platform: https://bigmodel.cn/注册账号.
- invoke an API: According to the API documentation, call the model interface with an HTTP request to send input data (e.g., image URL or Base64-encoded data, text, etc.) to the model and get the model's output. For example, call with Python code:
import requests
import json
api_url = "https://api.zhipuopen.com/v1/glm-4.1v-thinking"
api_key = "your_api_key"
input_data = {
"image": "image_url_or_base64_encoded_data",
"text": "your_input_text"
}
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
response = requests.post(api_url, headers=headers, data=json.dumps(input_data))
result = response.json()
print(result)- Open Source Model Use::
- Download model: Visit the Hugging Face platform, find the GLM-4.1V-Thinking model page, and download the required model files.
- Loading Models: Load the downloaded model with a deep learning framework such as PyTorch. Example:
from transformers import AutoModelForVision2Seq, AutoProcessor
import torch
model_name = "THUDM/glm-4.1v-thinking"
model = AutoModelForVision2Seq.from_pretrained(model_name)
processor = AutoProcessor.from_pretrained(model_name)- draw inferences: Preprocess input data (e.g., image paths or URLs, text, etc.) into the model and obtain the output of the model. Example:
image_url = "image_url_or_image_path"
text = "your_input_text"
inputs = processor(images=image_url, text=text, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
result = processor.decode(outputs.logits[0], skip_special_tokens=True)
print(result)- Online experience platform use::
- Access Experience Links: Visit the GLM-4.1V-Thinking experience page directly on the Hugging Face platform.
- input data: Upload data such as images or enter text on a web page.
- Getting resultsClick the "Run" button, wait for the model to process and view the output results, without the need for complex code writing and model deployment.
Core Benefits of GLM-4.1V-Thinking
- Multi-modal input support: Supports multiple inputs such as images, videos, documents, etc., and can synthesize and process multi-source information to meet the needs of complex tasks.
- Powerful reasoning: Introducing a chain-of-thinking reasoning mechanism that generates a detailed reasoning process with step-by-step thinking to improve complex task performance and interpretability.
- Effective Training Strategies: A course-based sampling reinforcement learning strategy that dynamically adjusts training difficulty and combines large-scale pre-training with fine-tuning to improve performance and efficiency.
- Excellent performanceThe 10B parameter count is a small footprint model that has excelled in a number of authoritative reviews, demonstrating high efficiency and stability.
- Open Source and Ease of Use: The open source feature lowers the threshold of use and provides a variety of ways to use it, facilitating rapid integration and secondary development by developers.
People for whom GLM-4.1V-Thinking is intended
- Educational counseling: Teacher-assisted instruction provides students with richer learning resources and more detailed steps to solve problems.
- content creator: Ad copywriters, social media operators, news reporters, etc. generate creative content by combining images and text to improve the efficiency and quality of creation.
- Businesses and Developers: Enterprises integrate models into intelligent customer service systems to improve customer service quality, support multimodal input, better understand user needs and provide accurate answers.
- Industry Application Development: Professionals in finance, healthcare, and industry perform tasks such as data analysis, report generation, and equipment monitoring to improve efficiency and accuracy.
- (scientific) researcher: Researchers perform analysis and processing of multimodal data to support complex reasoning tasks and advance research in related fields.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles

No comments...