Gemini 2.0 Family Adds New Members: Flash-Lite Focuses on Cost-Effectiveness, Pro Specializes in Code and Complex Tasks

Google Releases Gemini 2.0 New models in the Flash series, including Gemini 2.0 Flash,Flash-Lite cap (a poem) Pro Three new models designed to provide developers with faster, more affordable, and more powerful generative AI solutions. Gemini 2.0 Flash Now fully available with higher rate limiting and enhanced performance;Flash-Lite is the more cost-effective option; and Pro versions are optimized for coding and complex tasks. The new series of models all support millions of Token contextual windows, and provides powerful features such as native tool usage and multimodal input to help developers build more powerful AI applications. Additionally, the Gemini 2.0 Flash Series has significantly reduced pricing and offers easy-to-use development tools and free tiers that allow developers to get started and quickly scale their applications.

Gemini 2.0 Series Offers More Options for Developers
Google today announced exciting updates designed to make Gemini 2.0 available to more developers and into production. The following models are now said to be available through Google AI Studio and Vertex AI in Gemini API Provided in:
- Gemini 2.0 Flash Now fully available with higher rate limits, enhanced performance and simplified pricing.
- Gemini 2.0 Flash-Lite This is a new variant, and Google's most cost-effective model to date, now in public preview.
- Gemini 2.0 Pro, an experimental update to Google's best model to date for coding and complex cues, is now available.
In addition to the recently released Gemini 2.0 Flash Thinking Experimental, a reasoning-before-answering Flash variant, these new releases enable the functionality of Gemini 2.0 to be applied to a wider range of use cases and application scenarios.
Model Characteristics
Gemini 2.0 Flash offers a comprehensive set of features, including native tool usage, a 1 million Token context window, and multimodal input. Currently, it supports text output, while image and audio output capabilities and a multimodal Live API are scheduled for general availability in the coming months.Gemini 2.0 Flash-Lite is cost-optimized for large-scale text output use cases.

Model Performance
The Gemini 2.0 model achieves significant performance gains over Gemini 1.5 in a variety of benchmarks.

Similar to the previous model, Gemini 2.0 Flash defaults to a clean style, which makes it easier to use and reduces costs. In addition, it can be prompted to use more elaborate styles for better results in chat-oriented use cases.
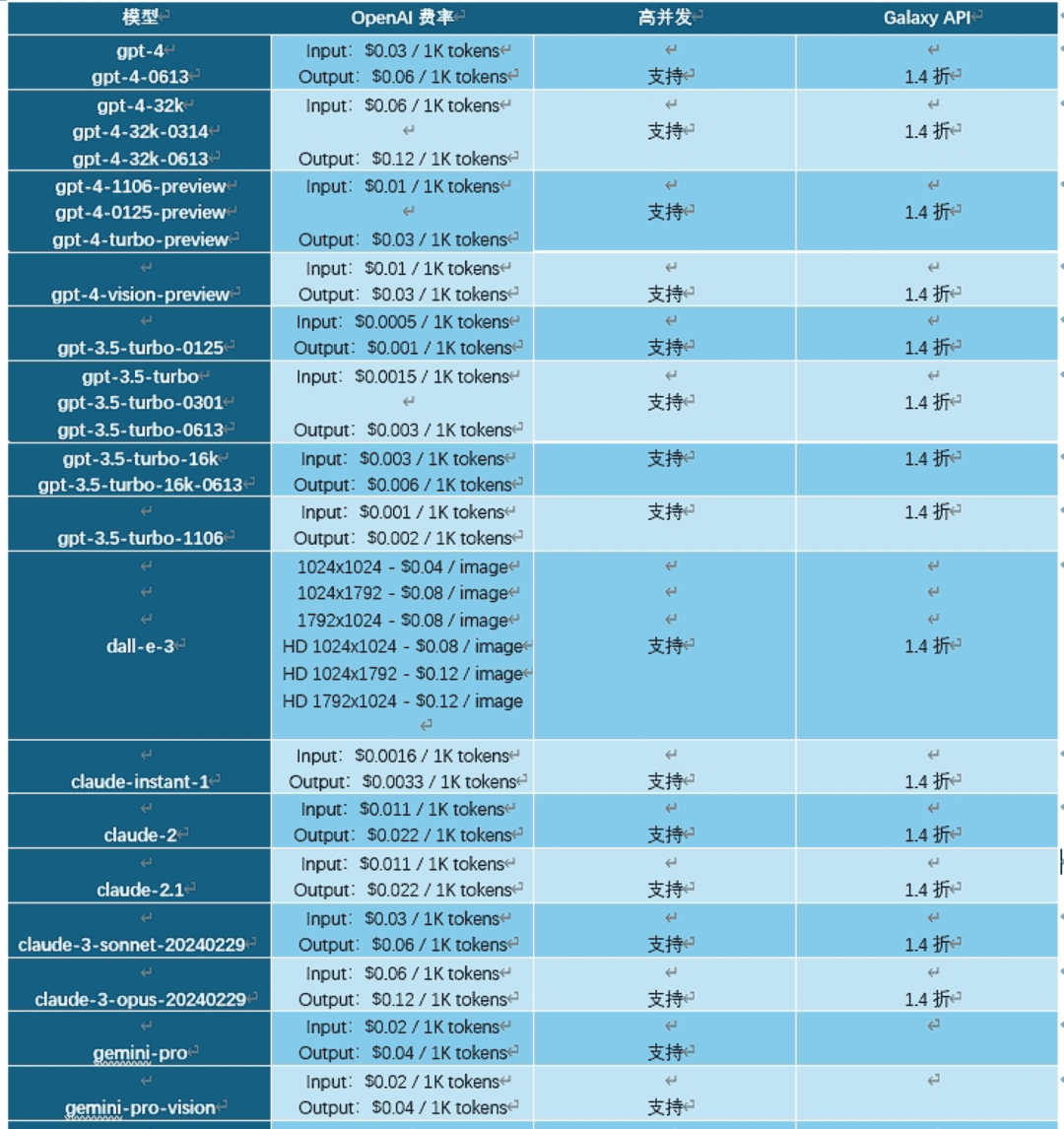
Gemini Pricing
Google continues to reduce costs with Gemini 2.0 Flash and 2.0 Flash-Lite. Both models have a single price per input type, removing the distinction that Gemini 1.5 Flash made between short and long context requests. This means that while both 2.0 Flash and Flash-Lite offer performance improvements, they can be less expensive than Gemini 1.5 Flash for mixed-context workloads.

Note: For the Gemini model, one tonkes is equivalent to approximately 4 characters. 100 lemmas is equivalent to approximately 60-80 English words.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles



No comments...