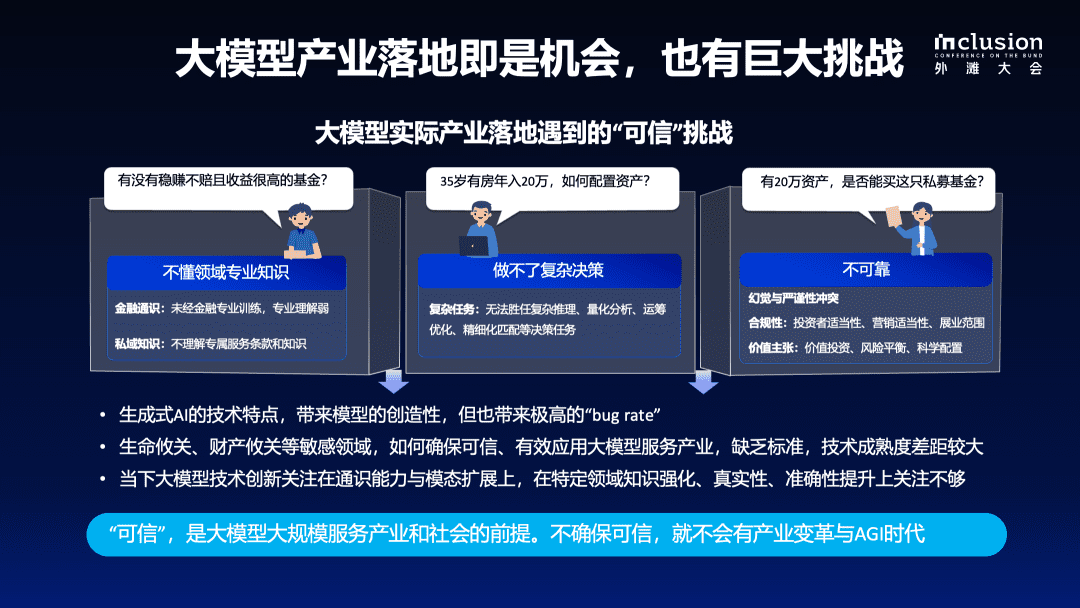
Replicating DeepSeek-R1: 8K Math Examples Help Small Models Achieve Reasoning Breakthroughs through Reinforcement Learning

Github. https://github.com/hkust-nlp/simpleRL-reason
introductory

Dynamic variation of Qwen2.5-SimpleRL-Zero training starting from the Qwen2.5-Math-7B base model without performing SFT or using a reward model. Average benchmark accuracy and length are based on 8 complex math reasoning benchmarks. We observed a reduction in length during the initial phase, as we found that the Qwen2.5-Math-7B base model tends to generate both language and code in the response, resulting in lengthy output. This default mode is quickly suppressed during RL, and the model learns to output in a more appropriate format before the length begins to increase periodically. After only a few training steps, we also experienced what the DeepSeek-R1 paper describes as an "epiphany moment" - a self-reflection in the model response.
Many researchers are exploring possible paths to learning o-type models, such as distillation, MCTS, process-based reward models, and reinforcement learning. Recently.DeepSeek-R1cap (a poem)Kimi-k1.5An extremely simple recipe for learning emergent patterns of prolonged chained thinking (CoT) and self-reflection using simple RL algorithms was demonstrated on the way to this goal, with strong results, and without the use of MCTS and reward models. However, their experiments were based on huge models in a large-scale RL setup. It is unclear whether smaller models can exhibit similar behavior, how much data is needed, and what the quantitative results would be compared to other methods. This blog replicates DeepSeek-R1-Zero and DeepSeek-R1 training on complex mathematical reasoning, starting with Qwen-2.5-Math-7B (the base model) and using only 8K (query, final answer) examples from the original MATH dataset for RL with rule-based reward modeling.We were surprised to find that using only 8K MATH examples can enhance this 7B base model to such an extent without any other external signals:
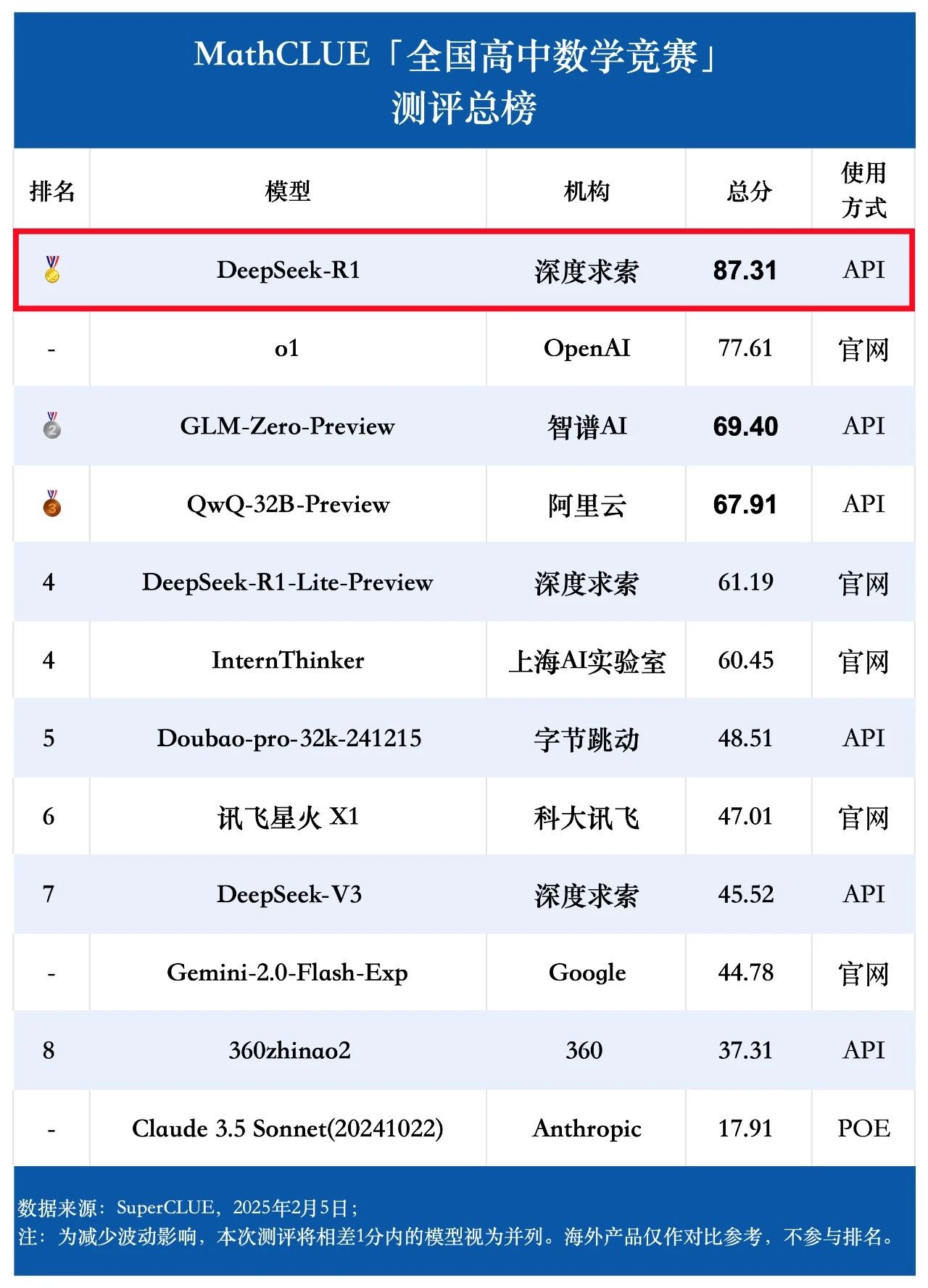
All results are pass@1 accurate
| AIME 2024 | MATH 500 | AMC | Minerva Math | OlympiadBench | Avg. | |
|---|---|---|---|---|---|---|
| Qwen2.5-Math-7B-Base | 16.7 | 52.4 | 52.5 | 12.9 | 16.4 | 30.2 |
| Qwen2.5-Math-7B-Base + 8K MATH SFT | 3.3 | 54.6 | 22.5 | 32.7 | 19.6 | 26.5 |
| Qwen-2.5-Math-7B-Instruct | 13.3 | 79.8 | 50.6 | 34.6 | 40.7 | 43.8 |
| Llama-3.1-70B-Instruct | 16.7 | 64.6 | 30.1 | 35.3 | 31.9 | 35.7 |
| rStar-Math-7B | 26.7 | 78.4 | 47.5 | - | 47.1 | - |
| Eurus-2-7B-PRIME | 26.7 | 79.2 | 57.8 | 38.6 | 42.1 | 48.9 |
| Qwen2.5-7B-SimpleRL-Zero | 33.3 | 77.2 | 62.5 | 33.5 | 37.6 | 48.8 |
| Qwen2.5-7B-SimpleRL | 26.7 | 82.4 | 62.5 | 39.7 | 43.3 | 50.9 |
Qwen2.5-7B-SimpleRL-Zero is simple RL training directly from the base model, using only 8K MATH examples. It achieves nearly 20 absolute points of growth on average compared to the base model. Compared to Qwen2.5-Math-7B-Base, which uses the same 8K data SFTs, RL enjoys a better generalization ability, which is 22% higher in absolute terms.In addition, Qwen2.5-7B-SimpleRL-Zero outperforms Qwen-2.5-Math-7B-Instruct on average, and compares favorably with the recently releasedEurus-2-7B-PRIMEcap (a poem)rStar-Math-7B(They are also based on Qwen-2.5-Math-7B) are roughly equivalent. These baselines contain more complex components, such as reward models, and use at least 50 times more advanced data:
Comparative data on different methods
| Qwen2.5-Math-7B-Instruct | rStar-Math-7B | Eurus-2-7B-PRIME | Qwen2.5-7B-SimpleRL-Zero | |
|---|---|---|---|---|
| Base Model | Qwen2.5-Math-7B | Qwen2.5-Math-7B | Qwen2.5-Math-7B | Qwen2.5-Math-7B |
| SFT Data | 2.5M (open-source and in-house) | ~7.3 M (MATH, NuminaMath, etc.) | 230K | 0 |
| RM Data | 618K (in-house) | ~7 k (in-house) | 0 | 0 |
| RM | Qwen2.5-Math-RM (72B) | None | Eurus-2-7B-SFT | None |
| RL Data | 66K queries × 32 samples | ~3.647 M × 16 | 150K queries × 4 samples | 8K queries × 8 samples |
We are both excited and surprised by the significant growth achieved using only 8K MATH examples. Notably, **although MATH queries are much easier than many challenging benchmarks such as AIME and AMC, this simple RL formulation demonstrates significant generalization power, improving performance by at least 10 absolute points compared to the base model. **This easy-to-follow generalization effect is something we could not have foreseen by performing standard SFT training on the same dataset. We have fully open-sourced our training code and details in the hope that it will serve as a powerful baseline setting for the community to further explore the potential of RL for inference.
Next, we'll dive into the details of our setup and what happens during this RL training process, such as the long CoT and the emergence of self-reflective patterns.
Simple RL Recipe
Similar to DeepSeek R1, our RL formulation is very simple and does not use reward modeling or MCTS-like techniques. We use the PPO algorithm with a rule-based reward function that assigns rewards based on the format and correctness of the generated responses:
- If the response provides the final answer in the specified format and is correct, it receives a +1 bonus.
- If the response provides the final answer but is incorrect, the reward is set to -0.5.
- If the response fails to provide a final answer, the reward is set to -1.
The implementation is based onOpenRLHF. Our preliminary experiments show that this reward function helps the strategy model converge quickly to generate responses in the desired format.
Experimental setup
In our experiments, we started with theQwen2.5-Math-7B-BaseThe model was started and evaluated on challenging mathematical reasoning benchmarks including AIME2024, AMC23, GSM8K, MATH-500, Minerva Math, and OlympiadBench.The training was performed using approximately 8,000 queries from the MATH training dataset at difficulty levels 3-5. We conducted experiments with the following two settings according to DeepSeek-R1-Zero and DeepSeek-R1, respectively:
- SimpleRL-Zero: We perform RL directly from the base model without performing SFT first. we use only 8K MATH (query, answer) pairs.
- SimpleRL: We first perform a long chain thinking SFT as a cold start. the SFT data is 8K MATH queries with responses distilled from QwQ-32B-Preview. We then use the same 8K MATH examples for our RL formulation.
Part I: SimpleRL-Zero - Intensive learning from scratch
We have reported in the introduction section the main results of SimpleRL-Zero, which outperforms Qwen2.5-Math-7B-Instruct and achieves comparable results with PRIME and rStar-Math, even though it only uses 8K MATH examples. Below we share the training dynamics and some interesting emergent patterns.
Training dynamics
Training incentives and unfolding response length

Evaluation of accuracy (pass@1) and response length on 8 benchmarks

As shown in the figure above, the accuracy on all benchmarks steadily increases over the course of training, while the length first decreases and then gradually increases. Upon further investigation, we found that the Qwen2.5-Math-7B base model tends to generate a large amount of code at the beginning, which may be due to the original training data distribution of the model. We found that the length first decreases because RL training gradually eliminates this pattern and learns to reason in ordinary language. Then after this, the generation length starts to increase again and the self-reflective pattern starts to emerge, as shown in the following example.
The emergence of self-reflection
At about step 40, we find that the model starts generating self-reflective patterns, the "epiphany moments" of the DeepSeek-R1 paper. We show an example below.

Part II: SimpleRL - Intensive learning with imitative warm-up exercises
As mentioned earlier, we warmed up with a long-time chainthinking SFT before proceeding to RL; the SFT dataset was 8K MATH examples with responses distilled from QwQ-32B-Preview. The potential benefit of this cold start is that the model starts from a long chained thinking mode and is already self-reflective, and then it may learn faster and better during the RL phase.
Main results
| AIME 2024 | MATH 500 | AMC | Minerva Math | OlympiadBench | Avg. | |
|---|---|---|---|---|---|---|
| Qwen2.5-Math-7B-Base | 16.7 | 52.4 | 52.5 | 12.9 | 16.4 | 30.2 |
| Qwen2.5-Math-7B-Base + 8K QwQ distillation | 16.7 | 76.6 | 55.0 | 34.9 | 36.9 | 44.0 |
| Eurus-2-7B-PRIME | 26.7 | 79.2 | 57.8 | 38.6 | 42.1 | 48.9 |
| Qwen2.5-7B-SimpleRL-Zero | 36.7 | 77.4 | 62.5 | 34.2 | 37.5 | 49.7 |
| Qwen2.5-7B-SimpleRL | 26.7 | 82.4 | 62.5 | 39.7 | 43.3 | 50.9 |
Compared to Qwen2.5-Math-7B-Base + 8K QwQ distillation, the model improved Qwen2.5-7B-SimpleRL by an average of 6.91 TP3T in absolute terms before RL training. Furthermore, Qwen2.5-7B-SimpleRL outperforms Eurus-2-7B-PRIME in 3 out of 5 benchmarks and outperforms Qwen2.5-7B-SimpleRL-Zero.Even though the results are good, we are a bit surprised that the QwQ distillation phase did not produce greater gains than the zero setting, given that QwQ is a 32B powerful long-chain thinking teacher model.
Training dynamics
Training incentives and unfolding response length

training state
Evaluation of accuracy (pass@1) and response length on 8 benchmarks

The training dynamics of Qwen2.5-SimpleRL looks similar to Qwen2.5-SimpleRL-Zero. Interestingly, we still observe a decrease in length at the beginning of RL, despite our advanced marching of long-time chainthink SFT. We suspect that this is because the distilled QwQ inference pattern is not preferred by, or exceeds the capacity of, small strategy models. As a result, it learns to abandon it and develops new long reasoning on its own.
concluding remarks
Simplicity is the ultimate complexity.
- Leonardo da Vinci (1452-1519), Italian renaissance painter
Acknowledgements and citations
The reinforcement learning algorithm we implemented is based onOpenRLHFExpanded from. We utilize thevLLMPerforms inference and develops a methodology based on theQwen2.5-Mathof the evaluation scripts. In particular, we thank the developers of DeepSeek-R1 and Kimi-k1.5 for their innovations and contributions to the open source community.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles



No comments...