Flying Paddle PP series models are new! New 'bee' vane for PP-DocBee document image understanding!

Document image understanding technology aims to enable computers to understand the content in document images as well as humans do. It mainly involves analyzing, processing and understanding document images (e.g., paper contracts, book pages, invoices, etc.) obtained from scanning or photographing, extracting valuable information in them, such as text, tables, charts and graphs, and structuring this information. In today's wave of digital transformation, document image understanding technology is widely used in business, academia and daily life to enhance document processing efficiency and accuracy.
Previously, combined with the Wenxin big model, FeiPaddle released the PP-ChatOCRv3 size model fusion solution, which first uses OCR technology to extract the text in the image, and then inputs the Wenxin big model to analyze the Q&A, which ultimately significantly improves the text image layout parsing and information extraction effect. The program is highly accurate on text and tables, but the ability to understand images and charts in documents needs to be further improved. Therefore, in order to better satisfy users' needs for complex and diverse document image understanding tasks, we propose a new scheme, PP-DocBee, which realizes end-to-end document image understanding based on a multimodal large model. It can be efficiently applied in all kinds of scenarios such as document understanding, document Q&A, etc. Especially for the scenarios of understanding Chinese documents, such as financial reports, laws and regulations, theses, manuals, contracts, research reports, etc., the performance is very excellent.
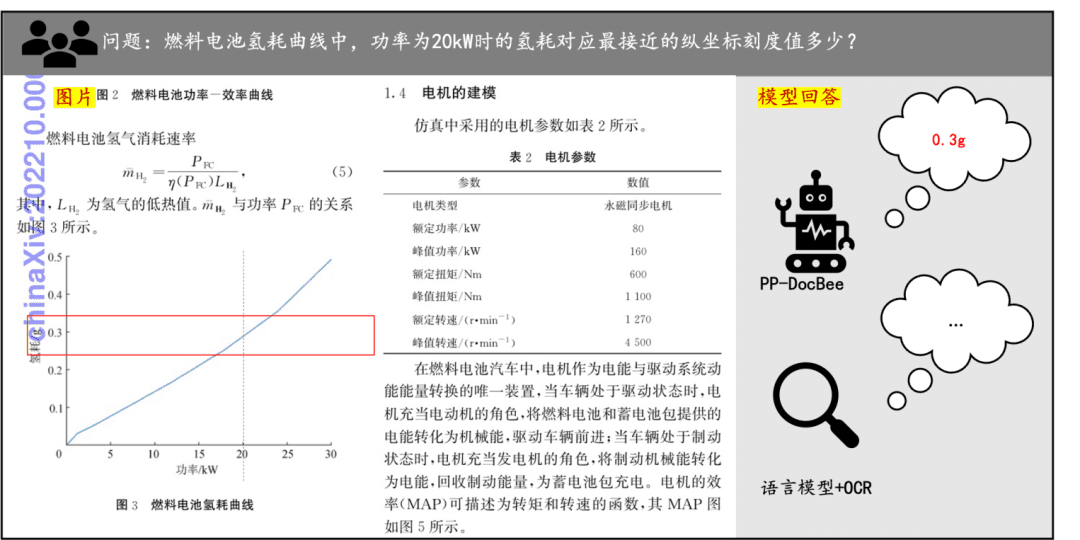
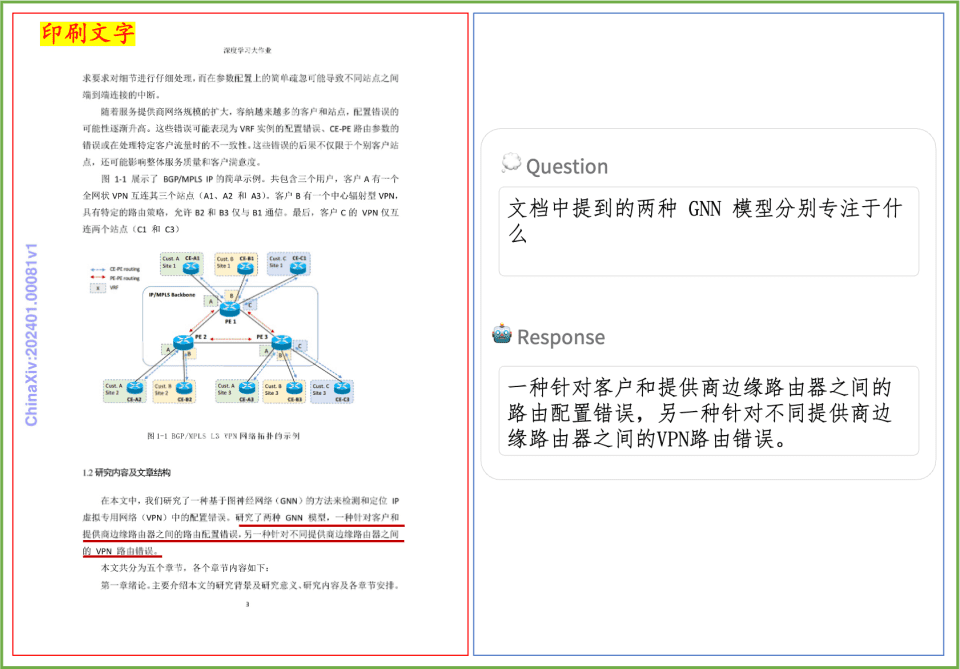
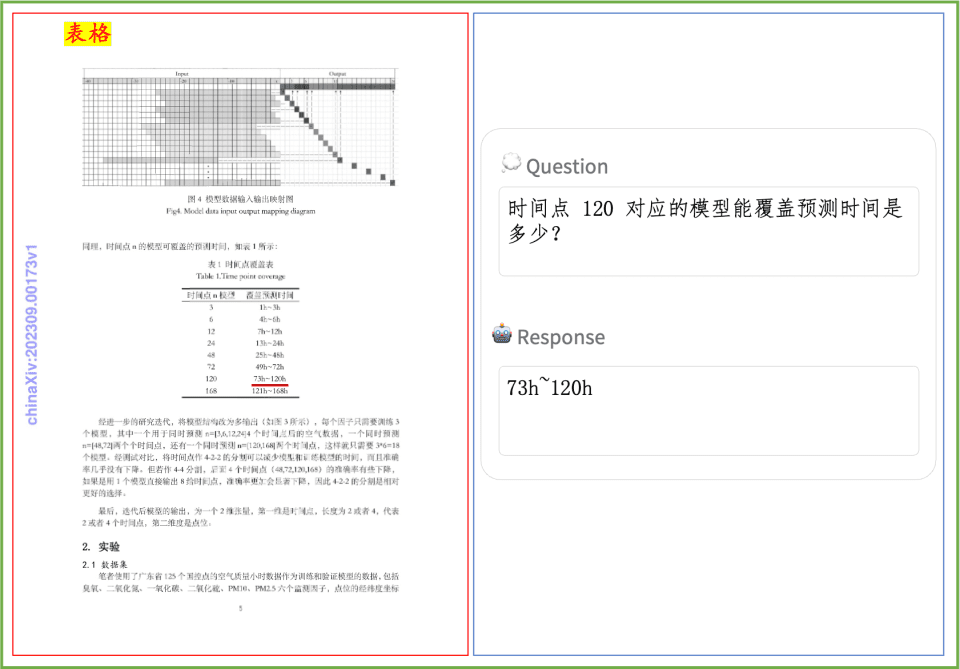
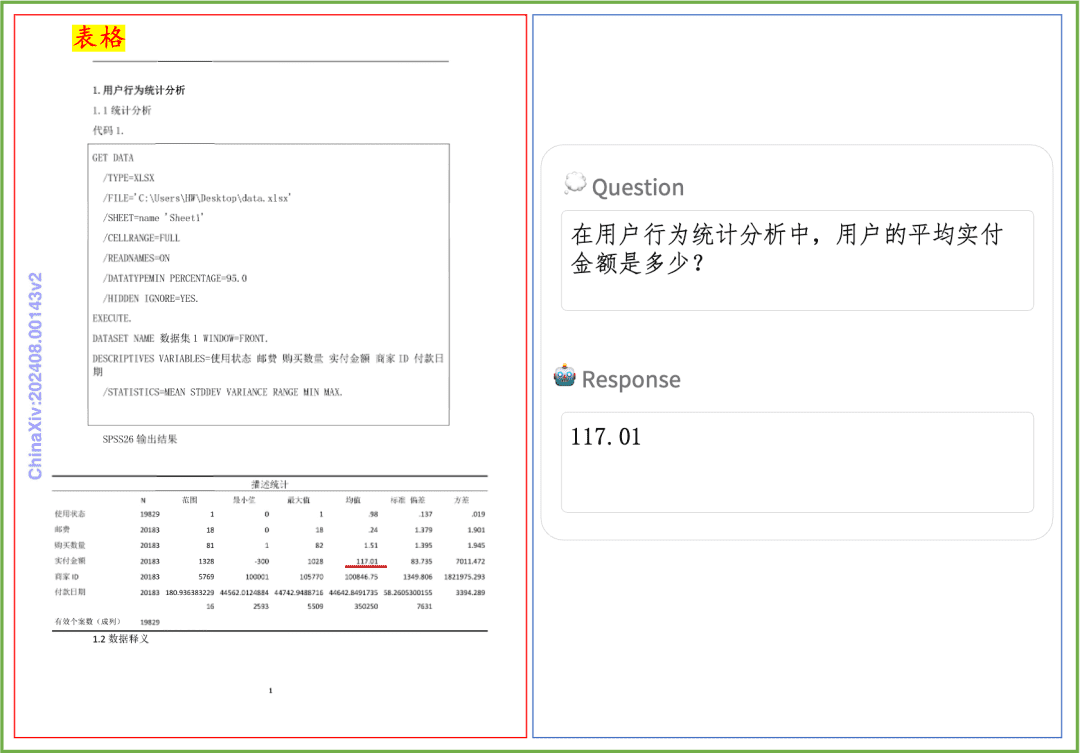
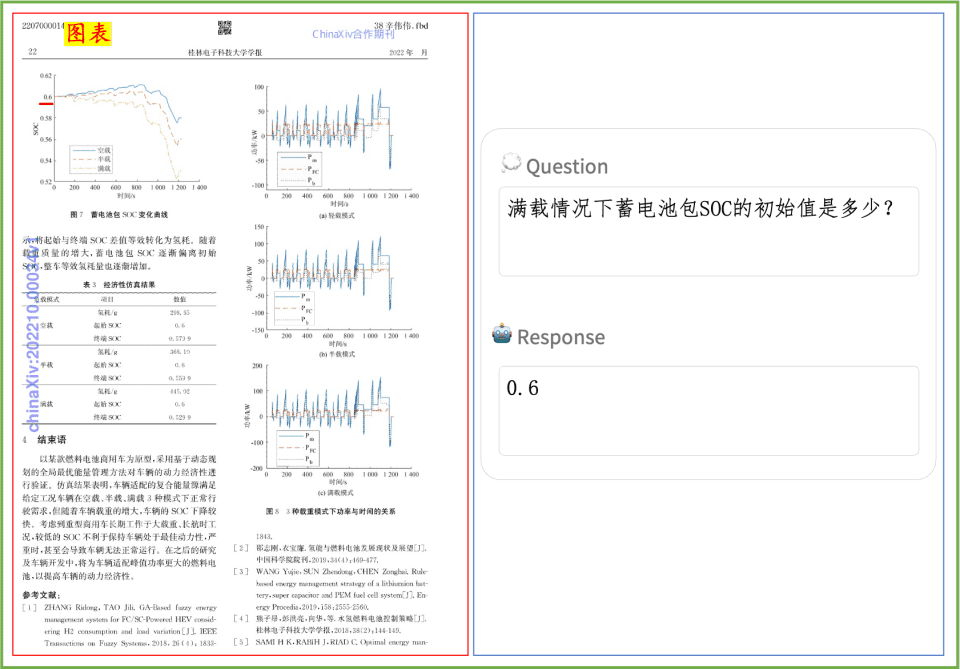
Document Comprehension Example A quick look at the effect of PP-DocBee on document comprehension of printed text, tables, charts, and more:


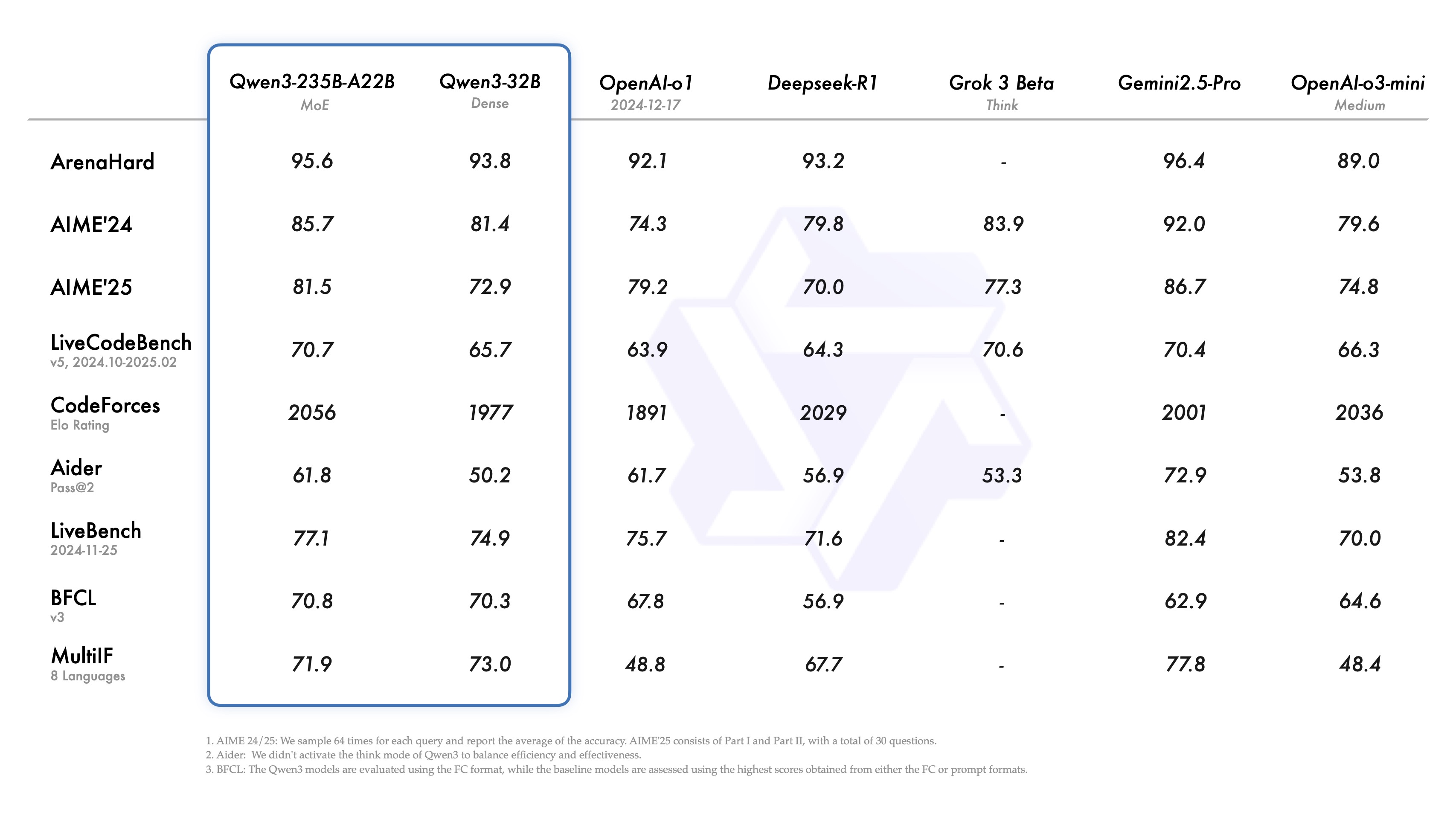
PP-DocBee has basically achieved SOTA for models of the same parameter volume level on several authoritative English document comprehension review lists in academia.
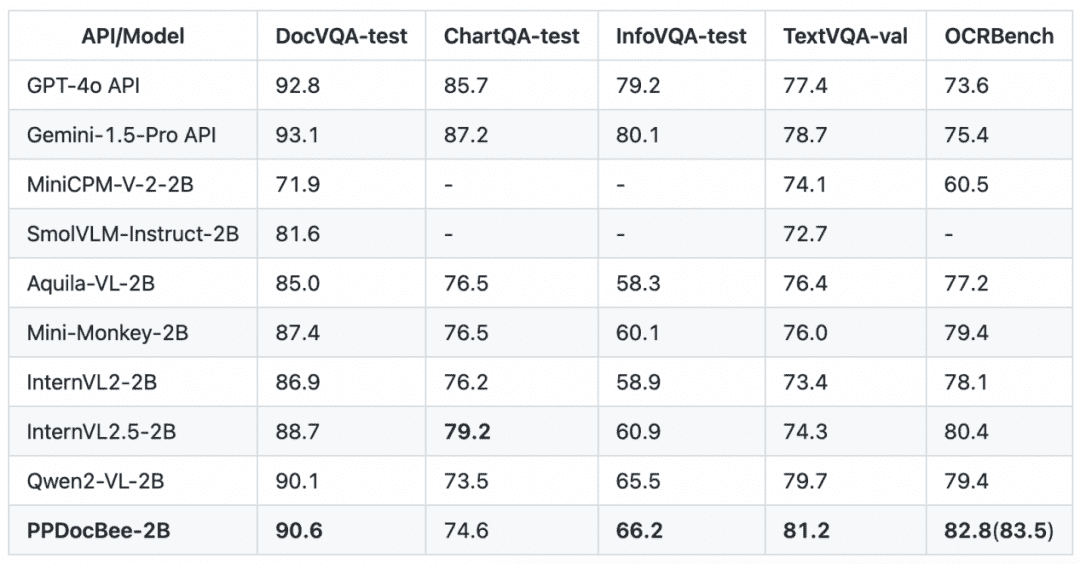
English Document Comprehension Review List Competitor Comparison
Note: The OCRBench metrics are normalized to a 100-point scale, and in PPDocBee-2B's OCRBench metrics, 82.8 is the score for end-to-end evaluation, and 83.5 is the score for OCR post-processing-assisted evaluation. PP-DocBee is also higher than the current popular open source and closed source models in the internal business Chinese scenario category of metrics.
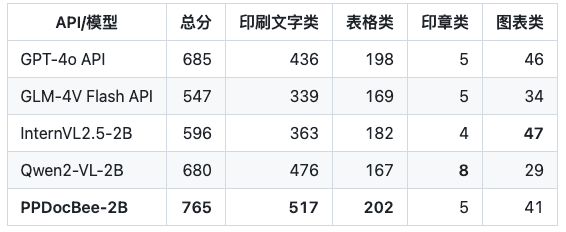
Business Chinese Scenario Competitor Comparison
Note: The assessment set of Chinese scenarios for internal business includes scenarios of financial reports, laws and regulations, scientific and technical papers, instruction manuals, liberal arts papers, contracts, research reports, etc., which are divided into 4 major categories: printed text, forms, seals, and charts.
To further improve the PP-DocBee inference performance, we achieve an inference elapsed time reduction of 51.51 TP3T and a total end-to-end elapsed time reduction of 41.91 TP3T through operator fusion optimization, as shown in the following table.
| PP-DocBee | Average end-to-end time(s) | Average preprocessing time(s) | Average time spent on reasoning (s) |
| default version | 1.60 | 0.29 | 1.30 |
| High Performance Edition | 0.93 | 0.29 | 0.63 |
Note: The high-performance version has basically the same amount of output tokens as the default version with the same amount of input tokens. Thanks to the flying paddle high-performance optimization, PP-DocBee responds more quickly while maintaining the quality of the answers. This high-performance reasoning version, for details, can be found at: https://github.com/PaddlePaddle/PaddleMIX/tree/develop/deploy/ppdocbee
We also provide an online experience environment for the Flying Paddle Star River Community, where you can quickly experience the features of PP-DocBee through the Flying Paddle Star River Community Application Center (https://aistudio.baidu.com/application/detail/60135).
In addition, we also provide local gradio deployment, OpenAI service deployment, as well as a detailed user guide, users and enthusiasts are welcome to check out the project homepage: https://github.com/PaddlePaddle/PaddleMIX/tree/develop/paddlemix/ examples/ppdocbee
Introduction of PP-DocBee program
The PP-DocBee model structure is shown in the following figure, using the architecture of ViT+MLP+LLM. The optimization ideas for document understanding scenarios includeData synthesis strategies, data preprocessing, training methods, and OCR post-processing assistanceIn the end, the model has both generalized document comprehension and strong document parsing capabilities for Chinese scenarios.

PP-DocBee model structure
Specifically, PP-DocBee includes the following major improvements:
1. Data synthesis strategy
To address the problems of insufficient Chinese language capability and lack of scenario data, we designed an intelligent production solution for document type data, designed different data generation links for each of the three major types of datasets, such as Doc, Table, Chart, etc., and adopted numerous strategies: combination of OCR small model and LLM large model, production of image data based on the rendering engine, customized data production for each document type prompt templates, etc., resulting in higher Q&A quality and controllable generation costs. The details are shown in the figure below:
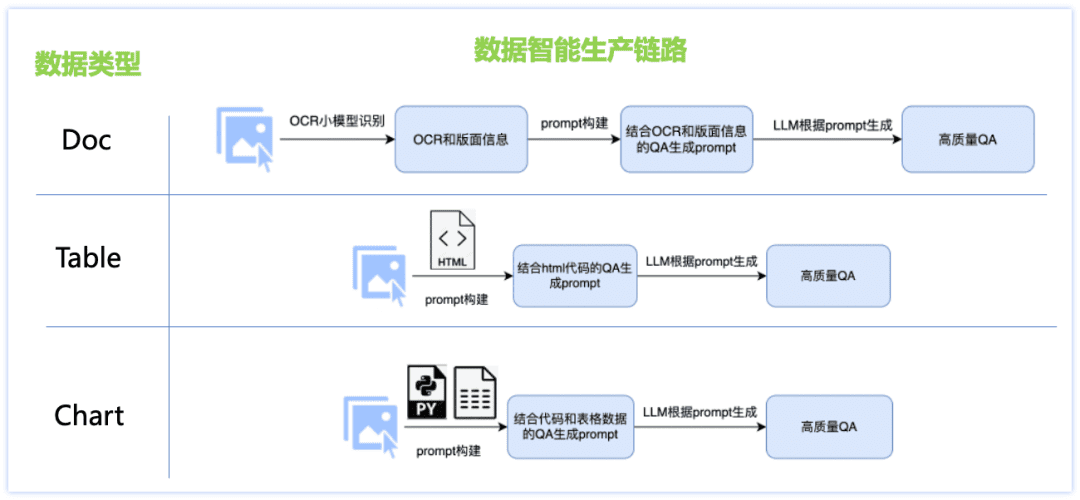
Doc class data:
Picture: collect and organize papers, financial reports, research papers and other pdf files, combined with pdf analysis tools, to produce massive single-page document picture data;
Q&A: The ocr small model extracts detailed picture layout information, thus making up for the shortcomings in visual perception of the large model, and at the same time utilizes the powerful text comprehension ability of the large language model to correct the inaccuracy of ocr small model's individual character recognition, and the combination of the two can produce a higher-quality and type-controllable Q&A.
Table class data:
Image: Based on the table image containing html text information, change the value, subject and other information in the text through the big language model, and get the content-rich high-quality table image through the table rendering tool.
Q&A: the text in html format corresponding to the table image is used as GT auxiliary information to ensure the accuracy of the answers, and the design of fine-tuned prompts to produce high-quality Q&A through a large language model.
Chart class data:
Image: Based on the crowd-tested high-quality chart source data (image-code-table data), randomly change the chart's values, axes, legends, themes and other fine-grained information in the code through a large language model to obtain source code with diverse contents, and then render the chart through the chart rendering tool (Matplotlib, Seaborn, Vega-Liteetc.) to get high quality chart image data;
Q&A: The code corresponding to the chart image and table data are used as GT auxiliary information to ensure the accuracy of the answer, and the corresponding types of questions are designed for different types of charts, and the fine-tuned prompt is designed to produce high-quality Q&A through the large language model. Through the above document type data intelligent production program we get a huge amount of synthetic data, and filter some of them as one of the PP-DocBee training data (data distribution is shown in the following figure), which effectively improves the model capability.
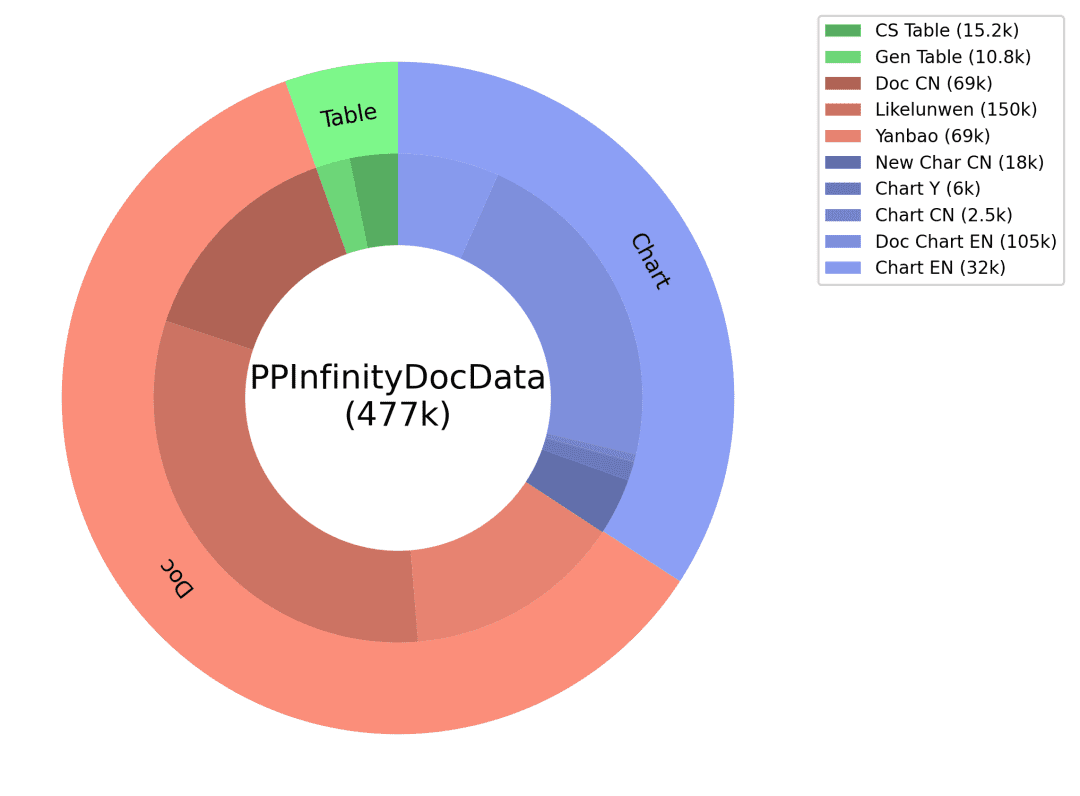
Synthetic data distribution
2. Data pre-processing
Two strategies are included, one is to set a larger resize threshold during training to increase the overall resolution distribution of the dataset, and the other is to set an equal scale enlargement of 1.1 to 1.3 times for most regular images during inference, while keeping the original data preprocessing strategy unchanged for small resolution images. These two strategies yielded more adequate and comprehensive visual features, which improved the final comprehension.
3. Training methods
It mainly mixes various document comprehension classes of data, as well as sets up a data matching mechanism. The various datasets include general VQA class, OCR class, diagram class, text-rich document class, mathematical and complex reasoning class, synthetic data class, plain text data, etc. The data matching mechanism is to set sampling ratios for data from different sources in different classes and inter-classes in order to increase the sampling weights of data with larger gains in several classes, as well as to balance the quantitative differences between the various types of datasets.
4.OCR post-processing assistance
Mainly through the OCR tool or model in advance to get the OCR recognition of text results, and then as an auxiliary a priori information provided in the picture quiz questions, and then to the PP-DocBee model reasoning, can be in the text is not much and clear picture has some effect on the improvement.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...