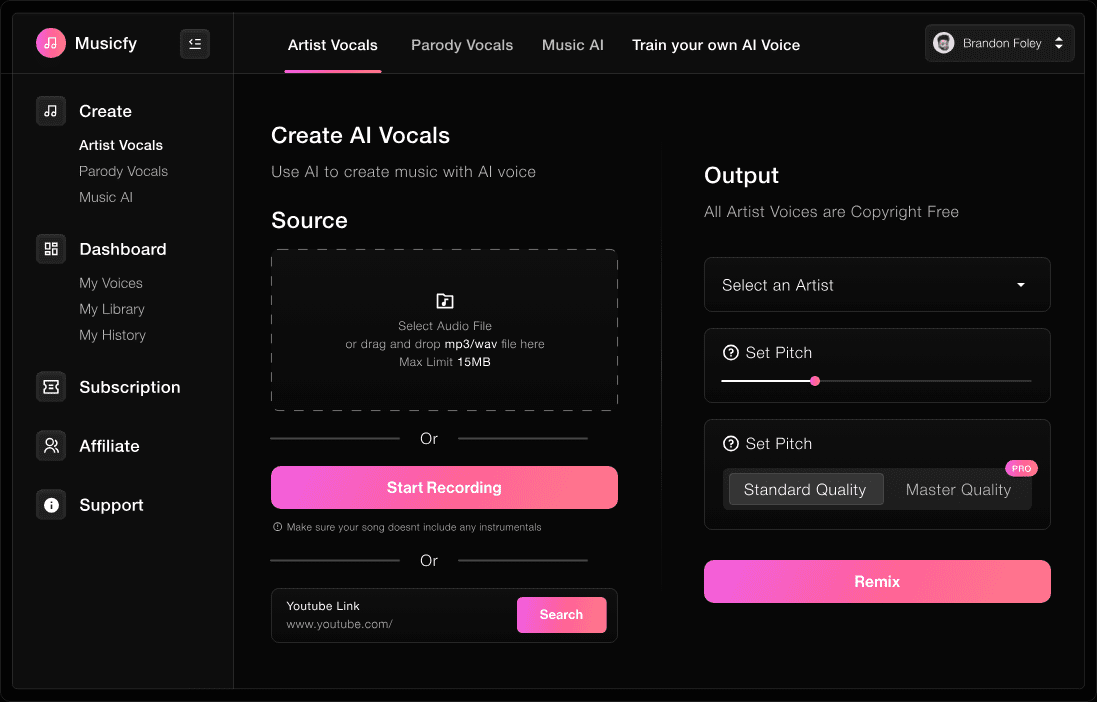
ER NeRF: Building a video synthesis system for talking heads with high fidelity

General Introduction
ER-NeRF (Efficient Region-Aware Neural Radiance Fields) is an open source talking character synthesis system presented at ICCV 2023. The project utilizes the Region-Aware Neural Radiance Fields technique to efficiently generate high-fidelity videos of speaking characters. The main features of the system are a regionalized processing scheme that models the head and torso of the character separately, and an innovative audio-space decomposition technique that enables more accurate lip synchronization. The project provides complete training and inference code, supports customized training videos, and can use different audio feature extractors (e.g., DeepSpeech, Wav2Vec, HuBERT, etc.) to process the audio input. The system achieves significant improvements in both visual quality and computational efficiency, providing an important technical solution in the field of talking character synthesis.
New project: https://github.com/Fictionarry/TalkingGaussian

Function List
- High fidelity video compositing of talking heads
- Neural radiation field rendering for area perception
- Supports separate head and torso modeling
- Precise lip synchronization
- Multiple audio feature extraction support (DeepSpeech/Wav2Vec/HuBERT)
- Customized Video Training Support
- Audio-driven character animation generation
- Smooth head movement control
- Blink motion support (AU45 feature)
- LPIPS fine-tuning optimization function
Using Help
1. Environmental configuration
System operating environment requirements:
- Ubuntu 18.04 operating system
- PyTorch version 1.12
- CUDA 11.3
Installation Steps:
- Create a conda environment:
conda create -n ernerf python=3.10
conda install pytorch==1.12.1 torchvision==0.13.1 cudatoolkit=11.3 -c pytorch
pip install -r requirements.txt
- Install additional dependencies:
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
pip install tensorflow-gpu==2.8.0
2. Preparation of pre-processing models
The following model files need to be downloaded and prepared:
- Face parsing model
- 3DMM Head Attitude Estimation Model
- Basel Face Model 2009
3. Customizing the video training process
- Video Preparation Requirements:
- Format: MP4
- Frame rate: 25FPS
- Resolution: 512x512 recommended
- Duration: 1-5 minutes
- Requires each frame to contain speaking characters
- Data preprocessing:
python data_utils/process.py data/<ID>/<ID>.mp4
- Audio feature extraction (one of three options):
- DeepSpeech feature extraction:
python data_utils/deepspeech_features/extract_ds_features.py --input data/<n>.wav
- Wav2Vec feature extraction:
python data_utils/wav2vec.py --wav data/<n>.wav --save_feats
- HuBERT feature extraction (recommended):
python data_utils/hubert.py --wav data/<n>.wav
4. Model training
The training is divided into two phases: head training and trunk training:
- Head training:
python main.py data/obama/ --workspace trial_obama/ -O --iters 100000
python main.py data/obama/ --workspace trial_obama/ -O --iters 125000 --finetune_lips --patch_size 32
- Torso Training:
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --head_ckpt <head>.pth --iters 200000
5. Model testing and inference
- Test modeling effects:
# 仅渲染头部
python main.py data/obama/ --workspace trial_obama/ -O --test
# 渲染头部和躯干
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --test
- Reasoning with target audio:
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --test --test_train --aud <audio>.npy
Tip: Adding the --smooth_path parameter reduces head jitter, but may reduce attitude accuracy.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...