
A clear article Knowledge Distillation (Distillation): let the "small model" can also have "big wisdom".

Knowledge distillation is a machine learning technique that aims to transfer learning from a large pre-trained model (i.e., a "teacher model") to a smaller "student model". Distillation techniques can help us develop lighter weight generative models for intelligent conversations, content creation, and other domains.
nearest (of locations) Distillation This word is seen very often.
The DeepSeek team, which made a big splash two days ago, released the DeepSeek-R1, whose large model with 670B parameters was successfully migrated its capabilities to a lightweight model with 7B parameters through reinforcement learning and distillation techniques.
The distilled model outperforms traditional models of the same size and even approaches OpenAI's top small model, OpenAI-o1-mini.
In the field of artificial intelligence, large language models (e.g., GPT-4, DeepSeek-R1 ) demonstrates excellent reasoning and generation capabilities with hundreds of billions of parameters. However, its huge computational requirements and high deployment costs severely limit its application in scenarios such as mobile devices and edge computing.
How to compress model size without losing performance?Knowledge Distillation(Knowledge Distillation) is a key technique to solve this problem.
1. What is knowledge distillation
Knowledge distillation is a machine learning technique that aims to transfer learning from a large pre-trained model (i.e., a "teacher model") to a smaller "student model."
In deep learning, it is used as a form of model compression and knowledge transfer, especially for large-scale deep neural networks.
The essence of knowledge distillation ismigration of knowledgethat mimics the output distribution of the teacher model so that the student model inherits its generalization ability and reasoning logic.
- Teacher model(Teacher Model): usually a complex model with a large number of parameters and sufficient training (e.g., DeepSeek-R1), whose output contains not only the prediction results, but also implicitly the similarity information between categories.
- Student model(Student Model: A small, compact model with fewer parameters that enables competency transfer by matching the Soft Targets of the Teacher Model.
Unlike traditional deep learning, where the goal is to train an artificial neural network to make predictions that more closely resemble the sample outputs provided in the training dataset, knowledge distillation requires the student model to not only fit the correct answer (a hard goal), but also to learn the "logic of thought" of the teacher's model -i.e., the output of theprobability distribution(soft targets).
For example, in the image categorization task, the teacher model will not only indicate that "this picture is a cat" (90% confidence), but will also give possibilities such as "it looks like a fox" (5%), "other animal " (5%) and other possibilities.
These probability values are like "easy points" marked by the teacher when grading papers. By capturing the correlations (e.g., cats and foxes have similar pointed ears and hair characteristics), the student model eventually learns to be more flexible in its ability to discriminate instead of mechanically memorizing standard answers.
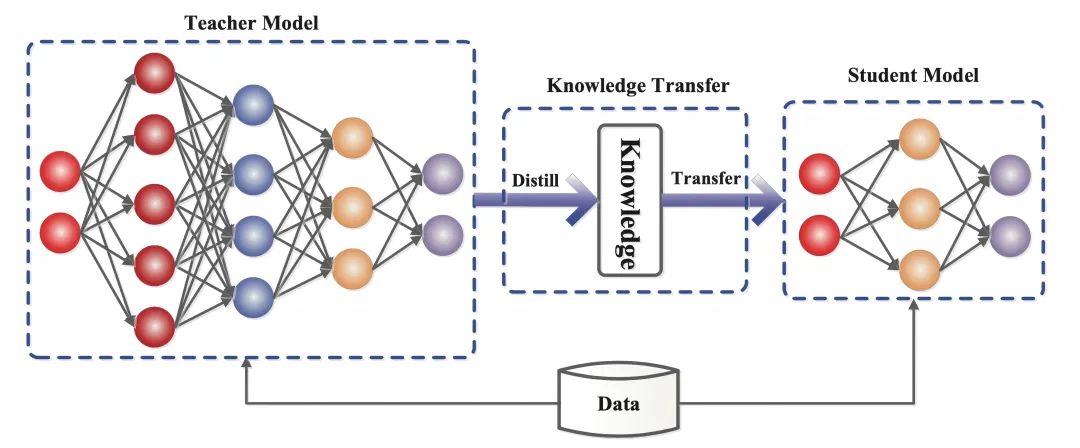
2. Knowledge of how distillation works
In the 2015 paper Distilling the Knowledge in a Neural Network, which proposes dividing training into two stages with different purposes, the authors draw an analogy: while the larval form of many insects is optimized for extracting energy and nutrients from the environment, the adult form is completely different, optimized for travel and reproduction, while traditional deep learning uses the same models in the training and deployment phases, even though they have different requirements.
The understanding of "knowledge" in the papers also varies:
Prior to the publication of the paper, there was a tendency to equate the knowledge in the training model with the learned parameter values, which made it difficult to see how the same knowledge could be maintained by changing the form of the model.
A more abstract view of knowledge is that it is a learnedMapping from input vector to output vectorThe
Knowledge distillation techniques not only replicate the output of teacher models, but also mimic their "thought processes." In the era of LLMs, knowledge distillation enables the transfer of abstract qualities such as style, reasoning ability, and alignment with human preferences and values.
The realization of knowledge distillation can be broken down into three core steps:
2.1 Soft target generation: "blurring" the answers
Teacher modeling throughHigh Temperature SoftmaxThe technology transforms the original "black and white" answers into "fuzzy hints" that contain detailed information.
As the temperature (Temperature) increases (e.g. T=20), the probability distribution of the model output is smoother.
For example, the raw judgment "Cat (90%), Fox (5%)"
May become "Cat (60%), Fox (20%), Other (20%)".
This adjustment forces student models to focus on correlations between categories (e.g., cats and foxes have similarly shaped ears) rather than mechanically memorizing labels.
2.2 Objective function design: balancing soft and hard objectives
The learning objectives of the student model are twofold:
- Imitate the logic of the teacher's thinking(Soft target): learning interclass relationships by matching teachers' high-temperature probability distributions.
- Memorize the correct answer.(Hard target): Ensure that the base accuracy rate does not decline.
The loss function of the student model is a weighted combination of soft and hard targets, and the weights of both need to be adjusted dynamically.
For example, when assigning weights of 70% to soft objectives and 30% to hard objectives, it is similar to students spending 70% time studying the teacher's solution and 30% time consolidating the standard answer, which ultimately achieves a balance between flexibility and accuracy.
2.3 Dynamic regulation of temperature parameters, control of "transfer granularity" of knowledge
The temperature parameter is the "difficulty knob" of intellectual distillation:
- High Temperature Mode(e.g., T = 20): answers are highly ambiguous and suitable for conveying complex associations (e.g., distinguishing between different breeds of cats).
- low-temperature mode(e.g., T = 1): answers are close to the original distribution and are suitable for simple tasks (e.g., number recognition).
- dynamic strategy: Extensively absorbing knowledge with high temperatures initially, and cooling down later to focus on key features.
For example, speech recognition tasks require lower temperatures to maintain accuracy. This process is similar to a teacher adjusting the depth of instruction to the level of the student-from heuristics to test-taking.
3. Importance of knowledge distillation
The best performing models for a given task tend to be too large, slow, or expensive for most real-world use cases, but they have excellent performance that comes from their size and ability to be pre-trained on large amounts of training data.
In contrast, smaller models, while faster and less computationally demanding, are less accurate, less refined, and less knowledgeable than larger models with more parameters.
This is where the value of the application of knowledge distillation comes into play, for example:
DeepSeek-R1's 670B-parameter large model migrates its capabilities to a 7B-parameter lightweight model through a knowledge distillation technique: the DeepSeek-R1-7B, which outperforms non-inference models such as GPT-4o-0513 in all aspects.DeepSeek-R1-14B outperforms the QwQ-32BPreview in all evaluation metrics, while the DeepSeek-R1-32B and DeepSeek-R1-70B significantly outperform o1-mini in most benchmarks.
These results demonstrate the strong potential of distillation. Knowledge distillation has become an important technical tool.
In the field of natural language processing, many research institutions and companies use distillation techniques to compress large language models into smaller versions for tasks such as translation, dialog systems, and text categorization.
For example, large models, when distilled, can be run on mobile devices to provide real-time translation services without relying on powerful cloud computing resources.
The value of knowledge distillation is even more significant in IoT and edge computing. While large traditional models often require powerful GPU cluster support, small models are distilled to be able to run on microprocessors or embedded devices with much lower power consumption.
This technology not only drastically reduces deployment costs, but also allows intelligent systems to be more widely used in areas such as healthcare, autonomous driving and smart homes.
In the future, the application potential of knowledge distillation will be even broader. With the development of generative AI, distillation technology can help us develop lighter-weight generative models for intelligent conversations, content creation, and other areas.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts




No comments...