
How long can a large model understand a video? Smart Spectrum GLM-4V-Plus: 2 hours


Based on the previous two generations of video models (CogVLM2-Video and GLM-4V-PLUS), we have further optimized the video comprehension techniques and released the GLM-4V-Plus-0111 beta version. This version introduces techniques such as native variable resolution, which improves the model's ability to adapt to different video lengths and resolutions.
- More detailed understanding of short videos: For content with shorter video length, the model supports native high-resolution videos to ensure accurate capture of detailed information.
- Stronger understanding of long videos: In the face of videos up to 2 hours long, the model can automatically adjust to a smaller resolution, effectively balancing the capture of temporal and spatial information, and realizing in-depth understanding of long videos.
With this update, the GLM-4V-Plus-0111 beta version not only continues the advantages of the previous two generations of models in terms of time Q&A, but also realizes a significant improvement in video length and resolution adaptability.
I. Performance Comparison
In the recently released Smart Spectrum Realtime, 4V, Air new model release, synchronized with the new API article, we detailed the review results of the GLM-4V-Plus-0111 (beta) model in the image understanding domain. The model reached sota level on several public review lists.
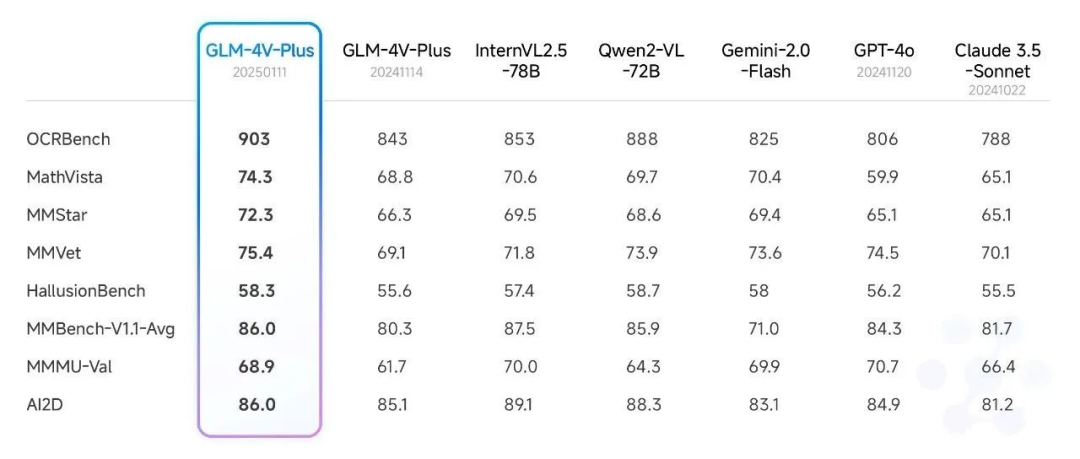
In addition, we also conducted a comprehensive test against an authoritative video understanding review set, and also achieved a relatively leading level. In particular, the GLM-4V-Plus-0111 beta model significantly outperforms comparable video understanding models in terms of fine-grained action understanding in video and long video understanding.
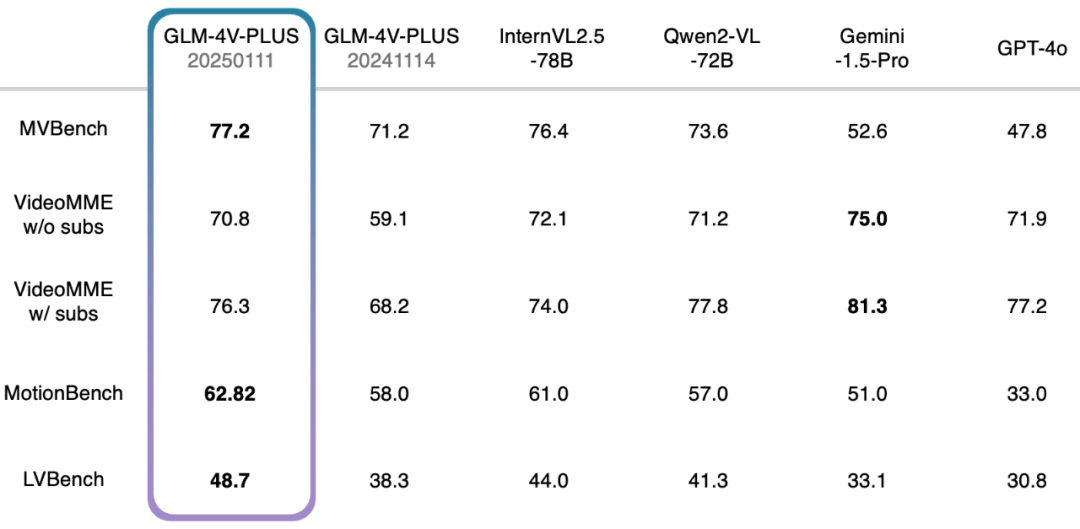
- MVBench: This review set consists of 20 complex video tasks designed to comprehensively assess the combined capabilities of multimodal grand models in video understanding.
- VideoMME w/o subs: As a multimodal evaluation benchmark, VideoMME is used to evaluate the video analysis capabilities of large language models. In this case, the w/o subs version denotes a multimodal input without subtitles, focusing on the analysis of the video itself.
- VideoMME w/ subs: Similar to the w/o subs version, but with the addition of subtitles as multimodal inputs to more fully evaluate the model's combined performance in handling multimodal data.
- MotionBench: Focusing on fine-grained motion understanding, MotionBench is a comprehensive benchmark dataset containing diverse video data and high-quality human annotations for evaluating the capabilities of video understanding models for motion analysis.
- LVBench: Aimed at evaluating the model's ability to understand long videos, LVBench challenges the performance of multimodal models when dealing with the task of long videos, and verifies the stability and accuracy of the models in long time series analysis.
II. Scenario application
In the past year, the application areas of video comprehension models have been expanding, providing diverse capabilities such as video description generation, event segmentation, categorization, tagging, and event analysis for industries such as new media, advertising, security review, and industrial manufacturing. Our newly released GLM-4V-Plus-0111 beta video comprehension model inherits and strengthens these basic functions, and further enhances the processing and analysis capabilities of video data.
More accurate video description capability: Relying on native resolution inputs and continuous data flywheel phantom optimization, the new model significantly reduces the phantom rate in video description generation and achieves a more comprehensive description of video content, providing users with more accurate and richer video information.


Efficient Video Data Processing: The new model not only has the ability to describe videos in detail, but also can efficiently complete video classification, title generation and labeling tasks. Users can further improve processing efficiency by customizing prompt words, or build automated video data processes for intelligent management.

Accurate time-awareness: In response to the time-dimensional nature of video data, our model has been dedicated to improving the time-questioning capability since its first generation. Now, the new model can more accurately locate the time point of a specific event, enable semantic segmentation and automated editing of videos, and provide powerful support for video editing and analysis.
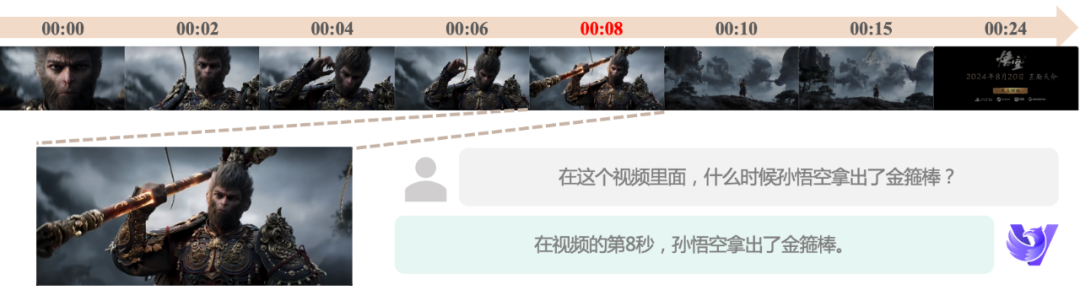
Fine Motion Understanding Capability: The new model supports higher frame rate inputs, which can capture small motion changes and realize finer motion understanding even when the video frame rate is low, providing a strong guarantee for application scenarios that require precise motion analysis.


Ultra-long video comprehension: Through innovative variable resolution technology, the new model breaks through the limitations of video processing time and supports up to 2 hours of video comprehension, which significantly broadens the business application scenarios of the video comprehension model, and the following is a case demonstration of one hour-level video comprehension:

Real-time video call capability: Based on the powerful video comprehension model, we have further developed a real-time video call model, GLM-Realtime, with real-time video comprehension and Q&A capability, and call memory up to 2 minutes. The model is now onlineSmart Spectrum AI Open PlatformAnd it is free for a limited time.GLM-Realtime not only helps customers to build video call intelligences, but also can be combined with existing networkable hardware to easily create smart homes, AI toys, AI glasses and other innovative products.
Currently, ordinary users can also get the experience of making video calls with AI on the Smart Spectrum Clear Speech App.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles



No comments...