
Complex Reasoning for Large Models from OpenAI-o1

In 2022 OpenAI released ChatGPT, which became the fastest APP in the world to break through the hundreds of millions of users, and at that time people thought that we were closer to real artificial intelligence. But people soon realized that ChatGPT could talk and chat, and even write poems and articles, but it still wasn't perfect in simple logic, such as the famous "strawberry" with several "r" stems in it.
Now, two years later, OpenAI has released the o1 model, which has sparked heated discussions about the methodology behind it with its powerful logical reasoning ability and OpenAI's strong technology hiding ability. In this article, we have combed through some related articles to take a look at the development of the complex reasoning ability of large models, using the speculation on the technology of the o1 model as a guide.
01 Background
Chain of Thought, or CoT, is a concept in cognitive psychology and education that describes the step-by-step process by which people's thinking develops as they solve problems or make decisions. Rather than simply jumping directly from question to answer, the process involves multiple steps, each of which may involve the gathering, analyzing, and evaluating of information, as well as the revision of previous conclusions. In this way, individuals are able to deal with complex problems more systematically and construct rational solutions.
Supervised fine-tuningSupervised Learning, or supervised learning, is the most common form of model training in the field of machine learning, using labeled datasets for the model to learn from in order to accurately categorize the data or predict outcomes. As input data comes into the model, supervised learning adjusts the model's weights until the model produces an appropriate fit.
Supervised Fine-Tune, or SFT for short, refers to supervised learning where we train a model with a dataset that focuses on a particular task on top of an existing base model, with a view to its ability to learn from it to solve the particular task.
Reinforcement LearningReinforcement Learning, or RL for short, is one of the three basic machine learning paradigms, alongside supervised and unsupervised learning. Reinforcement learning focuses on finding a balance between exploring (the unknown) and exploiting (the known), allowing models to learn the right behaviors with the goal of maximizing long-term returns.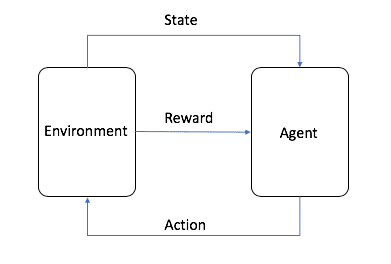
Image from AWS, as shown in the figure, in reinforcement learning, the Agent is the final target we need to train, and the set environment (Environment) to interact with the behavior (Action) and produce rewards (Reward) and state (state) transfer, Agent based on the rewards to learn to better choose the next Action This cycle is the training process of reinforcement learning.
In the training process of LLM, RL plays an important role, and it has become an industry consensus that the pre-training phase is aligned with the help of RLHF. In the reinforcement learning of LLM, we usually need another model to simulate the environment to reward the output of LLM, which is called Reward Model, or RM for short.
We will have multiple models: Actor model, Critic model and Reward model. Consistent with the standard RL training framework above, the Actor and Critic form the Agent and the Reward is trained as the Environment in the RL training process.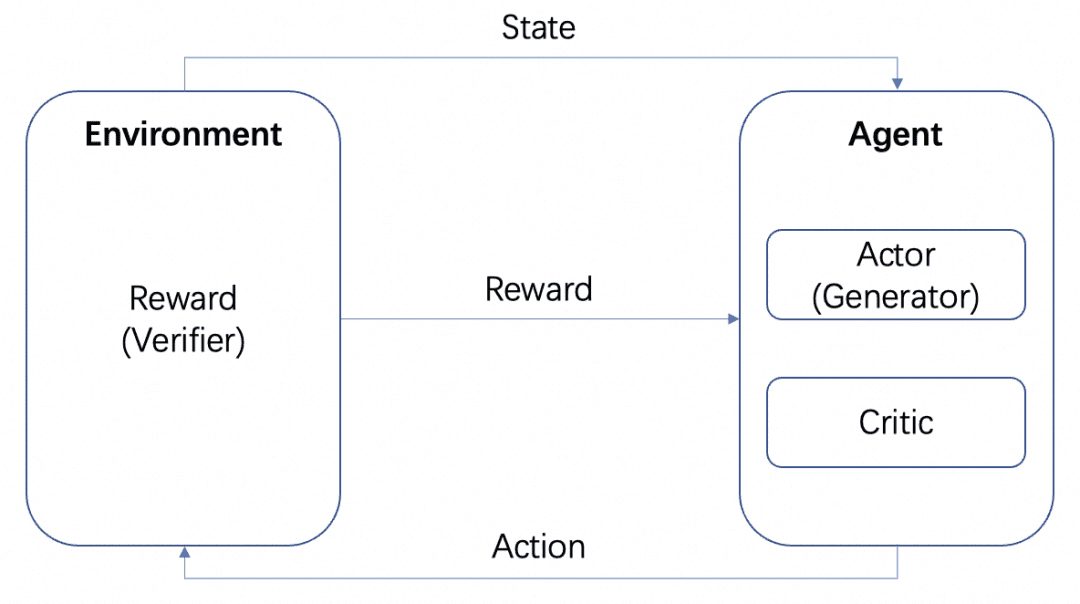
But after training, we can deploy Actor or Reward models separately, where the Actor model is our Generator and the Reward model is the Verifier that we use to measure the quality of the Generator's generation, which is the Generator-Verifier structure that OpenAI mentions in the paper Let's verify step by step. This is the Generator-Verifier structure mentioned in OpenAI's Let's verify step by step paper.
And Reward Models can be categorized according to how detailed their feedback is:
-Process Based Reward Model PRM: PRM gives feedback based on the intermediate results of LLM.
-Outcome Based Reward Model ORM: ORM gives feedback only after the final result.
We cover these two concepts in the specific scenarios below.
Monte Carlo Tree Search Monte Carlo Tree Search, or MCTS for short, is a tree search algorithm with the core idea that, at each step, it tries multiple behaviors and predicts the possible future payoffs of the behaviors, focusing on the selective exploration of some of the more rewarding behaviors.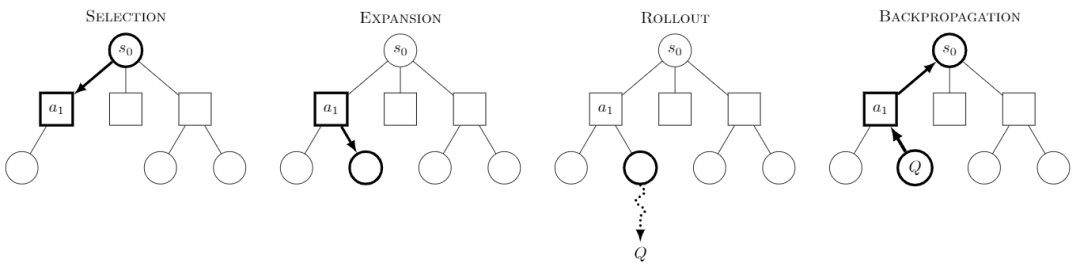
Image from Wikipedia. Each quest is referred to as being divided into four steps:
-Selection: select a node
-Expansion: generates a new node from this node to explore
-Rollout: perform a simulation along this new node to produce a result
-Back Propagation: the results of the simulation are propagated backwards, updating the nodes on the paths
By continuously exploring, we get a tree and each node has a possible result of the exploration and we can search in this tree to get the best path or result.
The use of MCTS for RL has resulted in well-known models such as AlphaZero, which performs the Selection and Rollout steps using trainable models, thus reducing the large search space and simulation cost of MCTS to efficiently obtain optimal solutions. AlphaZero's approach is to use trainable models to perform the Selection and Rollout steps, thus reducing the large search space and simulation cost of MCTS to efficiently obtain the optimal solution, e.g., using Policy Network to efficiently search for the possibility of the next step, and using Value Network to determine the value of each step instead of Rollout simulation.
o1's Multi-step Reasoning Ability When it comes to the o1 model, we have to talk about its amazing multi-step reasoning ability. o1's official website gives a few examples to visualize its multi-step reasoning ability in passwords, codes, mathematics, crossword puzzles, and so on. In the example related to "password", the decoding result is "THERE ARE THREE R'S IN STRAWBERRY", which is also the result of the once-explained "password". ChatGPT Reasoning ability to respond.
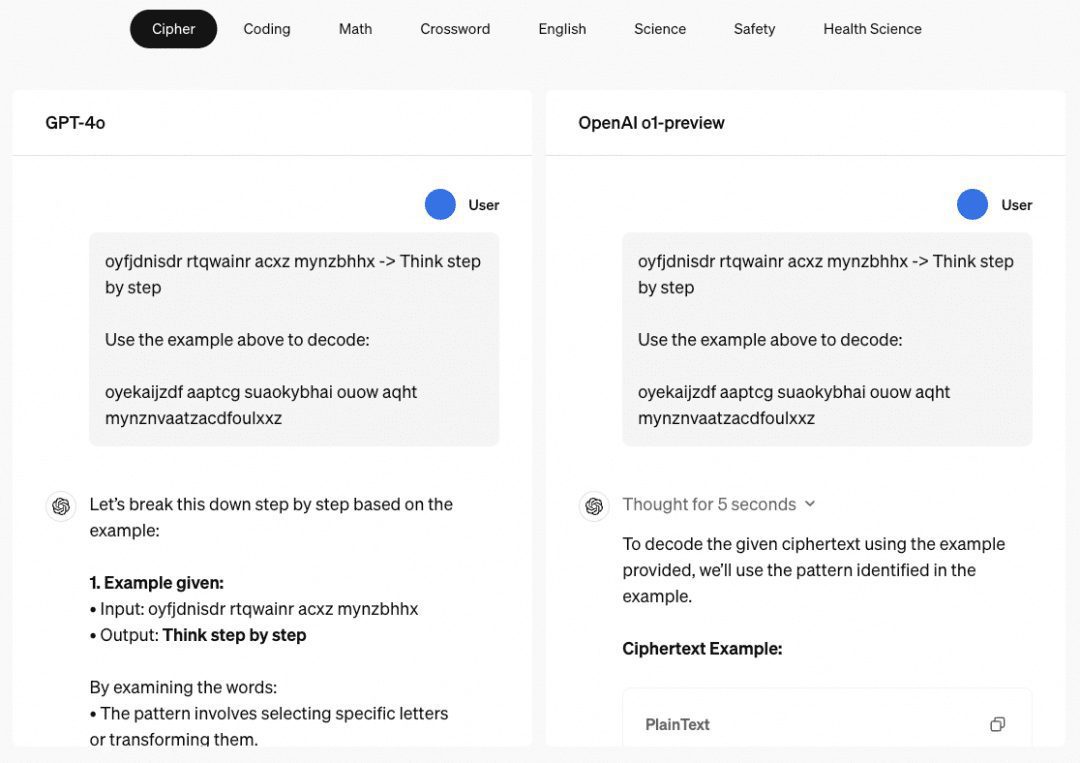
We have therefore explored a number of papers primarily in this capacity, organized and summarized as described below.
02 Cue word engineering
Before introducing cue word engineering for improving model inference, we need to understand, what is Few-Shot Learning.Currently AI training generally requires a lot of example data, and learning with only few examples is called Few-Shot, or Zero-Shot if no examples are given at all.
The paper "Chain of Thought Prompting Elicits Reasoning in Large Language Models" proposes a Few-Shot approach to improve the mathematical reasoning of models:
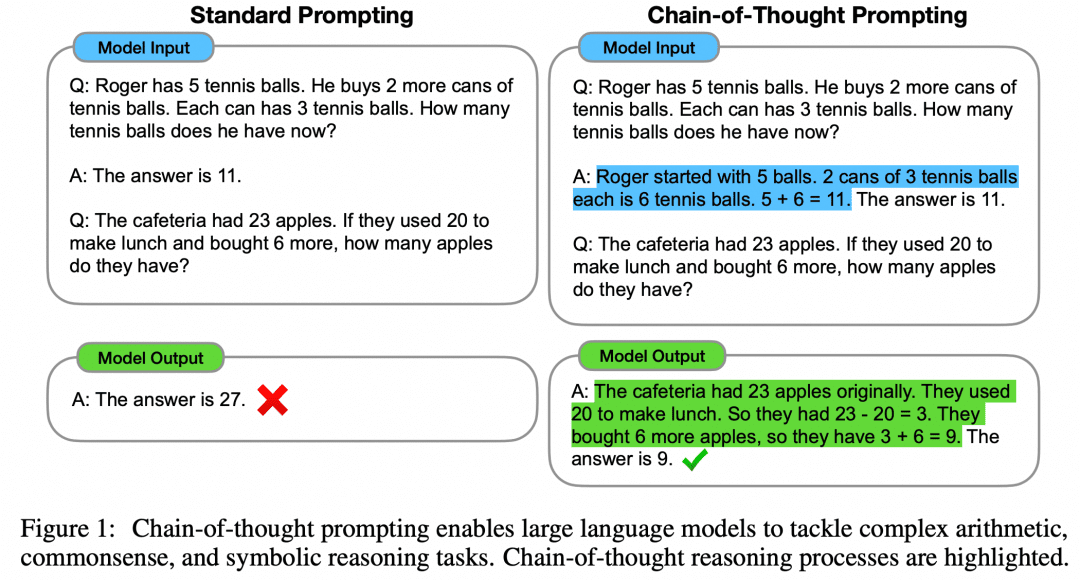
As shown in the figure, the left side gives a sample for LLM to learn in the Prompt of input LLM, which is Few-Shot Learning, but its effect is still unsatisfactory. The paper proposes this Few-Shot paradigm with CoT on the right side. So on the right, in Few-Shot, not only the question and answer of an example are given, but also the intermediate process and result. The authors found that the Few-Shot Prompt constructed in this way using CoT improves the inference of the model.
As the model itself improves and more research is done, the article "Large Language Models are Zero-Shot Reasoners" further reveals that Zero-Shot can also use CoT to enhance the model's capabilities:

Instead of going through the trouble of constructing a CoT intermediate process, or even constructing examples for Few-Shot, a simple "Let's think step by step" can enhance the LLM. Sounds like a no-brainer. This Prompt was later taken and changed by OpenAI to "Let's verify step by step", and the paper is now the centerpiece of repeated readings by anyone who wants to understand o1.
Of course building CoT on cue word engineering alone cannot be what makes o1 so powerful, but CoT, a step-by-step approach to advancing logic, has become the dominant direction for augmenting reasoning in large models.
03 CoT + Supervised Fine-Tune
Of course, there have been attempts to teach the multi-step reasoning capabilities of CoT to LLMs using SFT. "STaR: Bootstrapping Reasoning With Reasoning" is an early attempt. The image below is from that paper: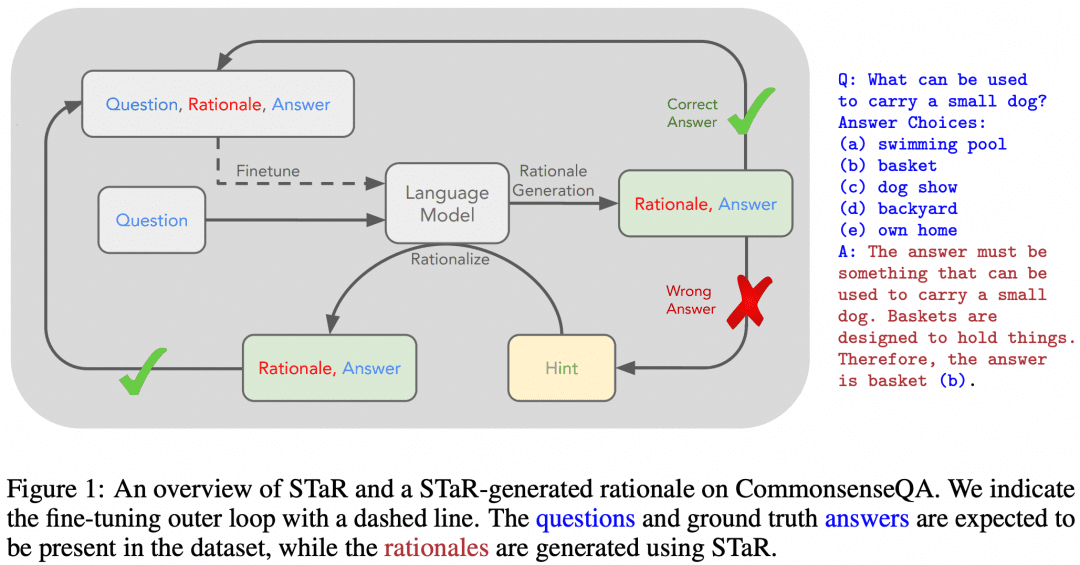
The idea of the paper is this. First we use the cue word engineering approach from above to have the model try CoT to reason over the dataset, which will result in a batch of answers, which will naturally have both right and wrong answers:
If we get a correct answer, we consider the corresponding CoT generated by the model to be a high-quality CoT, then collect such high-quality "question-CoT-answer" samples to get a new dataset, and use this dataset to SFT our LLM, and keep on looping, we can get the LLM with better reasoning ability. LLM;
-If there are some questions that LLM always answers wrongly, then we directly let LLM see the "Question+Answer", and let it generate a CoT from question to answer, we can think that the CoT generated by LLM is correct when the answer is known, and then this part of the " Question-CoT-Answer" sample can also be used for training.
Due to the early date of this study, it is easy to find the loopholes, e.g., LLM often has "wrong process but right result" or "right process but wrong result", which means that the samples we used for training are not of that high quality. This means that the samples we used for training above are not that high quality. So how to get a more correct inference process?
04 Monte Carlo Tree Search
We already know above that CoT breaks down the logic from question to answer into intermediate thought process after intermediate thought process already, so can MCTS be used to search for the best thought step for the next step of reasoning, and thus the best chain of reasoning thoughts? Naturally, yes.
Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers devised such an MCTS algorithm, called rStar, and they open-sourced the project to GitHub. the image below is from the paper, doesn't it bear some resemblance to the MCTS image above?
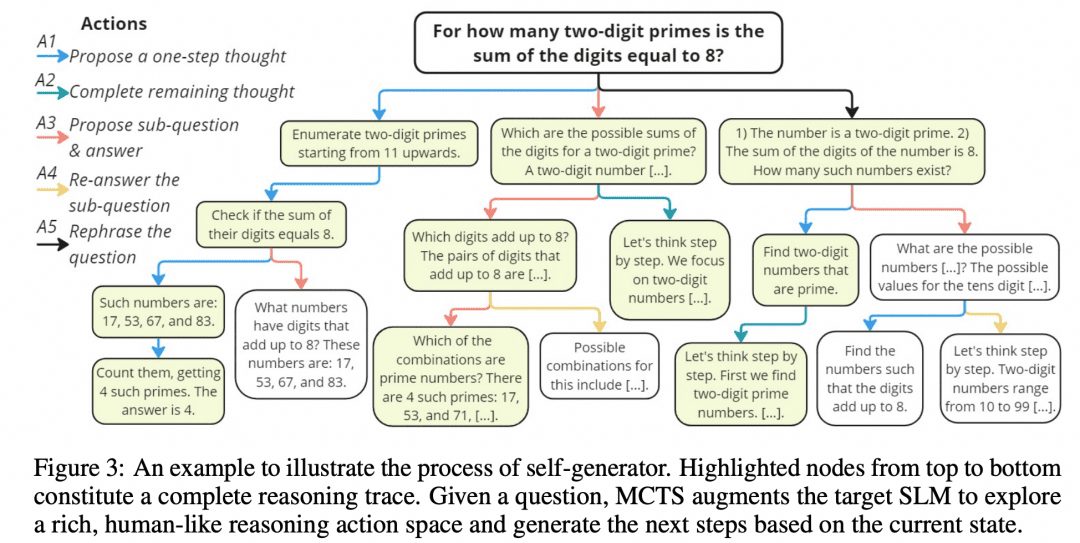
As shown in the figure above, the researchers divided the intermediate steps of CoT into 5 types of nodes:
1. Generating next steps in reasoning
2. Generating all subsequent reasoning
3. Generate a sub-question and answer
4. Re-answering the sub-questions
5. Reconfiguration issues
The MCTS is then used to determine the next thinking step node. The path linked by node after node of thought is the CoT. we simply take all the final results obtained and vote on them.
Of course, the authors studied more than that, as mentioned above, it is necessary to be able to measure the correctness of the nodes and the correctness of the reasoning at each step, and the researchers devised the following method:
-Discriminator filtering: after the original inference path obtained, randomly Mask a part of it, and then use another model for output, if we get the same result as the original Generator, then the original inference path is reliable.
-Answer correctness: all final answers are collected and the percentage of all answers that a particular answer represents is the answer score.
-Process correctness: for each reasoning node in the path, a number of 2-type nodes are generated in parallel to generate a number of one-step final results, and the proportion of these results that are the final result of the current path is considered as the process score of that reasoning node. The three-part measure leads to an optimal path, and the final result of the optimal path is considered as the result of the MCTS.
05 Generator + Verifier
In addition to MCTS above, which allows thought processes to be organized into trees and explored, there are other ways. Reinforcement learning, for example, and again we look at the introduction to reinforcement learning: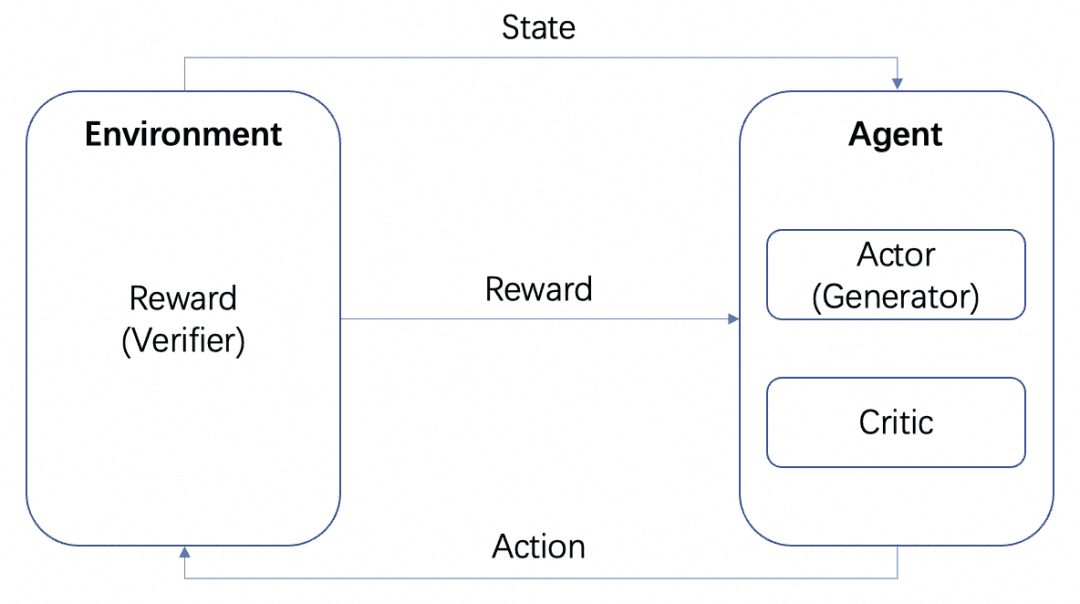
If we take the LLM as the Actor, another RM trained on the problem as the Environment, and an implicit Critic, a reinforcement learning loop would be: the Actor produces a result for the problem, the RM verifies the correctness of the result and feeds it back to the Agent, and the Actor and the Critic train according to the Reward. The Actor and the Critic are trained based on the Reward. We refer to the Agent as Generator, because its task is to generate the result, and the RM as Verifier, because its task is to verify the result.
If you think about it, isn't the relationship between Actor and Critic within an Agent very similar to the Policy and Value network used by AlphaZero? It's also true that Policy and Value networks conform to the Actor and Critic framework.
Now we summarize that a reinforcement learning process involves three networks, Actor, Critic and RM. When deploying, different frameworks are used depending on the situation: in a chess game, the winner can only be known at the end of the game, and the Reward given by the RM is too little, so we choose to keep the Actor-Critic framework when deploying, and then carry out the MCTS to get a better solution; while in the case of the LLM deployment, the RM that we have trained can provide timely feedback, so we can naturally combine the Actor and the RM into a Generator-Verifier framework when deploying. In the LLM deployment, our trained RM can provide timely feedback, so we can naturally combine the Actor and RM into the Generator-Verifier framework at the time of deployment.
OpenAI has been working on this direction since the days of GPT3 (ChatGPT is based on the GPT-3.5 model). The program they gave was the paper Training Verifiers to Solve Math Word Problems. The image below is from that paper:
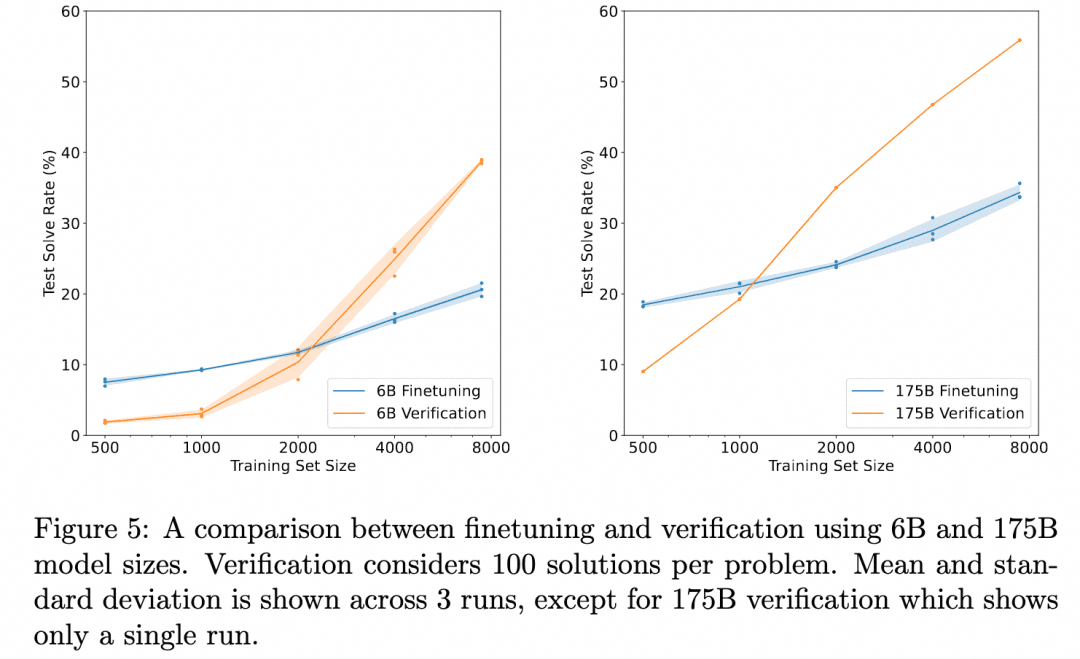
The graph above compares: "Correctness of results obtained by just fine-tuning the Generator" with "Correctness of results obtained by fine-tuning a Verifier, evaluating multiple results produced by the Generator, and selecting the more highly rated result". This demonstrates the effectiveness of the Verifier.
This is because the task here is: reasoning about the problem to get the result. So the Generator used does not produce an intermediate reasoning process but produces the result directly, and the Verifier is also the ORM (Outcome Based Reward Model) we mentioned in the Reinforcement Learning section, which serves to produce a score based on the Generator's result. So there is no multi-step inference process involved here that we want to explore, just the fact that ORM validation yields better final results than simple fine-tuning.
So the OpenAI team went a step further: on the one hand, they made Generator no longer output results directly, but instead generate step-by-step reasoning; on the other hand, they trained a PRM (Process-based Reward Model) that acts as a Verifier, whose role is to generate scores for each step in Generator's reasoning process. We believe that the results produced by striving for correctness in the Generator's reasoning process in this way are the most likely to be correct.
This is the Let's verify step by step we mentioned above. In this work, the team compared the inference results generated by searching the same Generator with PRM and ORM as Verifiers (at this point, their Generator was already GPT-4), and proved that PRM as a Verifier searched for more accurate results. The figure below is from the paper:
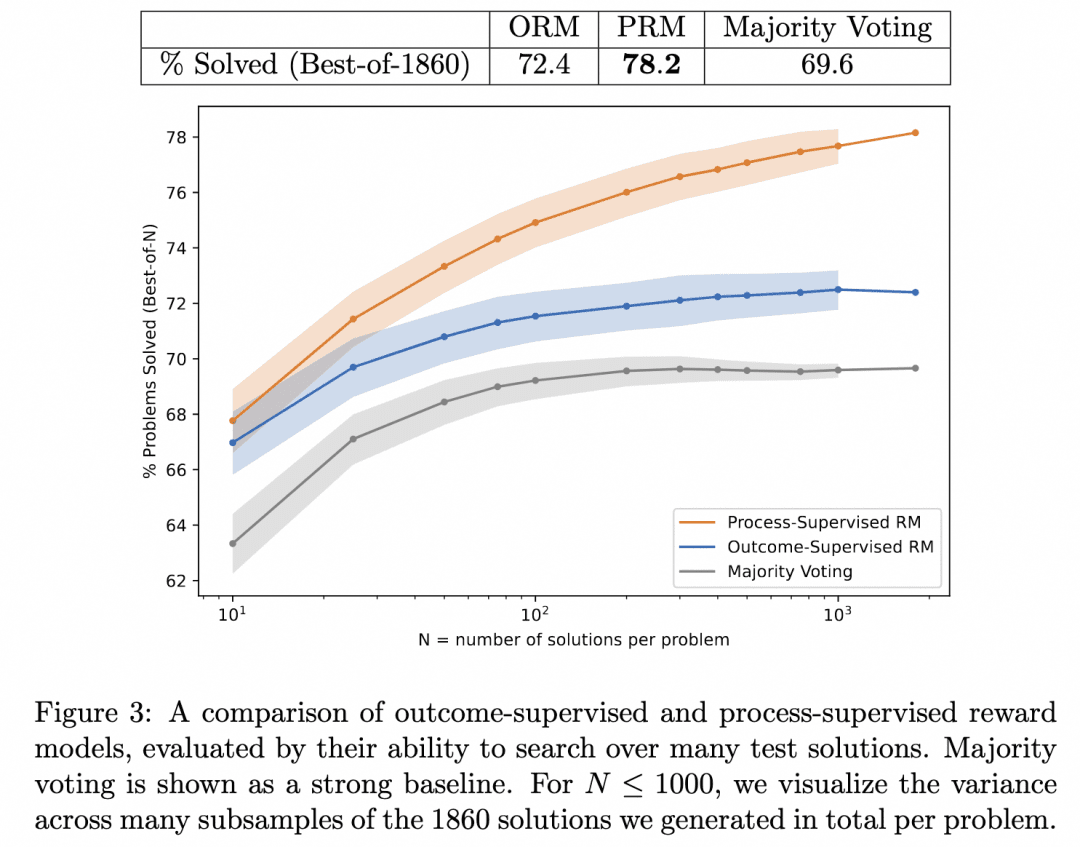
The above figure illustrates that the same stepwise reasoning Generator produces results where it is valid for us to use the ORM as a Verifier to pick the best answer for the result, but we are more likely to be correct when we use the PRM as a Verifier to pick the best answer for the process!
Is this the technology behind the o1 that we are looking for? We can only guess at this point that this is one of the core technologies behind it. The reasons are as follows:
1. This paper is relatively far from the release of o1, and one year is enough time for OpenAI researchers to delve more deeply into this direction. Because of the validity of PRM, although one year is also enough time to adjust to other directions, we still think they are going deeper rather than turning around.
2. The paper demonstrates the effectiveness of the PRM as a Verifier, and it is clear that the next step could be to improve the Generator with a powerful Verifier to produce better results. But the paper doesn't go there, so we have reason to believe that OpenAI must have tried, and it's not clear whether the result was o1.
With that guesswork out of the way, let's move on to explore other ways to search using Verifier. The article "Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters" from Google DeepMind this past August does more research. This paper is considered by many to show a similar technical line to the principles behind o1. The image below is from that paper:
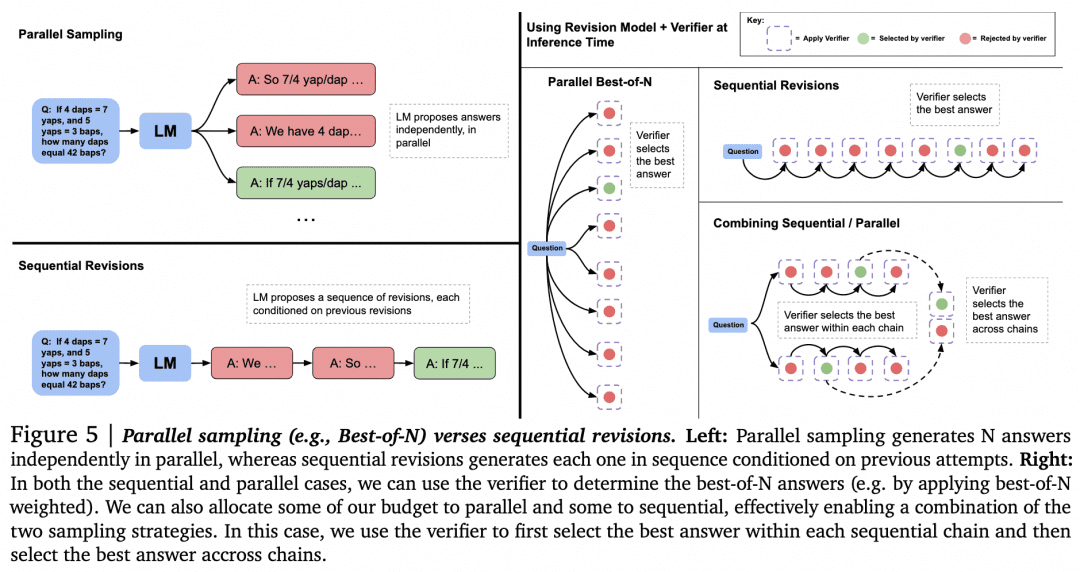
Now that we have a Generator and a Verifier, how can we make them work together to get the best results? One way to do this, as mentioned above, is to have the Generator sample in parallel to get multiple results, and the Verifier evaluates them and chooses the highest score. This is the Parallel Sampling + Best-of-N approach on the left in the figure above. But there are obviously other approaches:
-When generating multiple results, in addition to sampling multiple results in parallel, it is also possible for Generator to generate a result and then check and correct the result itself to get a sequence of answers, where they are no longer in parallel with each other.
-There can be alternatives to Best-of-N when selection is made by the Verifier. As shown in the following figure from the paper:
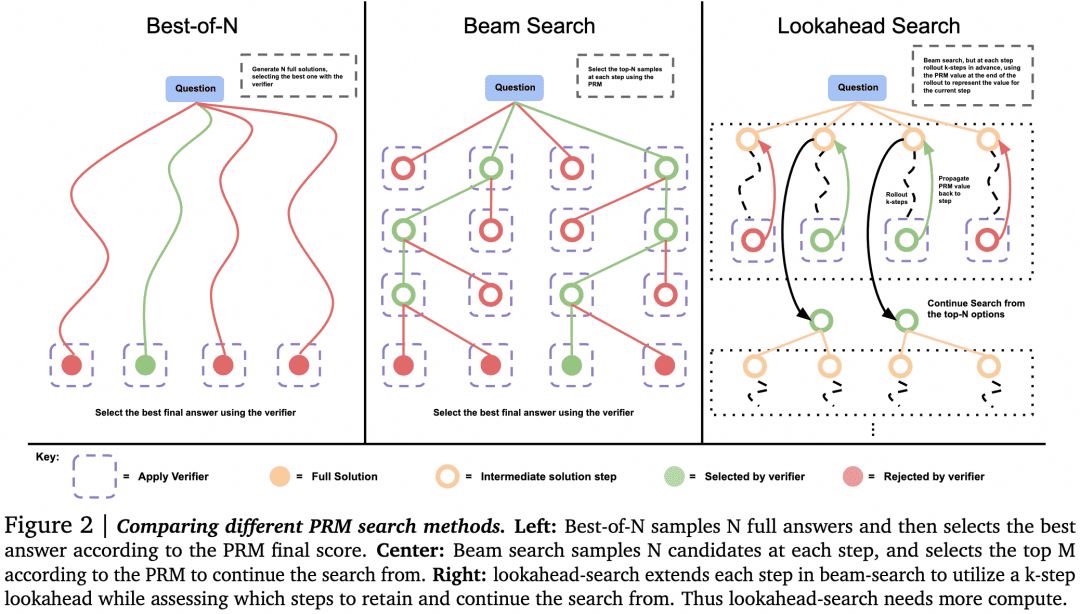
The paper found that for simple problems, we should use Verifier to encourage Generator to self-check and correct, rather than blindly searching in parallel. For complex problems, it is better for Generator to try different solutions in parallel.
A similar work is A Comparative Study on Reasoning Patterns of OpenAI's o1 Model. The paper team open-sourced Open-o1, a replica of o1, on GitHub, and this article is the result of some of their research after the release of o1. The image below is from the paper:
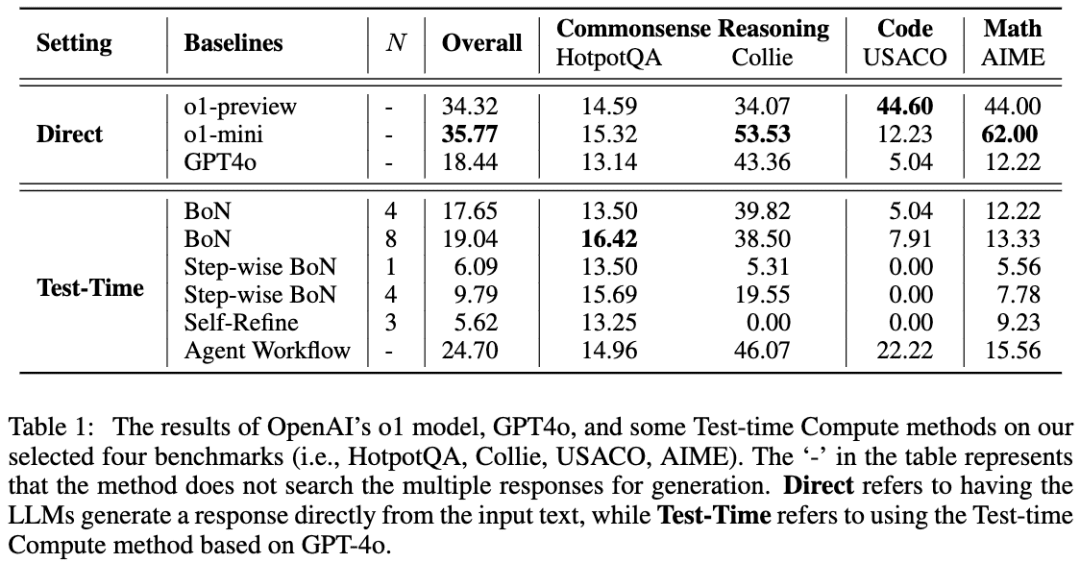
The team used GPT-4o as a skeleton model, and then compared their results using four common approaches to getting LLMs to think-before-reasoning. The team found that on the HotpotQA task, both the Best-of-N and Step-wise BoN approaches were able to significantly improve the LLM's reasoning, with BoN even making GPT-4o outperform the o1 model.
06 OpenR
Among the current open source projects trying to replicate o1, OpenR is one of the ones with a relatively high degree of completion.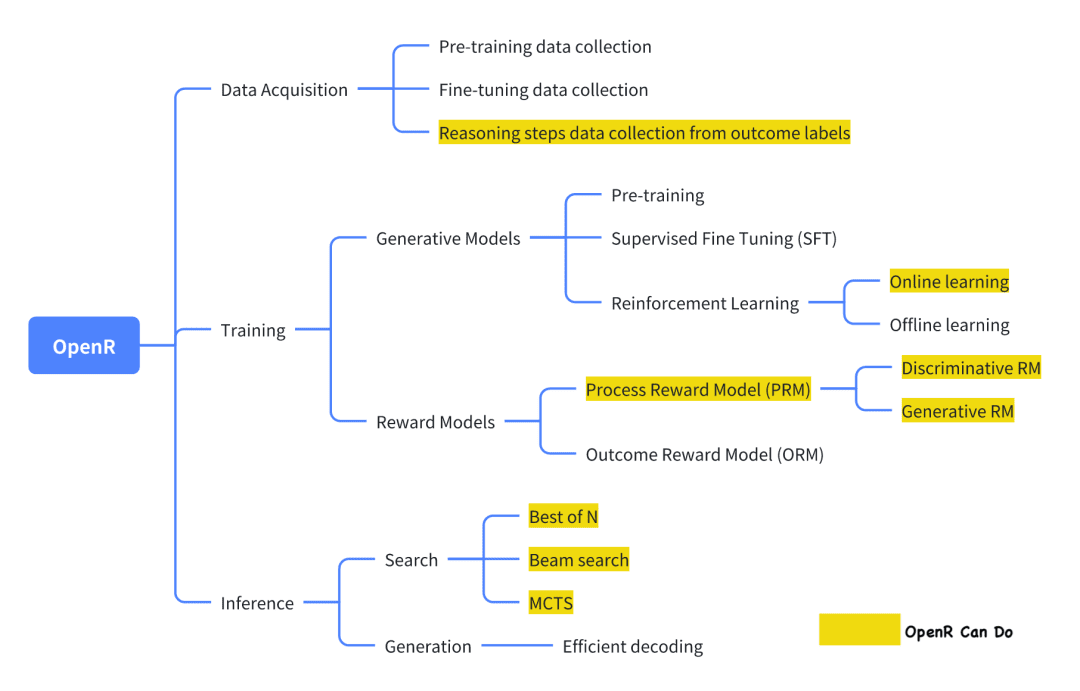
The image is from its official documentation, which, as of now, implements data collection as well as training and deployment in compliance with the Generator-Verifier framework.
Data Collection According to the official introduction, the data collection method is from the paper: 'Improve Mathematical Reasoning in Language Models by Automated Process Supervision'. In short, it is to use MCTS to extend the original problem-final_answer dataset to generate CoT inference steps. Finally, a MATH-APS dataset is obtained.
Relevant datasets have been hosted on ModelScope:
PRM800K-Stepwise dataset:
https://modelscope.cn/datasets/AI-ModelScope/openai-prm800k-stepwise-critic/
MATH-APS dataset:
https://modelscope.cn/datasets/AI-ModelScope/MATH-APS/
Math-Shepherd dataset:
https://modelscope.cn/datasets/AI-ModelScope/Math-Shepherd
The Generator training team uses a variant of the PPO algorithm from reinforcement learning to train Generator. Simply put, the PPO algorithm utilizes the Reward information provided by the Reward Model to train the Generator, and at the same time, restricts the Actor so that it doesn't stray too far from the original Actor during the learning process, avoiding the loss of existing knowledge. Currently, OpenR supports three variants: APPO, GRPO and TPPO.
The Virifier training team used SFT supervised learning to train a PRM using the MATH-APS dataset above, as well as two open source datasets, PRM800K and Math-Shepherd. Specifically, on these three Step-level datasets, the team labeled each step with a "+" or "-" label, and then had the PRM learn to predict the label of each Step and determine whether it was correct or incorrect.
The model uses "step-wise" data for PPO training, and the resulting model weights have been hosted in ModelScope, which currently provides checkpoints for SFT, PRM, and RL models, as well as some GGUF formats:
The mistral-7b-sft model:
https://modelscope.cn/models/AI-ModelScope/mistral-7b-sft
RL model (GGUF version):
https://modelscope.cn/models/QuantFactory/math-shepherd-mistral-7b-rl-GGUF
PRM modeling:
-GGUF version: https://modelscope.cn/models/QuantFactory/math-shepherd-mistral-7b-prm-GGUF
-PRM model: https://modelscope.cn/models/AI-ModelScope/math-shepherd-mistral-7b-prm
Reasoning Deployment At deployment time, OpenR uses search algorithms through the specified Generator and Verifier to obtain the reasoning process and final answer. Currently, MCTS, Beam Search, and best_of_n are supported.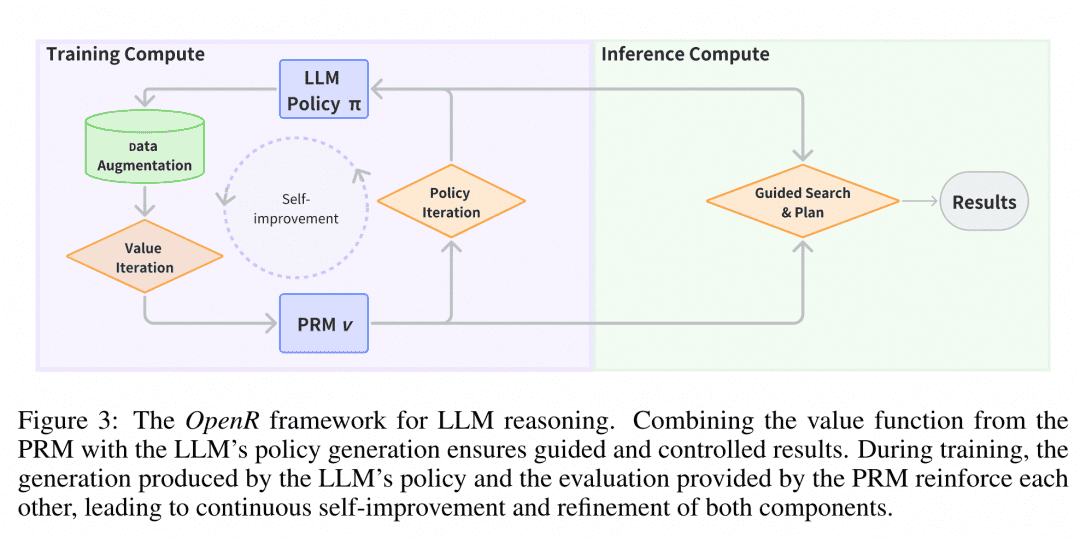
The image is from the paper "OpenR: An Open Source Framework for Advanced Reasoning with Large Language Models". The structure of OpenR is shown in the figure, and so far OpenR implements a replica of the O1 chain, from collecting training data to training a PRM to using the PRM to reinforce learning, and finally deploying the model. OpenR currently implements a chain of events that replicates O1, from collecting training data to training a PRM, to using the PRM to reinforce learning, to deploying the model for search, and the team has made all of this work open source for the community to try out, so we can get a glimpse of what's going on.
Creative Space ExperienceWe have deployed OpenR's inference service in the Magic Hitch Community Creative Space, and developers can experience the effect of OpenR online by visiting the following link: https://www.modelscope.cn/studios/modelscope/OpenR_Inference
07 Conclusion
The above papers on multistep reasoning that we have investigated demonstrate that allowing LLM to reason step-by-step instead of skipping intermediate processes can significantly enhance its accuracy on logic-related problems. In order to allow LLM to reason step-by-step, we can fine-tune it by using some datasets with intermediate processes, in addition to guiding it with simple cue word engineering. More efficiently, we can train a Verifier that can step-by-step verify the accuracy of the Generator to search the results generated by the Generator.
From the speculations and papers so far, the possible technology to move towards o1 is precisely based on the cooperation between the powerful LLM Generator and the LLM Verifier. This kind of left-foot-on-right-foot, self iterating against itself is not the first time in deep learning, but OpenAI is the first to introduce such a model into the LLM field, which is very expensive just to train the Generator.
Therefore, we believe that if we want to replicate o1, the first thing we need is a Verifier that can provide assistance and guidance to the Generator, and in order to generate the data needed to train the Verifier, we can refer to the CoT + Supervised Fine-Tune and Monte Carlo Tree Search chapters above to obtain higher-quality data in a more In order to generate the data needed to train the Verifier, one can refer to the CoT + Supervised Fine-Tune and Monte Carlo Tree Search chapters above for a low-cost way to obtain higher quality data. This is why we have also presented these tasks.
We ended up presenting one of the more finished open source projects, and based on their work, we were able to organize our thoughts and ideas.
08 Reference
Chain of Thought Prompting Elicits Reasoning in Large Language Models
Large Language Models are Zero-Shot Reasoners
STaR: Bootstrapping Reasoning With Reasoning
Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers
Training Verifiers to Solve Math Word Problems
Let's verify step by step
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
A Comparative Study on Reasoning Patterns of OpenAI's o1 Model
OpenR: An Open Source Framework for Advanced Reasoning with Large Language Models
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles




No comments...