
Tandem langchain open deep search for cue words

In order to string together the project execution process and translate the cue word instructions, we need to base our project on theprompts.pyfile to describe in detail the execution flow of each step and its corresponding cue word instructions.
Project execution process and corresponding cue word instructions
1. Generate search queries to help plan reports
- Prompt:
report_planner_query_writer_instructions = """ 你是一名专家技术写手,正在帮助计划一份报告。 <报告主题> {topic} </报告主题> <报告组织> {report_organization} </报告组织> <任务> 你的目标是生成 {number_of_queries} 个搜索查询,以帮助收集全面的信息来规划报告部分。 这些查询应当: 1. 与报告主题相关 2. 帮助满足报告组织中规定的要求 使查询足够具体,以找到高质量、相关的资源,同时覆盖报告结构所需的广度。 </任务> """
2. Plan for generating reports
- Prompt:
report_planner_instructions = """ 我需要一个报告计划。 <任务> 生成一个报告部分的列表。 每个部分应当包含以下字段: - 名称 - 报告部分的名称。 - 描述 - 本部分涵盖的主要主题的简要概述。 - 研究 - 是否需要为本部分报告进行网络研究。 - 内容 - 本部分的内容,现在可以留空。 例如,介绍和结论将不需要研究,因为它们将从报告的其他部分提炼信息。 </任务> <主题> 报告的主题是: {topic} </主题> <报告组织> 报告应遵循此组织: {report_organization} </报告组织> <上下文> 以下是用于规划报告部分的上下文: {context} </上下文> <反馈> 以下是对报告结构的审查反馈(如果有): {feedback} </反馈> """
3. Preparation of search queries
- Prompt:
query_writer_instructions = """ 你是一名专家技术写手,正在编写有针对性的网络搜索查询,以收集撰写技术报告部分的全面信息。 <部分主题> {section_topic} </部分主题> <任务> 你的目标是生成 {number_of_queries} 个搜索查询,以帮助收集有关本部分主题的全面信息。 这些查询应当: 1. 与主题相关 2. 检查该主题的不同方面 使查询足够具体,以找到高质量、相关的资源。 </任务> """
4. Report writing component
- Prompt:
section_writer_instructions = """ 你是一名专家技术写手,正在撰写技术报告的一个部分。 <部分主题> {section_topic} </部分主题> <现有部分内容(如果已填写)> {section_content} </现有部分内容> <源材料> {context} </源材料> <撰写指南> 1. 如果现有部分内容未填写,则从头撰写新的部分。 2. 如果现有部分内容已填写,请撰写一个新的部分,将现有内容与新信息综合起来。 <长度和风格> - 严格限制在150-200字 - 不使用营销语言 - 技术重点 - 使用简单、清晰的语言 - 用**加粗**的最重要的见解开头 - 使用简短的段落(每段最多2-3句话) - 使用 ## 作为部分标题(Markdown格式) - 仅在有助于澄清观点时使用一个结构元素: * 要么是比较2-3个关键项目的集中表格(使用Markdown表格语法) * 要么是使用正确的Markdown列表语法的简短列表(3-5项): - 使用 `*` 或 `-` 表示无序列表 - 使用 `1.` 表示有序列表 - 确保正确的缩进和间距 - 以参考以下源材料的###来源结束: * 列出每个来源的标题、日期和URL * 格式:`- 标题 : URL` </长度和风格> <质量检查> - 恰好150-200字(不包括标题和来源) - 仔细使用一个结构元素(表格或列表),仅在有助于澄清观点时 - 一个具体的例子/案例研究 - 以加粗见解开头 - 在创建部分内容之前不作任何序言 - 在结尾引用来源 </质量检查> """
5. Assessment of the reporting component
- Prompt:
section_grader_instructions = """ 审核相对于指定主题的报告部分: <部分主题> {section_topic} </部分主题> <部分内容> {section} </部分内容> <任务> 评估该部分是否通过检查技术准确性和深度,充分涵盖了主题。 如果该部分未满足任何标准,请生成具体的后续搜索查询以收集缺失的信息。 </任务> <格式> grade: Literal["pass","fail"] = Field( description="评估结果,指示响应是否符合要求('通过')或需要修订('失败')。" ) follow_up_queries: List[SearchQuery] = Field( description="后续搜索查询列表。", ) </格式> """
6. Writing the final report section
- Prompt:
final_section_writer_instructions = """ 你是一名专家技术写手,正在撰写综合报告其他部分信息的部分。 <部分主题> {section_topic} </部分主题> <可用报告内容> {context} </可用报告内容> <任务> 1. 部分特定方法: 对于介绍: - 使用 # 作为报告标题(Markdown格式) - 50-100字限制 - 使用简单和清晰的语言 - 重点介绍报告的核心动机,1-2段 - 使用清晰的叙述弧线介绍报告 - 不使用任何结构元素(无列表或表格) - 不需要来源部分 对于结论/总结: - 使用 ## 作为部分标题(Markdown格式) - 100-150字限制 - 对于比较报告: * 必须包含使用Markdown表格语法的集中比较表 * 表格应提炼报告中的见解 * 保持表格条目清晰简洁 - 对于非比较报告: * 仅在有助于提炼报告中的要点时使用一个结构元素: * 要么是比较报告中项目的集中表格(使用Markdown表格语法) * 要么是使用正确的Markdown列表语法的简短列表: - 使用 `*` 或 `-` 表示无序列表 - 使用 `1.` 表示有序列表 - 确保正确的缩进和间距 - 以具体的下一步或影响结束 - 不需要来源部分 3. 撰写方法: - 使用具体细节而非一般陈述 - 每个字都要有意义 - 重点突出最重要的一点 </任务> <质量检查> - 对于介绍:50-100字限制,# 作为报告标题,无结构元素,无来源部分 - 对于结论:100-150字限制,## 作为部分标题,仅使用一个结构元素,无来源部分 - Markdown格式 - 不在响应中包含字数或任何序言 </质量检查> """
Tandem execution process
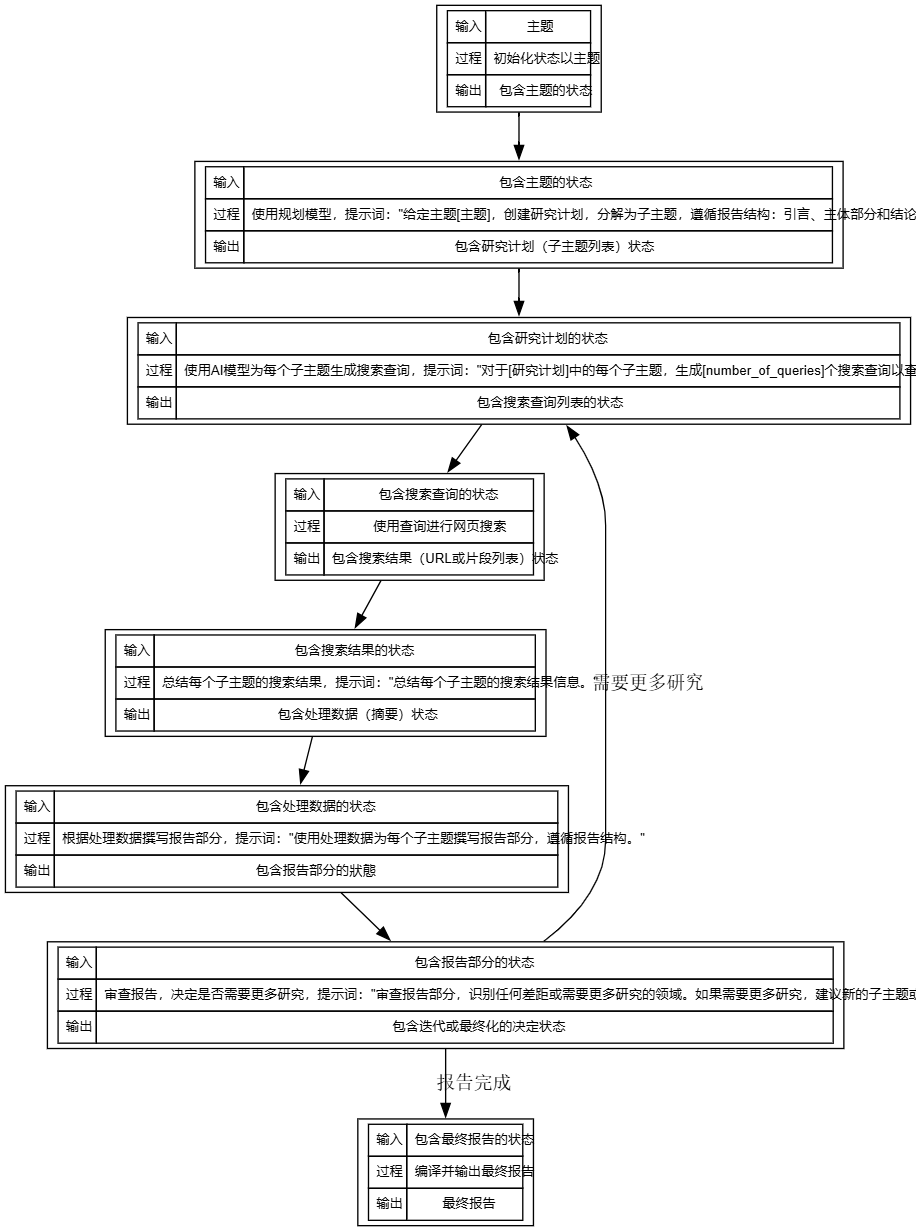
1. Initialization (Start)
- importation : User-supplied topics such as "Overview of the AI Reasoning market with a focus on Fireworks, Together.ai, Groq".
- course of events : The system initializes the state and stores the topic as part of the state without AI model calls.
- exports : Contains the status of the topic for use in subsequent steps.
2. Planning
- importation : Contains the status of the topic.
- course of events : Generate a research plan using a planning model such as the default OpenAI o3-mini or Groq's deepseek-r1-distill-llama-70b. The prompt word is: "Given a topic [theme], create a research plan, broken down into sub-topics, that follows the report structure: introduction, main body section, and conclusion."
- exports : Status updated to include research programs (list of subtopics), e.g. "1. Definition of the AI inference market; 2. Role of Fireworks; 3. TogetherA case study of .ai" and more.
- Cue word source : Presumably from the DEFAULT_REPORT_STRUCTURE of configuration.py, the structure consists of an introduction, a main body section, and a conclusion, with the main body section needing to cover key concepts, definitions, and examples.
3. Query Generation
- importation : Contains the status of the research program.
- course of events : Use the AI model to generate a search query for each subtopic with the prompt phrase: "For each subtopic in [research program], generate [number_of_queries] search queries to find relevant information." The default number_of_queries is 2.
- exports : Status updated to include list of search queries such as "AI Reasoning Market Definition 2023", "Fireworks AI Service Cases", etc.
- Cue word source : From the project documentation, it is mentioned that the number of queries can be configured, assuming that the prompt word is a generic form of the generated query.
4. Web Search
- importation : Contains the status of the search query.
- course of events : Execute each query using the search API (e.g. default Tavily) to get web search results. No AI model calls, executed directly through the tool.
- exports : The status is updated to include search results (URLs or snippet lists), such as a summary of pages returned by Tavily.
- Technical details : Dependency on tavily-python >= 0.5.0, need to configure TAVILY_API_KEY.
5. Data Processing
- importation : Contains the status of the search results.
- course of events : Use the AI model to summarize the search results for each subtopic with the prompt word: "Summarize the search result information for each subtopic."
- exports : Status updated to include processing data (summary), e.g. "AI Inference Market Definition: refers to the industry that uses AI models for real-time forecasting and is growing rapidly by 2023."
- Cue word source : Assumptions for summarizing the generic prompts for the task, based on the project objectives for generating the report.
6. Report Writing
- importation : Contains the status of the processed data.
- course of events : Use a writing model (e.g. default Anthropic). Claude 3.5 Sonnet) Write a report section based on processed data with the prompt words, "Use processed data to write a report section for each sub-theme that follows the report structure."
- exports : Status updated to include a report section, e.g., "Introduction: the AI reasoning market is an important area for AI adoption; Main body section 1: Fireworks provides efficient reasoning services, with cases including cloud deployments."
- Cue word source : In conjunction with DEFAULT_REPORT_STRUCTURE, the report needs to include an overview, key concepts and examples.
7. Reflection
- importation : Contains the status of the report section.
- course of events : Use the AI model to review the report and determine if more research is needed, with the prompt words, "Review the report section and identify any gaps or areas where more research is needed. If more research is needed, suggest new subtopics or queries."
- exports : Status updated to include iteration decision (e.g. more research needed) or final report. If iteration is needed, output new subtopics or query suggestions.
- Cue word source : Mention from the project documentation that reflection and iteration are supported, assuming the cue word is a generic form of review and recommendation.
8. Output
- importation : Contains the status of the final report (when Reflection decides the report is complete).
- course of events : Compile all report sections to generate the final report in Markdown format with no AI model calls.
- exports : Final report, e.g. full Markdown document, for users to download or view.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts




No comments...