Avoid the pit guide: Taobao DeepSeek R1 installation package paid upsell? Teach you local deployment for free (with one-click installer)

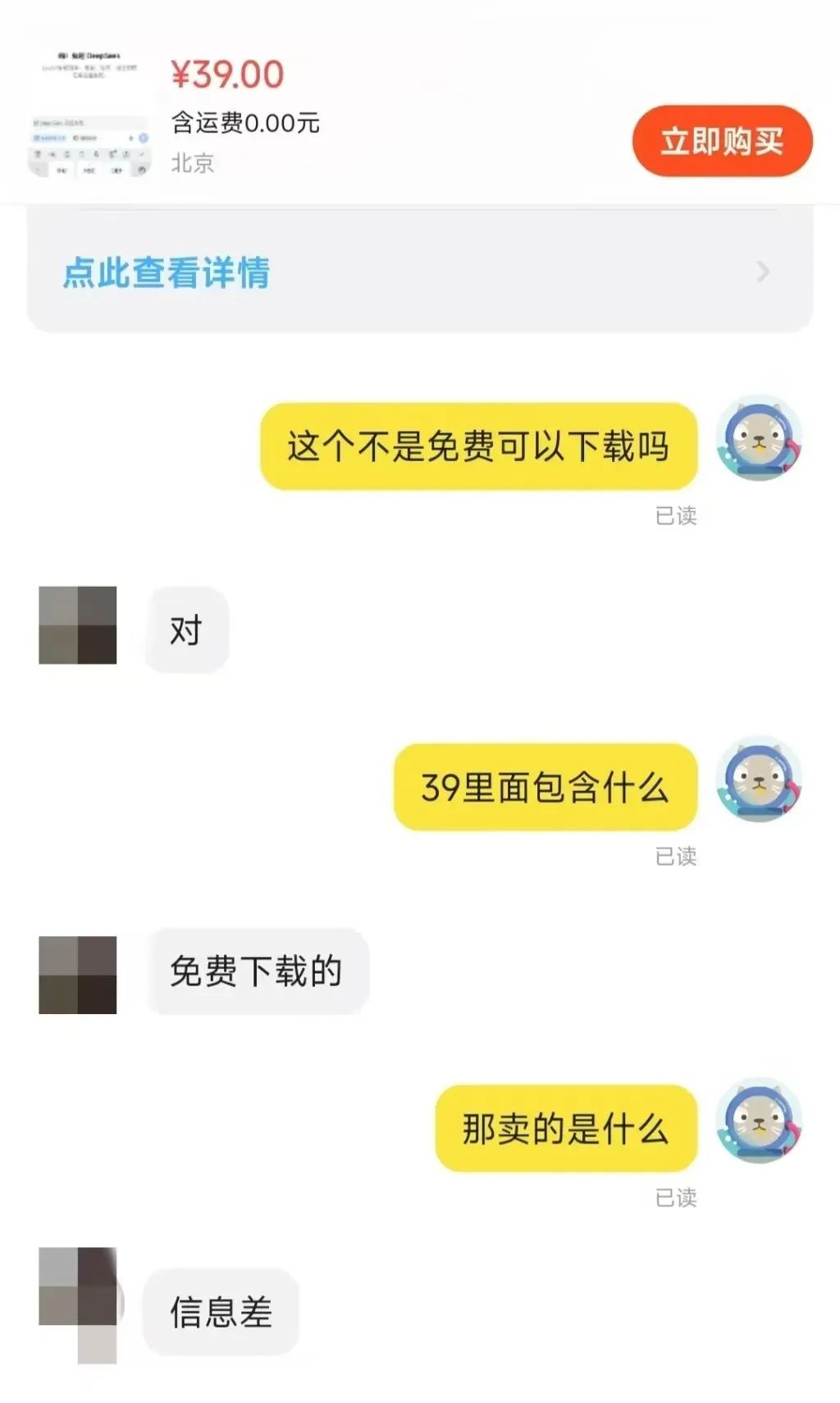
Recently, on the Taobao platform DeepSeek The phenomenon of selling installation packages has aroused widespread concern. It is surprising that some businesses are profiting from this free and open source AI model. This is also a reflection of the local deployment boom that DeepSeek models are generating.

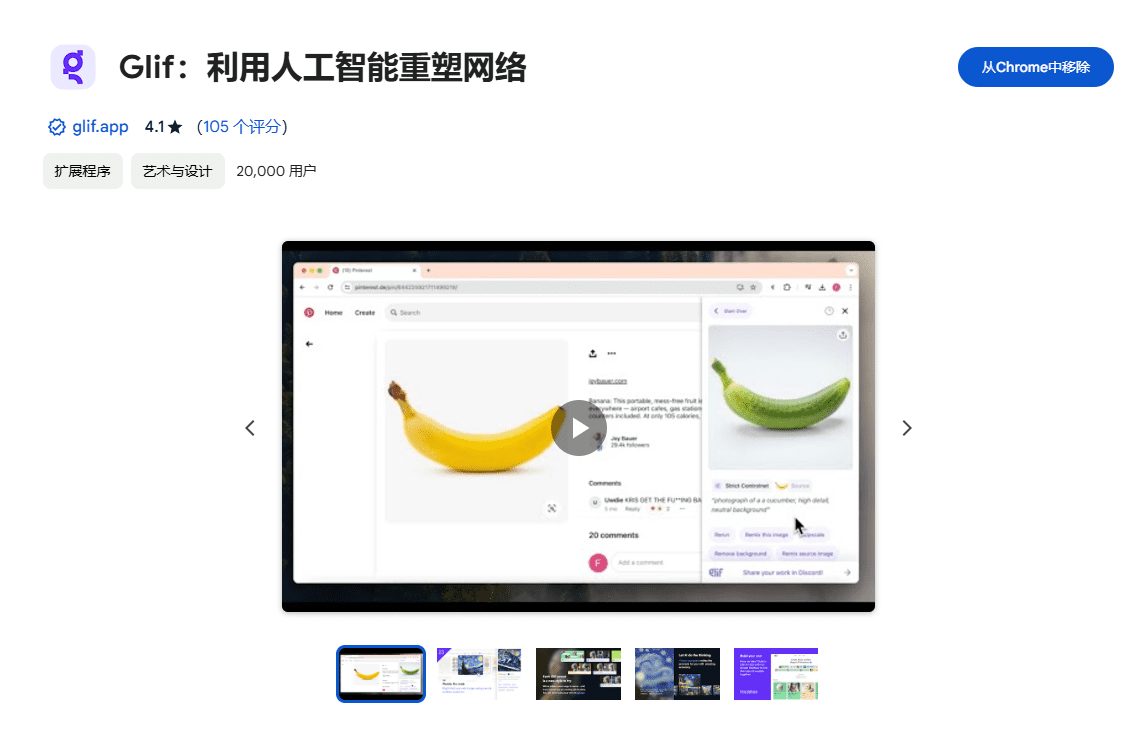
Searching for "DeepSeek" on e-commerce platforms such as Taobao and Jinduoduo, you can find many merchants selling resources that could have been obtained for free, including installation packages, cue word packages, tutorials, etc. Even some sellers have marked up DeepSeek-related tutorials. Some sellers even sell DeepSeek-related tutorials at a marked-up price, but in reality, users can easily find a large number of free download links simply by using a search engine.
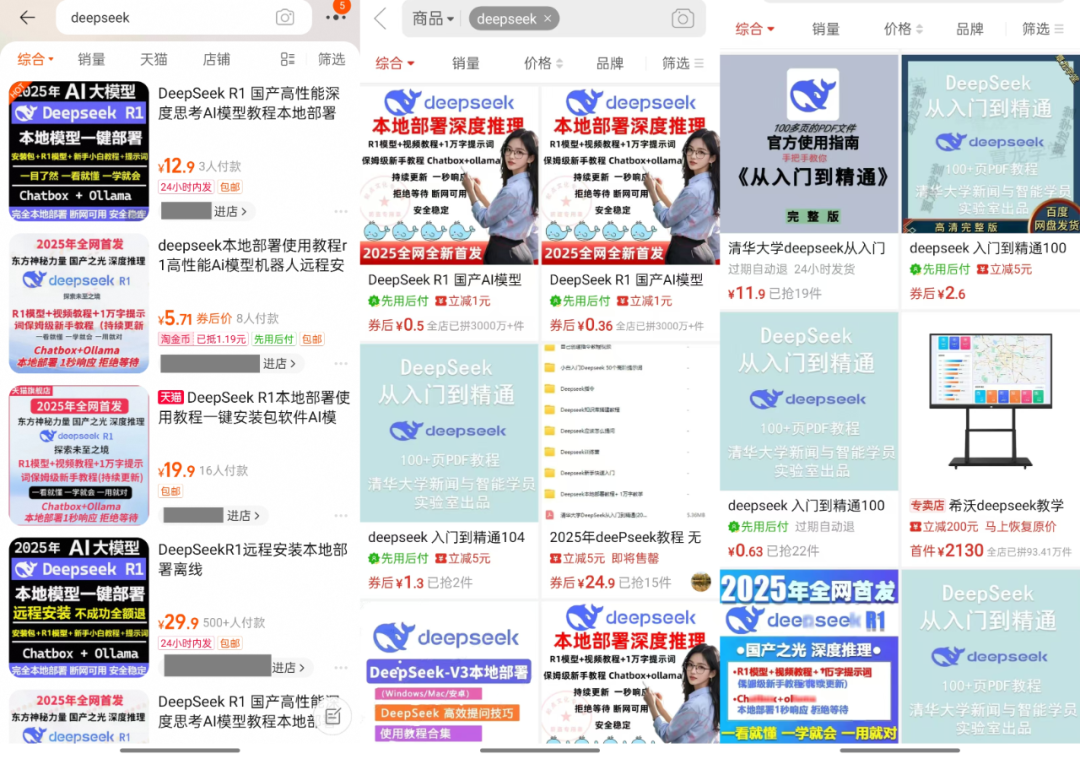
So, how much do these resources sell for? It has been observed that the package price of "installer + tutorials + tips" usually ranges from $ 10 to $ 30, and most merchants also provide a certain degree of customer service support. Among them, many commodities have been sold hundreds of copies, a few popular commodities and even достигают thousand people to pay the scale. More surprisingly, a priced $ 100 software packages and tutorials, but also 22 people choose to buy.

The business opportunities presented by the information gap are thus evident.
In this article, we will walk the reader through how to deploy a DeepSeek model on a local device at no cost at all. Before that, we will briefly analyze the need for local deployment.
Why choose to deploy DeepSeek-R1 locally?
DeepSeek-R1 models, although they may not be the top performing inference models available today, are certainly a highly coveted option in the market. However, when using the services of official or third-party hosting platforms directly, users often experience server congestion.
A local deployment model can effectively circumvent this problem. In short, local deployment means installing AI models on users' own devices, rather than relying on cloud APIs or online services. Common local deployment methods include the following:
- Lightweight Local Reasoning: Runs on a PC or mobile device, e.g. Llama.cpp, Whisper, GGUF format models.
- Server/workstation deployment: Run large models with high-performance GPUs or TPUs, such as the NVIDIA RTX 4090, A100, and more.
- Private cloud/intranet servers: Deployment on on-premises servers, e.g., using tools such as TensorRT, ONNX Runtime, vLLM, etc.
- Edge device deployment: Run AI models on embedded systems or IoT devices such as the Jetson Nano, Raspberry Pi, etc.
Different deployment methods are suitable for different application scenarios. Local deployment technologies have shown their unique value in a number of areas. for example:
- On-premises AI applications: Build private chatbots, document analysis systems, etc.
- scientific research calculations: Applied to data analysis and model training in biomedicine, physics simulation, and other fields.
- Offline AI Features: Provides speech recognition, OCR, and image processing capabilities in a network-less environment.
- Security Audit and Monitoring: To assist with compliance analysis in legal, financial and other industries.
In this article, we will focus on lightweight local inference, which is the most relevant deployment option for a wide range of individual users.
Advantages of Local Deployment
In addition to solving the root cause of the "busy server" problem, local deployment offers a number of advantages:
- Data Privacy and Security: Deploying AI models locally eliminates the need to upload sensitive data to the cloud, effectively preventing the risk of data leakage. This is critical for industries such as finance, healthcare, and legal, which require high levels of data security. In addition, local deployment also helps companies or organizations meet data compliance requirements, such as China's Data Security Law and the EU's GDPR.
- Low latency and real-time performance: Since all computations are performed locally without network requests, the inference speed depends entirely on the computational performance of the local device. Therefore, as long as the performance of the device is sufficient, the user can get excellent real-time response, which makes local deployment ideal for applications with strict real-time requirements, such as speech recognition, automated driving, industrial inspection, and so on.
- Long-term cost-effectivenessNative deployment eliminates the need for API subscription fees, enabling once-deployed, long-term use. For applications with low performance requirements, hardware costs can also be reduced by deploying lightweight models such as INT 8 or 4-bit quantization models.
- Offline AvailabilityAI models can be used normally even when there is no network connection, which is suitable for edge computing, offline office, remote environment and other scenarios. The ability to run offline also ensures the continuity of critical services and avoids business interruption due to network disconnection.
- Highly customizable and controllable: Local deployment allows users to fine-tune and optimize the model to better suit specific business needs. For example, the DeepSeek-R1 model has spawned numerous fine-tuned and distilled versions, including the unrestricted version deepseek-r1-abliterated. In addition, local deployments are not affected by third-party policy changes, providing greater control and avoiding potential risks such as API price adjustments or access restrictions.
Limitations of local deployment
The advantages of local deployment are significant, but the limitations are not negligible, the main challenge being the computational power requirements of large models.
- Hardware cost inputs: Individual users often have difficulty running models with large parameter sizes smoothly on their local devices, while models with smaller parameters may have compromised performance. Therefore, users need to weigh the cost of hardware against the performance of the model. The pursuit of high-performance models inevitably requires additional hardware investment.
- Large-scale task processing capability: When faced with tasks that require large-scale data processing, server-level hardware support is often required to accomplish them effectively. Personal devices have a natural bottleneck in processing power.
- technological threshold: Compared to the convenience of cloud services, which can be used by simply visiting a web page or configuring an API, there is a technical barrier to local deployment. If users need to further fine-tune their models, deployment will be even more difficult. Thankfully, the technical barriers to local deployment are gradually being lowered.
- maintenance cost: Upgrades and iterations of the model and associated tools may cause environment configuration issues that require user time and effort for maintenance and problem solving.
Therefore, the choice of local deployment or online model needs to be considered according to the user's actual situation. The following is a brief summary of scenarios where local deployment is and is not applicable:
- Scenarios suitable for local deployment: High privacy requirements, low latency requirements, long-term use (e.g., enterprise AI assistants, legal analytics systems, etc.).
- Scenarios not suitable for local deployment: Short-term test validation, high arithmetic requirements, reliance on very large models (e.g., 70B+ parameter level).
Private deployment using free servers in the cloud is also a good way to go, and was recommended a long time ago, but it requires a certain technical base:Deploying DeepSeek-R1 Open Source Models Online with Free GPU Computing Power
DeepSeek-R1 Local Deployment in Action
There are many ways to deploy DeepSeek-R1 locally, but in this article, we will present two simple options: based on the Ollama deployment methods and zero-code deployment scenarios using LM Studio.
Option 1: Deploy DeepSeek-R1 based on Ollama
Ollama is the dominant framework for deploying and running native language models. It is lightweight and highly scalable, and has risen to prominence since the release of Meta's Llama family of models. Despite its name, the Ollama project is community-driven and not directly related to the development of Meta and the Llama family of models.

The Ollama project is growing rapidly, and the variety of models and ecosystems it supports is expanding rapidly.
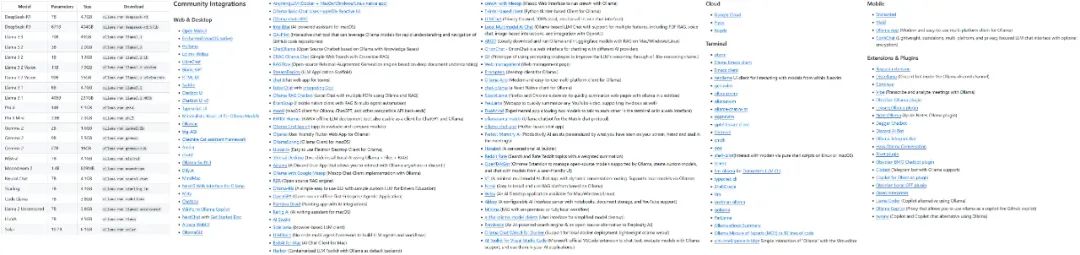
Some of the models and ecologies supported by Ollama
The first step in using Ollama is to download and install the Ollama software. Visit the official Ollama download page and select the version that matches your operating system.
Download: https://ollama.com/download
After installing Ollama, you need to configure the AI model for the device. Let's take DeepSeek-R1 as an example. Visit the model library on the Ollama website to browse the supported models and versions:
https://ollama.com/search
DeepSeek-R1 is available in 29 different versions of the Ollama model library in scales ranging from 1.5B to 67B, including versions fine-tuned, distilled or quantized based on the open-source models Llama and Qwen.
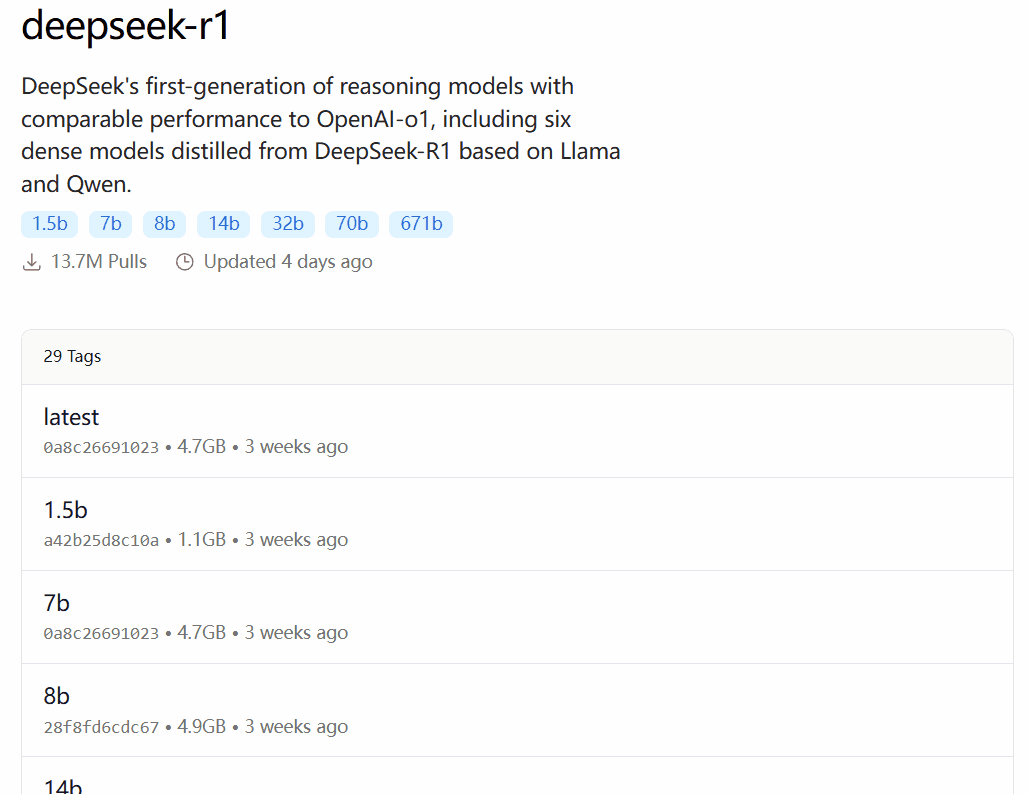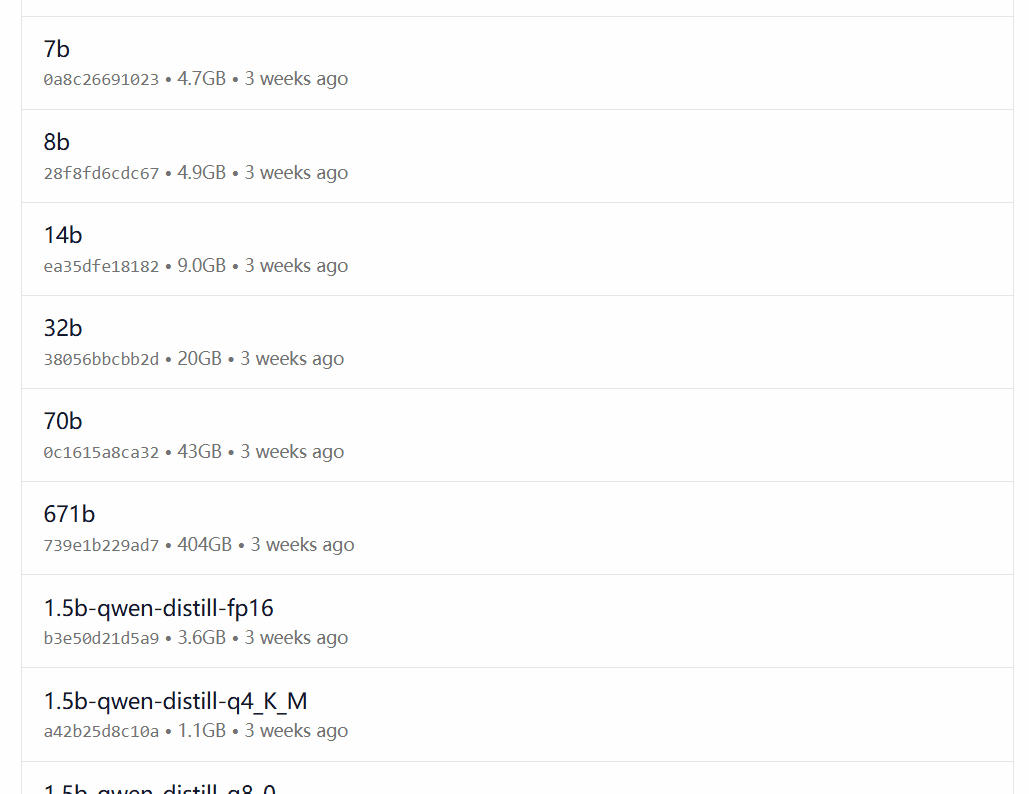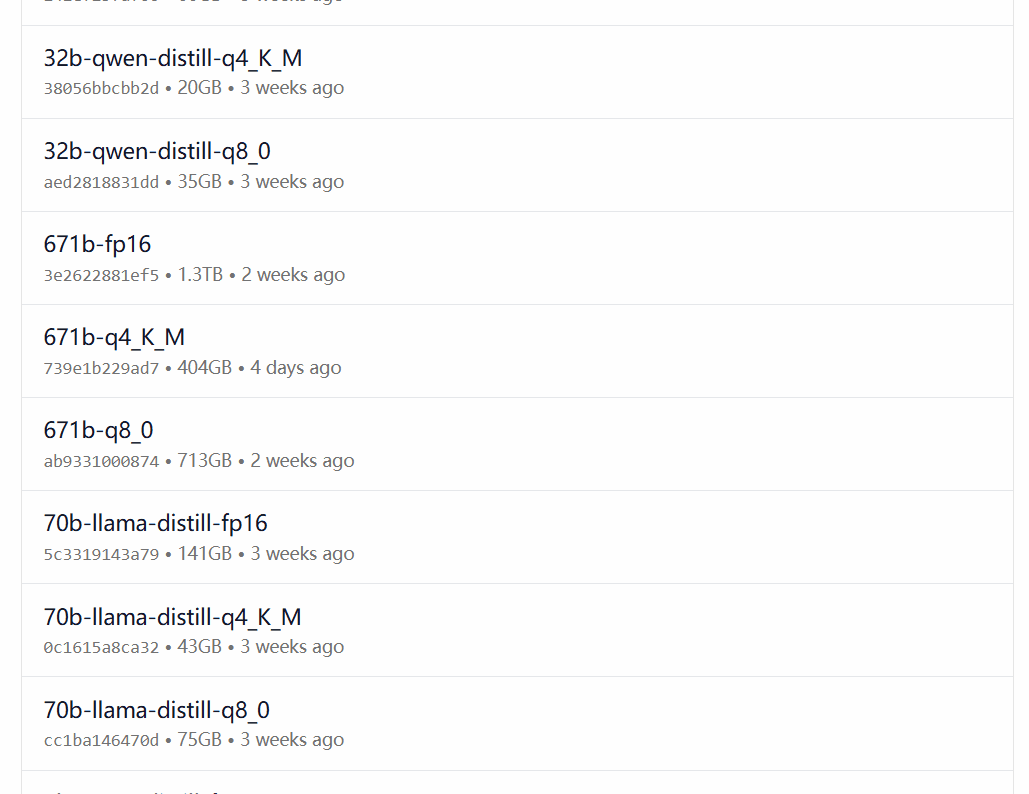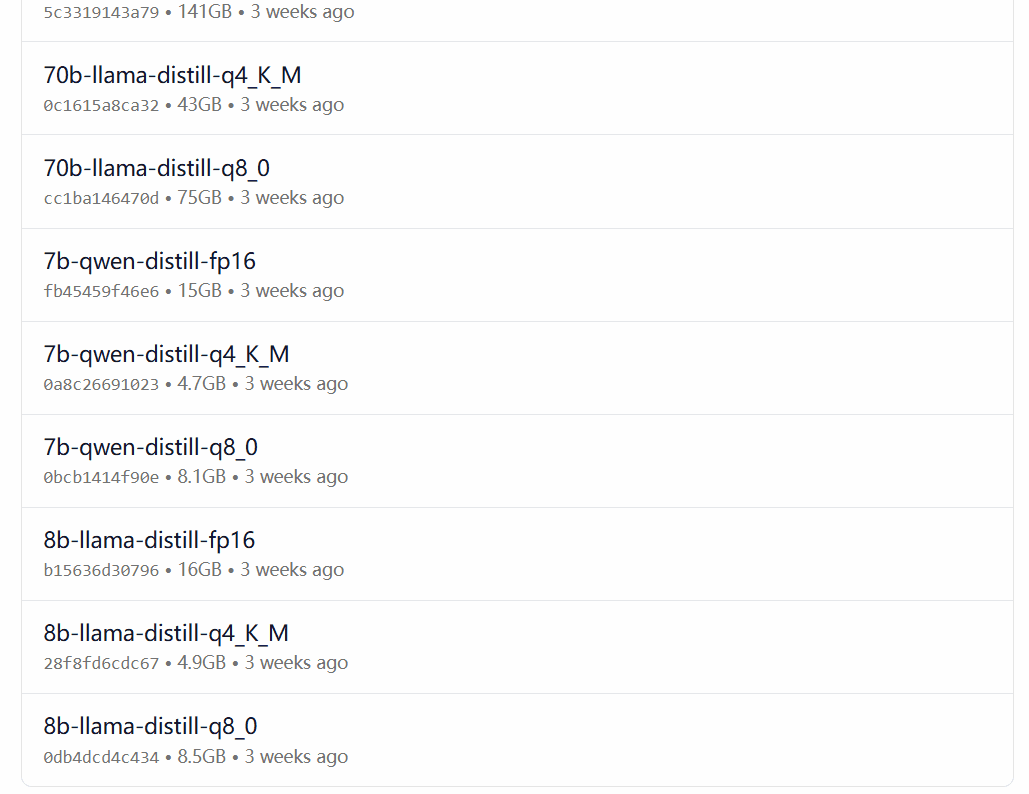
Which version to choose depends on the user's hardware configuration. Avnish from the dev.to developer community has written an article summarizing the hardware requirements for different sized versions of DeepSeek-R1:
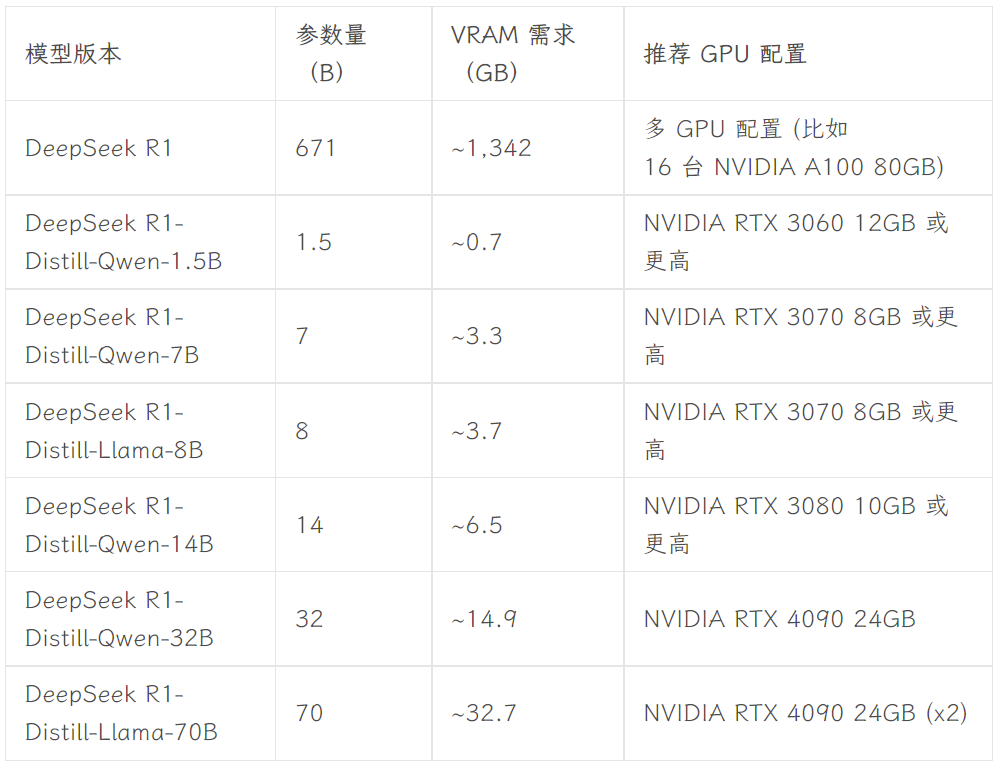
Image source: https://dev.to/askyt/deepseek-r1-architecture-training-local-deployment-and-hardware-requirements-3mf8
This article takes version 8B as an example for demonstration. Open the device terminal and run the following command:
ollama run deepseek-r1:8b
Next, just wait for the model to finish downloading. (Ollama also supports downloading models directly from Hugging Face, with the command ollama run hf.co/{username}/{library}:{quantized version}, e.g. ollama run hf.co/bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0.)

Once the model is downloaded, you can talk to the 8B version of DeepSeek-R1 in the terminal.

However, for the average user, this type of terminal dialog is not intuitive and easy to operate. Therefore, a user-friendly graphical interface front-end is required. There is a wide range of front-end options, such as Open WebUI Getting something like ChatGPT The interactive experience can also be selected from Chatbox and other desktop applications. More front-end options can be found in the official Ollama documentation:
https://github.com/ollama/ollama
- Open WebUI
If you choose Open WebUI, simply run the following two lines of code in the terminal:
Install Open WebUI:
pip install open-webui
Run the Open WebUI service:
open-webui serve
After that, visit http://localhost:8080 in your browser to experience the ChatGPT-like web interface. In the model list of Open WebUI, you can see several models that have been configured by local Ollama, including DeepSeek-R1 7B and 8B versions, and other models such as Llama 3.1 8B, Llama 3.2 3B, Phi 4, Qwen 2.5 Coder, etc. Select the DeepSeek-R1 8B model for testing. The DeepSeek-R1 8B model is chosen for testing:

- Chatbox
If you prefer to use a standalone desktop application, you can consider tools such as Chatbox. The configuration steps are equally simple, starting with downloading and installing the Chatbox application:
https://chatboxai.app/zh
After launching Chatbox, enter the "Settings" interface, select OLLAMA API in "Model Provider", and then select the model you want to use in the "Model" column. Then select the model you want to use in the "Model" field, and set the parameters such as the maximum number of context messages and Temperature according to your needs (you can also keep the default settings).

Once configured, you can have a smooth conversation with the locally deployed DeepSeek-R1 model in Chatbox. However, the test results show that the DeepSeek-R1 7B model is slightly underperforming when processing complex commands. This confirms the previous point that individual users can usually only run models with relatively limited performance on local devices. However, it is foreseeable that as hardware technology continues to evolve, the barriers to using large-parameter models locally will be lowered even further in the future - and that day may not be too far away.

**Both Open WebUI and Chatbox support access to DeepSeek's models, ChatGPT, and Claude via APIs, Gemini and other business models. Users can use them as a front-end interface for everyday use of AI tools. In addition, models configured in Ollama can be integrated into other tools, such as Obsidian and note-taking applications like Civic Notes.
Option 2: Deploy DeepSeek-R1 with zero code using LM Studio
For users who are not familiar with command line operation or code, you can use LM Studio to realize zero-code deployment of DeepSeek-R1. First, visit the LM Studio official download page to download the program that matches your operating system:
https://lmstudio.ai
Start LM Studio after the installation is complete. In the "My Models" tab, set the local storage folder for the models:

Next, download the required language model files from Hugging Face and place them in the above folder according to the specified directory structure (LM Studio has a built-in model search function, but it doesn't work well in practice). Note that you need to download the model files in .gguf format. For example Unsloth A collection of DeepSeek-R1 models provided by the organization:
https://huggingface.co/collections/unsloth/deepseek-r1-all-versions-678e1c48f5d2fce87892ace5
Considering the hardware configuration, in this paper, we choose the DeepSeek-R1 Distillate version (14B parameter number) based on the fine-tuning of the Qwen model, and the 4-bit quantization version: DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf.
After the download is complete, place the model files in the folder you set up according to the following directory structure:
Model folder /unsloth/DeepSeek-R1-Distill-Qwen-14B-GGUF/DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf
Finally, open LM Studio and select the model you want to load at the top of the application interface to talk to your local model.

The biggest advantage of LM Studio is that it is completely zero-code, there is no need to use a terminal or write any code - just install the software and configure the folders, which is very user-friendly.
summarize
The tutorials provided in this article only provide a basic level of local deployment of DeepSeek-R1. Deeper integration of this popular model into local workflows requires more detailed configuration, such as setting up system prompts, and more advanced model fine-tuning, RAG Integration, search function, multimodal capabilities and tool invocation capabilities. At the same time, as AI-specific hardware and small-model technologies continue to evolve, I believe the barriers to deploying large models locally will continue to drop in the future. After reading this article, are readers willing to try to deploy DeepSeek-R1 models on their own?
Attached DeepSeek R1+OpenwebUI one-click installation package
The one-click installation package provided by Sword27 integrates specifically for DeepSeek the Open WebUI
DeepSeek local deployment of one-click run, unpacked to use Support 1.5b 7b 8b 14b 32b, minimum support for 2G graphics cards
Installation process
1.AI environment download: https://pan.quark.cn/s/1b1ad88c7244
2. Download the installation package: https://pan.quark.cn/s/7ec8d85b2f95
Get help in the original article: https://www.jian27.com/html/1396.html
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles

No comments...