
Local Deployment QwQ-32B Large Model: Easy to follow guide for PCs

The field of Artificial Intelligence (AI) modeling is always full of surprises, and every technological breakthrough can pull the nerves of the industry. Recently, Alibaba's QwQ team released its latest inference model, QwQ-32B, in the wee hours of the morning, which once again attracted a lot of attention.

According to the official releaseQwQ-32B is an inference model with a parameter size of only 32 billionBut he claimed to be able to rival DeepSeek-R1 and other industry-leading, cutting-edge models. The announcement was a bombshell that instantly set the tech community ablaze, with links to the official blog, Hugging Face model library, model downloads, online demos, and a website for users to learn more about the product and experience it.
Although the release information is brief and concise, the technical strength behind it is far from simple. The phrase "32 billion parameters comparable to DeepSeek-R1" is impressive enough, knowing that, in general, the larger the number of parameters of a model, the stronger its performance tends to be, but it also means higher demand for computing resources. QwQ-32B Achieving a performance similar to that of the mega-model with a small number of parameters is undoubtedly a major breakthrough, which has naturally stirred strong interest among technology enthusiasts and professionals.
In order to demonstrate the performance of QwQ-32B more intuitively, an official benchmark test chart has been made public simultaneously. Benchmarking is an important means of evaluating the capabilities of an AI model. It measures the model's performance on different tasks by testing it on a series of preset, standardized datasets, thus providing users with an objective performance reference.

From this benchmarking chart, we can quickly capture the following key points of information:
- Phenomenal spreading speed: The model release information достига́ть has been read by more than 1.69 million people in just 12 hours, which fully reflects the market's urgent demand for high-performance AI models and the high expectation for QwQ-32B.
- Excellent performance: With only 32 billion parameters, QwQ-32B is able to compete with the full-parameter version of DeepSeek-R1, which has a parameter count of 671 billion, in the benchmark test, showing an amazing energy-efficiency ratio. This phenomenon of a small model outperforming a large model definitely breaks the traditional perception of the relationship between model performance and parameter size.
- Outperforms distillation models in its class: QwQ-32B significantly outperforms the 32B distillation version of DeepSeek-R1. Distillation is a model compression technique designed to mimic the behavior of a larger model by training a smaller model, thereby reducing computational cost while maintaining performance. The fact that QwQ-32B outperforms the 32B distillation model further demonstrates the sophistication of its architecture and training methodology.
- Multi-dimensional performance leadership: QwQ-32B outperforms OpenAI's closed-source model, o1-mini, in several benchmark dimensions. This shows that QwQ-32B is capable of competing with the top closed-source models in terms of generalization.
Of particular interest is the fact that QwQ-32B, with only 32 billion parameters, is able to outperform giant models with more than 20 times the number of parameters, which represents another leap forward in AI technology. Even more exciting, users can now easily run the quantized version of QwQ-32B locally with an RTX3090 or RTX4090-class consumer graphics card. Local deployment not only lowers the barrier to use, but also opens up more possibilities for data security and personalized applications. For users with lower graphics card performance, they can try to get started with the recommended cloud deployment option:Deploying DeepSeek-R1 Open Source Models Online with Free GPU Computing Power, or apply directly to use the free API.Alibaba (volcano) provides 1 million tokens per day (for 180 days), while the Akash The API is free to use directly without registration.
DeepSeek is no longer a one-trick pony, so how does OpenAI stay on top?
With the QwQ-32B showing such strong competition, OpenAI's existing products, both the $200 Pro version and the $20 Plus version, face a serious challenge in terms of price/performance. The QwQ-32B has given the market something to think about, especially in light of the performance fluctuations that OpenAI models sometimes exhibit, which users have criticized as a "smart downgrade. Nonetheless, OpenAI still has a deep accumulation and extensive ecosystem in the AI field, and it may still have an advantage in fine-tuning models and application optimization in specific areas. However, the release of QwQ-32B undoubtedly breaks the original pattern of the market, forcing all players to re-examine their technical advantages and market strategies.
In order to more fully evaluate QwQ-32B's real-world capabilities, it is necessary to install it locally and test it in detail, especially to examine its reasoning performance and "IQ" level in a local operating environment.
Fortunately, thanks to the Ollama With the advent of tools such as Ollama, deploying and running large language models locally on personal computers has now become very simple. Ollama, an open source lightweight model running framework, greatly simplifies the process of deploying and managing large local models.
Ollama is recognized for its efficiency and ease of use. Shortly after the release of the QwQ-32B, Ollama quickly announced support for the model, further lowering the barrier for users to experience the latest AI technology and making it easy for everyone to get started with the power of the QwQ-32B.
1. Installation and operation of Ollama
First, visit the official Ollama website at ollama.com and click the Download button to download the appropriate installation package for your operating system.
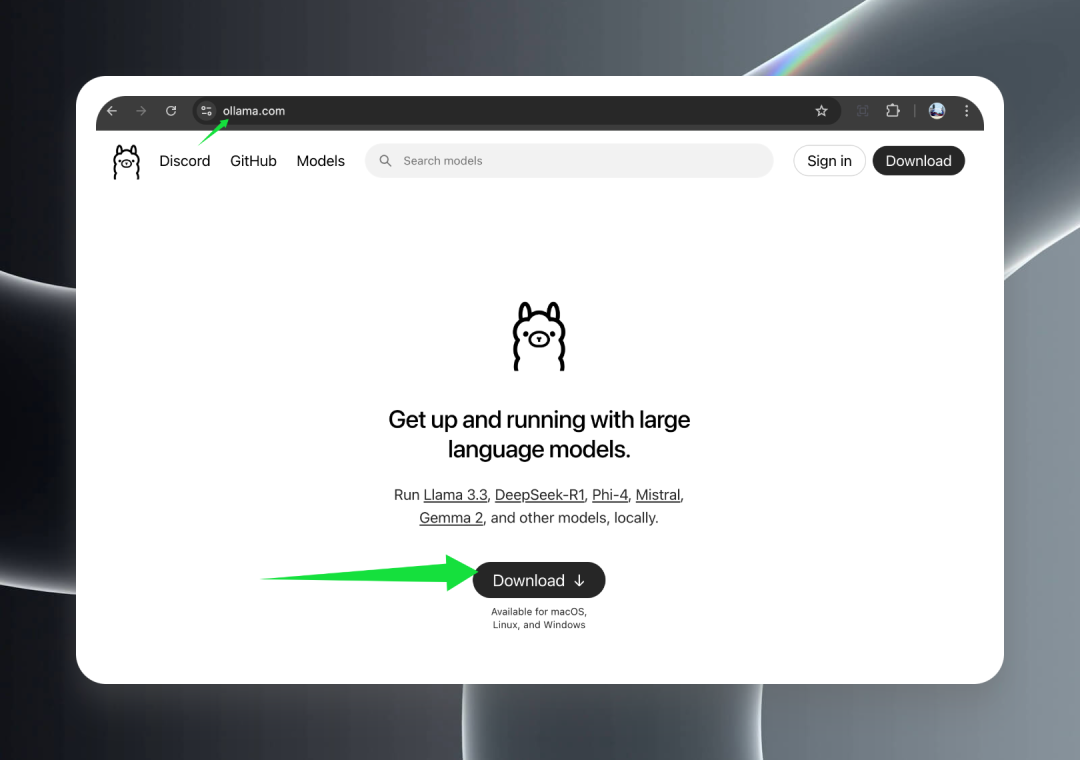
Ollama provides full support for all major operating systems including macOS (Intel and Apple Silicon), Windows, and Linux, ensuring that the QwQ-32B model can be easily utilized on a variety of platforms.
Once the download is complete, double-click on the installer and follow the wizard to complete the installation process. After successful installation, you will see a cute alpaca icon in the taskbar tray on Windows or in the menu bar on macOS, indicating that Ollama has been successfully launched and is running in the background, ready to serve you.
2. Download of the QwQ-32B model
Must Read:Unsloth solves duplicate inference problem in quantized version of QwQ-32B
After successfully installing and running Ollama, you can now start downloading the QwQ-32B model.

Open the Ollama client in the Models On the Models page, you will see that the QwQ-32B model has quickly climbed to the top of the Hot Models list, which is a testament to its popularity. Find the "qwq" model entry and click on it to go to the model details page. On the details page, copy the commands highlighted in the red border.
Open a local terminal (macOS/Linux) or command prompt (Windows).
In a terminal or command prompt, paste and execute the following command:ollama run qwq
ollama run qwq
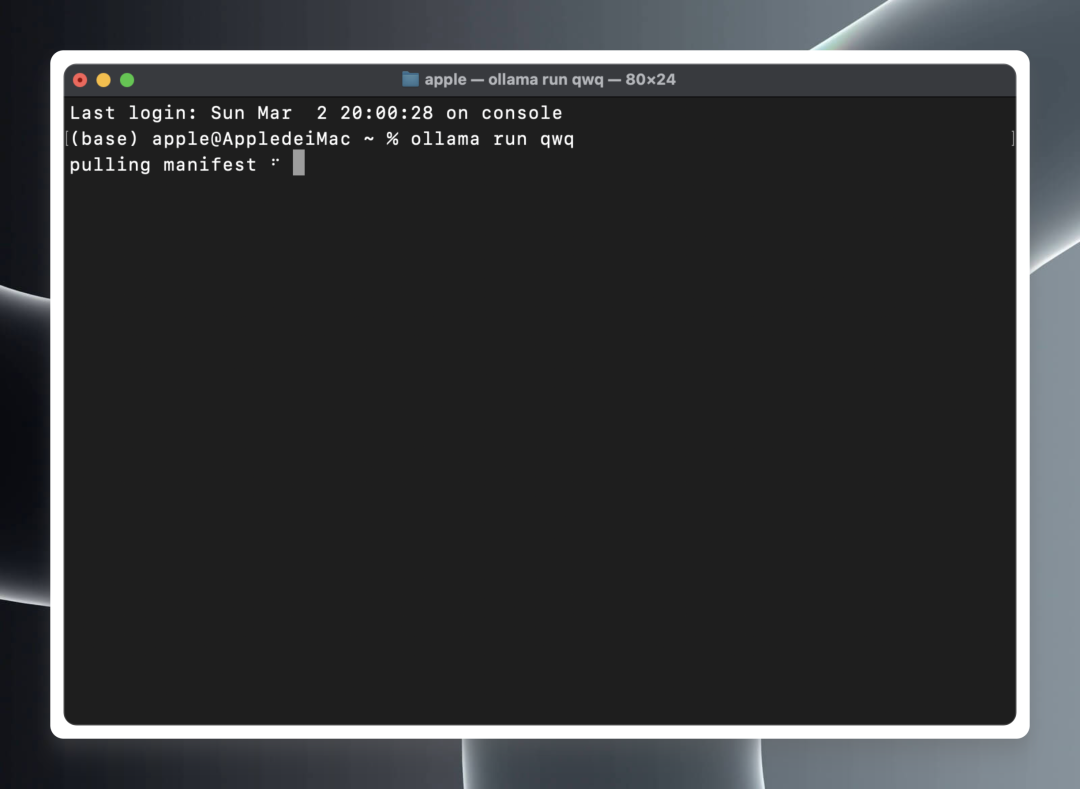
Ollama will automatically begin downloading the QwQ-32B model files from the cloud and will automatically start the model runtime environment when the download is complete.
It is worth noting thatThe model download process does not appear to require additional network configuration on the part of the user. This is undoubtedly a very friendly feature for domestic users. After all, a model file that is nearly 20GB in size will greatly reduce the user experience if the download speed is too slow or requires a special network environment.
However, since the QwQ-32B model is currently very popular and there are many users downloading it, the actual download speed may be affected to some extent, resulting in a longer download time, which requires users to be patient.
After a while of waiting, the model was finally downloaded. I ran the QwQ-32B model on a computer equipped with an RTX3060 desktop-grade graphics card with 12GB of video memory to try it out, and was pleasantly surprised: not only did the model load successfully, but it was also able to give smooth answers based on the user's inputs, and, more importantly, there were no video memory overflow problems throughout the entire process. More importantly, there is no memory overflow problem during the whole process. This means that even mainstream graphics cards can meet the requirements of the QwQ-32B quantization model.

In terms of actual inference performance, QwQ-32B's ability has already surpassed some OpenAI models that users jokingly refer to as "IQ underline". This also confirms the superiority of QwQ-32B in terms of performance.
Through Windows Task Manager, we can monitor the resource utilization of the model in real time. The results show that the CPU, memory, and video memory are all under high load during the model inference process, which also reflects the high hardware resource requirements for running large models locally.
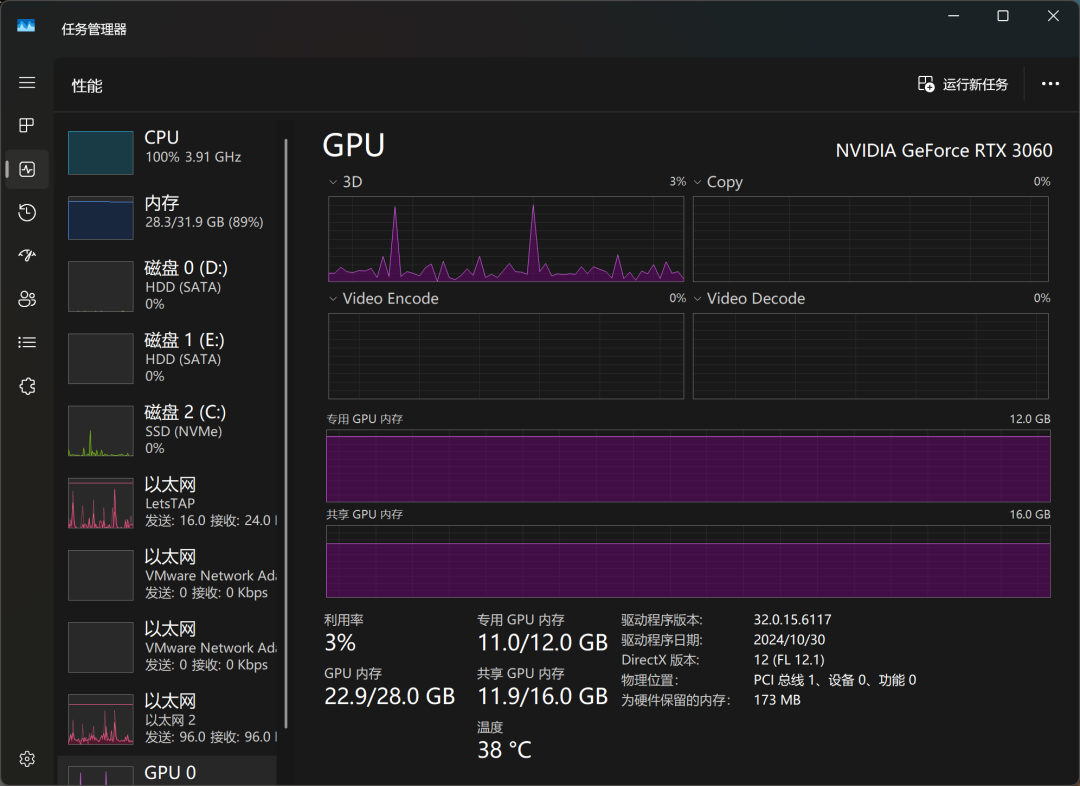
On RTX3060 graphics card, QwQ-32B answers at about "da, da, da, da..." tempo, which can satisfy the basic usage needs, but there is still room for improvement in terms of responsiveness and smoothness. If you are looking for a more extreme local model running experience, you may need a higher level of hardware configuration.
In order to further improve the running speed of the model, I downloaded and ran the QwQ-32B model again on a device equipped with a top-of-the-line RTX3090 graphics card. The experimental results show that after replacing the higher-end graphics card, the running speed of the model has been significantly improved, and it is not an exaggeration to describe it as "as fast as flying". This also reaffirms the importance of hardware configuration to the local large model running experience.
3. Integration of QwQ-32B into clients
While talking to the model directly from the command line interface is a simple and direct way, for users who need to use it frequently or seek a better interaction experience, using a graphical client is definitely a more convenient choice. There are many excellent AI model client software on the market, and we have already introduced many of them, such as ChatWise. The main reason for choosing ChatWise is its simple and intuitive interface design, clear and easy-to-understand operation logic, and its ability to provide users with a good experience.
The following outlines the steps to configure a QwQ-32B model to the ChatWise client.
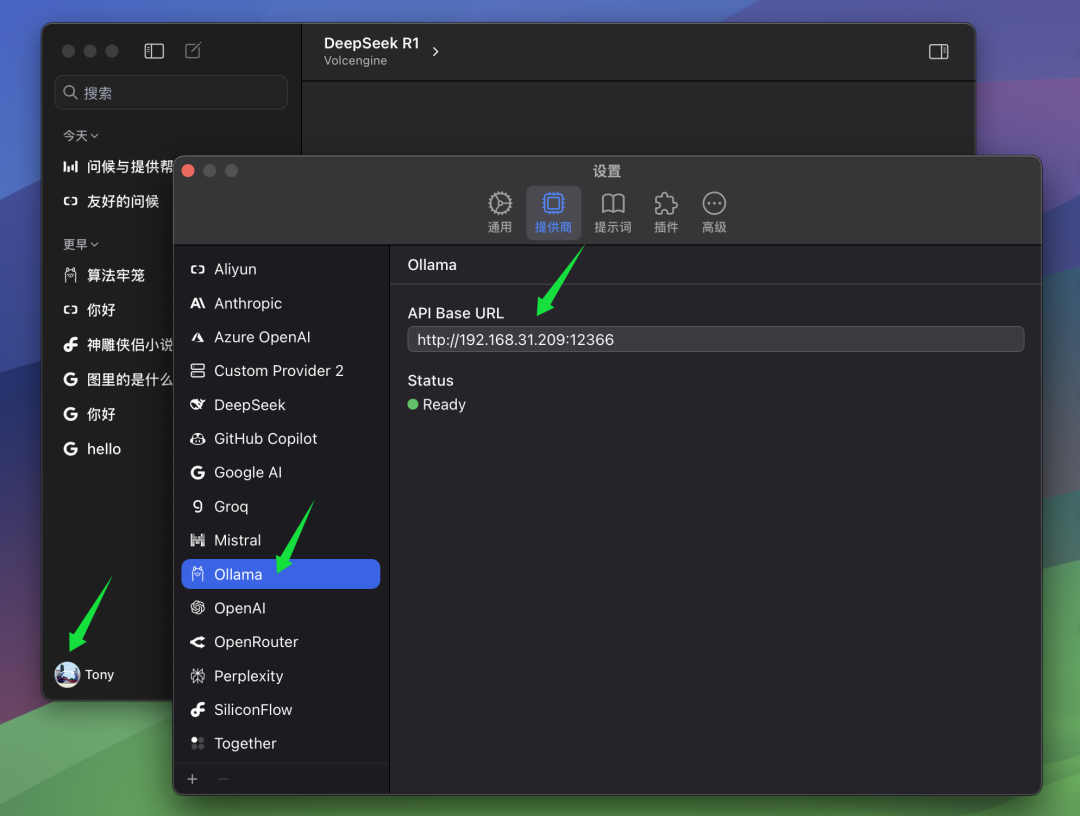
If your ChatWise client and the Ollama service are running on the same computer, you can usually open the ChatWise client and use the QwQ-32B model directly without any additional configuration. This is the case for most users, i.e. both the Ollama service and the client application are installed on the same device.
However, if you, like the author, have installed the Ollama service on another computer (e.g. a server) and the ChatWise client is running on your local computer, you will need to manually modify ChatWise's BaseURL settings so that clients can connect to the remote Ollama service. In the BaseURL In the settings, you need to fill in the IP address of the computer running the Ollama service, and the port number you configured on the Ollama server. The default port for Ollama is 13434, so if you have not configured it specifically, you can just use the default port.
fulfillment BaseURL Once configured, you can select the model you want to use in the ChatWise client.
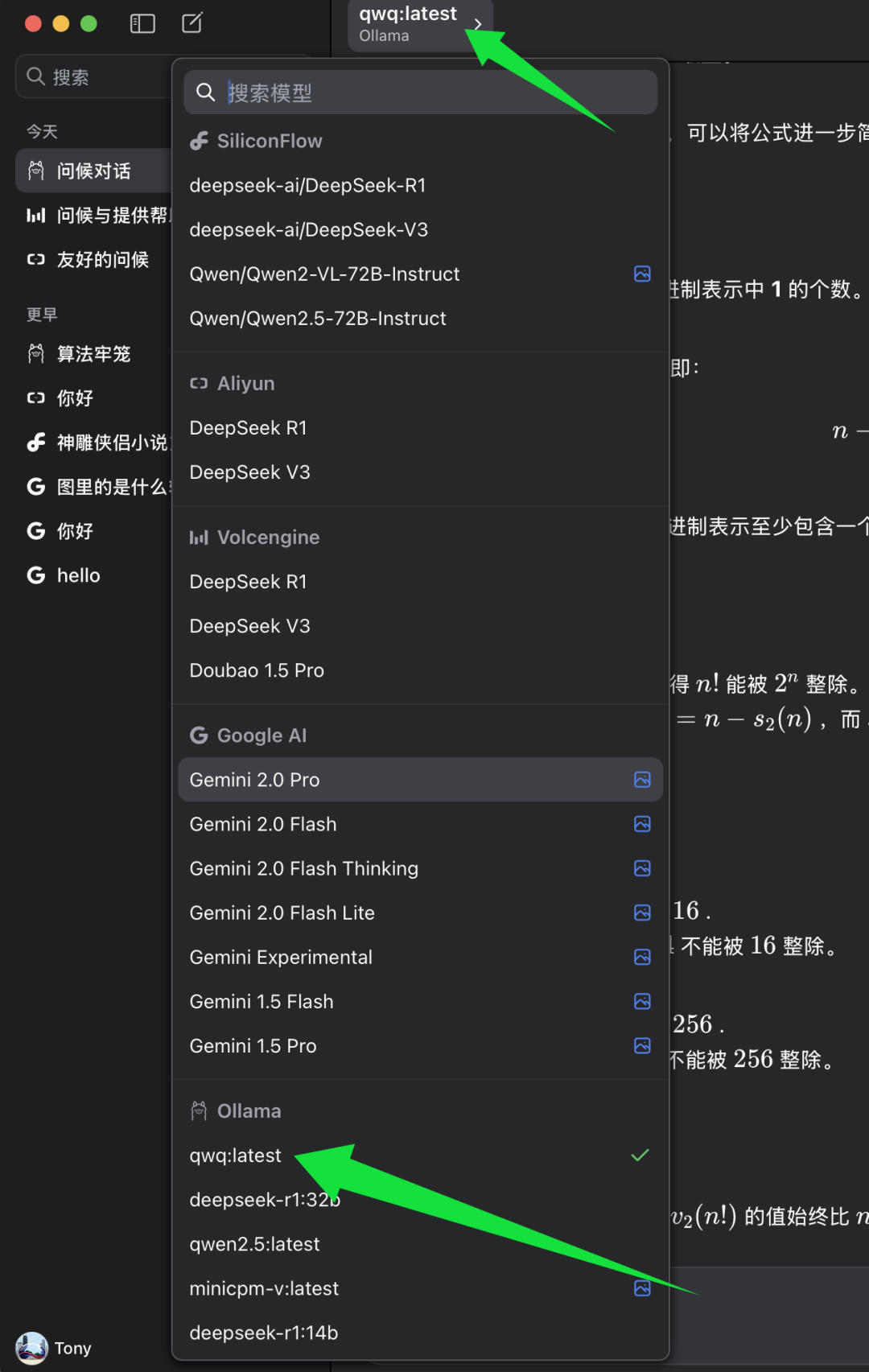
In ChatWise's model selection list, find the Ollama model category and below it select the qwq:latestThe qwq:latest Represents the latest version of the QwQ-32B model, and usually the 4-bit quantized version. Select qwq:latest After that, you can start experiencing the power of the QwQ-32B model in the ChatWise client.
4. QwQ-32B model intelligence level test
In order to assess the intelligence level of the QwQ-32B model more objectively, we used a set of classic questions that were previously summarized when testing the OpenAI model for "reduced intelligence". This set consists of four carefully selected questions, which empirically show that if the ChatGPT (especially for GPT-3 or GPT-4 models), it is often difficult to answer these questions correctly when there is user feedback of "reduced intelligence". Therefore, this set of questions can be used to some extent as a reference for testing the intelligence level of the larger models.
Next, we will test the locally run QwQ-32B model one by one to see if it can successfully answer all the questions.
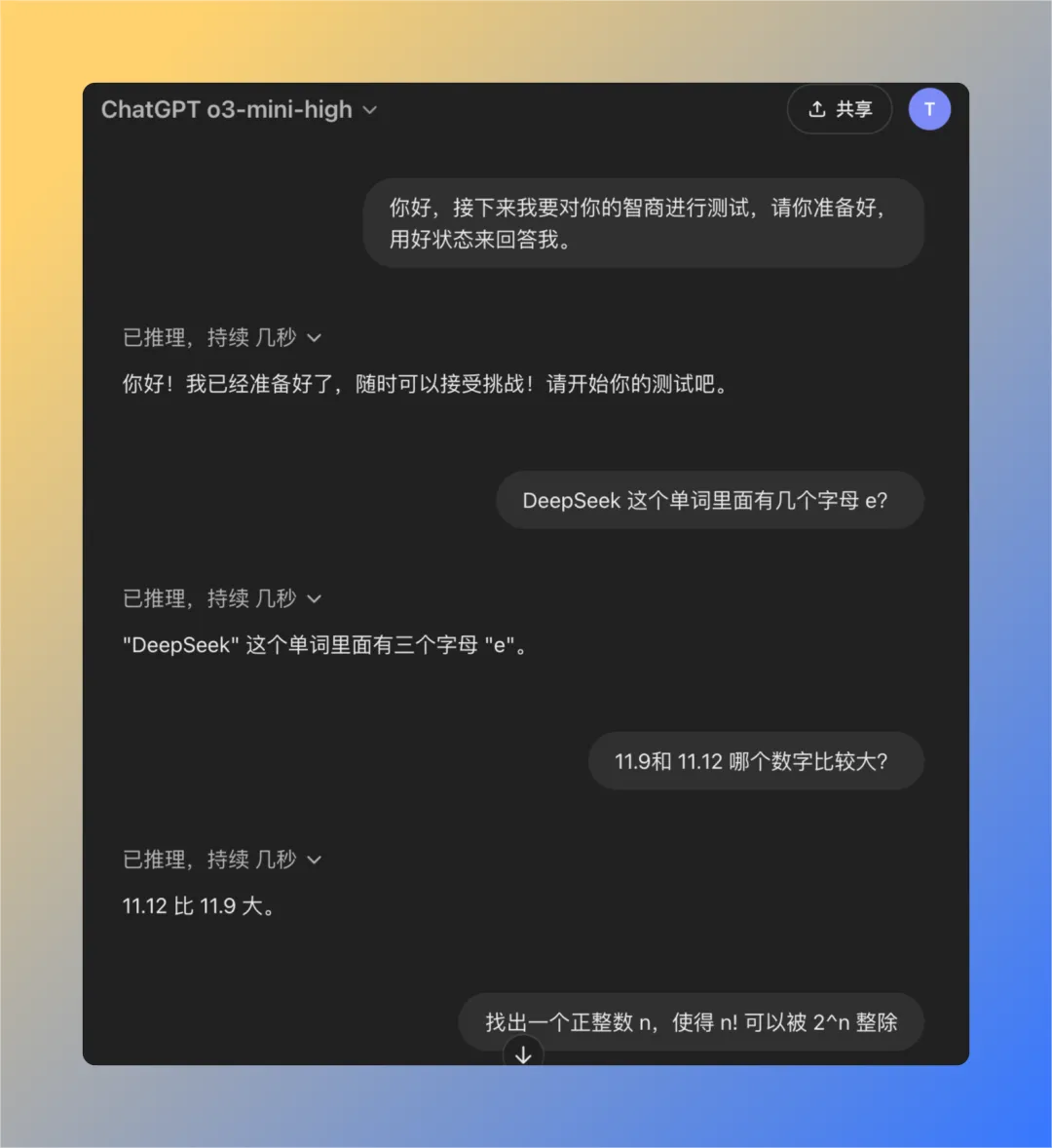
Question 1: How many letters of the letter e are in the word deepseek?
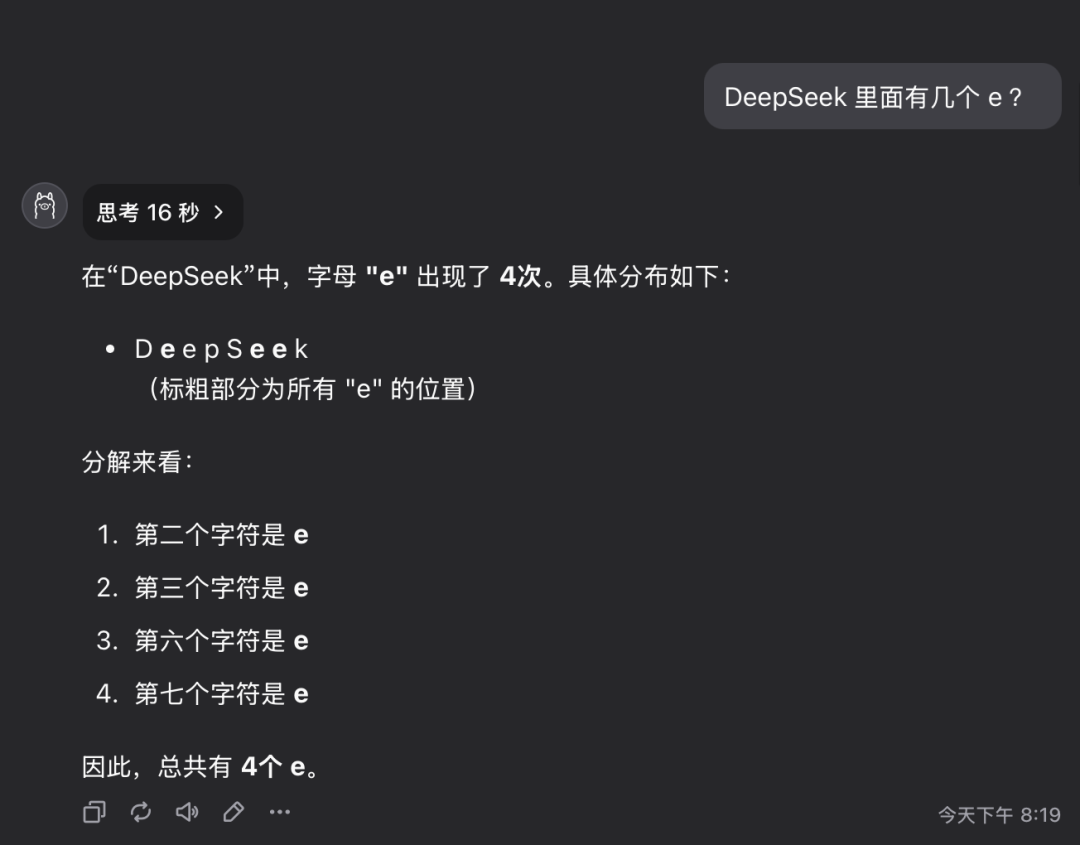
The QwQ-32B model gave the correct response in 16 seconds: 3. The answer is correct.The
This question may seem simple, but it actually examines the model's ability to accurately understand and extract detailed information. Surprisingly, there are still a significant number of large models that are unable to accurately answer such questions.
Question 2: Which value is greater, 11.9 or 11.12?

The QwQ-32B model gave the correct answer in 47 seconds: 11.12 is bigger. The answer is correct.The
Again, this is a seemingly basic but classic problem. Many large models are confused or misjudge simple numerical comparisons, reflecting possible deficiencies in the underlying logical reasoning of the model.
Problem 3: Find a positive integer n such that the factorial of n (n!) is divisible by the nth power of 2 (2^n).

The QwQ-32B model gives the correct answer in 121 seconds: no such positive integer n exists. The answer is correct.The
The point of this question is not to find a specific numerical answer, but to examine whether the model has the ability to think abstractly and reason logically, to understand the nature of the problem, and ultimately to reach the conclusion that "it does not exist." QwQ-32B was able to answer this question correctly, demonstrating some ability in logical reasoning.
Problem 4: Classic Logic Reasoning - Hat Color Puzzle
"There are 5 people lined up in a row and each of them is wearing a hat on their head, which may be red or blue in color. Each person can only see the color of the hat of the person in front of them in the line, but not the color of the hat on their own head. The facilitator tells the group in advance, "Of these 5 people, there is at least one red hat." Now, starting with the person at the end of the line and moving forward in order, ask each person, "Do you know what color your hat is?" Each person can only answer "yes" or "no." Assuming that the fifth person answers "No" and the fourth person answers "Yes," what is the distribution of all possible hat colors?"
Compared to the first three questions, this logical reasoning question was significantly more difficult and demanded more logical analysis and reasoning skills from the model.
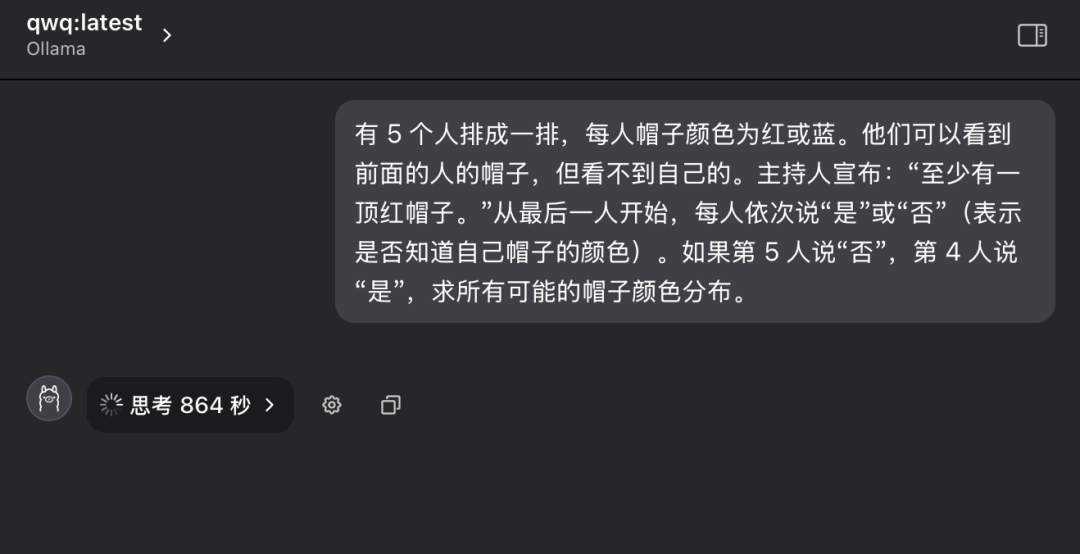
During the first questioning, the QwQ-32B model went into a state of prolonged thinking, with the words "Thinking..." flashing on the screen, as if the "brain" was running at a high speed, making people worry whether the hardware could withstand such an intense computational load. One may even worry whether the hardware can withstand such an intense computational load. Considering the time and the hardware running condition, after more than ten minutes of waiting, I manually interrupted the model thinking process.
The author then reopened a new dialog session to ask the QwQ-32B model the same questions again.

This time, the QwQ-32B model finally gave a completely correct answer after 196 seconds and explained the reasoning in detail. The answer is correct.The
By looking at the model's reasoning process record, we can feel that despite the relatively small parameter size of QwQ-32B, it still shows a very "hard" thinking and analyzing process when facing complex logical reasoning problems. The model performs a lot of logical operations and probability deduction in the background before finally arriving at the correct conclusion.
After the above series of rigorous and detailed intelligence tests, we can preliminarily conclude that the quantized version of the QwQ-32B 4-bit model has already shown impressive comprehensive performance, especially in logical reasoning and knowledge quiz, which exceeds the performance of other models in the same class. From this, we have reason to believe that the performance of the unquantized version of QwQ-32B will be even better. 32B Full Blood Edition Model Performance Evaluation Report QwQ-32B provides more comprehensive performance data and analysis. Therefore, we can basically judge that the performance publicity made by Alibaba's QwQ team when the QwQ-32B model was released was not overstated, and that QwQ-32B is indeed an excellent new inference model, which, with a parameter scale of 32 billion parameters, realizes the strength of competing head-to-head with the DeepSeek-R1 model with 671 billion parameters.
The rapid rise of domestic open source models fully demonstrates China's vigorous innovation and huge development potential in the field of AI technology.
What's even better is that the QwQ-32B 32B version of the model requires only a graphics card with 24GB of video memory to run it smoothly and at an impressive speed. While a few years ago it would have required millions of dollars in specialized equipment to run such a high-performance large-scale model, now, thanks to advances in technology such as QwQ-32B and Ollama, users can deploy and experience it locally on a $10,000 PC. The release of the QwQ-32B model signals the accelerated popularization of high-performance AI models, and the era of "AI for All" is approaching at an accelerated pace, and high-performance AI technology will have a broader application outlook for personal terminal devices and various industries.
Now is the best time to take action to explore and fully utilize the power of the QwQ-32B! Let's embrace the bright future of AI technology together!
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles




No comments...