91Writing - Open Source AI Intelligent Novel Creation Platform
91 Writing is a fully open source AI novel creation tool, developed based on Vue 3 and Element Plus, integrating a variety of advanced AI models, such as GPT, Claude, Gemini, and so on. The tool provides creators with a complete creation tool chain from idea to text, including project creation...

MIT's new report, "The Generative AI Divide: the State of Business AI in 2025
MIT's latest report, The Generative AI Divide: the State of Business AI in 2025, reveals the core of the generative AI (GenAI) adoption process that companies are experiencing through in-depth research of more than 300 AI projects, interviews with 52 organizations, and a survey of 153 executives...
AutoClip - Open source AI video slicing tool to generate thematic video collections with one click
AutoClip is open source AI video editing tool, based on advanced AI technology to realize the whole process of automated video processing. Tools can automatically identify the highlights of the video, accurate extraction of valuable content, can be based on the similarity of the theme of intelligent clustering, to generate a collection of content.AutoClip support...

Hands-On AI: Artificial Intelligence Liberalization and Practice - Free AI Liberalization Course by AliCloud
Hands-On Learning AI: Artificial Intelligence General Knowledge and Practice" of AliCloud, in conjunction with Superstar Erlang, is a systematic learning course on AI for learners of different professional backgrounds. The course is taught by master teachers from five top universities, with comprehensive content, from the development history of AI, core technology to ethical security, etc., to build a complete body of knowledge...

Seed-OSS - A new AI model open-sourced by the Wordpress team
Seed-OSS is a large family of language models open-sourced by the Byte Jump Seed team, focusing on long text and reasoning tasks. The model performs well in complex logical reasoning and multi-step reasoning, with high accuracy and efficient problem solving.Seed-OSS supports long text contexts up to 512K...
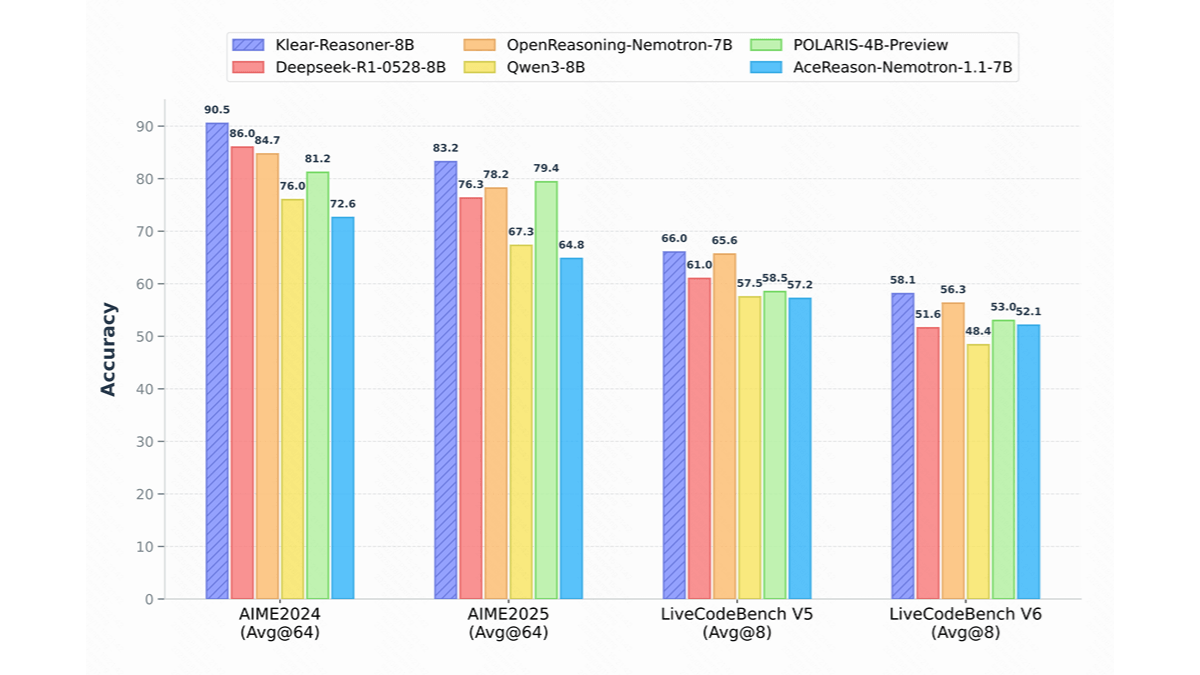
Klear-Reasoner - The New Reasoning Model Introduced by Racer
Klear-Reasoner is a high-performance inference model from Racer, based on Qwen3-8B-Base. The model is trained by long thought chain supervised fine-tuning and reinforcement learning to perform well in mathematical and code reasoning.Klear-Reasoner...

CombatVLA - Efficient VLA Model by Amoy Group
CombatVLA is an innovative 3D action role-playing game (ARPG)-specific model from the Future Life Lab team of the Amoy Sky Group.CombatVLA is a visual-linguistic-action (VLA) model, built on a 3B parametric scale, that collects human player's through a motion tracker...

DeepSeek V3.1 - Latest Open Source AI Models from DeepSeek
DeepSeek V3.1 is a new generation of AI models introduced by DeepSeek, with important upgrades based on its predecessor, V3. DeepSeek V3.1 introduces a hybrid reasoning architecture that allows the model to flexibly switch between thinking and non-thinking modes, significantly improving the thinking...

Qwen-Image-Edit - Ali Tongyi open source image editing model
Qwen-Image-Edit is an all-purpose image editing model introduced by Ali Tongyi, built on the Qwen-Image architecture with 20 billion parameters. The model combines both semantic and appearance editing capabilities, and can perform low-level visual appearance editing on images (e.g., adding, deleting...

MoE-TTS - The Latest Speech Generation Framework from KunlunWei
MoE-TTS is a speech synthesis framework introduced by KunlunWanwei, based on the Mixed Expert (MoE) architecture, which combines pre-trained Large Language Models (LLMs) with speech expert modules.MoE-TTS retains the powerful textual reasoning by freezing the textual module parameters and updating only the speech module parameters...