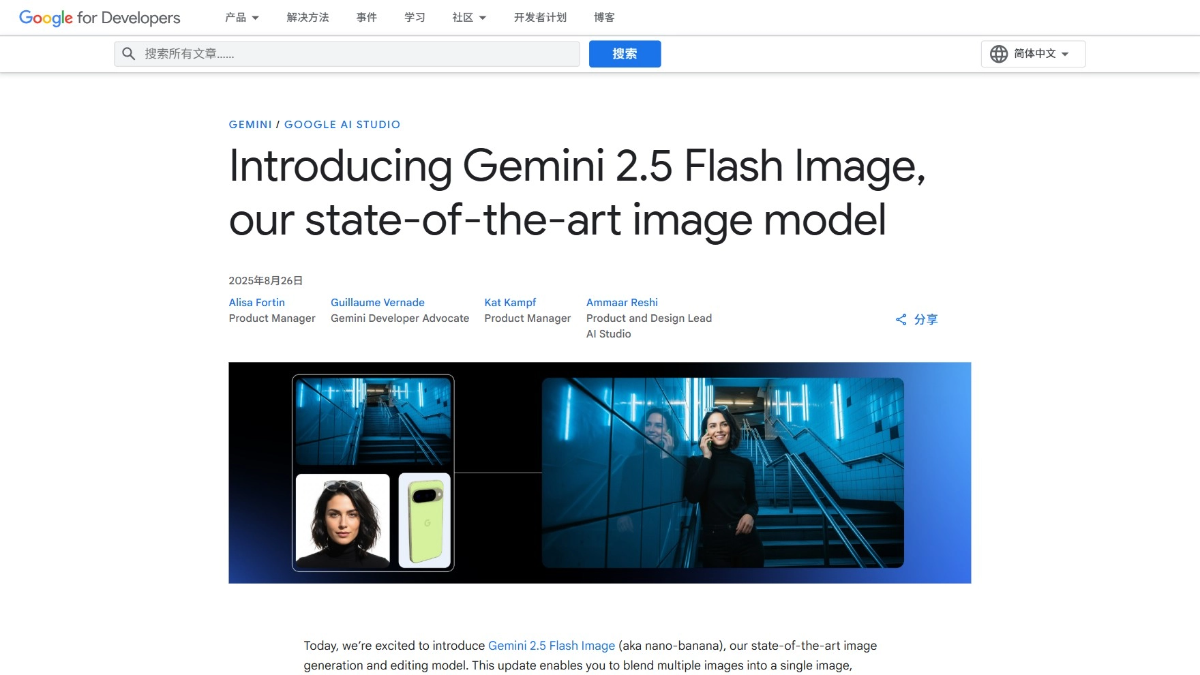
Gemini 2.5 Flash Image - The Most Powerful Image Generation and Editing Model from Google
Gemini 2.5 Flash Image (codename nano banana) is a state-of-the-art image generation and editing model from Google that maintains the consistency of characters across different scenes and supports precise image editing through natural language, such as blurring backgrounds and removing stains.

Wan2.2-S2V - Ali Tongyi open source audio-driven video generation model
Wan2.2-S2V is Ali Tongyi open source multimodal video generation model , only a static picture and a piece of audio , you can generate high-quality digital human video , and supports a variety of image types and frame .
Free Course on ChatGPT Tip Engineering for Developers by Ernest Ng
ChatGPT Tip Engineering for Developers is a joint DeepLearning.AI and OpenAI course designed for developers, featuring Isa Fulford, Andrew Ng to teach how to use Large Language Models (LLMs...
Ask Whitey o4 - A parallel thinking model introduced by Ask Whitey that opens 8 thinking paths at the same time
Ask White o4 is an innovative parallel thinking model that opens 8 thinking paths at the same time, analyzes the problem from multiple perspectives and automatically filters out the optimal solution. The model incorporates advanced Long-CoT reinforcement learning and process reward learning techniques, has powerful deep reasoning capabilities, and performs well in complex tasks.
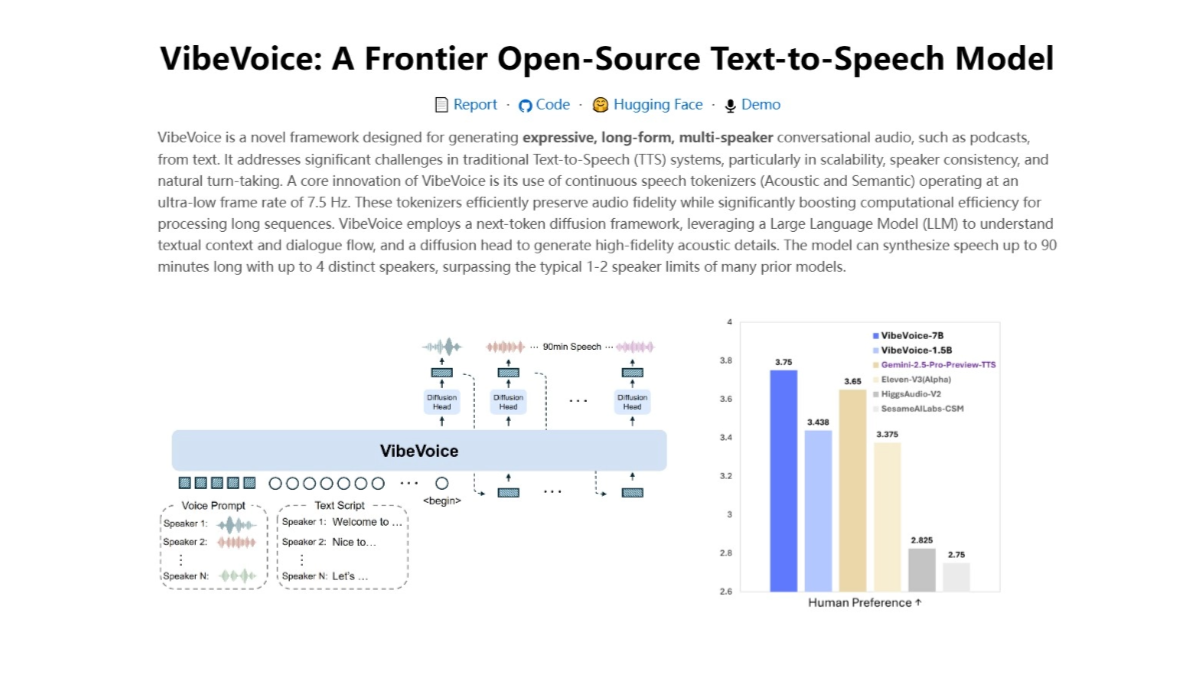
VibeVoice - Text-to-Speech Model from Microsoft
VibeVoice is a new text-to-speech (TTS) model from Microsoft. The model generates conversational audio from up to four different speakers and supports up to 90 minutes of continuous voice output, breaking the length limitations of traditional TTS systems.

SpatialGen - Open Source 3D Scene Generation Model by Qunar Technology
SpatialGen is an open source 3D scene generation model of Qunar Technology, based on the diffusion model architecture, supporting the generation of spatio-temporally consistent multi-view images based on textual descriptions, reference images and 3D spatial layouts, and further generating 3D Gaussian scenes and rendering roaming videos.

EchoMimicV3 - Ant open source multimodal digital human animation generation model
EchoMimicV3 is a multimodal digital human video generation model introduced by Ant Group, with 1.3 billion parameters, capable of handling multiple inputs such as audio, text, images, etc. to generate high-quality digital human animations.
What are the best AI essay writing tools? 15 Recommended Free AI Academic Essay Assistants
In the era of booming artificial intelligence, AI tools have changed our lives and greatly boosted academic research and paper writing. In order to help users work and study more efficiently, this compilation carefully selects and introduces 15 cutting-edge free AI academic paper assistants.

Fun-ASR - A New Generation of Speech Recognition Models Jointly Launched by Nail and Tongyi
Fun-ASR is a big model of speech recognition jointly launched by Nail and Tongyi Labs. The model has been trained with massive audio data and can accurately recognize multi-industry terminology, such as Internet, technology, home decoration, etc., significantly improving the recognition accuracy. The model combines with Nail enterprise information for inference optimization to reduce the illusion problem...
Squibler - AI novel-assisted writing platform that facilitates the entire process from idea to creation
Squibler is a powerful AI-assisted writing platform designed for writers that helps users with the entire process from conception to creation to publication. The platform provides a variety of story templates covering novels, screenplays, short stories, etc. Users only need to enter the initial concept, and the AI can generate outlines, characters, scenes...