StartAI - AI painting software, based on Adobe Photoshop, offering a wide range of drawing features.
StartAI is an Adobe Photoshop-based AI painting software designed for designers and creative workers. The software is based on AI technology to improve design efficiency and stimulate creativity, and supports text-based drawing, partial redrawing, line coloring, non-destructive zoom, high-definition restoration and other...
Inter AI - AI drawing platform, supports Chinese and English bilingual text to generate images
Inter-Italian AI is the leading AI drawing and design customization platform that supports bilingual input and contains 400+ models and 100,000 drawing styles. Users input text descriptions or upload images to quickly generate images that meet their requirements.

Metamirror - AI video creation tool with automatic script generation
Metamirror is an AI video creation tool based on the human-computer symbiosis engine, which supports efficient creation from creative inspiration to finished video. The tool is equipped with automated script generation, character style unification, multimodal fusion and intelligent workflow, etc. It can quickly generate creative video scripts, multimodal split-screen design, and synthesize the complete video with one key...
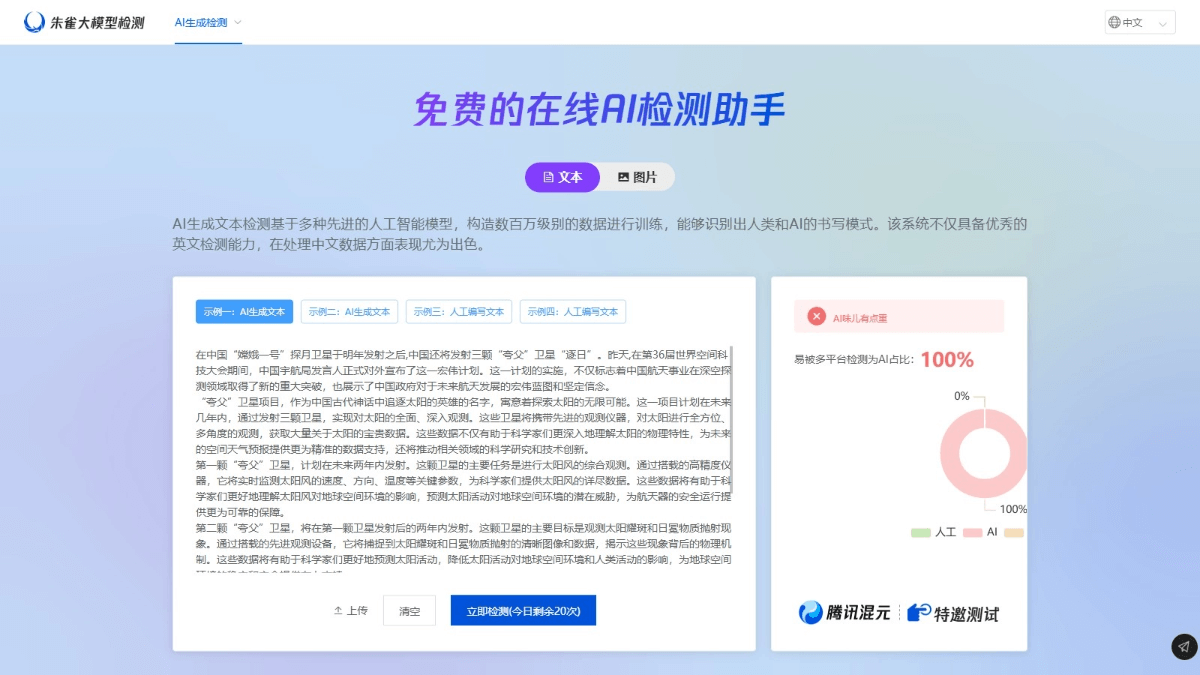
Jubilee AI Inspection - AI image and text inspection platform launched by Tencent
Vermilion Bird AI Detection is an AI detection platform launched by Tencent's hybrid security team, Vermilion Bird Labs, to help users identify AI-generated images and text content. Vermilion Bird AI detection is based on analyzing the hidden features of images, content that does not conform to common sense logic, and "watermark" logos, etc., to quickly determine whether an image is generated by AI.
Mr. ZJU - AI Intelligent Body Platform Launched by ZJU with DeepSeek Integration
Mr. Zhejiang University is a platform for deeply integrated intelligences launched by Zhejiang University, based on DeepSeek V3 and R1 models, relying on CARSI resource sharing platform, providing free services for teachers and students of Zhejiang University as well as teachers and students of 829 CARSI-allied universities across the country.
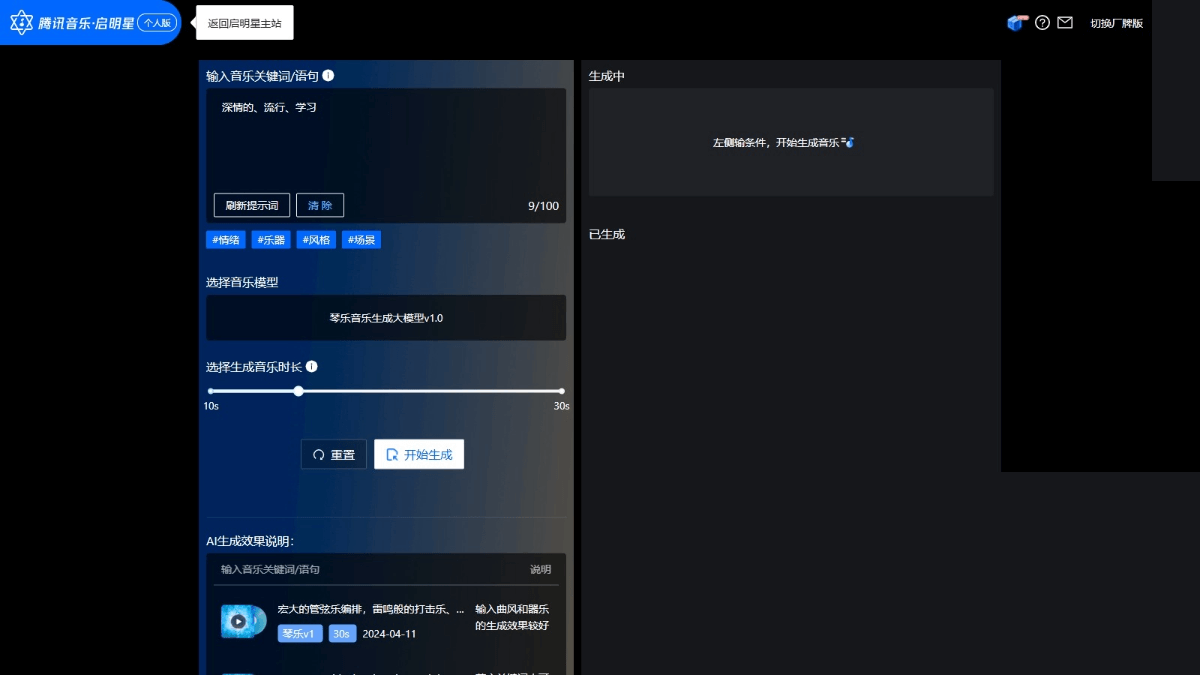
Piano Music Big Model - AI Music Composition Model by Tencent
Qin Music Grand Model is an advanced AI music creation grand model jointly launched by Tencent AI Lab and Tencent TME Tianqin Lab. The model intelligently generates high-quality stereo audio or multi-track sheet music based on user-inputted keywords, descriptive statements or audio clips in English and Chinese.
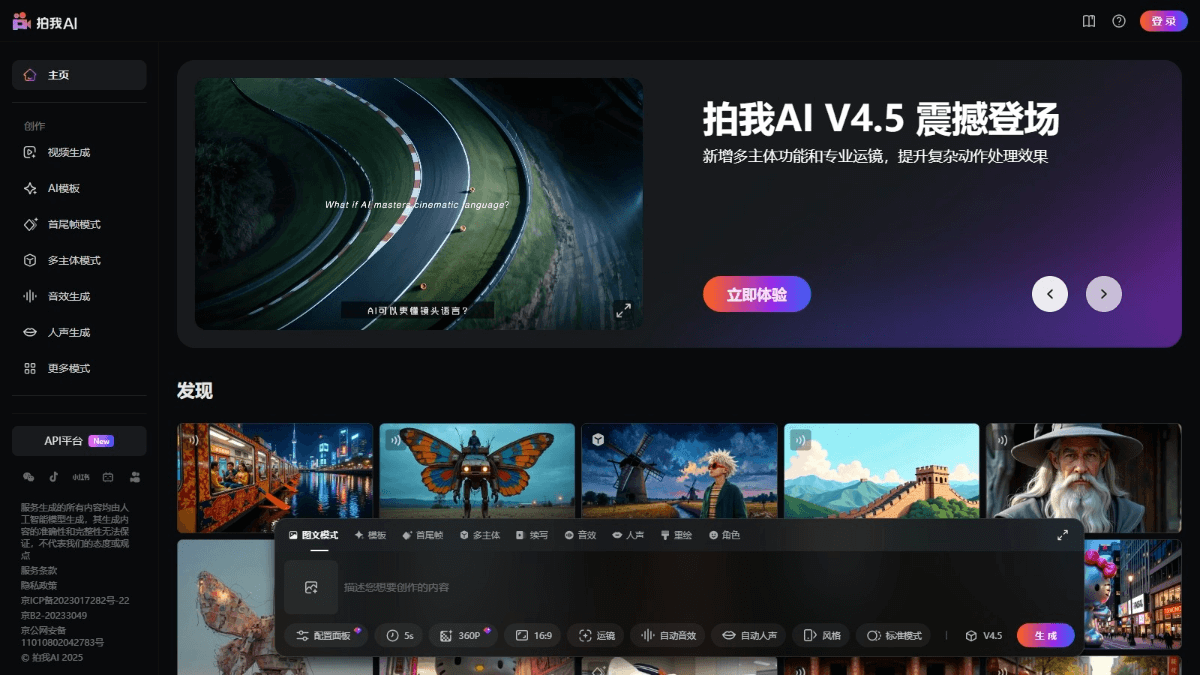
Shoot Me AI - PixVerse Domestic Version of AI Video Generation Platform Launched by Aishi Technologies
Shoot Me AI is an innovative AI video generation platform launched by Aishi Technology, customized for the domestic market and is the domestic version of PixVerse. The platform supports the rapid generation of high-quality dynamic video content based on simple text prompts or uploaded images. The latest V4.5 version of the platform has improved video quality, animation smoothness...

How to Make a PPT with AI, Recommended 4 AI Agent Free Generation
Often friends ask if there are any tools for generating better quality PPTs. "Making PPT is harder than writing content!"

Seed-Music - AI Music Generation Model Launched by ByteHopper
Seed-Music is a big model of AI music generation launched by ByteDance, which supports transforming 10 seconds of user-recorded audio into a complete musical composition. Based on autoregressive language modeling and diffusion methods, it generates multimodal user inputs (e.g., style descriptions, audio references, scores, and sound cues) based on high...
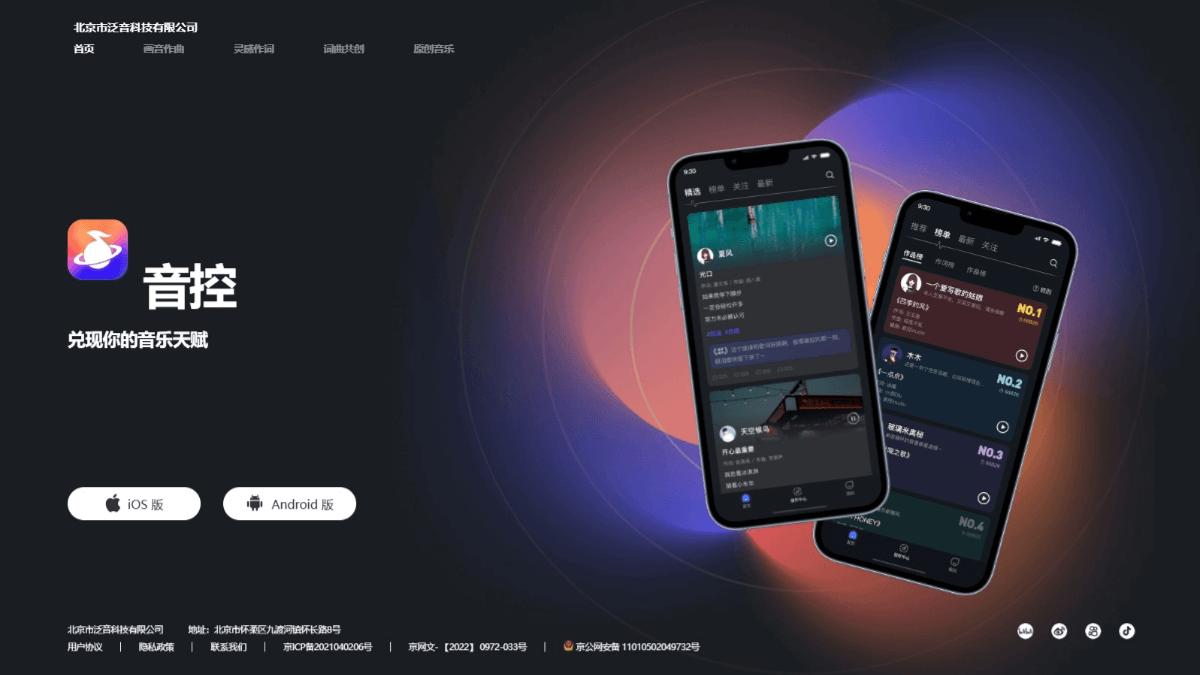
Sound Control - AI music creation platform that generates songs with lyrics or melody snippets
Sound Control is an innovative AI music creation platform that provides comprehensive support for music creators. Audio Control is equipped with various functions such as AI lyrics, compositions, accompaniment generation, professional recording, etc. Users only need to input simple lyrics or melody snippets, and the AI can quickly generate complete song content, covering rock, rap, ballad, and many other...