
AnyI2V - Fudan, Ali Dharma Institute and other open source framework for intelligent image animation generation

What is AnyI2V
AnyI2V is an image animation generation framework jointly launched by Fudan University, Alibaba Dharmo Academy, etc. It supports transforming static conditional images (such as grids, point clouds, etc.) into dynamic videos without the need for complex training processes and large amounts of data.AnyI2V extracts image features through DDIM inversion, and generates animations by combining them with user-defined motion trajectories.AnyI2V supports a variety of modal inputs, and is able to be AnyI2V supports multiple modal inputs and can be edited by LoRA or text prompts to realize style migration and content adjustment.AnyI2V has a wide range of applications in the fields of animation production, video effects, game development, dynamic advertising, etc., and provides a highly efficient and flexible animation generation solution for creators.
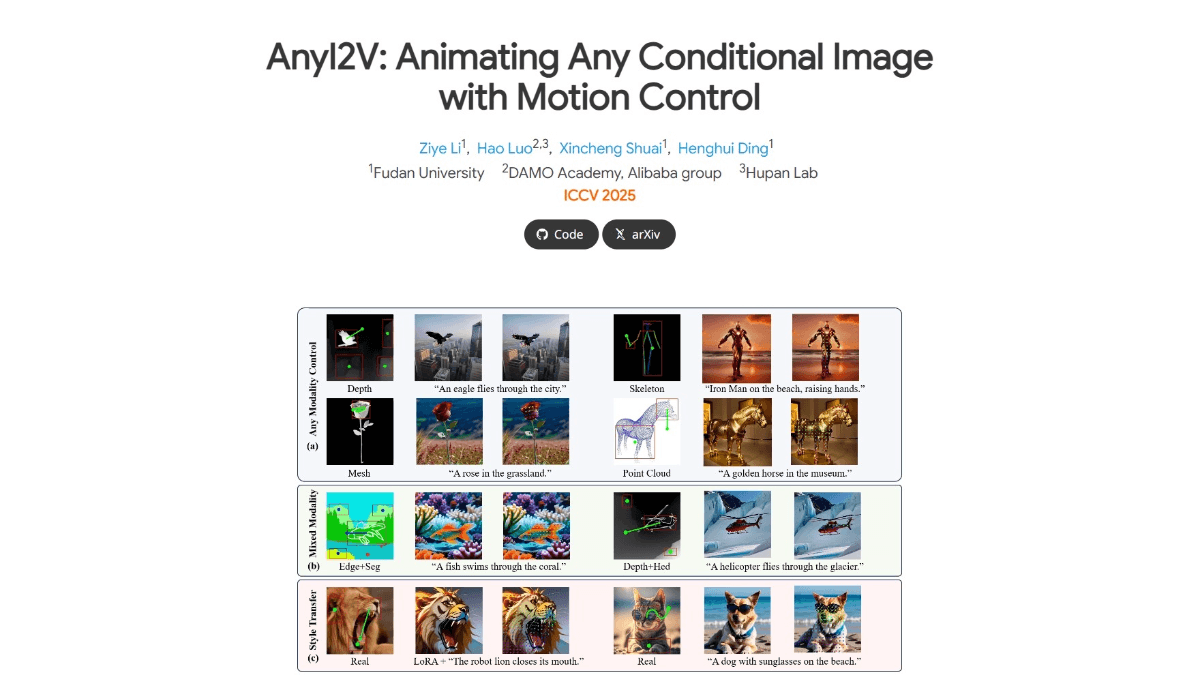
Features of AnyI2V
- multimodal support: AnyI2V is able to handle inputs from multiple modalities, including meshes and point clouds, which are difficult to handle in traditional methods.
- Combined input: Supports users to combine different types of conditional inputs to further enhance input diversity.
- content editor: With the help of LoRA or text prompts, users can migrate the style and adjust the content of images to achieve personalized editing effects.
- Precision Motion Control: Supports users to precisely control the animation effects in the video by defining motion trajectories and realizing complex motion paths.
- Low-threshold use: There is no need for large amounts of training data and complex training processes, making the framework easy to get started and use.
Core Benefits of AnyI2V
- efficiency: AnyI2V does not require a large amount of training data and complex training process, directly using conditional images to quickly generate animation, significantly saving time and computing resources, and improve the efficiency of creation.
- dexterity: Supports a variety of modal (e.g., grid, point cloud, etc.) and mixed condition inputs, providing users with a wider creative space to meet the diverse needs of different scenarios.
- controllability: Users can customize the motion trajectory to achieve precise control of the animation, while supporting flexible editing through LoRA and text prompts to ensure that the generated results meet expectations.
- innovativeness: As a training-independent framework, AnyI2V breaks through the limitations of traditional methods and brings new technical ideas and creation modes to the field of image animation.
- practicality: AnyI2V is easy to use, lowers the creation threshold, is suitable for a variety of application scenarios, and has high promotion value and practical application potential.
What is AnyI2V's official website?
- Project website:: https://henghuiding.com/AnyI2V/
- GitHub repository:: https://github.com/FudanCVL/AnyI2V
- arXiv Technical Paper:: https://arxiv.org/pdf/2507.02857
Who AnyI2V is for
- animator: Rapidly convert static images into motion video, generate animation prototypes, and provide more creative space for animation creation.
- Video Creators: The model generates compelling and dynamic video content for use in social media, advertising, etc., to increase the attractiveness and distribution of the content.
- moviemaker: Models can generate complex visual effects, transform static scene images into dynamic backgrounds, or add dynamic effects to characters to enhance visual impact.
- game developer: Generate dynamic scenes and character animations in the game with models, bringing richer and more vivid visual effects to the game and enhancing the player's experience.
- advertising copywriter: Convert static advertising images into dynamic videos to attract viewers' attention and improve the attractiveness and effectiveness of advertisements.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...