Alibaba AI Research Institute Releases CosyVoice 2: Improved Streaming Speech Synthesis Models


1. Overview
In recent years, speech synthesis technology has made significant progress, especially in achieving real-time, natural and smooth speech generation. However, issues such as latency, pronunciation accuracy, and speaker consistency still plague the industry in real-world applications, especially in streaming applications that require high responsiveness. These technical challenges are especially prominent when dealing with complex linguistic inputs, such as tongue twisters or polyphonic words, which are beyond the processing capabilities of existing models. To address these challenges, Alibaba researchers have introduced CosyVoice 2, an upgraded model for speech synthesis technical challenges, which aims to effectively solve these problems.
2. CosyVoice 2 Debut: From Basics to Breakthroughs
 CosyVoice 2 builds on the foundation of the original CosyVoice and brings a significant upgrade in speech synthesis technology. This enhanced model is not only optimized for streaming applications, but also makes significant progress in offline applications. Its adaptability, flexibility and accuracy in a wide range of application scenarios have been improved, especially in text-to-speech and interactive speech systems.
CosyVoice 2 builds on the foundation of the original CosyVoice and brings a significant upgrade in speech synthesis technology. This enhanced model is not only optimized for streaming applications, but also makes significant progress in offline applications. Its adaptability, flexibility and accuracy in a wide range of application scenarios have been improved, especially in text-to-speech and interactive speech systems.
Core highlights of CosyVoice 2:
- Unified streaming and non-streaming modes: CosyVoice 2 adapts seamlessly to a variety of application scenarios, whether they are generated in real time or processed offline, without compromising performance.
- Higher pronunciation accuracy: In complex language environments, CosyVoice 2 reduces the pronunciation errors of 30%-50%, especially when dealing with polysyllabic words or tongue-twisters, and greatly improves speech intelligibility.
- enhanced speaker congruenceWhether it's zero-shot synthesis or cross-language synthesis, CosyVoice 2 ensures that the output is consistent, so every synthesis is natural and smooth.
- More precise command control: Users can precisely control the tone, style, and accent of their voice through natural language commands, and even adjust their voice performance according to their emotional needs.
3. The technology and advantages behind the innovation
CosyVoice 2 is able to solve many of the challenges in the field of speech synthesis thanks to a number of innovations in its technology.
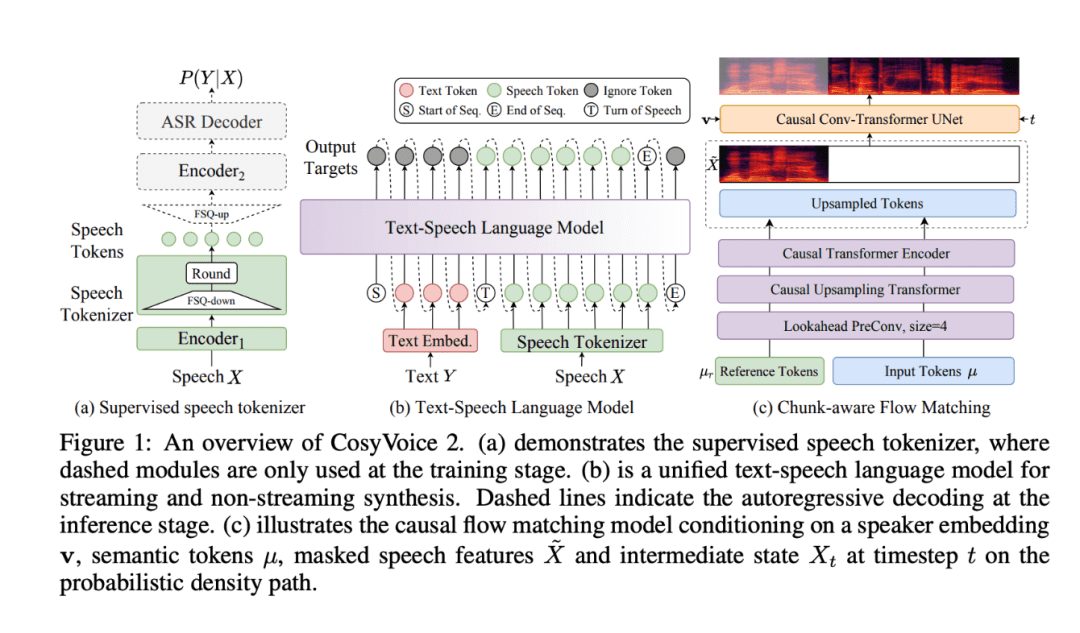
- Finite Scalar Quantization (FSQ) Technique: FSQ replaces the traditional vector quantization method, optimizes the use of speech-tagged vocabularies, and improves the semantic representation capability and synthesis quality. This technological innovation not only enhances the expressive power of the model, but also effectively reduces the complexity of data processing.
- Simplified Text-to-Speech Architecture: CosyVoice 2 is based on pre-trained Large Language Models (LLMs), eliminating the need for additional text encoders, simplifying the model architecture, and improving cross-language performance. This architectural design makes CosyVoice 2 significantly more efficient and accurate when processing multiple languages.
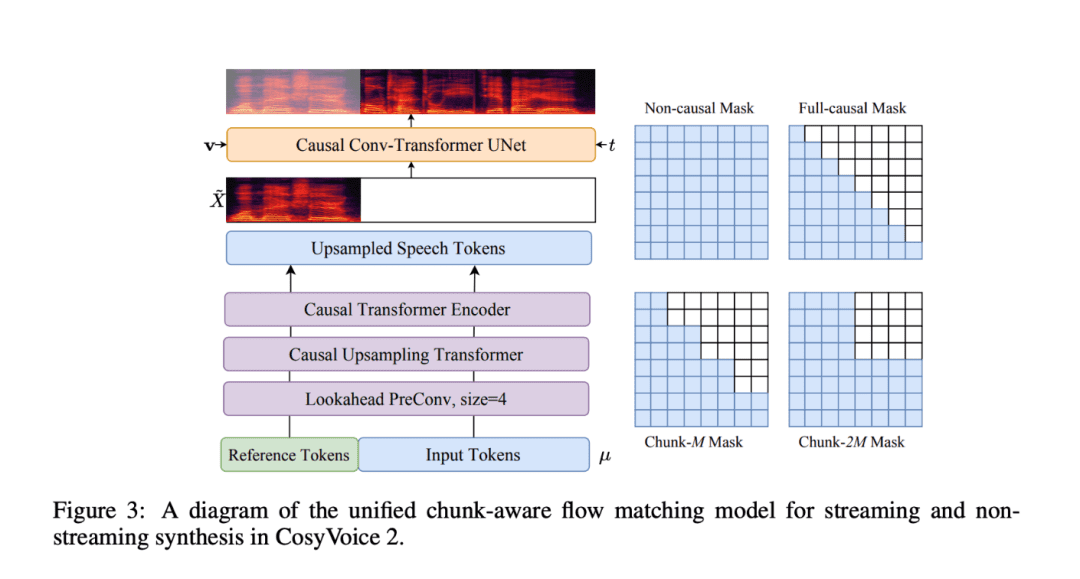
- Block-aware causal flow matching: This innovative technology allows semantic and acoustic features to be aligned with minimal latency, enabling CosyVoice 2 to excel in real-time speech generation, especially for real-time voice interaction and streaming applications.
- Extended Command Dataset: With over 1500 hours of training data, CosyVoice 2 adds granular control over different accents, emotions, and voice styles, making speech synthesis more flexible and expressive. Whether it's a warm tone of voice or a tense emotion, CosyVoice 2 is able to capture and express it with precision.
4. Performance of CosyVoice 2: How it solves real-world problems
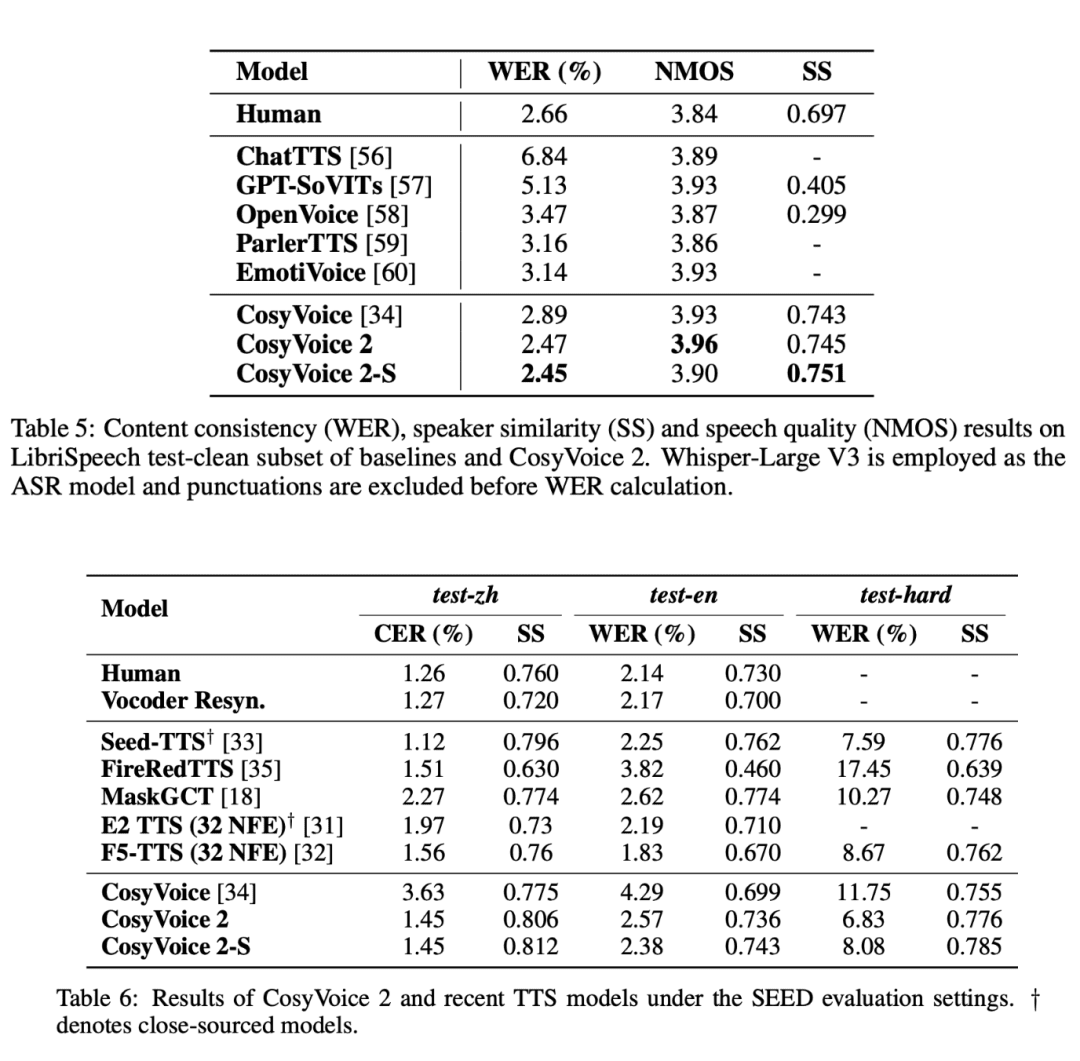
In a series of rigorous evaluation tests, CosyVoice 2 demonstrated undeniable strengths, particularly in the areas of low latency, high accuracy and voice consistency.
- Low Latency and High Efficiency: CosyVoice 2 has response times as low as 150 milliseconds in speech generation, which means it can be ideally suited for real-time voice applications such as voice chat and streaming interactions.
- Improved pronunciation accuracy: CosyVoice 2 provides significant enhancements to complex linguistic structures (e.g., polysyllabics, tongue twisters, etc.), dramatically improving pronunciation accuracy and reducing errors in everyday speech synthesis.
- Consistent speaker performance: CosyVoice 2 is able to maintain a high degree of consistency across different synthesis tasks, whether it is cross-language synthesis or zero-shot synthesis, and the naturalness and stability of the speech is greatly guaranteed.
- multilingualism: CosyVoice 2 also performs well in benchmarks for languages such as Japanese and Korean, and despite challenges with certain overlapping character sets, it still demonstrates the power of cross-language synthesis.
- Resilience in challenging scenarios: CosyVoice 2 outperforms previous technical limitations by demonstrating better clarity and accuracy than previous models in some challenging speech scenarios such as tongue twisters.
5. Conclusion
The launch of CosyVoice 2 is an important advancement in speech synthesis technology. It provides a more mature and stable solution by addressing key issues such as latency, accuracy, and speaker consistency.Innovative technologies such as FSQ and block-aware causal flow matching provide strong support for the model's performance and ease-of-use, while a large training dataset and precise control of speech styles enable it to cope with a wide range of complex speech application scenarios.
Although CosyVoice 2 still needs to be further improved in terms of multi-language support and processing of complex language scenarios, it lays a solid foundation for future speech synthesis technology, especially in the application of streaming media and real-time speech generation, which has a broad development prospect. Whether in the field of AI voice assistant, intelligent customer service, or real-time translation, CosyVoice 2 demonstrates its strong potential and paves the way for further breakthroughs in speech synthesis technology.
Reference:
- https://arxiv.org/abs/2412.10117
- https://huggingface.co/spaces/FunAudioLLM/CosyVoice2-0.5B
- https://www.modelscope.cn/models/iic/CosyVoice2-0.5B
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...