The first list of "AI Search" evaluation benchmarks was released! 4o's leading margin is small, and domestic big models perform brilliantly, with a total of 5 bases, 11 scenarios, and 14 models.


The benchmark evaluation of Chinese big model "AI Search" (SuperCLUE-AISearch) was released, which is an in-depth evaluation of the ability of big model combined with search. The evaluation not only focuses on the basic capabilities of the big model, but also examines its performance in scenario applications. The evaluation covers 5 basic capabilities, such as information retrieval and up-to-date information acquisition, as well as 11 scenario applications, such as news and life applications, to comprehensively test the model's performance in combining search in different basic capabilities and scenario application tasks. For the evaluation program, see: "AI Search" Benchmark Evaluation Program Release. This time, we evaluated the AI search capabilities of 14 representative large models at home and abroad, and the following is the detailed evaluation report.
AI Search Evaluation Summary
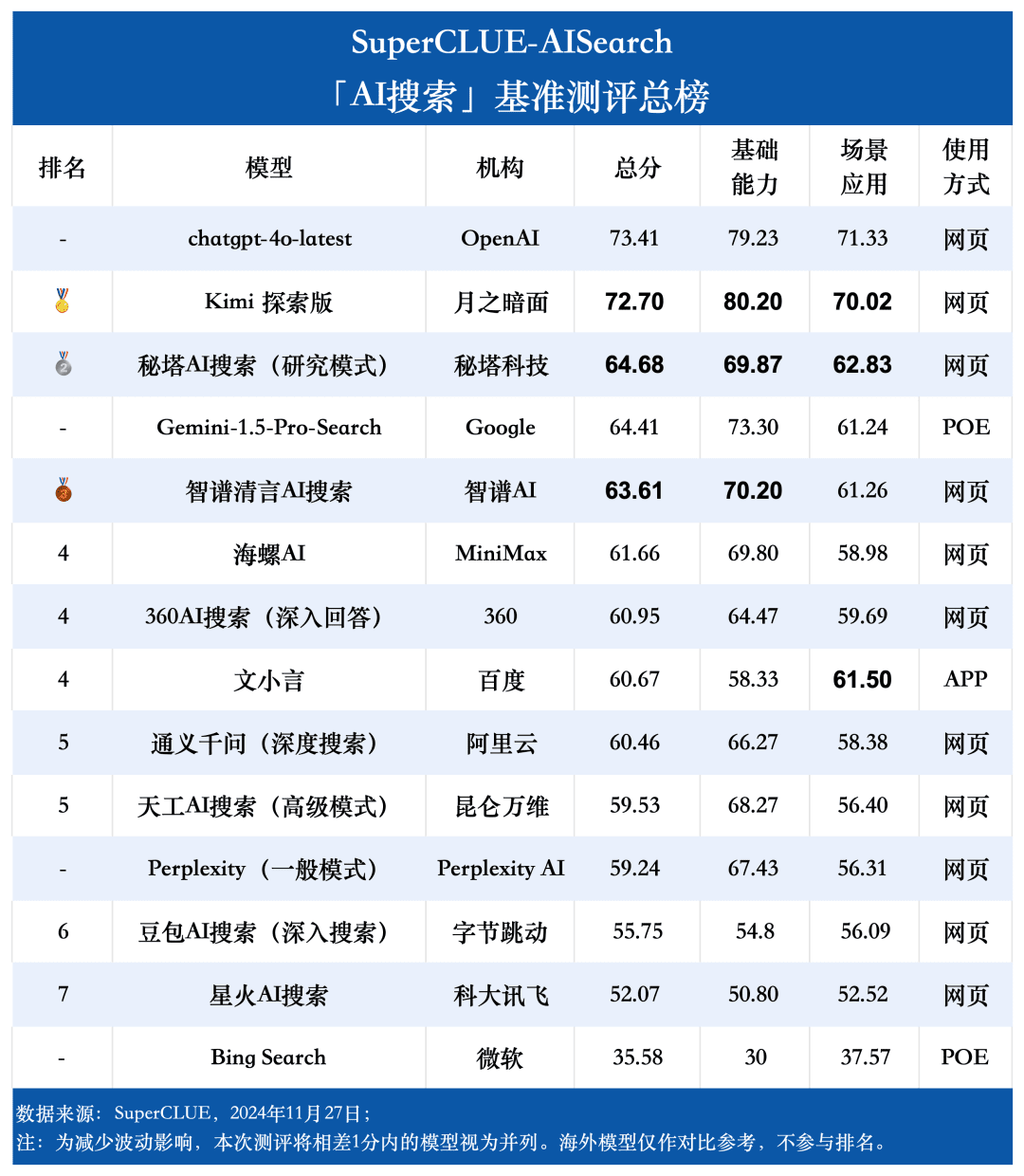
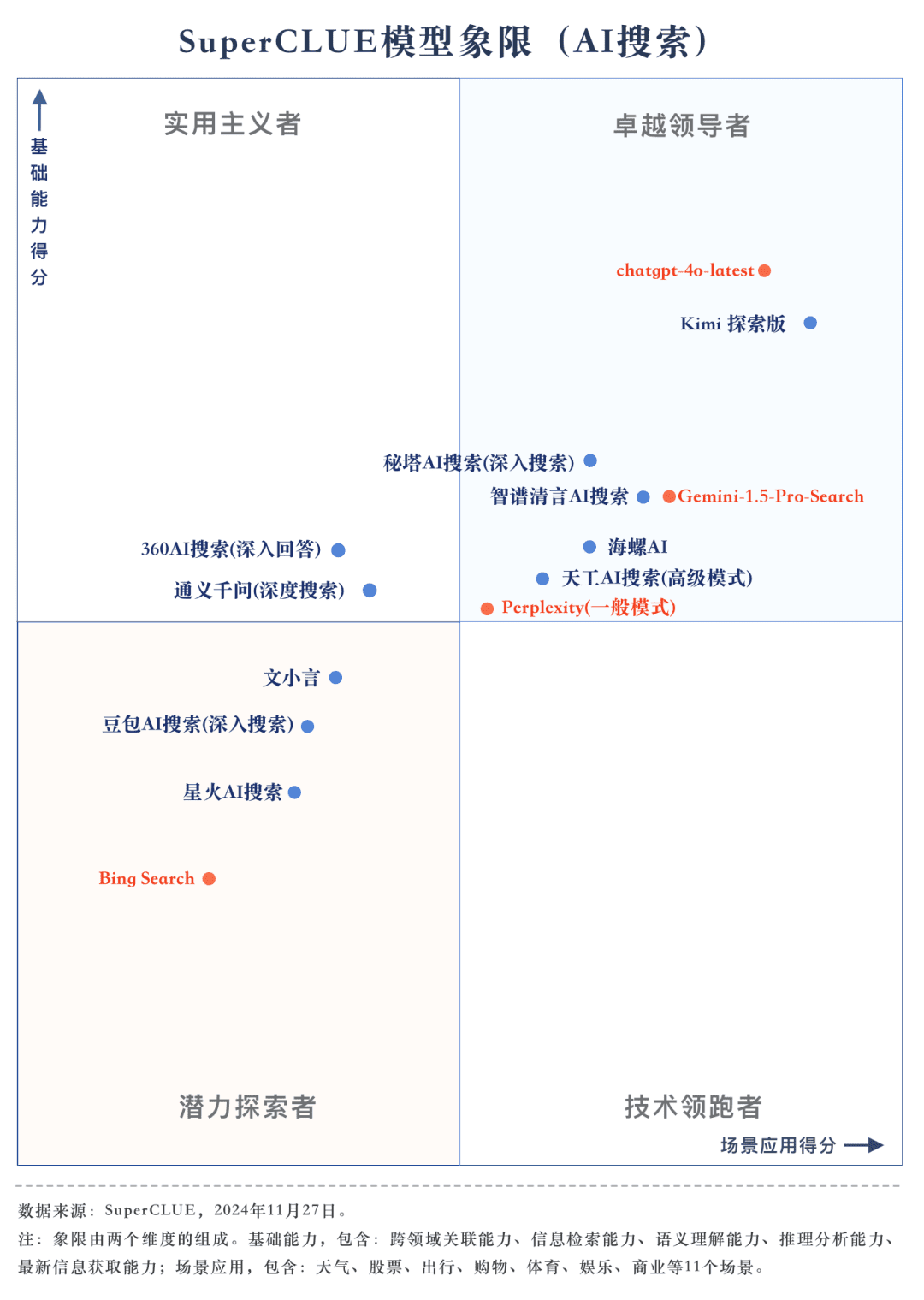
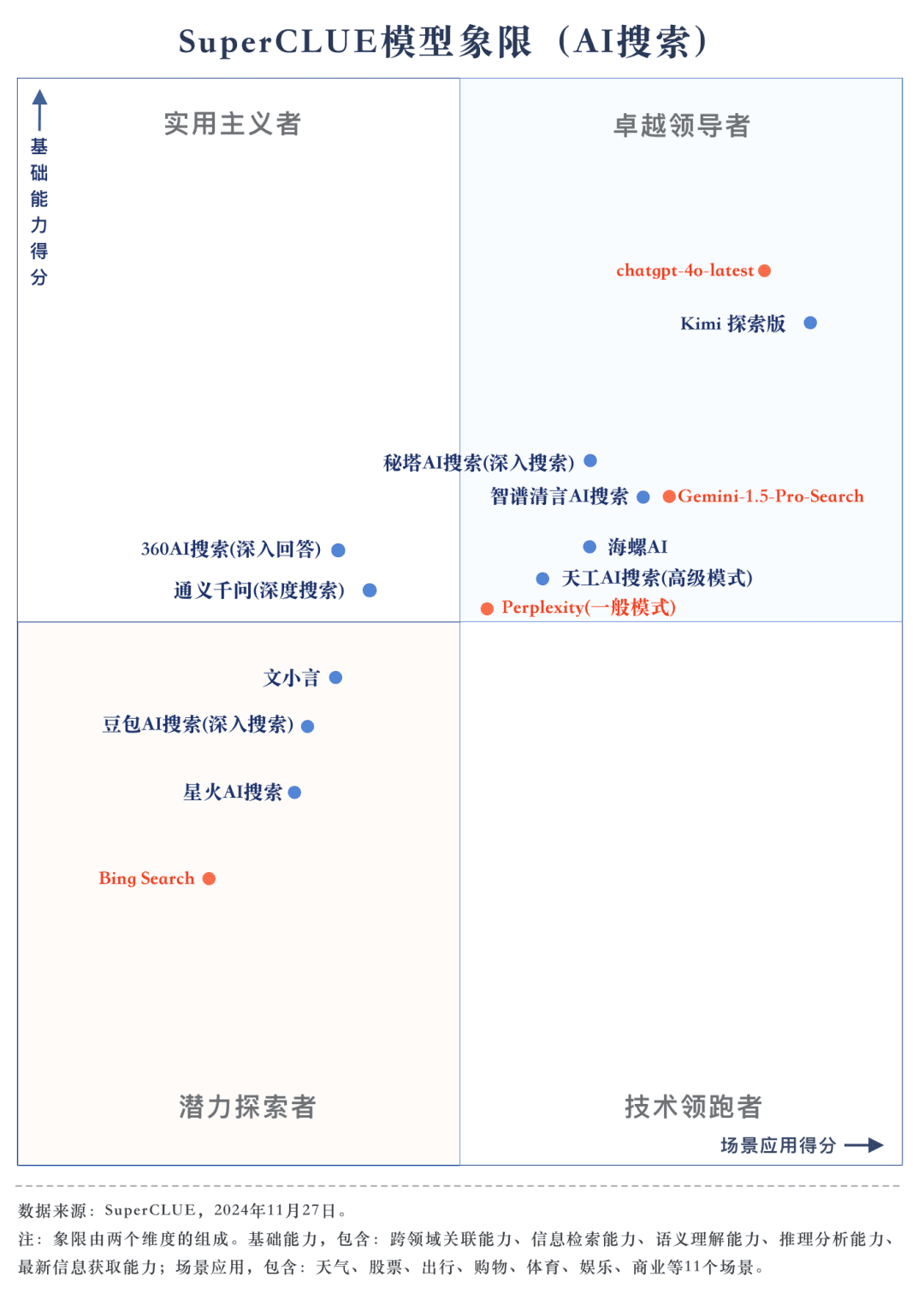
Assessment point 1: chatgpt-4o-latest leads the AI search list, followed by Kimi Explorer, with only 0.71 points difference between them In this evaluation, chatgpt-4o-latest scored 73.41 points with excellent performance, ahead of other participating models. Meanwhile, the big domestic model Kimi The performance of the Explorer Edition is also noteworthy, performing well in the shopping and cultural topics in the scenario application, showing superb AI search capabilities, as well as excellent comprehensive performance in multiple dimensions.
Assessment point 2: The overall performance of domestic big models is quite bright, surpassing some international counterparts From the evaluation results, domestic big models such as Secret Tower AI Search (Research Mode), Wisdom Spectrum Clear Speech AI Search and Conch AI are relatively bright in terms of overall performance, and are on par with the overseas big model Gemini-1.5-Pro-Search. Apart from that, the performance of several domestic big models in the middle of the overall performance such as 360AI Search (in-depth answer), Wen XiaoYin, Tongyi QianQi (deep search) and other big models are not similar, showing a small difference.
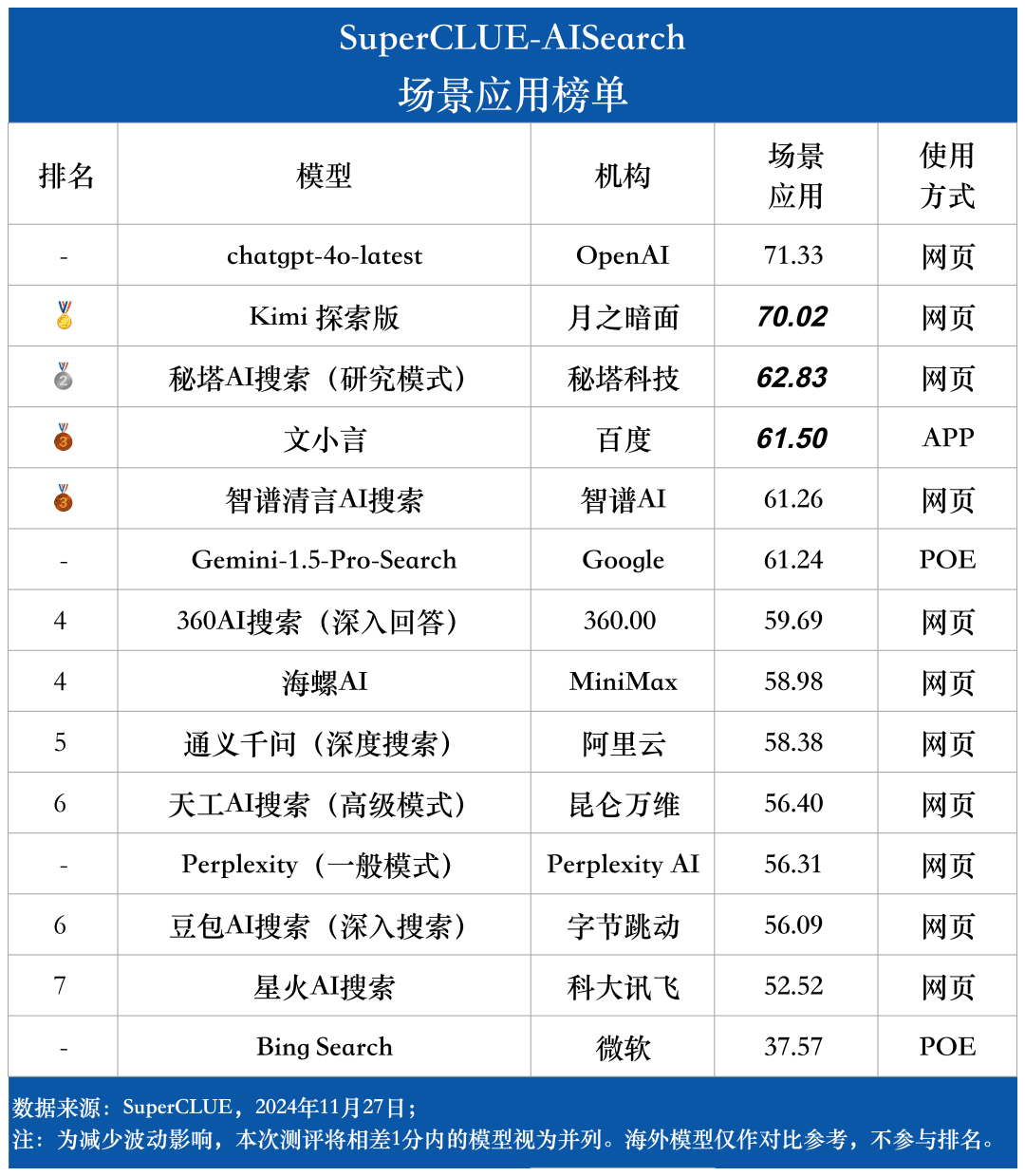
Measurement point 3: The models show different degrees of performance in different scenario applications. In the evaluation of AI search, we also focus on the performance of each big model under different scenario applications. The domestic grand models performed relatively well in scenarios such as science and technology, culture, business and entertainment, demonstrating excellent information retrieval and integration capabilities while grasping the timeliness of information. However, there is still room for domestic big models to improve in scenario applications such as stocks and sports.
Overview of the list
Introduction to SuperCLUE-AISearch
SuperCLUE-AISearch is a comprehensive evaluation set of Chinese AI search models, aiming to provide a reference for evaluating the capability of AI search models in the Chinese domain.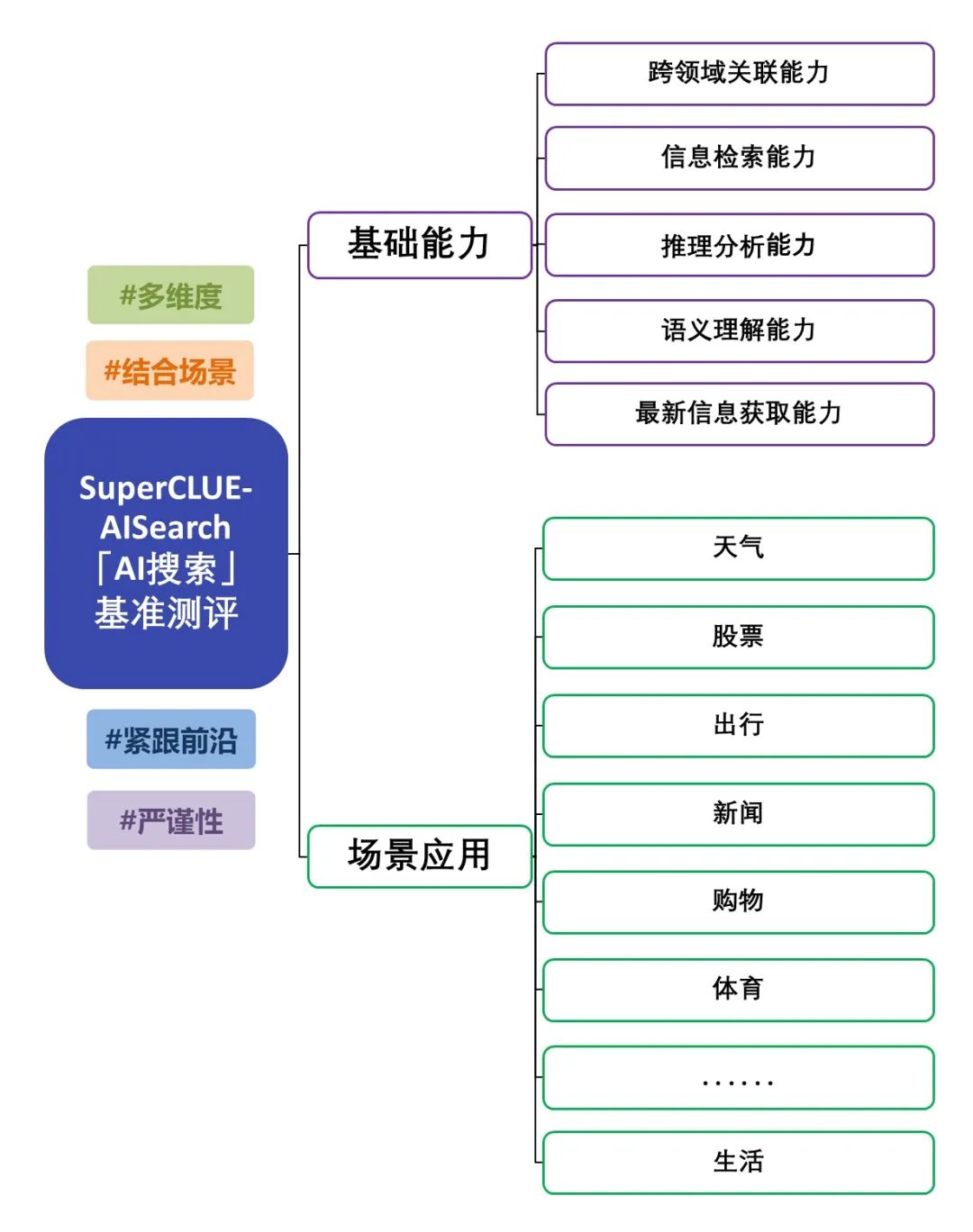
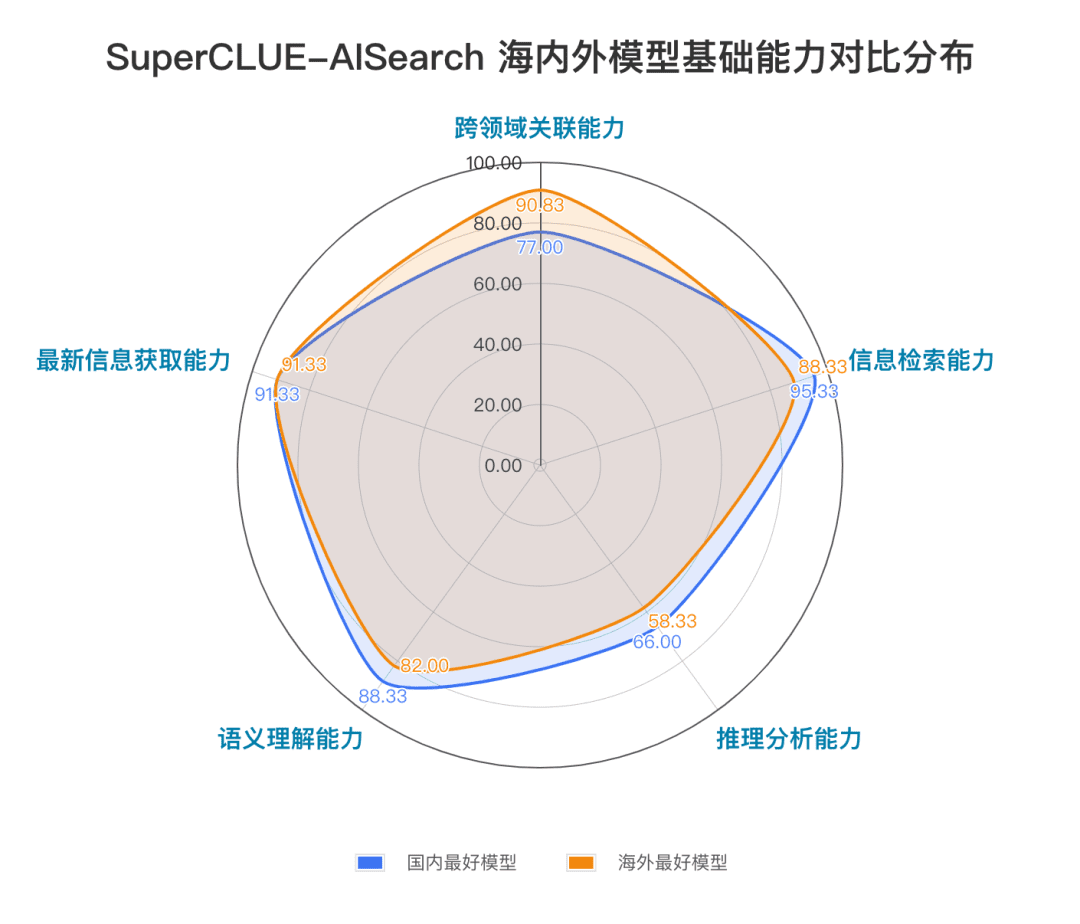
The foundational capabilities include five capabilities that are required in AI search tasks: cross-domain relevance, information retrieval, semantic understanding, up-to-date information acquisition, and reasoning.
Scenario applications include 11 scenarios common to AI search tasks: weather, stocks, travel, news, shopping, sports, entertainment, education, travel, business, culture, technology, healthcare, and life.
Methodology
Referring to the SuperCLUE fine-grained evaluation method, we build a specialized evaluation set, which provides fine-grained evaluation for each dimension and can provide detailed feedback information.
1) Measurement set construction
Chinese Prompt Construction Process: 1. Reference to existing prompt ---> 2. Chinese Prompt Writing ---> 3. Testing ---> 4. Modify and finalize Chinese Prompt; build a dedicated assessment set for each dimension.
2) Scoring method
The evaluation process begins with the interaction of the model with the dataset, where the model needs to be understood and answered based on the questions provided.
The assessment criteria cover the dimensions of thinking process, problem solving process, reflection and adjustment.
The scoring rules combine automated quantitative scoring with expert review for efficient scoring while ensuring scientific and fair assessment.
3) Scoring Criteria
For the assessment of the response quality of each macromodel on the assessment tasks, we used two assessment criteria to evaluate the subjective and objective questions in the assessment set respectively. These criteria were given different weights in the evaluation to fully reflect the performance of the grand models on the AI search task.
The SuperCLUE-AISearch assessment system is designed to score subjective questions out of 5 points, which are evaluated from the dimensions of information practicability, analytical accuracy and clarity of expression, of which information practicability accounts for 60%, analytical accuracy accounts for 20%, and clarity of expression accounts for 20%.The scoring criteria for objective questions are scored out of 5 points, which are evaluated from the dimensions of information accuracy and clarity of expression. The objective questions are scored out of 5 points and are evaluated in two dimensions: accuracy of information and clarity of expression, with accuracy of information accounting for 80% and clarity of expression accounting for 20%. 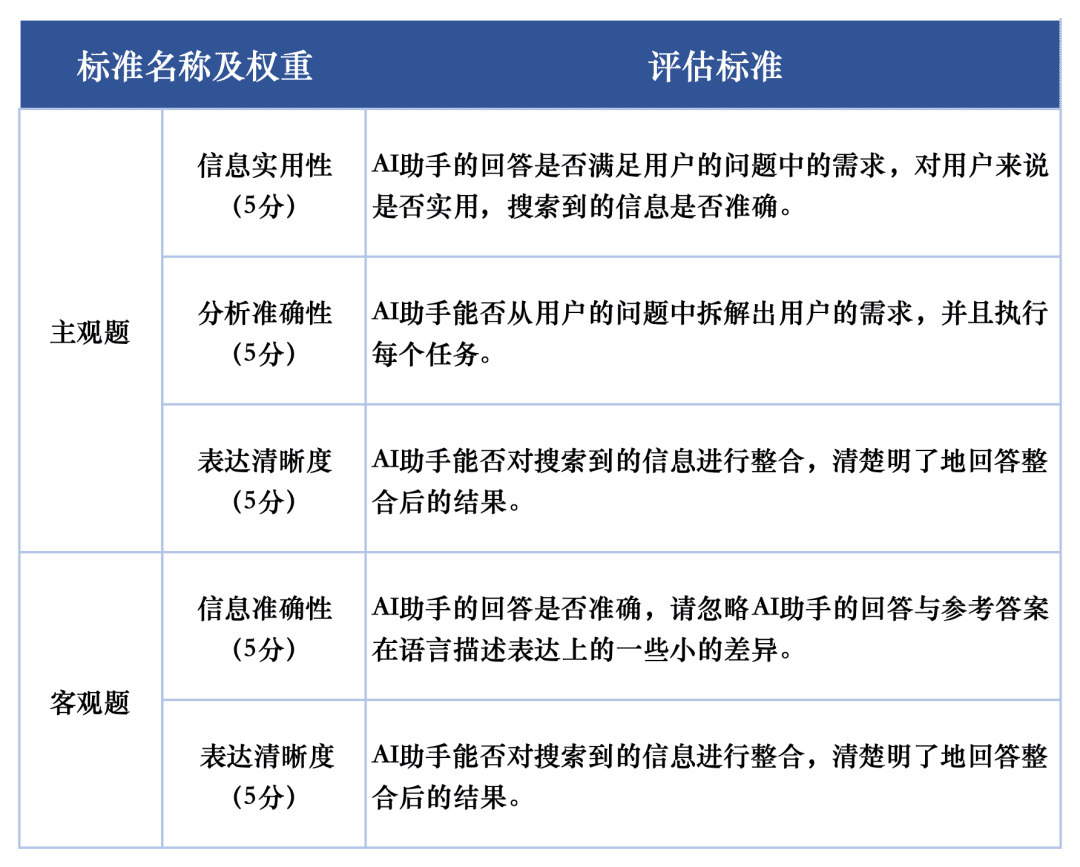
Example of Assessment
Prompt word Prompt: when and where was the Shenzhou 19 manned spacecraft launched, and who were the astronauts this time?
Answer: In the early morning of October 30, the launch of the manned spacecraft Shenzhou XIX at the Jiuquan Satellite Launch Center was a complete success. The crew of the Shenzhou-19 manned mission consisted of three astronauts: Mr. Cai Xuzhe, Mr. Song Lingdong and Mr. Wang Haize.
Model Answer:
Supermodel (chatgpt-4o-latest) referee:
Evaluate this answer as follows:
The AI assistant's answer accurately provided the launch time and location of the Shenzhou XIX manned spacecraft as well as the list of astronauts. However, the answer did not mention the main objectives and mission content of the mission, failing to fully satisfy the user's need to know the details of the mission. In addition, the section on the personal profiles of the astronauts, although detailed, may have exceeded the users' scope of concern. Therefore, it is suggested that a brief description of the mission objectives and main tasks be added to the answer to more fully meet the users' needs.1. Information usefulness (5 points):
The AI assistant provided the launch time, location and list of astronauts for Shenzhou XIX, which satisfied the user's need for such basic information. However, the main objectives of the mission and the mission content were not mentioned, failing to fully satisfy the user's need to know the details of the mission. Therefore, the score for information usefulness was 4.
Score: 4/52. Analytical accuracy (5 points):
The AI assistant accurately extracted key information such as the launch time, location and astronaut list from the user's question and provided a detailed personal profile. However, it did not address the mission objectives and main mission content, and failed to fully meet the user's needs. Therefore, the analysis accuracy score was 4.
Score: 4/53. clarity of expression (5 points):
The AI assistant's answers are clearly structured, with well-organized information that is easy to understand. The personal profile section is detailed, making it easy for users to understand the astronaut's background. Therefore, the clarity of expression is scored as 5 points.
Score: 5/5 composite score = 4*0.6 + 4*0.2 + 5*0.2 = 4.2 Combining the above, the composite score for the AI assistant's answer is 4.2. (out of 5 points)
Participating Models
In order to comprehensively measure the current development level of domestic and international big models in AI search capability, 4 overseas models and 10 domestic representative models were selected for this evaluation.
In view of the fact that many large-scale models in China and overseas generally provide two or more versions, including the general version and the in-depth exploration version, in this model selection process, we adopt a unified criterion: if a model is equipped with a more in-depth search or analysis version, we will select the version with the strongest search capability for comprehensive evaluation. 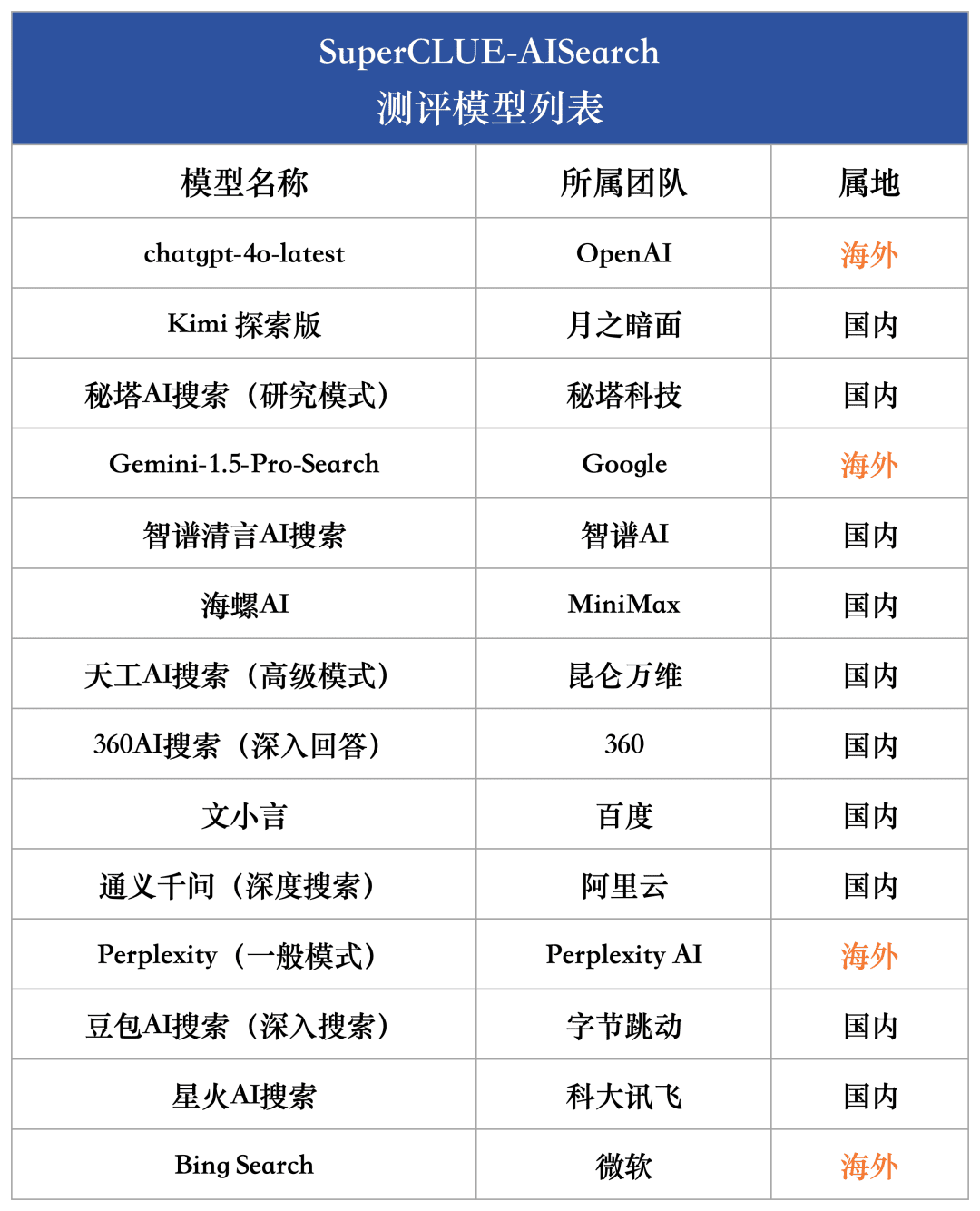
Evaluation results
overall list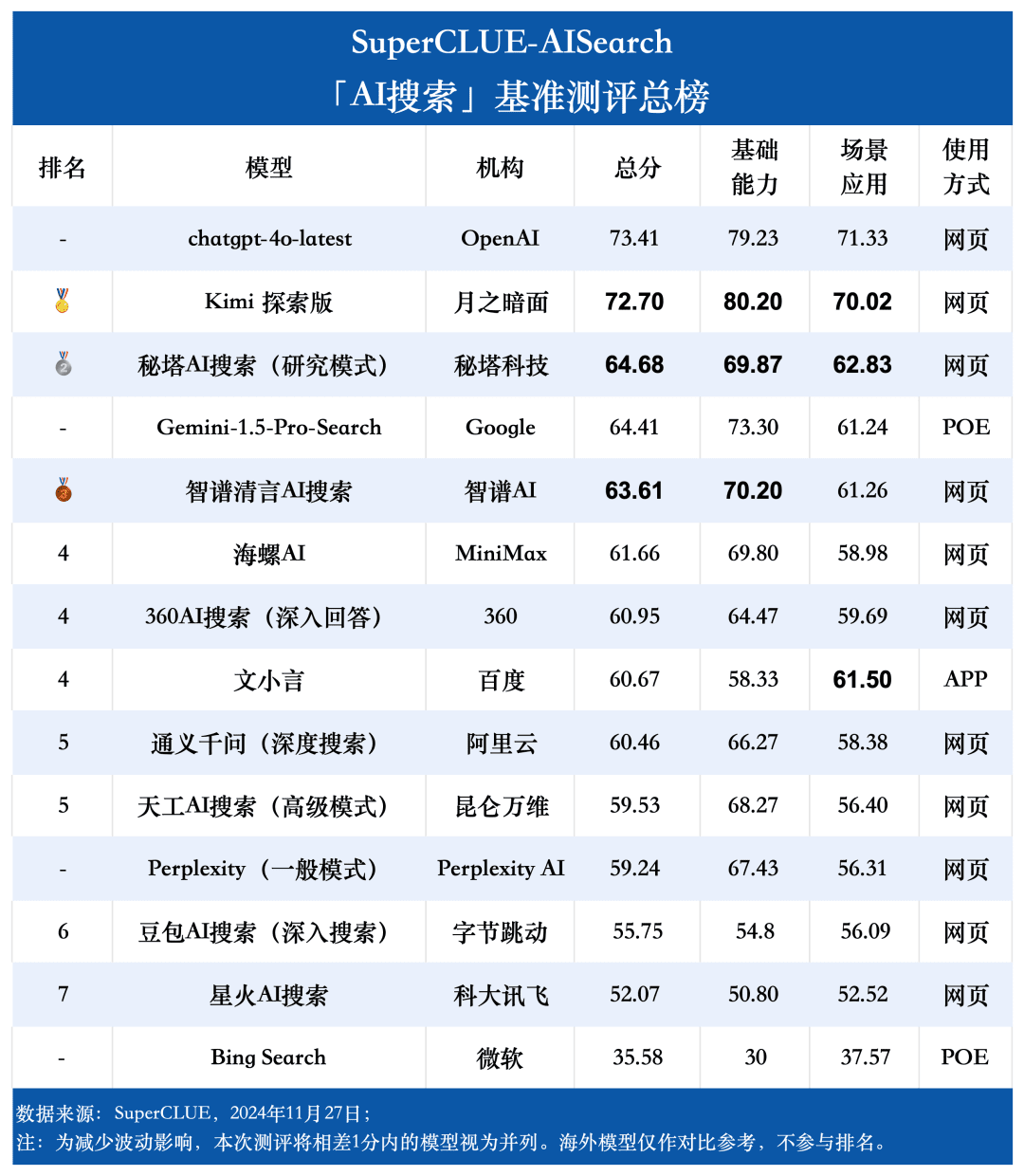
Basic Capabilities List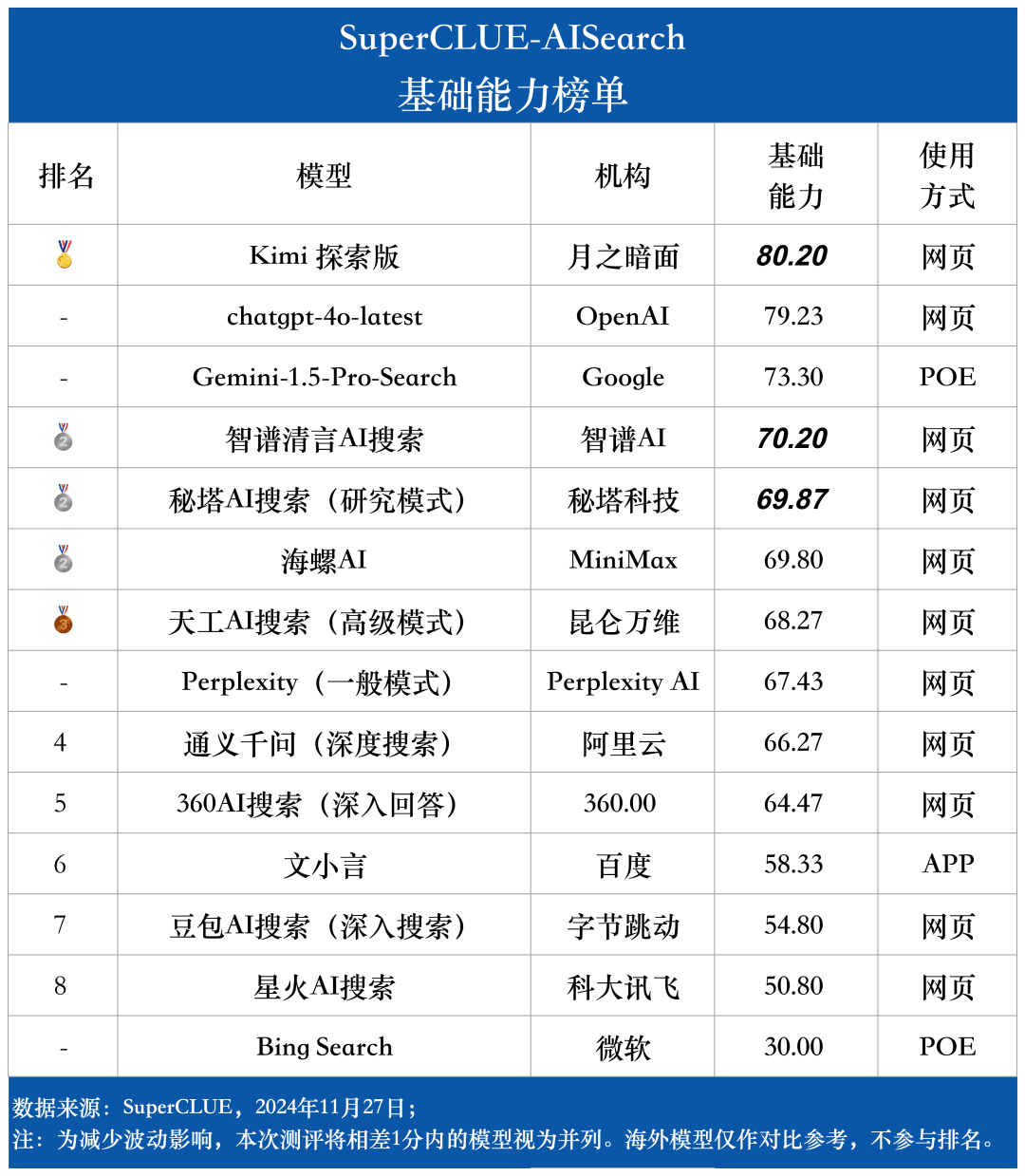
Scenario Application List
List of Subjective Questions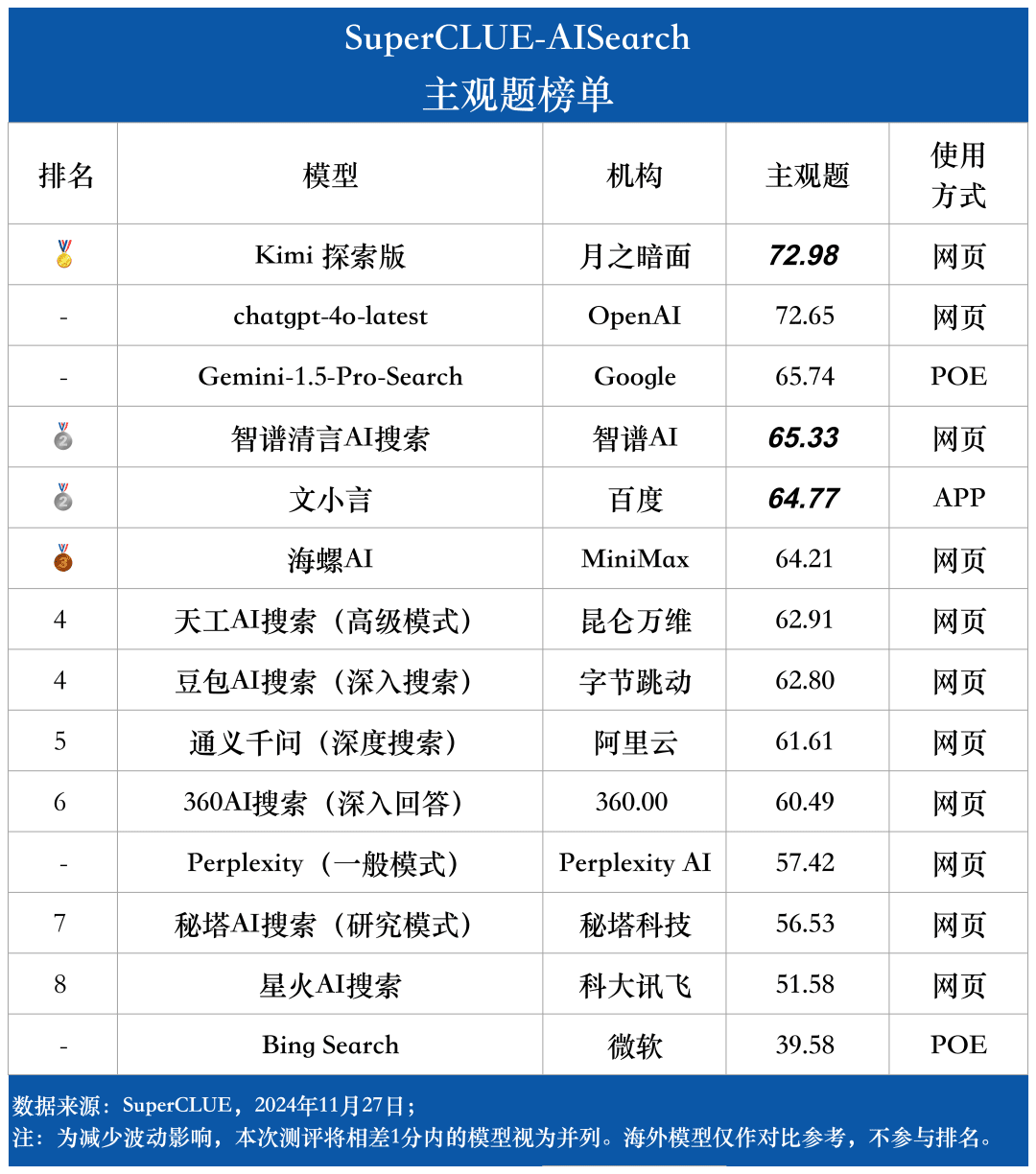
Objective question list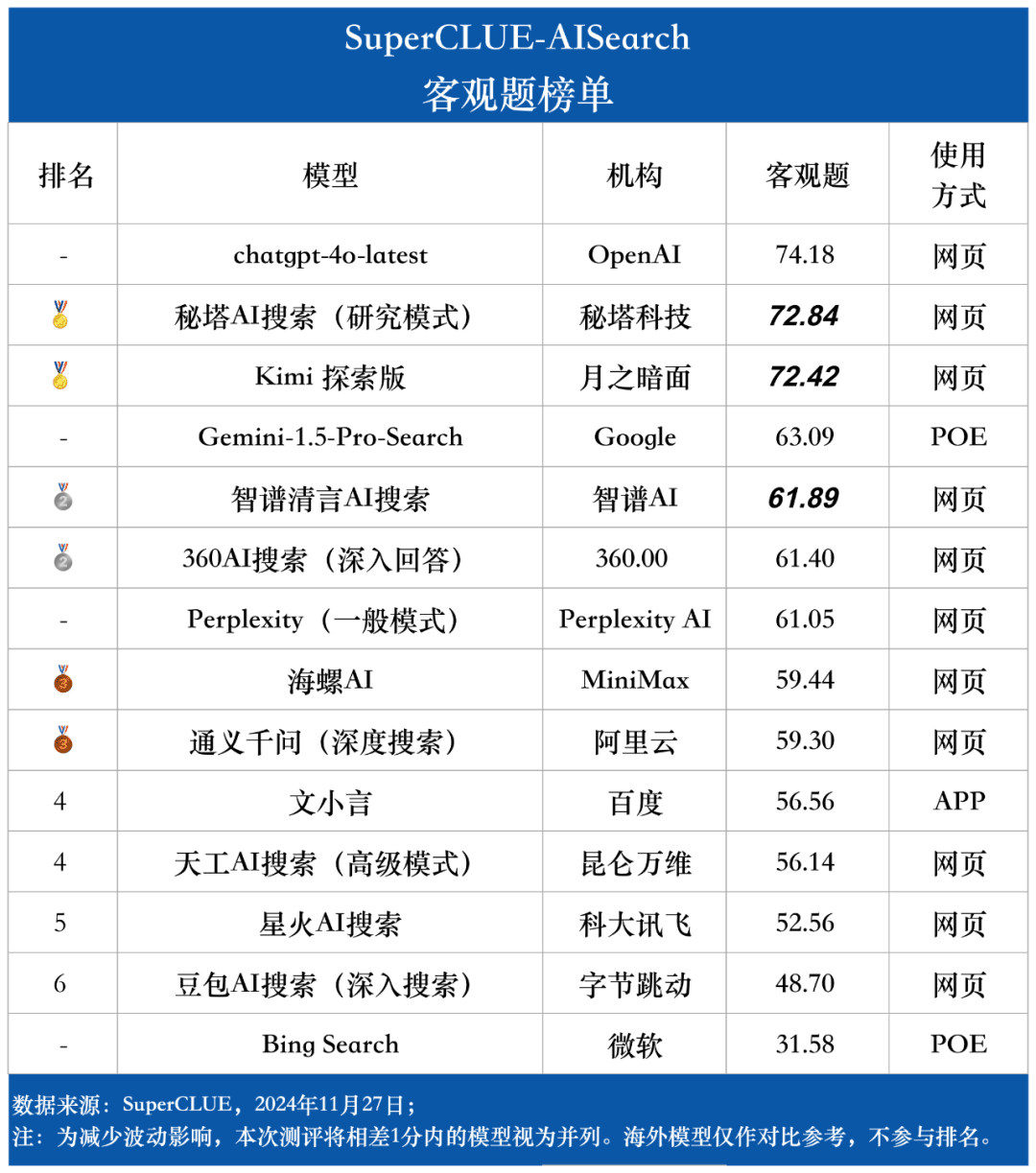
Model Comparison Example
Example 1 Basic Skills - Reasoning and Analytical Skills
Prompt: "Why is the structure of the GPT-1 model used? Transformer Instead of LSTM?"
Comparison of model responses (out of 5):
[Kimi Explorer]: 4 points 
[chatgpt-4o-latest]: 3.9 points 
[Tiangong AI Search (Advanced Mode)]: 3.4 points 
Example 2 Basic competencies - cross-cutting linkages
PromptPrompt: "Please help me to find out what are all the applications of computer vision technology in agriculture and choose 3 of these applications and briefly describe each one of them".
Comparison of model responses (out of 5):
[Secret Tower AI Search (Research Mode)]: 4 points 
[Wen Xiaoyan]: 3.4 points 
[Starfire AI Search]: 3 points 
Example 3 Scenario Application - Stocks
PromptPrompt: "Please tell me about several important bull markets in A-shares in recent years and their related data (e.g., start time, duration, rate of increase, highest and lowest points, etc.)." Comparison of model responses (out of 5 points): [Gemini-1.5-Pro-Search]: 3.2 points 
[Smart Spectrum Clear Speech AI Search]: 3.3 points 
Bing Search]: 2.6 points 
Example 4 Scene Application-Life
Prompt Prompt: "From January to October this year, China's automobile production and sales reached how many million units respectively, and by what percentage did they increase compared to the same period last year?"
Comparison of model responses (out of 5):
[Tongyi Thousand Questions (Deep Search)]: 4.2 points 
[360AI search (in-depth answer)]: 3.8 points 
Human consistency assessment
To ensure the scientific validity of the automated assessment of large models, we evaluated the human consistency of GPT-4o-0513 in the AI search evaluation task.
The specific operation method is as follows: five models are selected, and each model is independently scored by one person, respectively, for different dimensions of the subjective and objective questions, and then weighted and averaged according to the scoring criteria. We calculate the difference between the human scores and the model scores for each question, and then sum and average to get the average gap for each question as the evaluation result of human consistency assessment.
The final average results obtained were as follows: The average difference result was (in percentage): 5.1 points
Because of the high reliability of this automated evaluation.
Measurement Analysis and Conclusion
1.AI search comprehensive ability, chatgpt-4o-latest keep leading.
As can be seen from the evaluation results, the chatgpt-4o-latest (73.41 points) has an excellent overall capability and leads the SuperCLUE-AISearch benchmark. It is only 0.71 points higher than the best domestic model, Kimi Explorer.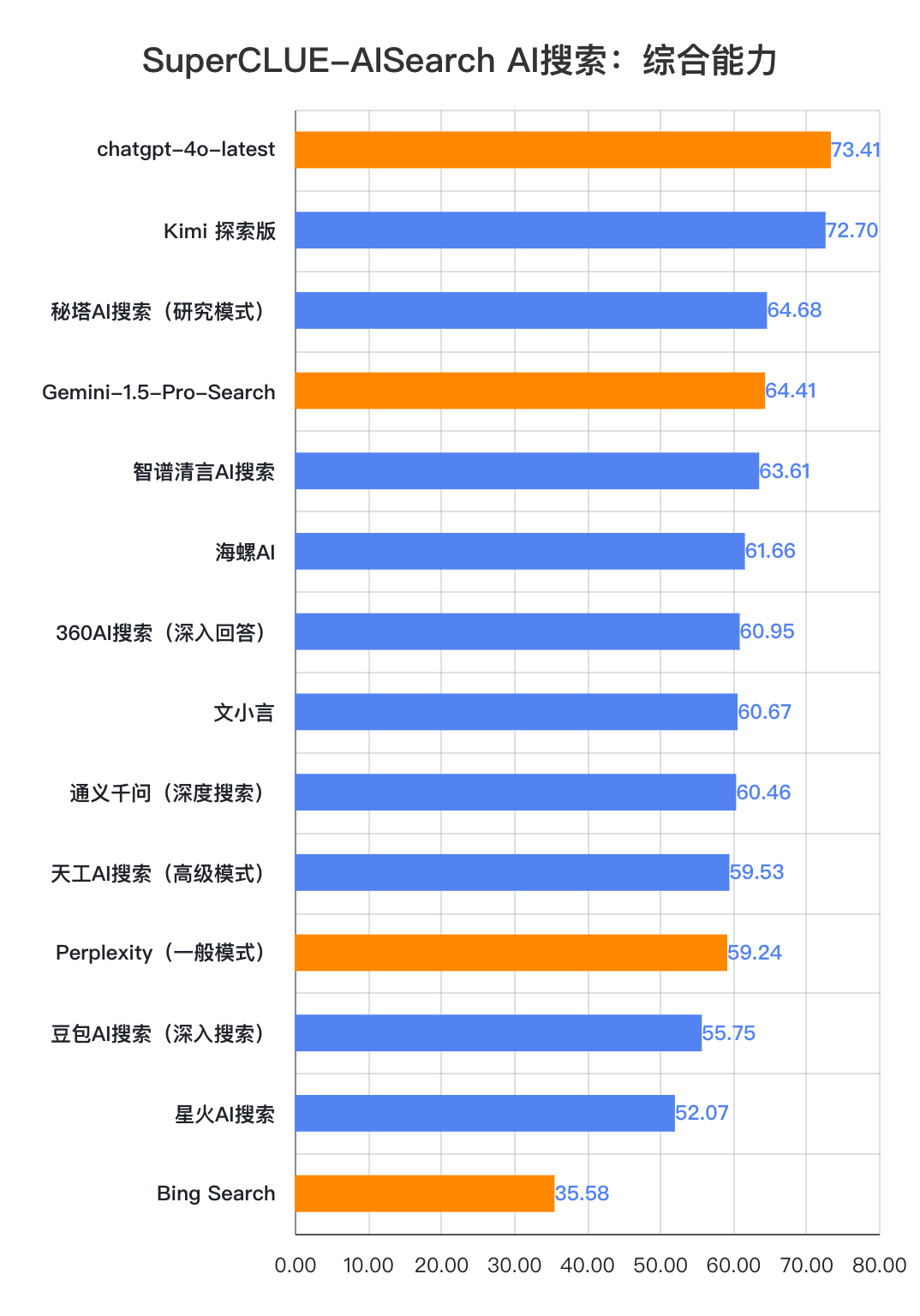
2. The overall performance of large domestic models is quite impressive, with relatively small differences between models
From the evaluation results, domestic models such as Secret Tower AI Search (research model), Wisdom Spectrum Clear Speech AI Search and Conch AI perform relatively well in terms of basic capabilities, and have the momentum to catch up with the overseas large model Gemini-1.5-Pro-Search. Overall, the performance of several large domestic models in the middle of the overall results, such as Conch AI, Wen Xiaoyin, Tongyi Qianqian (deep search), the performance of the models are not comparable, showing a small difference.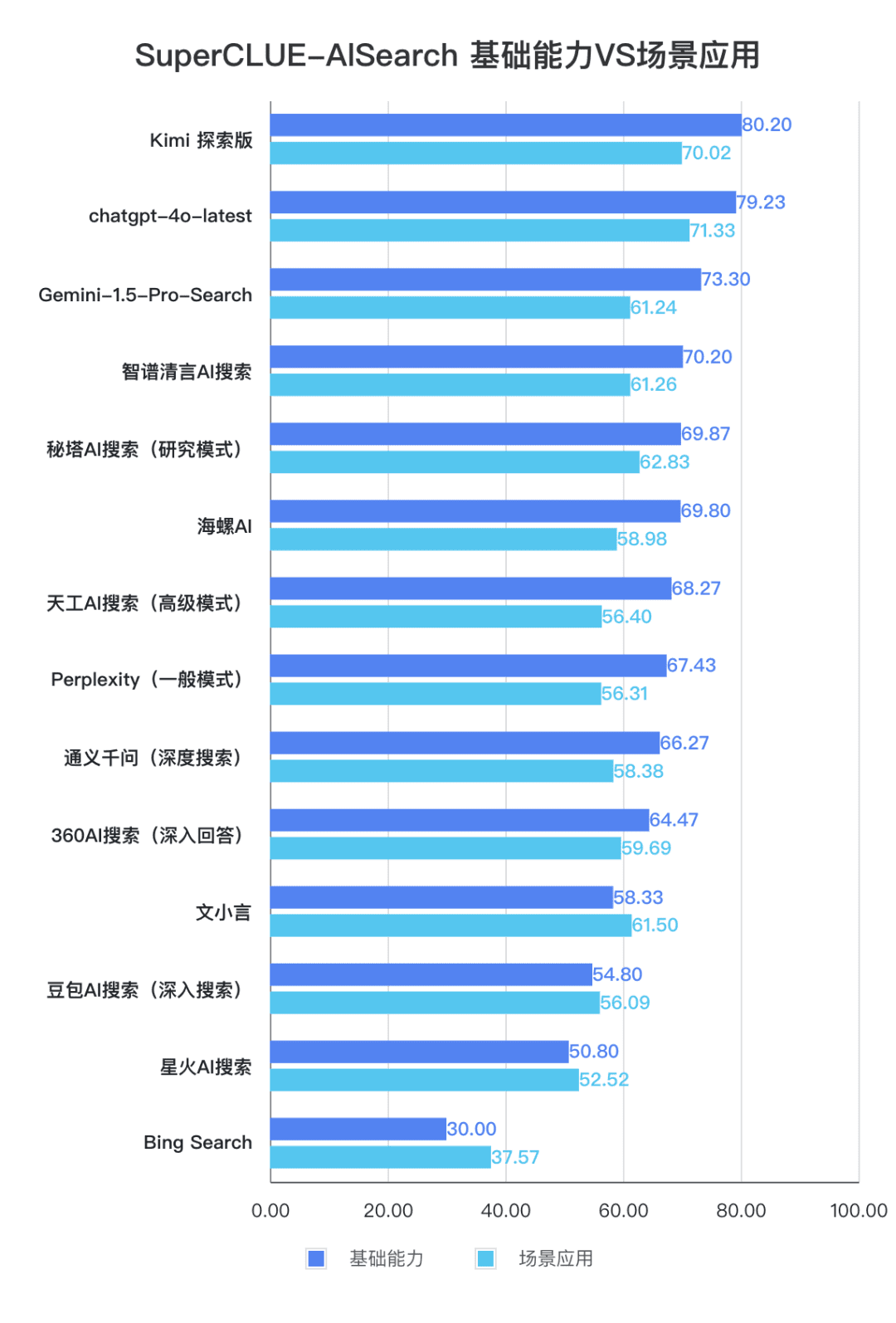
3. The model shows different levels of performance in different scenario applications.
In the examination of AI search, we focused on the performance of the model under different scenarios of application. The domestic large model performs relatively well in science and technology, culture, business and entertainment scenarios, showing good ability to retrieve and integrate information while accurately grasping the timeliness of information. However, in stock and sports scenarios, there is still obvious room for improvement for domestic big models.
For example, in the process of AI search, the model needs to accurately disassemble the user's search needs, search for the correct relevant web pages with accurate time-sensitive information, and finally integrate the information to form a copy of the answer results that are practical for the user. From the current observation, domestic big models sometimes cannot accurately analyze the search needs, and sometimes refer to irrelevant web content in the process of integrating information, which leads to the poor performance of domestic big models in certain scenarios.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles


No comments...