
AI Engineering Academy: 2.2 Basic RAG Implementation

present (sb for a job etc)
Search Enhanced Generation (RAG) is a powerful technique that combines the benefits of large-scale language modeling with the ability to retrieve relevant information from a knowledge base. This approach improves the quality and accuracy of generated responses by basing them on specific retrieved information.a This notebook is intended to provide a clear and concise introduction to RAG for beginners who want to understand and implement this technique.
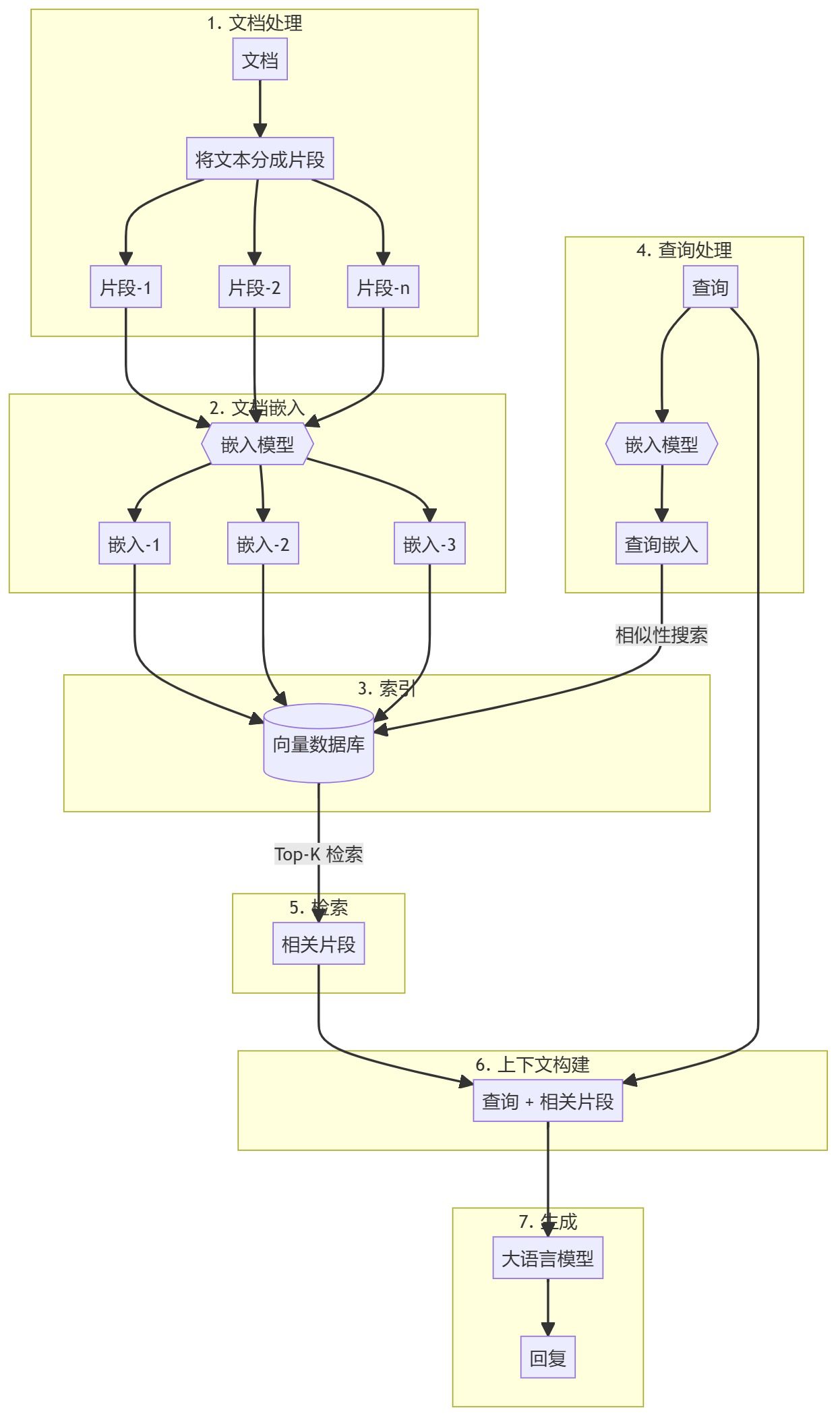
RAG Process
commencement
Notebook
You can run the Notebook provided in this repository. https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/01_Basic_RAG
chat application
- Install dependencies:
pip install -r requirements.txt - Run the application:
python app.py - Dynamic import of data:
python app.py --ingest --data_dir /path/to/documents
server (computer)
Use the following command to run the server:
python server.py
The server provides two endpoints:
/api/ingest/api/query
locomotive
Traditional language models generate text based on patterns learned from training data. However, they may struggle to provide accurate responses when faced with queries that require specific, updated, or specialized information.RAG addresses this limitation by introducing a retrieval step that provides the language model with relevant context to generate more accurate answers.
Methodological details
Document preprocessing and vector store creation
- Document chunking: Pre-process and split knowledge base documents (e.g. PDFs, articles) into manageable chunks. This creates a searchable corpus for efficient retrieval processes.
- Generate Embedding: Each block is converted into a vector representation using a pre-trained embedding (e.g., OpenAI's embedding). These documents are then stored in a vector database (e.g. Qdrant) for efficient similarity search.
Retrieval Augmentation Generation (RAG) Workflow
- Query Input:: Users provide queries that need to be answered.
- search step: Embed the query as a vector using the same embedding model as the documents. Then performs a similarity search in the vector database to find the most relevant block of documents.
- Generation steps: Pass the retrieved chunks of documents as additional context to a large language model (e.g., GPT-4). The model uses this context to generate more accurate and relevant responses.
Key features of the RAG
- contextual relevance: By generating responses based on the actual information retrieved, RAG models can generate more contextually relevant and accurate answers.
- scalability: The retrieval step can be extended to handle large knowledge bases, enabling the model to extract content from massive amounts of information.
- Use case flexibility: RAG can be adapted to a variety of application scenarios, including Q&A, summary generation, recommender systems, and more.
- Improved accuracy: A combination of retrieval and generation often produces more accurate results, especially for queries that require specific or cold information.
Advantages of this method
- Combining the benefits of retrieval and generation: RAG effectively blends a retrieval-based approach with a generative model for both accurate fact finding and natural language generation.
- Enhanced handling of long-tail queries: The method performs particularly well for queries that require specific and uncommon information.
- Domain Adaptation: Retrieval mechanisms can be tuned for specific domains to ensure that the responses generated are based on the most relevant and accurate domain-specific information.
reach a verdict
Retrieval-Augmented Generation (RAG) is an innovative fusion of retrieval and generation techniques that effectively enhances language modeling by basing the output on relevant external information. This approach is particularly valuable in response scenarios that require precise and context-aware answers (e.g., customer support, academic research, etc.). As AI continues to evolve, RAG stands out for its potential to build more reliable and context-sensitive AI systems.
pre-conditions
- Preferred Python 3.11
- Jupyter Notebook or JupyterLab
- LLM API Key
- Any LLM can be used. in this notebook, we use OpenAI and GPT-4o-mini.
With these steps, you can implement a basic RAG system that incorporates real-world, up-to-date information and enhances the efficiency of language modeling in a variety of applications.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles



No comments...