AI Engineering Academy: 2.12 Self-Query RAG: Enhanced Retrieval Augmentation Generation with Metadata Filtering

present (sb for a job etc)
Self-Query RAG (SQRAG) is an advanced retrieval augmentation generation (RAG) approach that enhances traditional RAG by introducing metadata extraction in the ingestion phase and intelligent query parsing in the retrieval phase RAG Process.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/07_Self_Query_RAG
locomotive
Traditional RAG systems often struggle to handle complex queries involving semantic similarity and specific metadata constraints. Self-querying RAG addresses these challenges by leveraging metadata and intelligently parsing user queries using the Large Language Model (LLM).
Methodological details
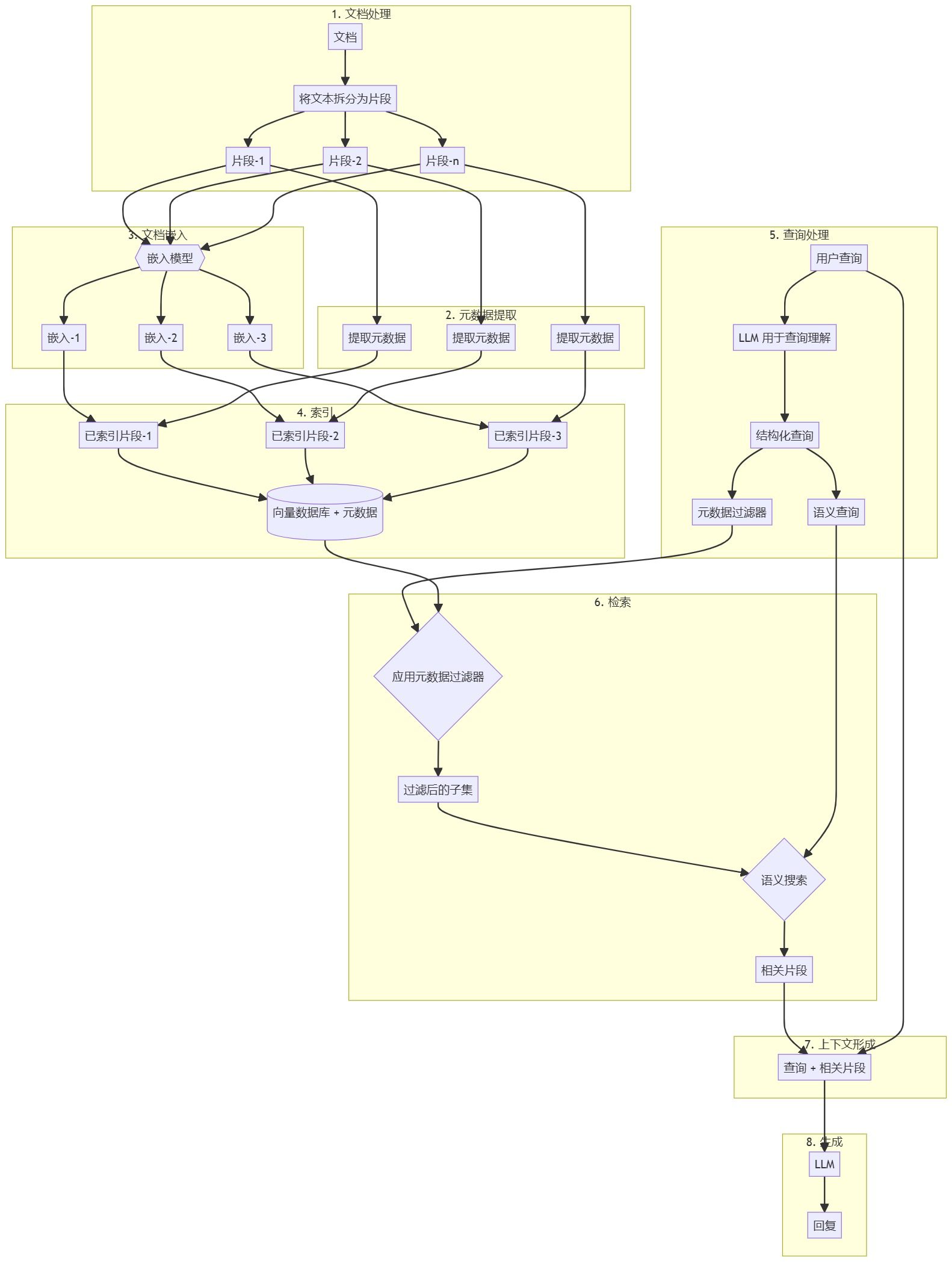
Document preprocessing and vector store creation
- Split documents into manageable chunks.
- Extract metadata (e.g. date, author, category) from each chunk.
- Embed each nugget using the appropriate embedding model.
- Index the nuggets, their embedding vectors and associated metadata into a vector database.
Self-querying RAG workflow
- Users submit natural language queries.
- Parsing queries using Large Language Modeling (LLM) to understand user intent and query structure.
- LLM Generation:
a) Query-based metadata filtering conditions.
b) Semantic search queries for content-related retrieval. - Apply metadata filters to narrow your search.
- Performs semantic search on a filtered subset.
- The retrieved document chunks are combined with the original user query to form a context.
- Pass the context to the Large Language Model (LLM) to generate the final answer.
Key Features of Self-Querying RAG
- Metadata extraction: Enhance document representation with structured information.
- Intelligent Query Resolution: Utilize LLM to understand complex user queries.
- hybrid search: Combining metadata filtering and semantic search.
- Flexible Search: Allows users to implicitly specify metadata constraints in natural language.
Benefits of this method
- Improve search accuracy: Metadata filters help narrow down the search to more relevant documents.
- Handling complex queries: can interpret and respond to queries involving content similarity and metadata constraints.
- Efficient retrieval: Metadata filtering can significantly reduce the number of documents requiring semantic search.
- Enhanced Context: Metadata provides additional structured information that improves response generation.
reach a verdict
Self-query RAG enhances the traditional RAG process by introducing metadata extraction and intelligent query parsing. This approach makes retrieval more accurate and efficient, especially for complex queries involving semantic similarity and specific metadata constraints. By leveraging the Large Language Model (LLM) for query understanding, self-querying RAG provides AI Q&A systems with more accurate and contextually relevant responses.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...