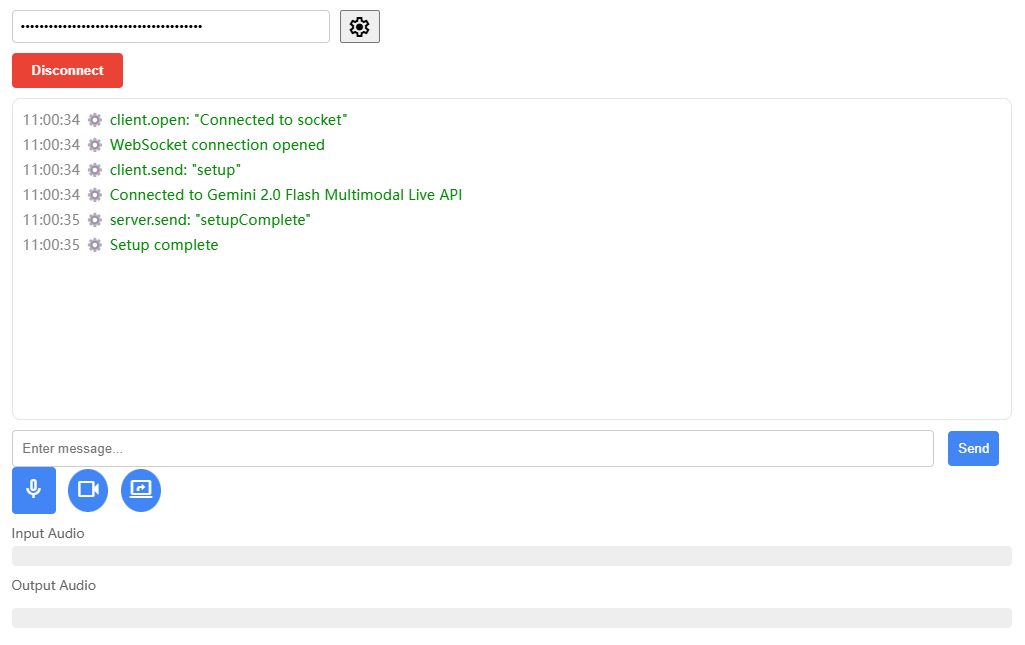
Zonos: Hochwertige Sprachsynthese- und Sprachklonierungswerkzeuge

Allgemeine Einführung
Zonos ist ein von Zyphra entwickeltes Open-Source-Werkzeug zur Sprachsynthese und zum Klonen von Sprache. Die Version Zonos-v0.1 verwendet erweiterte Transformator Die Sprachklonfunktion von Zonos erzeugt nach nur wenigen Sekunden Referenzaudio eine hochwertige Sprachausgabe. Das Tool unterstützt mehrere Sprachen, darunter Englisch, Japanisch, Chinesisch, Französisch und Deutsch, und bietet eine fein abgestufte Kontrolle über Audioqualität und Emotionen. Die Funktion "Speech Clone" von Zonos erzeugt nach nur wenigen Sekunden Referenzaudio eine äußerst natürliche Sprachausgabe. Benutzer können Modellgewichte und Beispielcode über GitHub erhalten und es auf Huggingface ausprobieren.

Funktionsliste
- Abtastfreies TTS-SprachklonenEingabe von Text und einer 10-30 Sekunden langen Sprechprobe, um eine qualitativ hochwertige Sprachausgabe zu erzeugen.
- Audio-Präfix-Eingang: Hinzufügen von Text- und Audio-Präfixen für eine umfassendere Sprechererkennung.
- Unterstützung mehrerer SprachenEnglisch, Japanisch, Chinesisch, Französisch und Deutsch werden unterstützt.
- Audioqualität und EmotionskontrolleErmöglicht eine fein abgestufte Steuerung vieler Aspekte des erzeugten Tons, einschließlich Sprechgeschwindigkeit, Tonhöhenvariation, Tonqualität und Emotionen (z. B. Freude, Angst, Traurigkeit und Wut).
- Spracherzeugung in EchtzeitUnterstützt die Echtzeit-Erzeugung von originalgetreuer Sprache.
Hilfe verwenden
Einbauverfahren
- Klonprojekt: Führen Sie den folgenden Befehl in einem Terminal aus, um das Zonos-Projekt zu klonen:
bash
git clone https://github.com/Zyphra/Zonos.git
cd Zonos - Installation von Abhängigkeiten: Verwenden Sie den folgenden Befehl, um die erforderlichen Python-Abhängigkeiten zu installieren:
bash
pip install -r requirements.txt - Download Modellgewichte: Laden Sie die benötigten Modellgewichte von Huggingface herunter und legen Sie sie im Projektverzeichnis ab.
Verwendung
- Modelle ladenLaden Sie das Zonos-Modell in die Python-Umgebung:
import torch import torchaudio from zonos.model import Zonos from zonos.conditioning import make_cond_dict model = Zonos.from_pretrained("Zyphra/Zonos-v0.1-transformer", device="cuda") - Sprache generierenText- und Sprecherbeispiele zur Erzeugung von Sprachausgabe bereitstellen:
python
wav, sampling_rate = torchaudio.load("assets/exampleaudio.mp3")
speaker = model.make_speaker_embedding(wav, sampling_rate)
cond_dict = make_cond_dict(text="Hello, world!", speaker=speaker, language="en-us")
conditioning = model.prepare_conditioning(cond_dict)
codes = model.generate(conditioning)
wavs = model.autoencoder.decode(codes).cpu()
torchaudio.save("sample.wav", wavs[0], model.autoencoder.sampling_rate) - Verwendung der Gradio-SchnittstelleDie Gradio-Schnittstelle wird für die Spracherzeugung empfohlen:
bashDies erzeugt eine
uv run gradio_interface.py
# 或者
python gradio_interface.pysample.wavDatei, die im Stammverzeichnis des Projekts gespeichert ist.
Detaillierte Funktionsabläufe
- Abtastfreies TTS-Sprachklonen::
- Nach Eingabe des gewünschten Textes und einer 10-30 Sekunden langen Hörprobe des Sprechers erzeugt das Modell eine qualitativ hochwertige Sprachausgabe.
- Audio-Präfix-Eingang::
- Fügen Sie Text- und Audiopräfixe hinzu, um die Sprechererkennung zu verbessern. Zum Beispiel können Flüsterton-Präfixe verwendet werden, um Flüstereffekte zu erzeugen.
- Unterstützung mehrerer Sprachen::
- Wählen Sie die gewünschte Sprache (z.B. Englisch, Japanisch, Chinesisch, Französisch oder Deutsch) und das Modell erzeugt die Sprachausgabe in der entsprechenden Sprache.
- Audioqualität und Emotionskontrolle::
- Verwenden Sie die Funktion "Bedingte Einstellungen" des Modells, um alle Aspekte des erzeugten Audios genau zu steuern, einschließlich Sprechgeschwindigkeit, Tonhöhenvariation, Audioqualität und Emotionen (z. B. Freude, Angst, Traurigkeit und Wut).
- Spracherzeugung in Echtzeit::
- Verwenden Sie die Gradio-Schnittstelle oder andere Echtzeit-Generierungsmethoden, um schnell eine realitätsnahe Sprache zu erzeugen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...