
Ein Artikel zum Verständnis von RAG (Retrieval Augmented Generation), dem Konzept der theoretischen Einführung + Code-Praxis
I. LLMs haben bereits starke Fähigkeiten, warum brauchen wir RAG (Retrieval Augmentation Generation)?
Das LLM hat zwar seine Fähigkeiten unter Beweis gestellt, aber es gibt noch einige Herausforderungen, die Anlass zur Sorge geben:
- Das Illusionsproblem: LLM verwendet einen statistisch basierten probabilistischen Ansatz, um Text Wort für Wort zu generieren, ein Mechanismus, der von Natur aus zur Möglichkeit von Ausgaben führt, die logisch streng zu sein scheinen, aber nicht auf Fakten beruhen, die so genannten "grandiosen fiktiven Aussagen";
- (a) Probleme mit der Aktualität: Mit zunehmender Größe des LLM steigen die Kosten und die Zykluszeit des Trainings. Infolgedessen ist es schwierig, Daten mit aktuellen Informationen in den Modelllernprozess einzubeziehen, wodurch das LLM weniger in der Lage ist, zeitkritische Fragen wie "Bitte schlagen Sie den aktuellen Lieblingsfilm vor" zu bewältigen;
- Datensicherheitsprobleme: Das generische LLM verfügt nicht über interne Unternehmensdaten und Benutzerdaten. Wenn Unternehmen das LLM unter der Prämisse der Gewährleistung der Sicherheit nutzen wollen, ist es am besten, alle Daten lokal zu speichern, und alle Geschäftsberechnungen der Unternehmensdaten werden lokal durchgeführt. Das große Online-Modell erfüllt lediglich eine Zusammenfassungsfunktion;
II. die RAG einführen?
RAG (Retrieval Augmented Generation) ist ein technologischer Rahmen, dessen Kern darin besteht, dass das LLM, wenn es mit der Aufgabe konfrontiert wird, eine Frage zu beantworten oder einen Text zu erstellen, zunächst die umfangreiche Dokumentenbibliothek durchsucht und die Materialien herausfiltert, die in engem Zusammenhang mit der Aufgabe stehen, und dann den anschließenden Prozess der Antwortgenerierung oder der Texterstellung auf der Grundlage dieser Materialien präzise leitet, um auf diese Weise die Genauigkeit und Zuverlässigkeit der Modellausgabe zu verbessern. Ziel ist es, die Genauigkeit und Zuverlässigkeit der Modellausgabe auf diese Weise zu verbessern.
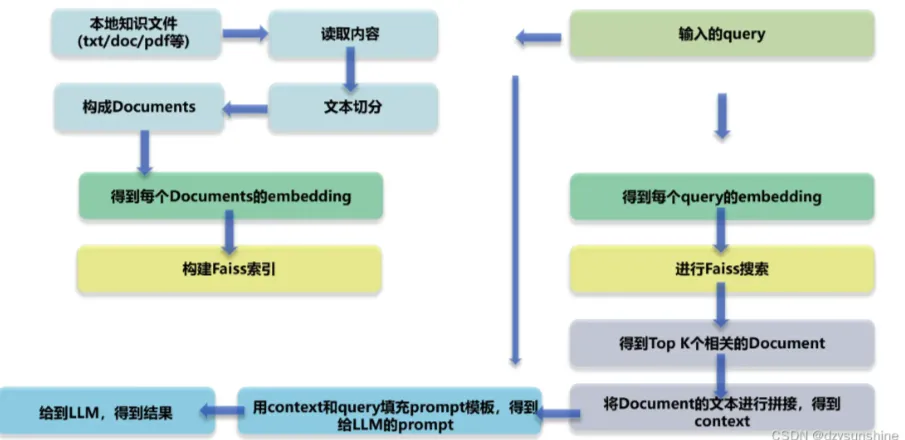
RAG Diagramm der technischen Architektur
III. was sind die Hauptmodule der RAG?
- Modul 1: Layout-Analyse
- Lesen von lokalen Wissensdateien (pdf, txt, html, doc, excel, png, jpg, voice, etc.)
- Wiederherstellung von Wissensdokumenten
- Modul II: Aufbau der Wissensbasis
- Wissen Textsegmentierung und Konstruktion von Doc-Text
- Doc-Text einbetten
- Doc Text Build Index
- Modul 3: Feinabstimmung des großen Modells
- Modul IV: RAG-basiertes Wissensquiz
- Einbettung von Benutzeranfragen
- Abfrage Rückruf
- Abfragesortierung
- Die wichtigsten K relevanten Docs wurden zusammengefügt, um den Kontext zu erstellen
- Erstellung von Prompts auf der Grundlage von Abfrage und Kontext
- Geben Sie die Eingabeaufforderung an das große Modell weiter, um die Antwort zu generieren
Was sind die Vorteile von RAG gegenüber der direkten Verwendung von LLMs für Quizze?
Der RAG-Ansatz (Retrieval Augmented Generation) gibt Entwicklern die Möglichkeit, die Genauigkeit ihrer Antworten erheblich zu verbessern, ohne große Modelle für jede spezifische Aufgabe neu trainieren zu müssen, indem sie einfach eine Verbindung zu einer externen Wissensbasis herstellen, die mit zusätzlichen Informationsressourcen gespeist werden kann. Dieser Ansatz eignet sich besonders für Aufgaben, die in hohem Maße von Fachwissen abhängig sind. Nachfolgend sind die wichtigsten Vorteile des RAG-Modells aufgeführt:
- Skalierbarkeit: Reduzieren Sie die Modellgröße und den Trainingsaufwand und vereinfachen Sie gleichzeitig den Prozess der Erweiterung und Aktualisierung der Wissensbasis.
- Genauigkeit: Durch die Angabe von Quellen können die Nutzer die Glaubwürdigkeit der Antworten überprüfen, was wiederum ihr Vertrauen in die Modellergebnisse stärkt.
- Kontrollierbarkeit: Unterstützt die flexible Aktualisierung und personalisierte Konfiguration von Wissensinhalten.
- Interpretierbarkeit: Anzeige der Sucheinträge, von denen die Modellvorhersagen abhängen, um das Verständnis und die Transparenz zu verbessern.
- Vielseitigkeit: RAG kann auf eine Vielzahl von Anwendungsszenarien abgestimmt und angepasst werden und deckt Bereiche wie Fragen und Antworten, Textzusammenfassung und Dialogsysteme ab.
- Aktualität: Durch den Einsatz von Retrieval-Techniken zur Erfassung der neuesten Informationsentwicklungen wird sichergestellt, dass die Antworten sowohl unmittelbar als auch präzise sind - ein klarer Vorteil gegenüber Sprachmodellen, die sich nur auf intrinsische Trainingsdaten stützen.
- Domänenanpassung: Durch die Zuordnung von Textdatensätzen zu bestimmten Branchen oder Domänen ist die RAG in der Lage, gezielte fachliche Unterstützung zu bieten.
- Sicherheit: Durch die Implementierung von Rollenpartitionierung und Sicherheitskontrolle auf Datenbankebene stärkt RAG effektiv die Verwaltung der Datennutzung und demonstriert eine höhere Sicherheit als die potenzielle Mehrdeutigkeit von Feinabstimmungsmodellen für die Verwaltung von Datenrechten.
V. Vergleichen Sie RAG und SFT und sagen Sie uns, worin die Unterschiede bestehen?
In der Tat ist die SFT eine der häufigsten und grundlegenden Lösungen für die oben genannten Probleme des LLM, und sie ist auch ein grundlegender Schritt bei der Realisierung von LLM-Anwendungen. Dann ist es notwendig, die beiden Ansätze in mehreren Dimensionen zu vergleichen:
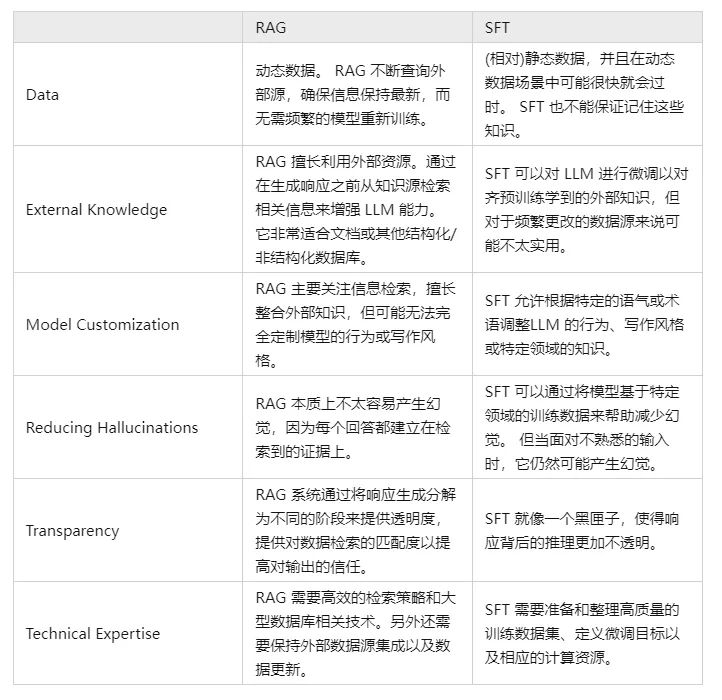
Natürlich sind diese beiden Methoden kein Entweder-Oder, und es ist sinnvoll und notwendig, die geschäftlichen Anforderungen mit den Vorteilen beider Methoden zu kombinieren und sie auf sinnvolle Weise einzusetzen.
Modul 1: Layout-Analyse
Warum brauche ich eine Layout-Analyse?
Obwohl der Kernwert der RAG (Retrieval Augmented Generation)-Technologie in der Kombination von Retrieval und Generierung liegt, um die Genauigkeit und Kohärenz von Textinhalten zu verbessern, können ihre funktionalen Grenzen erweitert werden, um die Layout-Analyse in spezifischen Anwendungsbereichen einzubeziehen, wie z.B. Dokumenten-Parsing, intelligentes Authoring und die Konstruktion von Dialogen, insbesondere wenn strukturierte oder halbstrukturierte Informationen verarbeitet werden müssen.
Das liegt daran, dass diese Art von Informationen oft in eine bestimmte Layout-Struktur eingebettet ist und ein tiefes Verständnis der Seitenelemente und ihrer Zusammenhänge erfordert.
Wenn das RAG-Modell mit Datenquellen konfrontiert wird, die reichhaltige multimediale oder multimodale Komponenten enthalten, wie z.B. Webseiten, PDF-Dateien, Rich-Text-Datensätze, Word-Dokumente, Bilddaten, Sprachclips, Tabellendaten und andere komplexe Inhalte, ist es von entscheidender Bedeutung, über eine grundlegende Layout-Analysefähigkeit zu verfügen, um solche nicht-textuellen Informationen effizient aufnehmen und nutzen zu können. Diese Fähigkeit hilft dem Modell, die verschiedenen Informationseinheiten genau zu analysieren und sie erfolgreich in eine sinnvolle Gesamtinterpretation zu integrieren.
Schritt 1: Beschaffung von Dokumenten über lokale Kenntnisse
Frage 1: Wie kann man lokale Wissensdokumente erwerben?
Der Zugriff auf lokale Wissensdateien umfasst den Prozess der Extraktion von Informationen aus verschiedenen Datenquellen (z. B. .txt, .pdf, .html, .doc, .xlsx, .png, .jpg, Audiodateien usw.). Für die verschiedenen Dateitypen werden spezifische Zugriffs- und Analysestrategien benötigt, um das in ihnen enthaltene Wissen effektiv zu nutzen. Im Folgenden werden wir die Zugriffsmethoden und Schwierigkeiten für verschiedene Datenquellen vorstellen.
Q2: Wie erhalte ich den Inhalt von Rich-Text-Texten?
- Einführung: Rich Text ist vor allem in der txt-Datei gespeichert, weil das Layout ist relativ ordentlich, so dass die Art und Weise zu bekommen relativ einfach
- Praktische Fähigkeiten:
- [Layout-Analyse - Lesen von Rich-Text-Dokumenten]
Frage 3: Wie erhält man den Inhalt des PDF-Dokuments?
- Einführung: PDF-Dokumente in den Daten ist komplexer, einschließlich Text, Bilder, Tabellen und andere verschiedene Arten von Daten, so dass die Parsing-Prozess wird komplexer sein!
- Praktische Fähigkeiten:
- Layout-Analyse - PDF-Parser pdfplumber
- Layout-Analyse--PDF-Parser PyMuPDF
Frage 4: Wie erhält man den Inhalt eines HTML-Dokuments?
- Einführung: PDF-Dokumente in den Daten ist komplexer, einschließlich Text, Bilder, Tabellen und andere verschiedene Arten von Daten, so dass die Parsing-Prozess wird komplexer sein!
- Praktische Fähigkeiten:
- Layout-Analyse - HTML-Parsing BeautifulSoup
q5: Wie erhalte ich den Inhalt eines Dokuments?
- Einführung: Die Daten eines Dokuments sind komplexer und enthalten Text, Bilder, Tabellen und andere verschiedene Arten von Daten, so dass der Parsing-Prozess komplexer wird!
- Praktische Fähigkeiten:
- Layout-Analyse--Docx-Parsing-Artefakt python-docx]
Frage 6: Wie kann ich mit OCR den Inhalt eines Bildes ermitteln?
- Einführung: Optische Zeichenerkennung (Optical Character Recognition) Zeichen Recognition, OCR) ist der Prozess der Analyse und Erkennung von Bilddateien mit Textinformationen, um Text- und Layoutinformationen zu erhalten. Es bedeutet auch, dass der Text im Bild erkannt und in Form von Text zurückgegeben wird.
- Gedanken:
- Texterkennung: Erkennung von gut platzierten Textbereichen, das Hauptproblem ist, das Problem zu lösen, was jeder Text ist, der Textbereich im Bild in die Umwandlung von Zeicheninformationen.
- Texterkennung: Das gelöste Problem besteht darin, wo Text vorhanden ist und wie groß die Textbereiche sind;
- Aktuelles Open-Source-OCR-Projekt
- Tesserakt
- PaddleOCR
- EasyOCR
- chineseocr
- chineseocr_lite
- TrWebOCR
- cnocr
- hn_ocr
- Theoretische Studien:
- Layout-Analyse - Picture Parsing Tool OCR]
- Praktische Fähigkeiten:
- [Layout-Analyse - OCR-Tesserakt]
- [Layout-Analyse - OCR Magic PaddleOCR]
- [Layout-Analyse - OCR-Artefakte hn_ocr]
Q7: Wie kann man ASR verwenden, um Sprachinhalte zu erhalten?
- Alias: Automatische Spracherkennung AutomaTlc Speech RecogniTlon, (ASR)
- Einleitung: Die Umwandlung eines Sprachsignals in eine entsprechende Textnachricht ist eine Art "maschinelles Hörsystem", das es der Maschine ermöglicht, das Sprachsignal durch Erkennen und Verstehen in einen entsprechenden Text oder Befehl umzuwandeln.
- Ziel: Umwandlung des lexikalischen Inhalts menschlicher Sprache in computerlesbare Eingaben (z. B. Tastenanschläge, Binärcodes oder Zeichenfolgen).
- Gedanken:
- Akustisches Signal Pre-Processing: um zu extrahieren Features effektiver oft auch müssen erfasst werden Sound-Signal-Filterung, Framing und andere Pre-Processing-Arbeit, das Signal zu analysieren, aus dem ursprünglichen Signal-Extraktion;
- Merkmalsextraktion: Konvertierung des Schallsignals vom Zeitbereich in den Frequenzbereich, um geeignete Merkmalsvektoren für das akustische Modell zu erhalten.
- Akustische Modellierung: Berechnung einer Punktzahl für jeden Merkmalsvektor für akustische Merkmale auf der Grundlage der akustischen Eigenschaften; die
- Sprachmodellierung: Berechnung der Wahrscheinlichkeit, dass das Tonsignal einer Folge möglicher Phrasen entspricht, auf der Grundlage linguistisch relevanter Theorien.
- Wörterbuch und Dekodierung: Auf der Grundlage des vorhandenen Wörterbuchs wird die Abfolge der Phrasen dekodiert, um die endgültige mögliche Textdarstellung zu erhalten
- Theorie-Tutorial:
- Spracherkennung für die Layout-Analyse
- Praktische Fähigkeiten:
- [Speech-to-Text-Layout-Analyse]
- Layout-Analyse von WeTextProcessing
- [Layout-Analyse - ASR-Werkzeug Wenet]
- Layout-Analyse ASR-Schulung
Schritt 2: Wiederherstellung von Wissensdokumenten
Frage 1: Warum ist die Wiederherstellung von Wissensdokumenten erforderlich?
Bei der Erfassung lokaler Wissensdokumente ist es nach dem Lesen von Daten mit mehreren Quellen (txt, pdf, html, doc, excel, png, jpg, voice usw.) leicht möglich, einen mehrzeiligen Absatz in mehrere Absätze aufzuteilen, was dazu führt, dass die Absätze aufgespalten werden, so dass es notwendig ist, die Absätze entsprechend der Inhaltslogik neu zu organisieren.
Frage 2: Wie kann ich Wissensdokumente wiederherstellen?
- Methodik I: Regelbasierte Wiederherstellung von Wissensdokumenten
- Methode 2: Kontext-Splicing auf der Grundlage von Bert NSP
Schritt 3: Layout-Analyse - Optimierungsstrategien
- Theoretische Studien:
- [Layout-Analyse - Optimierungsstrategien]
Schritt 4: Hausaufgaben
- Aufgabenbeschreibung: Verwenden Sie die oben genannte Methodik, um das Layout des [ChatGLM Evaluation Challenge - Finance Track Dataset] des [SMP 2023 ChatGLM Finance Big Model Challenge] zu analysieren.
- Wirksamkeit der Aufgabe: Analyse der Wirksamkeit und Leistung der verschiedenen Methoden
Modul II: Aufbau der Wissensbasis
Warum brauchen Sie eine Wissensdatenbank?
Der Aufbau einer Wissensbasis in RAG (Retrieval-Augmented Generation) ist aus mehreren Gründen von entscheidender Bedeutung, unter anderem aus folgenden Gründen
- Erweiterung der Modellfähigkeiten: Groß angelegte Sprachmodelle wie die GPT-Familie verfügen zwar über leistungsstarke Fähigkeiten zur Spracherzeugung und zum Sprachverständnis, sind aber durch den Umfang des Trainingsdatensatzes begrenzt und können einige Fragen, die auf spezifischen Fakten oder detaillierten Hintergrundinformationen beruhen, möglicherweise nicht genau beantworten. Durch den Aufbau einer Wissensbasis kann die RAG die eigenen Wissensbeschränkungen des Modells ergänzen, so dass das Modell die aktuellsten und genauesten Informationen abrufen kann, um Antworten zu generieren.
- Informationsaktualisierung in Echtzeit: Die Wissensdatenbank kann in Echtzeit aktualisiert und erweitert werden, um sicherzustellen, dass das Modell Zugang zu den neuesten Wissensinhalten hat, was besonders wichtig ist, wenn es um zeitkritische Informationen wie Nachrichten, wissenschaftliche und technologische Fortschritte usw. geht.
- Verbesserte Genauigkeit: Das RAG kombiniert sowohl Abfrage- als auch Generierungsprozesse, um die Genauigkeit bei der Beantwortung von Fragen zu verbessern, indem relevante Dokumente abgerufen werden, bevor Antworten generiert werden. Auf diese Weise basieren die vom Modell generierten Antworten nicht nur auf seinem internen parametrisierten Wissen, sondern auch auf einer externen Wissensbasis aus zuverlässigen Quellen.
- Verringerung von Overfitting und Halluzinationen: Große Modelle können sich manchmal zu sehr auf intrinsische Muster verlassen und unter Halluzinationen leiden, d.h. sie erzeugen Antworten, die vernünftig erscheinen, es aber nicht sind. Die RAG kann die Wahrscheinlichkeit solcher Fehler verringern, indem sie endgültige Beweise aus der Wissensbasis zitiert.
- Verbesserte Interpretierbarkeit: Die RAG liefert nicht nur die Antwort, sondern verweist auch auf die Quelle der Antwort, was die Transparenz und Glaubwürdigkeit der vom Modell generierten Ergebnisse erhöht.
- Unterstützung für Personalisierungs- und Privatisierungsbedürfnisse: Unternehmen oder Einzelnutzer können exklusive Wissensdatenbanken aufbauen, um den Bedürfnissen bestimmter Bereiche oder privater Anpassungen gerecht zu werden, wodurch das große Modell besser in der Lage ist, spezifische Szenarien und Geschäfte zu bedienen.
Zusammenfassend lässt sich sagen, dass der Aufbau einer Wissensbasis einer der wichtigsten Mechanismen für RAG-Modelle ist, um eine effiziente und genaue Abfrage und Generierung von Antworten zu erreichen, was die Leistung und Zuverlässigkeit des Modells in praktischen Anwendungen erheblich verbessert.
Schritt 1: Chunking von Wissenstexten
- Warum muss ich den Text in Stücke schneiden?
- Risiko fehlender Informationen: Der Versuch, die Einbettungsvektoren für das gesamte Dokument auf einmal zu extrahieren, erfasst zwar den Gesamtkontext, lässt aber möglicherweise viele wichtige themenspezifische Informationen außer Acht, was dazu führen kann, dass weniger genaue oder fehlende Informationen generiert werden.
- Begrenzung der Chunk-Größe: Die Chunk-Größe ist ein wichtiger limitierender Faktor bei der Verwendung von Modellen wie OpenAI. Das GPT-4-Modell hat zum Beispiel eine Fenstergrößenbeschränkung von 32K. Obwohl diese Grenze in den meisten Fällen kein Problem darstellt, ist es wichtig, die Chunk-Größe von Anfang an zu berücksichtigen.
- Es gibt zwei Hauptfaktoren zu berücksichtigen:
- Token Einschränkung Fall für die Einbettung Modelle;
- Die Auswirkung der semantischen Integrität auf die Gesamteffektivität des Abrufs;
- Praktische Fähigkeiten:
- [Aufbau einer Wissensbasis - Chunking von Wissenstexten]
- [Aufbau einer Wissensbasis - Optimierungsstrategien für das Slicing und Dicing von Dokumenten]
Schritt 2: Vektorisierung der Dokumente (Embdeeing)
q1: Was ist Docs-Vektorisierung (embdeeing)?
Die Einbettung ist auch eine informationsintensive Darstellung der semantischen Bedeutung eines Textes, wobei jede Einbettung ein Vektor von Gleitkommazahlen ist, so dass der Abstand zwischen zwei Einbettungen im Vektorraum mit der semantischen Ähnlichkeit zwischen den beiden Eingaben im Originalformat korreliert. Wenn zum Beispiel zwei Texte ähnlich sind, sollten auch ihre Vektordarstellungen ähnlich sein, und diese Menge von Array-Darstellungen im Vektorraum beschreibt die subtilen Merkmalsunterschiede zwischen den Texten. Einfach ausgedrückt, hilft die Einbettung Computern, die "Bedeutung" menschlicher Informationen zu verstehen. Die Einbettung kann verwendet werden, um die "Relevanz" von Merkmalen in Texten, Bildern, Videos oder anderen Informationen zu ermitteln, was häufig auf der Anwendungsebene bei der Suche, Empfehlung, Klassifizierung und anderen Anwendungen genutzt wird. Diese Art der Korrelation wird häufig bei der Suche, Empfehlung, Klassifizierung und Clusterbildung verwendet.
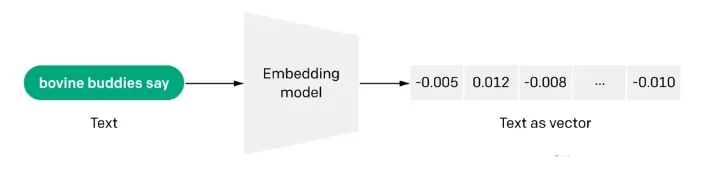
Frage 2: Wie funktioniert die Einbettung?
Als Beispiel seien hier drei Sätze genannt:
- "Die Katze jagt die Maus".
- "Das Kätzchen jagt Nagetiere".
- "Ich mag Schinkensandwichs." Ich mag Schinkensandwichs.
Wenn Menschen diese drei Sätze einordnen würden, hätten Satz 1 und Satz 2 fast die gleiche Bedeutung, während Satz 3 völlig anders wäre. Wir sehen aber, dass in den englischen Originalsätzen nur "The" in Satz 1 und Satz 2 gleich ist, und keine anderen Wörter gleich sind. Wie kann ein Computer die Bedeutung der ersten beiden Sätze verstehen? Die Einbettung komprimiert diskrete Informationen (Wörter und Symbole) in verteilte Daten mit kontinuierlichem Wert (Vektoren). Wenn wir den vorherigen Satz in ein Diagramm einzeichnen würden, könnte es etwa so aussehen:
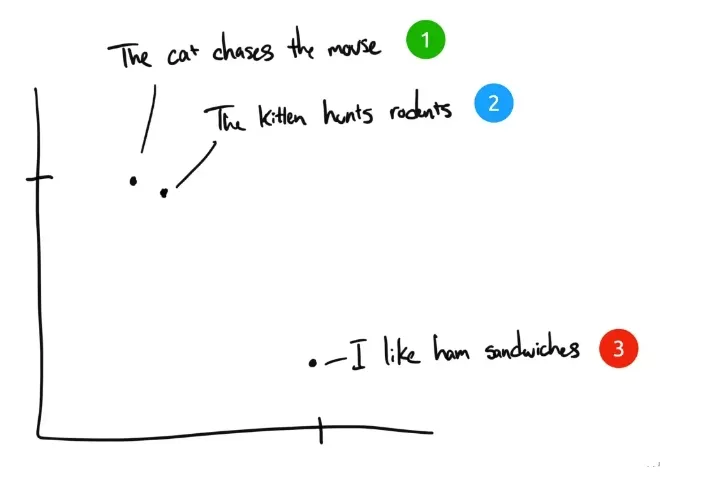
Nachdem der Text durch Embedding in einen für den Computer verständlichen mehrdimensionalen vektorisierten Raum komprimiert wurde, werden die Sätze 1 und 2 nahe beieinander eingezeichnet, da sie ähnliche Bedeutungen haben. Satz 3 ist weiter entfernt, weil er nicht mit ihnen verwandt ist. Wenn wir einen vierten Satz hätten, "Sally aß Schweizer Käse", würde er wahrscheinlich irgendwo zwischen Satz 3 (Käse kommt auf Sandwiches) und Satz 1 (Mäuse mögen Schweizer Käse) stehen.
Q3: Vorteile des semantischen Retrieval-Ansatzes von Embedding gegenüber dem Keyword Retrieval?
- Semantisches Verständnis: Einbettungsbasierte Retrievalmethoden stellen Text durch Wortvektoren dar, wodurch das Modell semantische Assoziationen zwischen Wörtern erfassen kann, im Gegensatz zum schlagwortbasierten Retrieval, das sich auf die wörtliche Übereinstimmung konzentriert und semantische Verbindungen zwischen Wörtern ignorieren kann.
- Fehlertoleranz: Da einbettungsbasierte Methoden in der Lage sind, die Beziehung zwischen Wörtern zu verstehen, sind sie vorteilhafter im Umgang mit Fällen wie Rechtschreibfehlern, Synonymen und Beinahe-Synonymen. Während stichwortbasierte Abrufmethoden in diesen Fällen relativ schwach sind.
- Unterstützung mehrerer Sprachen: Viele Einbettungsmethoden können mehrere Sprachen unterstützen, was die sprachübergreifende Textsuche erleichtert. So können Sie z. B. chinesische Eingaben verwenden, um englische Textinhalte abzufragen, während dies bei stichwortbasierten Abfragemethoden nur schwer möglich ist.
- Kontextbezogenes Verständnis: Einbettungsbasierte Methoden sind vorteilhafter, wenn es um mehrere Bedeutungen eines Wortes geht, da sie in der Lage sind, den Wörtern je nach Kontext unterschiedliche Vektordarstellungen zuzuordnen. Im Gegensatz dazu sind schlagwortbasierte Retrievalmethoden möglicherweise nicht in der Lage, die Bedeutung desselben Wortes in verschiedenen Kontexten gut zu unterscheiden.
Q4: Wo liegen die Grenzen der eingebetteten Suche?
- Beschränkungen der Wortanzahl: Selbst wenn die Textfragmente, die am besten zur Anfrage passen, mit Hilfe der Einbettungstechnologie für die Referenz des groß angelegten Modells ausgewählt werden, besteht immer noch die Beschränkung der Vokabelanzahl. Wenn die Abfrage einen großen Textbereich abdeckt, wird zur Kontrolle der Menge des in das Modell eingebrachten kontextuellen Vokabulars in der Regel ein TopK-Schwellenwert K für die Abfrageergebnisse festgelegt, was jedoch unweigerlich zu dem Problem der Auslassung von Informationen führt.
- Nur Textdaten: GPT-3.5 und viele groß angelegte Sprachmodelle verfügen derzeit noch nicht über Bilderkennungsfunktionen. Bei der Wissenssuche sind jedoch viele wichtige Informationen oft auf die Kombination von Grafiken und Text angewiesen, um sie vollständig zu verstehen. So ist es zum Beispiel schwierig, die Bedeutung von schematischen Diagrammen in wissenschaftlichen Abhandlungen und Datendiagrammen in Finanzberichten allein auf der Grundlage von Text zu erfassen.
- (b) Große Modellimprovisation: Wenn die gefundene einschlägige Literatur nicht ausreicht, um ein großes Modell zur genauen Beantwortung einer Frage zu unterstützen, kann das Modell einem gewissen Maß an "Improvisation" unterliegen, d. h. Spekulationen und Ergänzungen auf der Grundlage begrenzter Informationen, um die Antwort bestmöglich zu vervollständigen.
- Theoretische Studien:
- [Aufbau einer Wissensdatenbank - Vektorisierung von Dokumenten]
- Praktische Fähigkeiten:
- [Docs Vektorisierung - Tencent Word Vector]
- [Docs Vektorisierung - sbt]
- [Docs Vektorisierung - SimCSE]
- [Docs Vektorisierung - text2vec]
- [Docs Vektorisierung - SGPT]
- [Docs Vektorisierung -- BGE -- Smart Source open source das stärkste semantische Vektormodell]
- [Docs Vektorisierung - M3E: eine groß angelegte hybride Einbettung]
Schritt 3: Docs erstellen Index
- (jemandem eine Stelle etc.) anbieten
- Praktische Fähigkeiten:
- [Docs build index - Faiss]
- [Docs build index - milvus]
- [Docs Aufbau von Indizes - Elasticsearch]
Modul 3: Feinabstimmung des großen Modells
Warum brauchen wir eine Feinabstimmung der großen Modelle?
Normalerweise gibt es eine Reihe von Gründen für die Feinabstimmung eines großen Modells:
- Der erste Grund ist, dass die Anzahl der Parameter in einem großen Modell sehr groß ist und die Kosten für die Ausbildung sehr hoch sind. Jedes Unternehmen geht hinaus und bildet ein eigenes großes Modell von Grund auf aus, was sehr kostspielig ist;
- Der zweite Grund ist, dass der Prompt-Engineering-Ansatz ein relativ einfacher Weg ist, um mit großen Modellen zu beginnen, aber er hat offensichtliche Nachteile. Da die Implementierungsprinzipien großer Modelle in der Regel Beschränkungen für die Länge der Eingabesequenz enthalten, kann der Prompt-Engineering-Ansatz den Prompt sehr lang machen.
Je länger der Prompt ist, desto höher sind die Inferenzkosten des großen Modells, da die Inferenzkosten positiv mit dem Quadrat der Promptlänge korreliert sind. Außerdem wird ein zu langer Prompt abgeschnitten, weil er den Grenzwert überschreitet, was wiederum zu einer Verschlechterung der Ausgabequalität des großen Modells führt. Für Einzelpersonen, die in ihrem täglichen Leben und bei ihrer Arbeit einige Probleme lösen, ist es normalerweise kein großes Problem, Prompt Engineering direkt zu verwenden. Für Unternehmen, die Dienstleistungen für die Außenwelt erbringen und die Fähigkeit großer Modelle für ihre eigenen Dienstleistungen nutzen wollen, sind die Kosten für die Argumentation ein Faktor, der berücksichtigt werden muss, und die Feinabstimmung ist relativ gesehen eine bessere Lösung.
- Der dritte Grund ist, dass die Wirkung von Prompt Engineering nicht den Anforderungen entspricht und das Unternehmen über bessere eigene Daten verfügt, die zur Verbesserung der Fähigkeit des großen Modells in dem spezifischen Bereich genutzt werden können. In diesem Fall ist die Feinabstimmung sehr sinnvoll.
- Der vierte Grund ist die Nutzung der Leistungsfähigkeit großer Modelle für personalisierte Dienste, bei denen das Training eines leichtgewichtigen, fein abgestimmten Modells für die Daten jedes Nutzers eine gute Lösung darstellt.
- Der fünfte Grund ist der der Datensicherheit. Wenn die Daten nicht an einen Big-Model-Dienst eines Drittanbieters weitergegeben werden sollen, ist der Aufbau eines eigenen Big-Models sehr wichtig. In der Regel müssen diese Open-Source-Big-Models mit ihren eigenen Daten feinabgestimmt werden, um den Anforderungen des Unternehmens gerecht zu werden.
Wie nimmt man die Feinabstimmung eines großen Modells vor?
q1: Die Frage der Feinabstimmung der technischen Routen für große Modelle
Die Feinabstimmung großer Modelle unter dem Gesichtspunkt der Parameterskala erfolgt auf zwei technischen Wegen:
- Technischer Weg 1: Für die volle Menge an Parametern, die volle Menge an Training, wird dieser Weg Full Fine Tuning FFT (Full Fine Tuning) genannt.
- Technischer Weg II: Nur einige der Parameter werden trainiert, dieser Weg wird PEFT (Parameter-Efficient Fine Tuning) genannt.
Frage 2: Welche Probleme gibt es bei der FFT-Feinabstimmungsmethode für große Modelle?
FFT bringt auch eine Reihe von Problemen mit sich, von denen die beiden wichtigsten die folgenden sind:
- Problem 1: Die Kosten für das Training sind höher, weil die Anzahl der Parameter für die Feinabstimmung dieselbe ist wie für das Vortraining;
- Problem 2: Katastrophisches Vergessen (Catastrophic Forgetting), bei dem eine Feinabstimmung mit spezifischen Trainingsdaten die Leistung in diesem Bereich verbessern, aber auch die Fähigkeiten in anderen Bereichen, die zuvor gut waren, verschlechtern kann.
Q3: Welche Probleme werden durch PEFT (Parameter-Efficient Fine Tuning) für große Modelle gelöst?
Das Hauptproblem, das PEFT lösen will, sind die beiden oben genannten Probleme der FFT, und PEFT ist derzeit auch das am weitesten verbreitete Feinabstimmungsprogramm. Aus der Perspektive der Quelle der Trainingsdaten und der Trainingsmethode gibt es mehrere technische Wege für die Feinabstimmung großer Modelle wie folgt:
- Technischer Weg 1: Supervised Fine Tuning SFT (Supervised Fine Tuning), dieses Schema konzentriert sich auf die Feinabstimmung großer Modelle mit manuell gekennzeichneten Daten unter Verwendung des traditionellen überwachten Lernansatzes beim maschinellen Lernen;
- Technischer Weg II: Verstärkungslernen mit menschlichem Feedback (RLHF), das Hauptmerkmal dieses Schemas besteht darin, menschliches Feedback durch Verstärkungslernen in die Feinabstimmung des großen Modells einzubringen, so dass die vom großen Modell erzeugten Ergebnisse besser mit einigen der menschlichen Erwartungen übereinstimmen können;
- Technologie-Route III: Verstärkungslernen mit KI-Feedback (RLAIF), dieses Prinzip ist in etwa ähnlich wie RLHF, aber die Quelle des Feedbacks ist KI. Hier wird versucht, das Effizienzproblem des Feedbacksystems zu lösen, denn das Sammeln von menschlichem Feedback ist relativ gesehen teurer und weniger effizient.
Die verschiedenen Klassifizierungsperspektiven sind einfach unterschiedliche Schwerpunkte, und die Feinabstimmung desselben großen Modells ist nicht auf ein bestimmtes Szenario beschränkt, sondern kann mehrere Szenarien zusammen betreffen. Das ultimative Ziel der Feinabstimmung ist es, die Fähigkeiten des großen Modells in einem bestimmten Bereich so weit wie möglich zu verbessern und dabei die Kosten unter Kontrolle zu halten.
Was lernen große Modell-LLMs, wenn sie SFT-Operationen durchführen?
- Pre-Training -> Pre-Training auf großen Mengen von unüberwachten Daten, um ein Basismodell zu erhalten -> Verwendung des vortrainierten Modells als Ausgangspunkt für SFT und RLHF.
- SFT --> Durchführung des SFT-Trainings auf überwachten Datensätzen und weitere Optimierung des Modells unter Verwendung von überwachten Signalen wie z. B. kontextuellen Informationen --> Verwendung des SFT-trainierten Modells als Ausgangspunkt für RLHF.
- RLHF --> Verstärkungslernen mit menschlichem Feedback zur Optimierung des Modells, um es besser an die menschlichen Absichten und Präferenzen anzupassen --> Bewertung und Validierung des mit RLHF trainierten Modells und Vornahme der erforderlichen Anpassungen.
Schritt 1: Aufbau von Trainingsdaten für die Feinabstimmung des großen Modells
- Einführung: Wie erstellt man Trainingsdaten?
- Praktische Fähigkeiten:
- [Großmaßstäbliche Modelle (LLMs) LLM-Methodik zur Erzeugung von SFT-Daten]
Schritt 2: Feinabstimmung der großen Modellanweisungen
- Einführung: Wie erstellt man Trainingsdaten?
- Praktische Fähigkeiten:
- [Fortgesetztes Vortraining großer Modelle (LLMs)]
- [Feinabstimmung der LLM-Anweisungen]
- [LLMs Belohnungsmodell Training]
- Verstärkungslernen für große Modelle (LLMs) - Kapitel PPO-Training
- Verstärkungslernen für große Modelle (LLMs) - Kapitel DPO Training
Modul 4: Dokumentenrecherche
Warum brauchen Sie Document Retrieval?
Dokumentenabruf Als Kernstück der RAG-Arbeit ist ihre Effektivität entscheidend für die nachgelagerte Arbeit. Obwohl es möglich ist, die Antwortqualität des Modells zu verbessern, indem man Dokumentfragmente, die sich auf Benutzerfragen beziehen, aus dem Dokumentenspeicher mittels Vektor-Recall abruft und sie gleichzeitig in das LLM eingibt. Ein üblicher Weg, Dokumente abzurufen, ist die direkte Verwendung der Benutzerfrage. Allerdings ist die Frage des Benutzers oft sehr umgangssprachlich und vage beschrieben, was die Qualität des Vektorabrufs und damit die Antwort des Modells beeinträchtigt. In diesem Kapitel werden hauptsächlich einige Probleme und entsprechende Lösungen im Prozess der Dokumentensuche vorgestellt.
Schritt 1: Dokumentensuche - Negativmuster - Mustersuche
- EINLEITUNG: Bei allen Arten von Retrievalaufgaben ist es zum Trainieren eines qualitativ hochwertigen Retrievalmodells oft erforderlich, aus einer großen Menge von Kandidatenbeispielen hochwertige Negativbeispiele zusammen mit Positivbeispielen zu entnehmen.
- Praktische Fähigkeiten:
- [Dokumentensuche - Kapitel "Negative Stichproben"]
Schritt 2: Optimierungsstrategie für die Dokumentensuche
- Einführung: Optimierungsstrategien für das Auffinden von Dokumenten
- Praktische Fähigkeiten:
- Dokumentenrecherche - Optimierungsstrategien für die Dokumentenrecherche
Modul V: Reranker
Warum brauchen Sie Reranker?
Die Basisanwendung der RAG besteht aus vier technischen Schlüsselkomponenten:
- Einbettungsmodelle: zur Umwandlung externer Dokumente und Benutzeranfragen in Einbettungsvektoren
- VektordatenbankEinbettungsvektoren: Dient der Speicherung von Einbettungsvektoren und der Durchführung von Vektorähnlichkeitssuchen (Abruf der relevantesten Top-K-Informationen).
- Prompt-Engineering: Inputs für die Kombination von Benutzerfragen und abgerufenen Kontexten zu größeren Modellen
- Large Language Modelling (LLM): für die Erstellung von Antworten
Die oben beschriebene grundlegende RAG-Architektur löst effektiv das Problem, dass LLMs "Illusionen" erzeugen und unzuverlässige Inhalte generieren. Einige Unternehmensnutzer benötigen jedoch anspruchsvollere Architekturen für kontextuelle Relevanz und Q&A-Genauigkeit. Ein bewährter und beliebter Ansatz ist die Integration von Reranker in RAG-Anwendungen.
Was ist Reranker?
Reranker ist ein wichtiger Bestandteil des Information Retrieval (IR)-Ökosystems für die Bewertung von Suchergebnissen und deren Neuordnung zur Verbesserung der Relevanz von Abfragen. In RAG-Anwendungen wird Reranker hauptsächlich verwendet, nachdem die Ergebnisse einer Vektorabfrage (ANN) erhalten wurden. Dies ermöglicht eine effektivere Bestimmung der semantischen Relevanz zwischen Dokumenten und Abfragen, eine feinkörnigere Neueinordnung der Ergebnisse und verbessert letztendlich die Qualität der Suche.
Schritt 1: Teil-Reranker
- Theoretische Studien:
- RAG-Dokumentationssuche - Bereich Reranker
- Praktische Fähigkeiten:
- [Reranker - bge-reranker Kapitel]
Modul 6: RAG-Bewertungsoberflächen
Warum muss ich die RAG überprüfen?
Bei der Erforschung und Optimierung von RAGs (Retrieval Augmentation Generators) ist die Frage, wie man ihre Leistung effektiv bewerten kann, von entscheidender Bedeutung.
Schritt 1: RAG-Überprüfung
- Theoretische Studien:
- [RAG-Kritik]
Modul 7: RAG Open Source Projekt Empfohlene Lerninhalte
Warum brauche ich RAG Open Source Project Recommended Learning?
Nachdem wir Sie durch die verschiedenen Prozesse von RAG geführt haben, finden Sie hier einige empfohlene RAG-Open-Source-Projekte, die den großen Jungs beim Verdauen und Lernen helfen.
RAG Open Source Projekt Empfehlungen - RAGFlow Artikel
- Einführung: RAGFlow ist eine quelloffene Retrieval-Augmented Generation (RAG)-Engine, die auf einem tiefgreifenden Verständnis von Dokumenten aufbaut. RAGFlow bietet einen rationalisierten Satz von RAG-Workflows für Unternehmen und Einzelpersonen jeder Größe, kombiniert mit einem Large Language Model (LLM), um zuverlässige RAGFlow bietet einen rationalisierten RAG-Workflow für Unternehmen und Einzelpersonen aller Größenordnungen, kombiniert mit einem Large Language Model (LLM), um zuverlässige Fragen, Antworten und begründete Zitate für eine Vielzahl komplexer Datenformate zu liefern.
- Projekt Lernen:
- RAG-Projekt-Empfehlungen - RagFlow Teil I - RagFlow-Docker-Einsatz
- RAG Projektempfehlung - RagFlow Teil (2) - Aufbau der RagFlow Wissensbasis]
- RAG-Projektempfehlung - RagFlow Teil (3) - Auswahl des RagFlow-Modellanbieters
- RAG-Projektempfehlung - RagFlow Teil (4) - RagFlow-Dialog]
- RAG-Projekt-Empfehlung - RagFlow Teil (V) - RAGFlow Api Zugang (zu) ollama (zum Beispiel)]
- RAG-Projekt-Empfehlung - RagFlow Teil (VI) - RAGFlow Source Code Learning
RAG Open Source Projekt-Empfehlungen - QAnything
- Einführung: QAnything (Question and Answer based on Anything) ist ein lokales Frage- und Antwortsystem für Wissensdatenbanken, das eine Vielzahl von Dateiformaten und Datenbanken unterstützt und eine Offline-Installation und -Nutzung ermöglicht. Mit QAnything können Sie einfach lokal gespeicherte Dateien in beliebigen Formaten löschen und erhalten genaue, schnelle und zuverlässige Antworten. QAnything unterstützt derzeit folgende Dateiformate für Wissensdatenbanken: PDF(pdf) , Word(docx) , PPT(pptx) , XLS(xlsx) , Markdown(md) , Email (eml) , TXT (txt), Bild (jpg, jpeg, png), CSV (csv), Weblinks (html) und so weiter.
- Projekt Lernen:
- [RAG-Empfehlungen für Open-Source-Projekte -- QAnything [Schriftstück]
RAG Open Source Projekt-Empfehlungen -- ElasticSearch-Langchain Artikel
- EINLEITUNG: Inspiriert durch das Langchain-ChatGLM Projekt, da Elasticsearch gemischte Abfragen sowohl in Text- als auch in Vektorform durchführen kann und in Geschäftsszenarien weiter verbreitet ist, ersetzt dieses Projekt Faiss durch Elasticsearch als Wissensspeicher und verwendet Langchain+Chatglm2, um ein intelligentes Quiz zu implementieren, das auf der Intelligente Fragen und Antworten auf der Grundlage einer eigenen Wissensdatenbank mit Langchain+Chatglm2.
- Projekt Lernen:
- [LLMs Getting Started] Efficient 🤖ElasticSearch-Langchain-Chatglm2 Based on Local Knowledge Base]
RAG Open Source Projekt-Empfehlungen - Langchain-Chatchat Artikel
- Einführung: Langchain-Chatchat (früher Langchain-ChatGLM) QA-App mit lokalem wissensbasiertem LLM (wie ChatGLM) | Langchain-Chatchat (früher Langchain-ChatGLM), lokale wissensbasierte LLM (wie ChatGLM) QA-Anwendung mit Langchain
- Projekt Lernen:
- [Erste Schritte mit LLMs] Efficient 🤖Langchain-Chatchat based on Local Knowledgebase]
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel

Keine Kommentare...