X-R1: Schulung von 0,5B-Modellen in gängigen Geräten zu geringen Kosten

Allgemeine Einführung
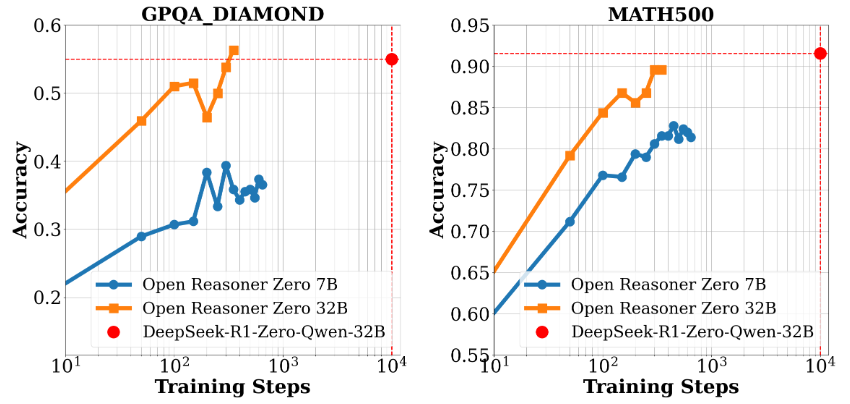
X-R1 ist ein Reinforcement-Learning-Framework, das vom dhcode-cpp-Team auf GitHub zur Verfügung gestellt wird. Ziel ist es, Entwicklern ein kostengünstiges und effizientes Tool für das Training von Modellen auf Basis von End-to-End Reinforcement Learning zur Verfügung zu stellen. Das Projekt wird unterstützt von DeepSeek-R1 Inspiriert von X-R1 und open-r1, konzentriert sich X-R1 auf den Aufbau einer Trainingsumgebung, die einfach zu starten ist und geringe Ressourcenanforderungen hat. Das Kernprodukt von X-R1 ist R1-Zero, ein Modell mit 0,5B Kovarianz, das den Anspruch erhebt, auf gängiger Hardware effizient trainieren zu können. Es unterstützt mehrere Basismodelle (0,5B, 1,5B, 3B) und verbessert die Inferenz und die Formateinhaltung des Modells durch Reinforcement Learning. Das Projekt ist in C++ entwickelt und kombiniert vLLM Inferenzmaschinen und GRPO Algorithmen für mathematische Schlussfolgerungen, die Verarbeitung chinesischer Aufgaben und andere Szenarien. Ob Sie nun ein einzelner Entwickler oder ein Forscher sind, X-R1 ist eine Open-Source-Option, die es wert ist, ausprobiert zu werden.

Funktionsliste
- Kostengünstige ModellschulungUnterstützung für das Training von R1-Zero-Modellen mit 0,5B Parametern auf gängiger Hardware (z.B. 4 3090 GPUs).
- Verbesserte LernoptimierungVerbesserung der Inferenzfähigkeit und der Ausgabeformatgenauigkeit von Modellen durch durchgängiges Reinforcement Learning (RL).
- Unterstützung mehrerer ModelleKompatibel mit 0,5B, 1,5B, 3B und anderen Basismodellen, flexibel anpassbar an unterschiedliche Aufgabenstellungen.
- GPU-beschleunigte AbtastungIntegration von vLLM als Online-Inferenzmaschine für schnelle GRPO-Datenabfragen.
- Chinesisches mathematisches DenkenUnterstützt mathematische Argumentationsaufgaben in einer chinesischsprachigen Umgebung und erzeugt klare Antwortprozesse.
- Benchmarking-BewertungBenchmark.py: Stellt Skripte für die Bewertung der Genauigkeit und der Formatausgabefähigkeiten des Modells zur Verfügung.
- Open-Source-Konfiguration: Stellen Sie eine detaillierte Konfigurationsdatei (z.B. zero3.yaml) für benutzerdefinierte Trainingsparameter zur Verfügung.
Hilfe verwenden
X-R1 ist ein Open-Source-Projekt, das auf GitHub basiert. Die Benutzer benötigen einige Programmierkenntnisse und eine Hardwareumgebung, um es zu installieren und zu verwenden. Im Folgenden finden Sie eine ausführliche Installations- und Nutzungsanleitung, die Ihnen einen schnellen Einstieg ermöglicht.
Einbauverfahren
- Vorbereitung der Umwelt
- Hardware-VoraussetzungMindestens 1 NVIDIA-GPU (z. B. 3090), für optimale Leistung werden 4 empfohlen; CPU unterstützt AVX/AVX2-Befehlssatz; mindestens 16 GB RAM.
- BetriebssystemLinux (z. B. Ubuntu 20.04+), Windows (erfordert WSL2-Unterstützung) oder macOS.
- Abhängige WerkzeugeGit, Python 3.8+, CUDA Toolkit (passend zur GPU, z.B. 11.8), C++ Compiler (z.B. g++) installieren.
sudo apt update sudo apt install git python3 python3-pip build-essential - GPU-TreiberStellen Sie sicher, dass der NVIDIA-Treiber installiert ist und mit der CUDA-Version übereinstimmt, indem Sie das Programm
nvidia-smiPrüfen.
- Klonprojekt
Führen Sie den folgenden Befehl in einem Terminal aus, um das X-R1-Repository lokal herunterzuladen:git clone https://github.com/dhcode-cpp/X-R1.git cd X-R1 - Installation von Abhängigkeiten
- Installieren Sie die Python-Abhängigkeiten:
pip install -r requirements.txt - Installieren Sie Accelerate (für verteilte Schulungen):
pip install accelerate
- Installieren Sie die Python-Abhängigkeiten:
- Konfiguration der Umgebung
- Bearbeiten Sie das Profil entsprechend der Anzahl der GPUs (z. B.
recipes/zero3.yaml), setzennum_processes(z. B. 3, was bedeutet, dass 3 der 4 GPUs für das Training und 1 für die vLLM-Inferenz verwendet werden). - Beispielkonfiguration:
num_processes: 3 per_device_train_batch_size: 1 num_generations: 3
- Bearbeiten Sie das Profil entsprechend der Anzahl der GPUs (z. B.
- Überprüfen der Installation
Führen Sie den folgenden Befehl aus, um zu prüfen, ob die Umgebung korrekt konfiguriert ist:accelerate configFolgen Sie den Aufforderungen zur Auswahl der Hardware- und Verteilungseinstellungen.
Hauptfunktionen
1. die Modellausbildung
- Grundlagentraining: Trainieren Sie das R1-Null-Modell mit dem GRPO-Algorithmus. Führen Sie den folgenden Befehl aus:
ACCELERATE_LOG_LEVEL=info accelerate launch \ --config_file recipes/zero3.yaml \ --num_processes=3 \ src/x_r1/grpo.py \ --config recipes/X_R1_zero_0dot5B_config.yaml \ > ./output/x_r1_0dot5B_sampling.log 2>&1 - Funktionelle BeschreibungDieser Befehl initiiert das Training des 0.5B-Modells, und die Protokolle werden in der Datei
outputMappe. Der Trainingsprozess nutzt Verstärkungslernen, um die Argumentationsfähigkeit des Modells zu optimieren. - caveat: Stellen Sie sicher, dass die globale Chargengröße (
num_processes * per_device_train_batch_size) können seinnum_generationsIntegrieren, sonst wird ein Fehler gemeldet.
2. chinesische mathematische Argumentation
- Konfigurieren von Matheaufgaben: Verwenden Sie die für Chinesisch vorgesehene Konfigurationsdatei:
ACCELERATE_LOG_LEVEL=info accelerate launch \ --config_file recipes/zero3.yaml \ --num_processes=3 \ src/x_r1/grpo.py \ --config recipes/examples/mathcn_zero_3B_config.yaml \ > ./output/mathcn_3B_sampling.log 2>&1 - Arbeitsablauf::
- Bereiten Sie einen Datensatz mit chinesischen Mathematikaufgaben vor (z. B. im JSON-Format).
- Ändern Sie den Pfad zu den Datensätzen in der Konfigurationsdatei.
- Führen Sie den obigen Befehl aus und das Modell wird den Inferenzprozess generieren und in das Protokoll ausgeben.
- Ausgewählte FunktionenUnterstützung für die Erstellung von detaillierten chinesischen Antwortschritten, geeignet für Bildungsszenarien.
3. das Benchmarking
- Operative Bewertung: Verwendung
benchmark.pyTesten Sie die Leistung des Modells:CUDA_VISIBLE_DEVICES=0,1 python ./src/x_r1/benchmark.py \ --model_name='xiaodongguaAIGC/X-R1-0.5B' \ --dataset_name='HuggingFaceH4/MATH-500' \ --output_name='./output/result_benchmark_math500' \ --max_output_tokens=1024 \ --num_gpus=2 - Auswertung der ErgebnisseDas Skript gibt die Genauigkeitsmetrik und die Formatmetrik aus und speichert die Ergebnisse in einer JSON-Datei.
- VerwendungsszenarienValidierung der Modellleistung bei mathematischen Aufgaben und Optimierung der Trainingsparameter.
Bedienungskompetenz
- Log-AnsichtNach Abschluss des Trainings oder der Tests überprüfen Sie die Protokolldatei (z. B. die
x_r1_0dot5B_sampling.log), um das Problem zu beheben. - Multi-GPU-OptimierungWenn mehr GPUs verfügbar sind, können Sie die
num_processesim Gesang antwortennum_gpusParameter zur Verbesserung der parallelen Effizienz. - FehlererkennungWenn ein Fehler in der Chargengröße auftritt, passen Sie die
per_device_train_batch_sizeim Gesang antwortennum_generationsMachen Sie es passend.
Empfehlungen für die Verwendung
- Für den ersten Gebrauch wird empfohlen, mit einem kleinen Modell (z. B. 0,5B) zu beginnen und dann auf ein 3B-Modell zu erweitern, sobald Sie mit dem Verfahren vertraut sind.
- Prüfen Sie Ihr GitHub-Repository regelmäßig auf Updates, neue Funktionen und Fehlerbehebungen.
- Für Unterstützung wenden Sie sich bitte an den Entwickler unter dhcode95@gmail.com.
Mit diesen Schritten können Sie problemlos eine X-R1-Umgebung einrichten und mit dem Training oder Testen von Modellen beginnen. Ob für Forschung oder Entwicklung, dieses Framework bietet effiziente Unterstützung.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel

Keine Kommentare...