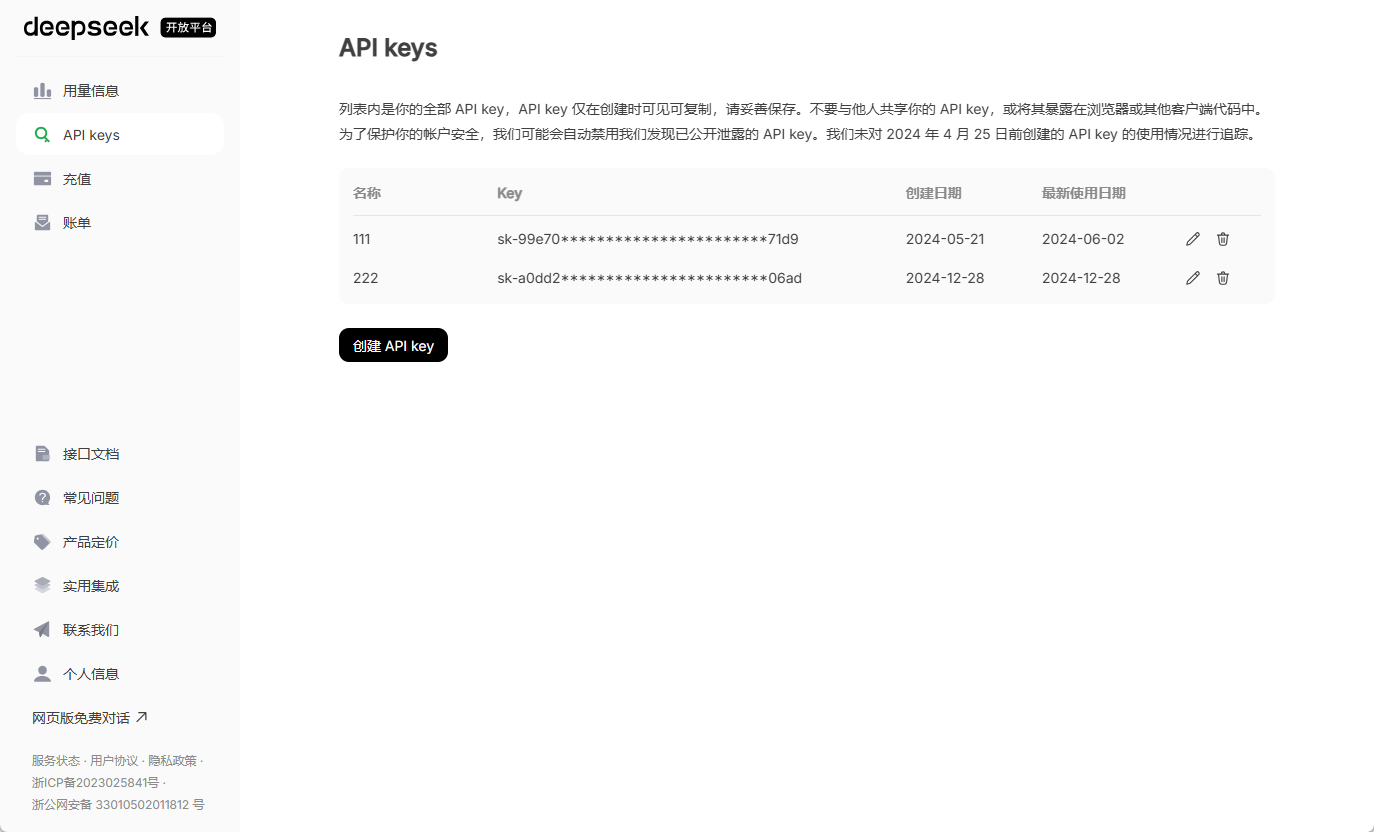
Was ist unüberwachtes Lernen (ULS) in einem Artikel?

Definition und Kernkonzepte des unüberwachten Lernens
Unüberwachtes Lernen (ULS) ist ein wichtiger Zweig des maschinellen Lernens, der sich auf die Verarbeitung von Datensätzen konzentriert, die nicht voretikettiert sind. Im wirklichen Leben liegen Daten oft in Rohform vor, ohne ausdrückliche Anleitung oder Kategorisierungsinformationen. Algorithmen des unüberwachten Lernens sind in der Lage, diese Daten eigenständig zu erforschen und inhärente Strukturen, Muster oder Regelmäßigkeiten zu erkennen, ohne dass der Mensch eingreifen muss, um Antworten zu geben.
Wenn beispielsweise ein Stapel unkategorisierter Bilder vorliegt, kann unüberwachtes Lernen automatisch ähnliche Bilder gruppieren, indem es beispielsweise Cluster auf der Grundlage von Farbe, Form oder Thema bildet. Bei hochdimensionalen Daten vereinfachen Algorithmen die Daten durch Techniken zur Dimensionalitätsreduzierung, die wichtige Informationen beibehalten und gleichzeitig die Komplexität reduzieren, so dass die Daten leichter visualisiert oder analysiert werden können. Zu den Kernkonzepten gehören Clustering (Gruppierung von Datenpunkten in Kategorien), Dimensionalitätsreduktion (Verringerung der Dimensionalität der Daten, ohne dass wichtige Merkmale verloren gehen), Anomalieerkennung (Identifizierung von Datenpunkten, die vom normalen Muster abweichen) und Korrelationsanalyse (Aufdeckung verborgener Beziehungen zwischen Datenelementen). Dieser Ansatz stützt sich auf statistische Prinzipien und mathematische Optimierung, um Wissen aus Datenverteilungen zu extrahieren, und nicht auf externe Kennzeichnungen. Die Stärke des unüberwachten Lernens liegt darin, dass es den menschlichen Lernprozess nachahmt: Wir verallgemeinern oft Muster aus Beobachtungen, anstatt immer die richtige Antwort zu erhalten. Da es sich hervorragend für die Verarbeitung großer, komplexer Datensätze eignet, ist es ein grundlegendes Instrument für die wissenschaftliche Forschung und gesellschaftliche Anwendungen.

Arten von Algorithmen für unüberwachtes Lernen
- Clustering-AlgorithmusBeispiele: K-means und hierarchisches Clustering, Algorithmen, die Datenpunkte auf der Grundlage von Ähnlichkeitsmaßen zu Clustern zusammenfassen. Zu den Anwendungsszenarien gehört die Marktsegmentierung, die Unternehmen dabei hilft, ihre Marketingstrategien anzupassen, indem sie die Kunden auf der Grundlage ihres Verbraucherverhaltens in verschiedene Gruppen einteilen; in der Biologie wird das Clustering bei der Analyse von Genexpressionsdaten eingesetzt, um Genome mit ähnlichen Funktionen zu identifizieren.
- Algorithmus zur DimensionalitätsreduktionDiese Techniken, wie z. B. die Hauptkomponentenanalyse (PCA) und t-SNE, reduzieren die Dimensionalität von Daten und bewahren wichtige Informationen. Anwendungsszenarien umfassen die Bildverarbeitung, bei der hochdimensionale Bilddaten zur einfacheren Speicherung und Übertragung komprimiert werden; im Finanzwesen trägt die Dimensionalitätsreduzierung zur Vereinfachung von Risikobewertungsmodellen und zur Verbesserung der Berechnungseffizienz bei.
- Algorithmus zur KorrelationsanalyseDer Apriori-Algorithmus wird zum Beispiel verwendet, um häufige Muster oder Regeln zwischen Datenelementen zu erkennen. Zu den Anwendungsszenarien gehören der Einzelhandel, wo Warenkorbdaten analysiert werden, um relevante Produkte zu empfehlen und den Umsatz zu steigern, und die Netzsicherheit, wo die Korrelationsanalyse anormale Netzverkehrsmuster erkennt und Angriffe verhindert.
- Algorithmus zur Erkennung von AnomalienDiese Methoden identifizieren Ausreißer oder Ausreißer in den Daten, wie z. B. Isolation Forests und eine Klasse von Support-Vektor-Maschinen. Die Anwendungsszenarien reichen von der Betrugserkennung, bei der Bankensysteme das Transaktionsverhalten überwachen, um verdächtige Aktivitäten zu erkennen, bis hin zur industriellen Wartung, bei der die Anomalieerkennung Geräteausfälle vorhersagt und Produktionsunterbrechungen vermeidet.
- Generierung von ModellalgorithmenDiese Modelle, wie z. B. Self-Encoder und generative adversarische Netze (GANs), lernen Datenverteilungen und erzeugen neue Muster. Zu den Anwendungsszenarien gehören die künstlerische Gestaltung, die Erzeugung realistischer Bilder oder Musik, und im medizinischen Bereich die Erstellung von Modellen zur Simulation des Krankheitsverlaufs und zur Unterstützung der Diagnose und Behandlungsplanung.
- Algorithmus zur Dichteschätzung:: Die Kerndichteschätzung wird beispielsweise zur Modellierung der Wahrscheinlichkeitsverteilung von Daten verwendet. Die Anwendungsszenarien beziehen sich auf die Umweltwissenschaften, wo Verschmutzungsausbreitungsmuster vorhergesagt werden, und auf die Wirtschaftswissenschaften, wo die Dichteschätzung Einkommensverteilungen analysiert, um die Formulierung politischer Maßnahmen zu unterstützen.
Herausforderungen und Grenzen des unüberwachten Lernens
- Ergebnisse sind weniger interpretierbarMuster oder Gruppierungen von Ergebnissen des unüberwachten Lernens können keine intuitive Bedeutung haben und erfordern das Eingreifen von Fachleuten zur Interpretation.
- Hohe Empfindlichkeit gegenüber ParameternViele Algorithmen sind auf anfängliche Parametereinstellungen angewiesen, wie z. B. die Anzahl der Cluster K bei K-means, und eine falsche Wahl kann zu suboptimalen Ergebnissen führen. Die Anpassung der Parameter erfordert iteratives Experimentieren, was zeit- und ressourcenaufwändig ist und insbesondere bei großen Projekten den Fortschritt verlangsamen kann.
- lokales Problem der optimalen LösungDer Optimierungsprozess neigt dazu, eher in lokale Minima als in ein globales Optimum zu fallen, was bedeutet, dass der Algorithmus möglicherweise bessere Datenmuster übersieht. Beim Clustering kann dies zu ungenauen Gruppierungen führen und nachfolgende Entscheidungen beeinflussen.
- Hohe Abhängigkeit von der DatenqualitätUnüberwachtes Lernen ist sehr empfindlich gegenüber Eingabedaten, bei denen Rauschen oder fehlende Werte die Ergebnisse verzerren können. Bei der Analyse von Finanzdaten können beispielsweise unvollständige Transaktionsdatensätze die Erkennung falscher Anomalien auslösen und zu Fehlalarmen führen.
- Fehlen von Kriterien für die Bewertung von IndikatorenIm Gegensatz zum überwachten Lernen gibt es beim unüberwachten Lernen keine expliziten Kennzeichnungen als Benchmarks, was die Bewertung der Modellleistung subjektiv macht.
Diese Herausforderungen erinnern uns daran, dass unüberwachtes Lernen kein Allheilmittel ist und mit Fachwissen und sorgfältiger Praxis kombiniert werden muss, um seinen Wert zu maximieren.
Ein praktischer Ansatz für unüberwachtes Lernen mit Fallstudien
- Online-Tutorials und KursePlattformen wie Coursera und edX bieten Kurse zum maschinellen Lernen an, in denen die Grundlagen des unüberwachten Lernens vermittelt werden. Der Kurs von Andrew Ng beispielsweise umfasst Experimente zum Clustering und zur Dimensionalitätsreduktion, und die Teilnehmer festigen ihr Wissen durch Videovorträge und Quizfragen.
- Open Source Tools und BibliothekenScikit-learn ist eine beliebte Bibliothek in Python, die einfache APIs zur Implementierung von K-means- und PCA-Algorithmen bietet. Die Benutzer können mit der Installation der Python-Umgebung beginnen, Code schreiben, um den Datensatz zu laden, den Algorithmus anzuwenden und die Ergebnisse zu visualisieren.
- Code-Beispiele und ProjekteZahlreiche Open-Source-Projekte sind auf GitHub verfügbar, z. B. die Verwendung von unüberwachtem Lernen zur Analyse des Iris-Blumendatensatzes für Clustervergleiche. Praktiker können diese Projekte replizieren und die Parameter ändern, um Veränderungen zu beobachten und ihr Verständnis zu vertiefen.
- Kaggle-Wettbewerbe und CommunityKaggle: Die Kaggle-Plattform veranstaltet Data-Science-Wettbewerbe, die sich manchmal auf unüberwachte Lernprobleme konzentrieren. Die Teilnehmer laden Datensätze herunter, erstellen Modelle, um Ergebnisse einzureichen, und lernen aus dem Feedback der Community bewährte Verfahren.
- Bücher und ReferenzenBücher wie Python Machine Learning bieten Kapitel über unüberwachtes Lernen, einschließlich theoretischem Hintergrund und Codeschnipseln. Die Leser können Schritt für Schritt Algorithmen implementieren, um reale Probleme wie die Kundensegmentierung zu lösen.
- Fallstudien
- Analyse des KundenverhaltensEin E-Commerce-Unternehmen nutzt K-means Clustering, um die Kaufhistorie der Nutzer zu analysieren und hochwertige Kundensegmente zu identifizieren. Die Ergebnisse werden verwendet, um Empfehlungen zu personalisieren und die Kundentreue und den Umsatz zu steigern.
- Visualisierung hochdimensionaler DatenForscher verwenden t-SNE Downscaling, um Genexpressionsdaten von Tausenden von Dimensionen auf 2 Dimensionen zu komprimieren, die Verteilung von Zelltypen zu visualisieren und neue Biomarker zu entdecken.
Mithilfe dieser Methoden können Einzelpersonen schrittweise unüberwachtes Lernen beherrschen und datenwissenschaftliche Fähigkeiten von der Theorie bis zur Anwendung entwickeln.
Praktische Anwendungsfälle für unüberwachtes Lernen
- Medizinischer BereichAnalyse von genetischen Sequenzierungsdaten und unüberwachtes Lernen, um krankheitsbezogene Muster zu erkennen, z. B. Klassifizierung von Krebs-Subtypen. Krankenhäuser verwenden Clustering-Algorithmen, um Patienten zu gruppieren und auf der Grundlage von Symptomen und genetischen Informationen personalisierte Behandlungspläne zu erstellen.
- FinanzsektorBanken setzen die Anomalieerkennung ein, um Transaktionsströme zu überwachen und Betrug zu erkennen. Die Downscaling-Technologie vereinfacht Kreditbewertungsmodelle, verbessert die Genauigkeit der Risikobewertung und verringert Forderungsausfälle.
- Bereich e-CommerceEmpfehlungssysteme nutzen Korrelationsanalysen, um Produktkaufmuster zu erkennen, z. B. Empfehlungen für den "gemeinsamen Kauf". Clustering-Algorithmen segmentieren Nutzer auf der Grundlage ihres Surfverhaltens, um Werbung und Bestandsverwaltung zu optimieren.
- DienstleistungsbrancheIn der Qualitätskontrolle erkennt unüberwachtes Lernen Produktfehler und identifiziert anormale Teile durch Bildanalyse. Bei der vorausschauenden Wartung werden Algorithmen zur Erkennung von Anomalien eingesetzt, um Sensordaten zu überwachen und Maschinenausfälle zu verhindern.
- UnterhaltungsindustrieStreaming-Plattformen wie Netflix nutzen Clustering, um die Sehgewohnheiten der Nutzer zu analysieren und Empfehlungslisten für Inhalte zu erstellen. Musikdienste setzen Downscaling ein, um Song-Bibliotheken zu organisieren und das Nutzererlebnis beim Entdecken neuer Musik zu verbessern.
- transportierenStädtische Verkehrsmanagementsysteme nutzen unüberwachtes Lernen, um Verkehrsdaten zu analysieren und Staumuster zu erkennen. Die Erkennung von Anomalien hilft, das Fahrzeugverhalten zu überwachen und die Verkehrssicherheit zu verbessern.
- EnergiesektorEnergieversorgungsunternehmen setzen Clustering ein, um Verbrauchsdaten zu analysieren und die Netzverteilung zu optimieren. Durch die Erkennung von Anomalien werden Energiediebstahl oder -verluste erkannt und die Ressourcenverschwendung reduziert.
Technologische Entwicklungen und Trends beim unüberwachten Lernen
- Der Aufstieg des selbstüberwachten LernensIn Kombination mit Deep Learning verbessert selbstüberwachtes Lernen die Modellleistung, indem es Repräsentationen aus unmarkierten Daten durch Vortrainingsaufgaben lernt. Bei der Verarbeitung natürlicher Sprache werden beispielsweise Modelle wie BERT mit maskierten Sprachmodellen vortrainiert und dann in nachgelagerten Aufgaben feinabgestimmt.
- Integration des halbüberwachten Lernens: Unüberwachtes und überwachtes Lernen werden kombiniert, um das Lernen mit kleinen Mengen von gekennzeichneten Daten zu verbessern. In der medizinischen Bildanalyse verringert dieser Ansatz die Abhängigkeit von großen Mengen an gekennzeichneten Daten und beschleunigt die Bereitstellung von Modellen.
- Verbesserte LernintegrationUnüberwachtes Lernen wird für die autonome Erkundung der Umgebung durch einen intelligenten Körper eingesetzt, während das Verstärkungslernen Strategien auf der Grundlage von Belohnungssignalen optimiert. Im Bereich der Robotik sind Intelligenzen in der Lage zu lernen, Objekte ohne ausdrückliche Anleitung autonom zu manipulieren.
- Fortschritte bei der generativen ModellierungGenerative Adversarial Networks (GANs) und Variational Auto-Encoders (VAEs) werden effizienter und erzeugen hochwertige synthetische Daten. In der Kunst- und Designbranche schaffen diese Modelle neue Inhalte und verschieben die kreativen Grenzen.
- Studien zur Interpretierbarkeit und FairnessDer neue Ansatz konzentriert sich darauf, die Ergebnisse des unüberwachten Lernens transparenter zu machen und Verzerrungen zu vermeiden. Durch die Entwicklung von Erklärungsinstrumenten zur Visualisierung von Clustering-Entscheidungen wird beispielsweise eine faire Behandlung aller Datenpunkte gewährleistet.
- Edge-Computing-AnwendungenUnüberwachte Algorithmen, die für ressourcenbeschränkte Geräte wie Smartphones oder IoT-Sensoren zur Datenanalyse in Echtzeit optimiert sind. In intelligenten Häusern lernen Geräte selbstständig die Gewohnheiten der Nutzer und automatisieren die Steuerung.
- Übergreifende ZusammenarbeitUnüberwachtes Lernen wird mit Neurowissenschaften kombiniert, um die Entwicklung neuer Algorithmen durch die Modellierung der Lernmechanismen des Gehirns zu inspirieren. Die Forschung hat gezeigt, dass das menschliche visuelle System Informationen auf unüberwachte Weise verarbeitet, was die Entwicklung des Computersehens inspiriert.
Diese Trends deuten darauf hin, dass das unüberwachte Lernen immer leistungsfähiger und zugänglicher wird und in Zukunft eine zentrale Rolle in der KI spielen könnte.
Bildungs- und Ressourcenempfehlungen für unüberwachtes Lernen
- Plattform für Online-KurseDer Stanford-Kurs "Maschinelles Lernen" auf Coursera enthält ein Modul für unüberwachtes Lernen. Auf den edX-Plattformen gibt es ähnliche Kurse, wie z. B. "Introduction to Machine Learning" am Massachusetts Institute of Technology (MIT), die praktische Übungen enthalten.
- Open-Source-Software-BibliothekScikit-learn ist sehr einsteigerfreundlich, mit ausführlicher Dokumentation und Beispielcode. TensorFlow und PyTorch unterstützen fortgeschrittene unüberwachte Lernmodelle (z.B. GANs) für Deep-Learning-Enthusiasten.
- Bücher und UnterrichtsmaterialienHands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow bietet praktische Anleitungen, denen die Leser folgen können, um Projekte durchzuführen. Pattern Recognition and Machine Learning hingegen konzentriert sich mehr auf die Theorie und ist für fortgeschrittene Lernende geeignet.
- Interaktive LernplattformKaggle Learn bietet Mikrokurse wie "Clustering", die direkt im Browser programmiert werden können, und DataCamp bietet Video-Tutorials und Herausforderungen, um die Fähigkeiten zu verbessern.
- Gemeinschaft & ForumDer Reddit-Subreddit r/MachineLearning ist sehr aktiv, und die Nutzer tauschen dort häufig Ressourcen für unüberwachtes Lernen aus, und Stack Overflow hilft bei der Lösung von Programmierproblemen und fördert Peer-to-Peer-Lernen.
- Hochschulstudiengänge und AkkreditierungViele Universitäten bieten Studiengänge in Datenwissenschaften an, die Kurse zum unüberwachten Lernen beinhalten. Online-Zertifikate wie die Google-Zertifizierung für maschinelles Lernen können die berufliche Wettbewerbsfähigkeit erhöhen.
- Praktische ProjektideenAnfänger können mit einfachen Projekten beginnen, wie z. B. der Visualisierung des Iris-Datensatzes mit Hilfe der Hauptkomponentenanalyse (PCA) oder der Anwendung des K-means-Algorithmus zur Analyse von Social-Media-Daten. Diese Projekte helfen dabei, ein Portfolio aufzubauen und potenziellen Arbeitgebern Kompetenz zu demonstrieren.
Ethische und soziale Implikationen des unüberwachten Lernens
- Transparenz und RechenschaftspflichtUnüberwachtes Lernen ist oft ein "Black Box"-Entscheidungsprozess, der schwer zu erklären ist. Wenn in der medizinischen Diagnose ein Algorithmus eine bestimmte Behandlung empfiehlt, müssen Ärzte und Patienten die Gründe dafür verstehen.
- Regulierungs- und NormbedarfLeitlinien sind für die Industrie erforderlich, um sicherzustellen, dass unüberwachte Technologien ethisch korrekt eingesetzt werden. Zum Beispiel ein Audit-Rahmen, um regelmäßig die Fairness von Algorithmen zu überprüfen und ihren Missbrauch zu verhindern.
- Sensibilisierung und Aufklärung der ÖffentlichkeitDie Sensibilisierung der Öffentlichkeit für unüberwachtes Lernen hilft den Menschen, die Vor- und Nachteile zu verstehen. Bildungsprogramme befähigen den Einzelnen, seine Privatsphäre zu schützen, und ermutigen ihn, sich an Diskussionen über die Verwaltung von Technologien zu beteiligen.
- Interdisziplinäre Zusammenarbeit bei der Lösung vonEthiker, Juristen und Technologen müssen zusammenarbeiten, um verantwortungsvolle Konzepte für unüberwachtes Lernen zu entwickeln. Initiativen wie "AI for Good" fördern den Einsatz von Technologie zum Wohle der Gesellschaft und nicht zum Schaden.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...