
Ein Artikel mit 10.000 Wörtern, um den Entwicklungsprozess von LLM-basiertem Text-to-SQL zu sortieren
OlaChat AI Digital Intelligence Assistant 10.000 Wörter ausführliche Analyse, nehmen Sie zu verstehen, die Vergangenheit und Gegenwart von Text-to-SQL-Technologie.
Dissertation: Datenbankschnittstellen der nächsten Generation: Ein Überblick über LLM-basierte Text-to-SQL
Die Generierung präziser SQL aus natürlichsprachlichen Problemen (Text-to-SQL) ist eine seit langem bestehende Herausforderung, da das Verstehen von Benutzerproblemen, das Verstehen von Datenbankschemata und die SQL-Generierung sehr komplex sind. Traditionelle Text-zu-SQL-Systeme, einschließlichKünstliche Technik und tiefe neuronale Netzewurden erhebliche Fortschritte erzielt. Anschließend.Vorgefertigte Sprachmodelle (PLM) wurden für die Umwandlung von Text in SQL entwickelt und eingesetzt, wobei eine vielversprechende Leistung erzielt wurde. Da moderne Datenbanken immer komplexer werden, werden die entsprechenden Benutzerprobleme immer anspruchsvoller, was dazu führt, dass PLMs mit eingeschränkten Parametern (vortrainierte Modelle) falsche SQL generieren, was anspruchsvollere, maßgeschneiderte Optimierungsmethoden erfordert, was wiederum die Anwendung von PLM-basierten Systemen einschränkt.
In jüngster Zeit haben Large Language Models (LLMs) aufgrund der zunehmenden Modellgröße erhebliche Fähigkeiten beim Verstehen natürlicher Sprache gezeigt. Daher ist die Integration von LLM-basierten Implementierungenkann einzigartige Möglichkeiten, Verbesserungen und Lösungen für die Text-to-SQL-Forschung bieten. In dieser Übersicht wird ein umfassender Überblick über LLM-basierte Text-to-SQL-Systeme gegeben. Insbesondere geben die Autoren einen kurzen Überblick über die technischen Herausforderungen und den evolutionären Prozess von Text-to-SQL. Anschließend geben die Autoren eine detaillierte Beschreibung der Datensätze und Evaluierungsmetriken, die zur Bewertung von Text-to-SQL-Systemen entwickelt wurden. Anschließend werden die jüngsten Fortschritte bei LLM-basierten Text-to-SQL-Systemen systematisch analysiert. Abschließend werden die verbleibenden Herausforderungen auf diesem Gebiet diskutiert und Erwartungen für zukünftige Forschungsrichtungen vorgestellt.
Die Papiere, auf die im Text mit "[xx]" verwiesen wird, können im Abschnitt "Referenzen" des Originalpapiers eingesehen werden.
Einführung
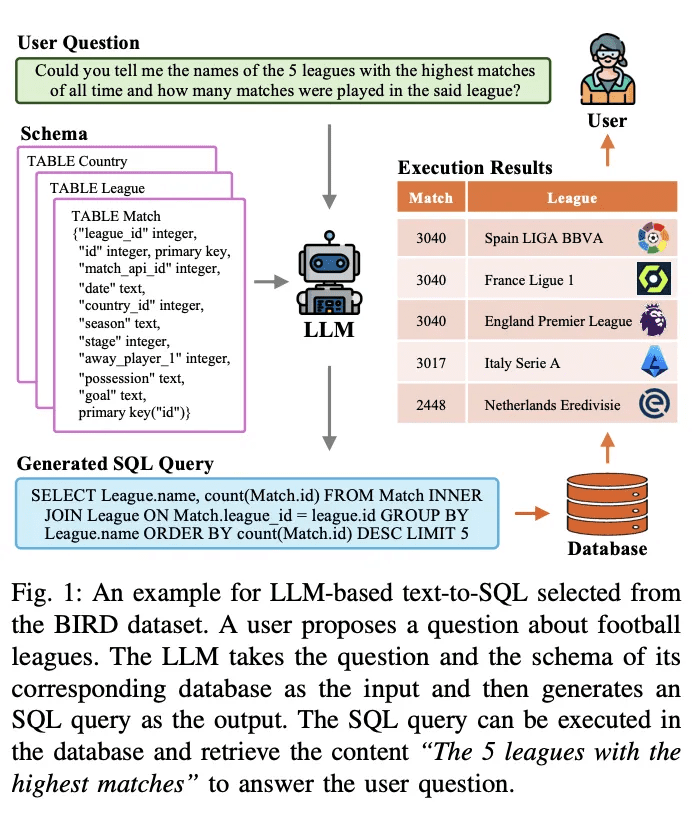
Text-To-SQL ist eine seit langem bestehende Aufgabe in der Forschung zur Verarbeitung natürlicher Sprache. Sie zielt darauf ab, natürlichsprachliche Probleme in datenbankausführbare SQL-Abfragen zu konvertieren (zu übersetzen). Abbildung 1 zeigt ein Beispiel für ein Text-to-SQL-System, das auf einem groß angelegten Sprachmodell (LLM-basiert) basiert. Bei einer Benutzerfrage, z.B. "Können Sie mir die Namen der 5 meistgespielten Ligen in der Geschichte nennen und wie viele Spiele in dieser Liga gespielt wurden?", übersetzt das LLM die Frage und die entsprechende Abfrage in eine ausführbare SQL-Abfrage. Der LLM nimmt die Frage und das dazugehörige Datenbankschema als Eingabe und analysiert sie. Anschließend generiert er eine SQL-Abfrage als Ausgabe. Diese SQL-Abfrage kann in der Datenbank ausgeführt werden, um relevante Inhalte zur Beantwortung der Frage des Benutzers abzurufen. Das obige System verwendet LLM, um eine natürlichsprachliche Schnittstelle zur Datenbank (NLIDB) zu erstellen.
Da SQL nach wie vor eine der am weitesten verbreiteten Programmiersprachen ist und die Hälfte (51,52%) der professionellen Entwickler SQL bei ihrer Arbeit verwenden, aber nur etwa ein Drittel (35,29%) der Entwickler in diesem System geschult ist, ermöglicht NLIDB auch ungeschulten Benutzern den Zugriff auf strukturierte Datenbanken wie professionellen Datenbankingenieuren [1 , 2] und beschleunigt außerdem die Mensch-Computer-Interaktion [3]. Darüber hinaus kann Text-to-SQL als einer der Forschungsschwerpunkte im LLM die Wissenslücke im LLM schließen, indem es reale Inhalte aus Datenbanken einbezieht und potenzielle Lösungen für das allgegenwärtige Problem der Täuschung bietet [4, 5] [6]. Der große Wert und das Potenzial von Text-to-SQL hat eine Reihe von Studien zur Integration und Optimierung mit LLMs ausgelöst [7-10]; daher bleibt LLM-basiertes Text-to-SQL ein viel diskutiertes Forschungsgebiet in den NLP- und Datenbankgemeinschaften.
Die bisherige Forschung hat erhebliche Fortschritte bei der Implementierung von Text-to-SQL gemacht und einen langen Evolutionsprozess durchlaufen. Die meisten der frühen Forschungen basierten auf gut entworfenen Regeln und Vorlagen [11], die sich besonders für einfache Datenbankszenarien eigneten. In den letzten Jahren wurde es immer schwieriger und unpraktischer, Regeln oder Vorlagen für jedes Szenario zu entwerfen, da regelbasierte Ansätze mit hohen Arbeitskosten verbunden sind [12] und die Komplexität von Datenbankumgebungen zunimmt [13 - 15]. Fortschritte bei der Umwandlung von Text in SQL wurden durch die Entwicklung von tiefen neuronalen Netzen [16, 17] vorangetrieben, die automatisch Zuordnungen von Benutzerfragen zu den entsprechenden SQL-Sätzen lernen [18, 19]. In der Folge wurden vortrainierte Sprachmodelle (PLMs) mit leistungsstarken semantischen Parsing-Fähigkeiten zum neuen Paradigma für Text-zu-SQL-Systeme [20] und brachten deren Leistung auf ein neues Niveau [21 - 23]. Die fortschreitende Forschung zu PLM-basierten Optimierungen (z. B. Codierung von Tabelleninhalten [ 19 , 24 , 25 ] und Pre-Training [ 20 , 26 ]) hat das Feld weiter vorangebracht. Kürzlich.Der LLM-basierte Ansatz implementiert die Text-zu-SQL-Transformation durch die Paradigmen des Kontextlernens (ICL) [8] und der Feinabstimmung (FT) [10].Das Unternehmen erreicht modernste Genauigkeit mit einem gut durchdachten Rahmen und einem größeren Verständnis als PLM.
Die allgemeinen Implementierungsdetails von LLM-basiertem Text-to-SQL können in drei Bereiche unterteilt werden:
1) Verständnis für das ProblemNL-Fragen sind semantische Repräsentationen von Benutzerabsichten, und die entsprechend generierten SQL-Abfragen sollten mit ihnen konsistent sein;
2) Verstehen von MusternSchema: Das Schema liefert die Tabellen- und Spaltenstruktur der Datenbank, und das Text-to-SQL-System muss die Zielkomponente identifizieren, die dem Problem des Benutzers entspricht;
3) SQL-GenerierungDies beinhaltet die Kombination des obigen Parsings und die Vorhersage der korrekten Syntax, um eine ausführbare SQL-Anfrage zu generieren und die gewünschte Antwort zu erhalten. Es hat sich gezeigt, dass LLMs die Text-zu-SQL-Funktionalität gut umsetzen können [7, 27], dank leistungsfähigerer semantischer Parsing-Fähigkeiten, die durch reichhaltigere Trainingskorpora ermöglicht werden [28, 29]. Weitere Forschungen zur Verbesserung von LLMs für das Problemverständnis [8, 9], das Musterverständnis [30, 31] und die SQL-Generierung [32] nehmen zu.
Trotz signifikanter Fortschritte in der Text-to-SQL-Forschung gibt es immer noch einige Herausforderungen, die die Entwicklung von robusten, universell einsetzbaren Text-to-SQL-Systemen behindern [ 73 ]. Einschlägige Forschungsarbeiten der letzten Jahre haben sich mit Text-to-SQL-Systemen in Deep-Learning-Ansätzen befasst und Einblicke in frühere Deep-Learning-Ansätze und PLM-basierte Forschung gegeben. Ziel dieses Überblicks ist es, die neuesten Fortschritte aufzuarbeiten und einen umfassenden Überblick über den aktuellen Stand der Technik bei Modellen und Ansätzen für LLM-basierte Text-zu-SQL-Systeme zu geben. Zunächst werden die grundlegenden Konzepte und Herausforderungen im Zusammenhang mit Text-zu-SQL vorgestellt, wobei die Bedeutung dieser Aufgabe in verschiedenen Bereichen hervorgehoben wird. Anschließend wird ein detaillierter Blick auf die Entwicklung der Implementierungsparadigmen für Text-zu-SQL-Systeme geworfen, wobei die wichtigsten Fortschritte und Durchbrüche auf diesem Gebiet diskutiert werden. Auf diesen Überblick folgt eine detaillierte Beschreibung und Analyse der neuesten Fortschritte bei der Text-zu-SQL-Integration für LLM. Dieses Übersichtspapier deckt insbesondere eine Reihe von Themen im Zusammenhang mit LLM-basierter Text-zu-SQL ab, darunter:
● Datensätze und BenchmarksDetaillierte Beschreibung von häufig verwendeten Datensätzen und Benchmarks zur Evaluierung von LLM-basierten Text-to-SQL-Systemen. Ihre Eigenschaften, Komplexität und die Herausforderungen, die sie für die Entwicklung und Bewertung von Text-zu-SQL-Systemen darstellen, werden diskutiert.
● Bewertung der IndikatorenDie Bewertungsmetriken, die zur Beurteilung der Leistung von LLM-basierten Text-zu-SQL-Systemen verwendet werden, werden vorgestellt, einschließlich inhaltsbezogener und ausführungsbezogener Beispiele. Anschließend werden die Merkmale der einzelnen Metriken kurz beschrieben.
● Methoden und ModelleDieses Papier präsentiert eine systematische Analyse verschiedener Ansätze und Modelle, die für LLM-basierte Text-zu-SQL-Aufgaben verwendet werden, einschließlich Beispiele, die auf kontextuellem Lernen und Feinabstimmung basieren. Ihre Implementierungsdetails, Vorteile und Anpassungen für Text-zu-SQL-Aufgaben werden aus verschiedenen Implementierungsperspektiven diskutiert.
● Erwartungen und künftige AusrichtungDieses Papier erörtert die verbleibenden Herausforderungen und Grenzen von LLM-basierten Text-zu-SQL-Verfahren, wie z.B. Robustheit in der realen Welt, Recheneffizienz, Datenschutz und Skalierung. Mögliche zukünftige Forschungsrichtungen und Möglichkeiten zur Verbesserung und Optimierung werden ebenfalls skizziert.
skizziert.
Text-to-SQL ist eine Aufgabe, die darauf abzielt, natürlichsprachliche Fragen in entsprechende SQL-Abfragen umzuwandeln, die in einer relationalen Datenbank ausgeführt werden können. Formal gesehen besteht das Ziel der Aufgabe darin, aus einer Benutzerfrage Q (auch als Benutzeranfrage, natürlichsprachliche Frage usw. bezeichnet) und einem Datenbankschema S eine SQL-Abfrage Y zu generieren, die den erforderlichen Inhalt aus der Datenbank abruft, um die Benutzerfrage zu beantworten. Text-to-SQL hat das Potenzial, den Datenzugriff zu demokratisieren, indem es den Benutzern ermöglicht, mit der Datenbank unter Verwendung natürlicher Sprache zu interagieren, ohne dass SQL-Programmierkenntnisse erforderlich sind [75]. Dadurch, dass auch ungeschulte Benutzer auf einfache Weise zielgerichtete Inhalte aus Datenbanken abrufen können und eine effektivere Datenanalyse möglich wird, können so unterschiedliche Bereiche wie Business Intelligence, Kundensupport und wissenschaftliche Forschung davon profitieren.
A. Herausforderungen bei Text-to-SQL
Die technischen Herausforderungen der Text-to-SQL-Implementierung lassen sich wie folgt zusammenfassen:
1)Linguistische Komplexität und MehrdeutigkeitProbleme in natürlicher Sprache enthalten oft komplexe sprachliche Darstellungen wie verschachtelte Klauseln, Ko-Referenzen und Ellipsen, die es schwierig machen, sie genau auf die entsprechenden Teile einer SQL-Abfrage abzubilden [41]. Darüber hinaus ist die natürliche Sprache von Natur aus mehrdeutig und bietet mehrere mögliche Darstellungen für ein bestimmtes Benutzerproblem [76, 77]. Um diese Mehrdeutigkeiten aufzulösen und die Absicht hinter dem Benutzerproblem zu verstehen, ist ein tiefgehendes Verständnis der natürlichen Sprache und die Fähigkeit zur Integration von Kontext- und Domänenwissen erforderlich [33].
2)Verständnis und Darstellung von MusternUm genaue SQL-Abfragen zu generieren, benötigen Text-to-SQL-Systeme ein gründliches Verständnis des Datenbankschemas, einschließlich Tabellennamen, Spaltennamen und Beziehungen zwischen einzelnen Tabellen. Datenbankschemata können jedoch sehr komplex sein und sich von Domäne zu Domäne stark unterscheiden [13]. Die Darstellung und Kodierung von Schemainformationen in einer Weise, die von Text-to-SQL-Modellen effektiv genutzt werden kann, ist eine anspruchsvolle Aufgabe.
3)Seltene und komplexe SQL-OperationenEinige SQL-Abfragen beinhalten seltene oder komplexe Operationen und Syntax in anspruchsvollen Szenarien, wie z. B. verschachtelte Unterabfragen, äußere Verknüpfungen und Fensterfunktionen. Diese Operationen sind in den Trainingsdaten weniger häufig und stellen eine Herausforderung für die genaue Generierung von Text-zu-SQL-Systemen dar. Die Entwicklung von Modellen, die sich auf eine Vielzahl von SQL-Operationen, einschließlich seltener und komplexer Szenarien, verallgemeinern lassen, ist ein wichtiger Aspekt.
4)bereichsübergreifende VerallgemeinerungText-to-SQL-Systeme lassen sich oft nur schwer über verschiedene Datenbankszenarien und Domänen hinweg verallgemeinern. Aufgrund der Vielfalt von Vokabularen, Datenbankschemastrukturen und Problemmustern können Modelle, die in einer bestimmten Domäne trainiert wurden, Probleme in anderen Domänen nicht gut lösen. Die Entwicklung von Systemen, die mit minimalen domänenspezifischen Trainingsdaten oder fein abgestimmten Anpassungen effektiv auf neue Domänen verallgemeinert werden können, ist eine große Herausforderung [78].
B. Evolutionäre Prozesse
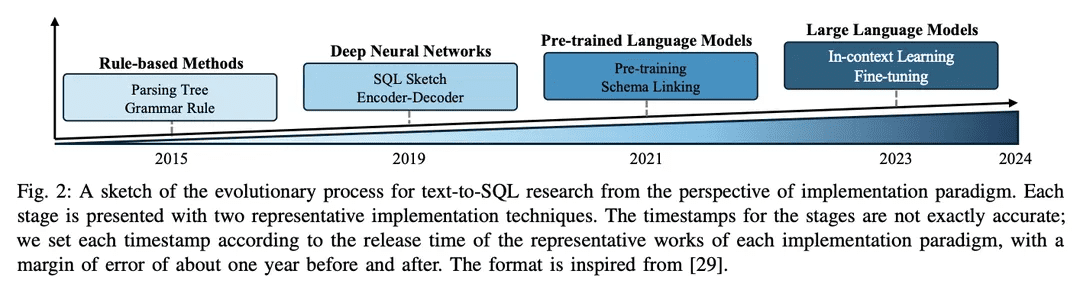
Der Bereich der Text-zu-SQL-Forschung hat in der NLP-Gemeinschaft im Laufe der Jahre große Fortschritte gemacht und sich von regelbasierten zu Deep-Learning-basierten Ansätzen und in jüngster Zeit zur Integration von vortrainierten Sprachmodellen (PLMs) und groß angelegten Sprachmodellen (LLMs) entwickelt, wobei eine Skizze des Evolutionsprozesses in Abbildung 2 dargestellt ist.
1) Regelbasierter AnsatzFrühe Text-to-SQL-Systeme stützten sich stark auf regelbasierte Ansätze [11, 12, 26], d. h. auf die Verwendung von manuell formulierten Regeln und Heuristiken zur Abbildung natürlichsprachlicher Probleme auf SQL-Abfragen. Diese Ansätze erfordern in der Regel ein umfangreiches Feature Engineering und domänenspezifisches Wissen. Während regelbasierte Ansätze in bestimmten einfachen Domänen erfolgreich waren, fehlt es ihnen an der Flexibilität und den Verallgemeinerungsfähigkeiten, die für die Bewältigung eines breiten Spektrums komplexer Probleme erforderlich sind.
2)Auf Deep Learning basierender AnsatzMit dem Aufstieg der tiefen neuronalen NetzeSequenz-zu-Sequenz-Modellierung und Encoder-Decoder-Architektur(z.B. LSTM [ 79] und Konverter [17]) werden verwendet, um SQL-Abfragen aus natürlichsprachlichen Eingaben zu generieren [ 19 , 80 ]. Typischerweise führt RYANSQL [19] Techniken wie Zwischendarstellungen und skizzenbasiertes Slot-Filling ein, um komplexe Probleme zu behandeln und die domänenübergreifende Allgemeinheit zu verbessern. Kürzlich haben Forscher schemaabhängigeDiagramme erfassen Beziehungen zwischen DatenbankelementenDer erste Schritt war die Einführung einer neuen Text-zu-SQL-Aufgabe, derGraphische neuronale Netze (GNN)[18,81].
3) PLM-basierte ImplementierungFrühe Anwendungen von PLMs in Text-to-SQL konzentrierten sich auf die Feinabstimmung von handelsüblichen PLMs auf Standard-Text-to-SQL-Datensätzen wie BERT [24] und RoBERTa [82] [13, 14]. Diese PLMs sind auf einem großen Trainingskorpus vortrainiert und erfassen umfangreiche semantische Repräsentationen und Sprachverstehensfähigkeiten. Durch ihre Feinabstimmung in Text-zu-SQL-Aufgaben wollen Forscher die semantischen und linguistischen Verständnisfähigkeiten von PLMs nutzen, um genaue SQL-Abfragen zu generieren [ 20, 80, 83]. Eine weitere Forschungsrichtung ist die Integration von Schemainformationen in PLMs, um die Art und Weise zu verbessern, wie diese Systeme den Benutzern helfen können, Datenbankstrukturen zu verstehen und besser ausführbare SQL-Abfragen zu generieren. Schema-aware PLMs sind so konzipiert, dass sie die Beziehungen und Einschränkungen in der Datenbankstruktur erfassen [21].
4) LLM-basierte ImplementierungLarge Language Models (LLMs), wie z.B. die GPT-Familie [84-86], haben in den letzten Jahren wegen ihrer Fähigkeit, kohärenten und flüssigen Text zu erzeugen, viel Aufmerksamkeit erhalten. Forscher haben begonnen, das Potenzial von Text-to-SQL zu erforschen, indem sie die umfangreiche Wissensbasis und die überlegenen generativen Fähigkeiten von LLMs ausnutzen [7, 9]. Diese Ansätze beinhalten typischerweise das Hint-Engineering von proprietären LLMs während der SQL-Generierung [47] oder die Feinabstimmung von Open-Source-LLMs auf Text-to-SQL-Datensätzen [9].
Die Integration von LLM in Text-to-SQL ist immer noch ein aufstrebendes Forschungsgebiet mit großem Potenzial für weitere Erforschung und Verbesserung. Forscher untersuchen, wie man das Wissen und die Argumentationsfähigkeiten von LLM besser nutzen, domänenspezifisches Wissen einbeziehen [31, 33] und effizientere Feinabstimmungsstrategien entwickeln kann [ 10 ]. Es ist zu erwarten, dass im Zuge der weiteren Entwicklung auf diesem Gebiet fortschrittlichere und bessere LLM-basierte Implementierungen entwickelt werden, die die Text-to-SQL-Leistung und Generalisierung auf ein neues Niveau heben werden.
Benchmarks und Bewertungen
In diesem Abschnitt werden Text-zu-SQL-Benchmarks vorgestellt, einschließlich bekannter Datensätze und Bewertungsmetriken.
A. Datensätze
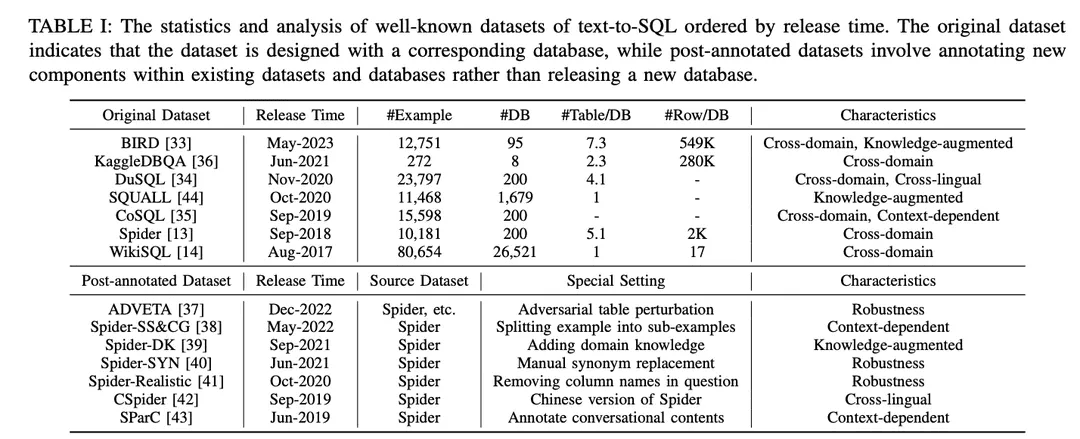
Wie in Tabelle I dargestellt, werden die Datensätze in "Originaldatensätze" und "Post-Annotation-Datensätze" eingeteilt. Die Datensätze werden in "Originaldatensätze" und "Post-Annotation-Datensätze" eingeteilt, je nachdem, ob die Datensätze mit den Originaldatensätzen und -datenbanken veröffentlicht oder durch spezielle Einstellungen an den vorhandenen Datensätzen und Datenbanken erstellt wurden. Für den Originaldatensatz wird eine detaillierte Analyse vorgelegt, einschließlich der Anzahl der Beispiele, der Anzahl der Datenbanken, der Anzahl der Tabellen pro Datenbank und der Anzahl der Zeilen pro Datenbank. Für die kommentierten Datensätze werden ihre Quelldatensätze identifiziert und die besonderen Einstellungen beschrieben, die auf sie angewendet wurden. Um die potenziellen Möglichkeiten eines jeden Datensatzes zu veranschaulichen, wurde er anhand seiner Merkmale kommentiert. Die Anmerkungen sind ganz rechts in Tabelle I aufgeführt. Sie werden im Folgenden ausführlicher erläutert.
1) Domänenübergreifende Datensätze: bezieht sich auf Datensätze, bei denen die Hintergrundinformationen für verschiedene Datenbanken aus unterschiedlichen Domänen stammen. Da reale Text-zu-SQL-Anwendungen in der Regel Datenbanken aus mehreren Domänen einbeziehen, sind die meisten der ursprünglichen Text-zu-SQL-Datensätze [13,14,33 - 36] und Post-Annotation-Datensätze [37 -43] domänenübergreifend aufgebaut, was für domänenübergreifende Anwendungen gut geeignet ist.
2) Mit Wissen angereicherte DatensätzeIn den letzten Jahren hat das Interesse an der Einbeziehung von domänenspezifischem Wissen in Text-zu-SQL-Aufgaben stark zugenommen.BIRD [ 33] nutzt menschliche Datenbankexperten, um jedes Text-zu-SQL-Beispiel mit externem Wissen zu annotieren, das in die Kategorien numerisches Wissen, Domänenwissen, Synonymwissen und Wertaussagen unterteilt ist. In ähnlicher Weise bearbeitete Spider-DK [ 39] manuell eine Version des Spider-Datensatzes [13] für menschliche Redakteure: die SELECT-Spalte wurde weggelassen, einfaches schlussfolgerndes Denken war erforderlich, synonyme Ersetzungen in zellwertigen Wörtern, ein nicht zellwertiges Wort erzeugt eine Bedingung und ist anfällig für Konflikte mit anderen Domänen. Beide Studien ergaben, dass manuell annotiertes Wissen die Leistung der SQL-Generierung bei Beispielen, die externes Domänenwissen erfordern, deutlich verbessert. Darüber hinaus wird in SQUALL [44] das Alignment zwischen Wörtern in NL-Problemen und Entitäten in SQL manuell annotiert, was eine feinere Überwachung als in anderen Datensätzen ermöglicht.
3) Kontextabhängige DatensätzeSParC [43] und CoSQL [35] erforschen die kontextabhängige SQL-Generierung durch den Aufbau eines Abfragesystems für Sitzungsdatenbanken. Im Gegensatz zu herkömmlichen Text-zu-SQL-Datensätzen, die ein einziges Frage-SQL-Paar mit nur einem Beispiel haben, zerlegt SParC die Frage-SQL-Beispiele im Spider-Datensatz in mehrere Unterfrage-SQL-Paare, um simulierte und sinnvolle Interaktionen aufzubauen, einschließlich miteinander verbundener Unterfragen, die zur SQL-Generierung beitragen, und nicht zusammenhängender Unterfragen, die die Datenvielfalt erhöhen. Im Gegensatz dazu beinhaltet CoSQL natürlichsprachliche Dialoginteraktionen, die reale Szenarien simulieren, um die Komplexität und Vielfalt zu erhöhen. Darüber hinaus teilt Spider-SS&CG [38] das NL-Problem im Spider-Datensatz [13] in mehrere Teilprobleme und Teil-SQLs auf und zeigt, dass das Training auf diesen Teilbeispielen die Verteilung der Stichproben der Generalisierungsfähigkeiten des Text-to-SQL-Systems verbessert.
4) Datensätze zur RobustheitSpider-Realistic [ 41] entfernt explizit schemabezogene Begriffe aus NL-Problemen, während Spider-SYN [ 40] sie durch manuell ausgewählte Synonyme ersetzt.ADVETA [ 37] führte die "adversarial table perturbation" (ATP) ein, die die Tabelle stört, indem sie die ursprünglichen Spaltennamen durch irreführende Substitutionen ersetzt und neue Spalten mit hoher semantischer Relevanz, aber geringer semantischer Äquivalenz einfügt. Diese Störungen können zu einer erheblichen Verschlechterung der Genauigkeit führen, da weniger robuste Text-zu-SQL-Systeme durch falsche Übereinstimmungen zwischen Token und Datenbankentitäten in NL-Problemen irregeführt werden können.
5) Sprachübergreifende DatensätzeCSpider [ 42 ] übersetzte den Spider-Datensatz ins Chinesische und fand neue Herausforderungen bei der Wortsegmentierung und dem sprachübergreifenden Abgleich zwischen chinesischen Fragen und englischen Datenbankinhalten.DuSQL [34] stellte einen praktischen Text-zu-SQL-Datensatz mit chinesischen Fragen und englischen und chinesischen Datenbankinhalten vor. chinesischen Fragen und englischen und chinesischen Datenbankinhalten.
B. Bewertungsindikatoren
Für Text-zu-SQL-Aufgaben werden die folgenden vier weit verbreiteten Bewertungsmetriken eingeführt: "Component Matching" und "Exact Matching" auf der Grundlage der SQL-Inhaltsübereinstimmung sowie "Execution Accuracy" auf der Grundlage der Ausführungsergebnisse "und "Effective Efficiency Score".
1) Metriken auf der Grundlage der Übereinstimmung von InhaltenDie SQL-Content-Matching-Metrik basiert in erster Linie auf der strukturellen und syntaktischen Ähnlichkeit der vorhergesagten SQL-Abfrage mit der zugrunde liegenden realen SQL-Abfrage.
Komponentenanpassung (CM)[13] Die Leistung eines Text-zu-SQL-Systems wird bewertet, indem genaue Übereinstimmungen zwischen vorhergesagten SQL-Komponenten (SELECT, WHERE, GROUP BY, ORDER BY und KEYWORDS) und realen SQL-Komponenten (GROUP BY, ORDER BY und KEYWORDS) unter Verwendung von F1-Scores gemessen werden. Jede Komponente wird in Sätze von Unterkomponenten zerlegt und auf exakte Übereinstimmungen verglichen, wobei SQL-Komponenten ohne Ordnungseinschränkungen berücksichtigt werden.
Genaue Übereinstimmung (EM))[ 13] misst den Prozentsatz der Beispiele, bei denen die vorhergesagte SQL-Abfrage genau mit der echten SQL-Abfrage übereinstimmt. Eine vorhergesagte SQL-Abfrage wird nur dann als korrekt angesehen, wenn alle ihre Komponenten (wie in CM beschrieben) genau mit den Komponenten der Grundwahrheitsabfrage übereinstimmen.
2) Durchführungsbezogene IndikatorenAusführungsergebnisse: Die Ausführungsergebnis-Metrik bewertet die Korrektheit der generierten SQL-Abfrage, indem sie die durch die Ausführung der Abfrage in der Zieldatenbank erzielten Ergebnisse mit den erwarteten Ergebnissen vergleicht.
Ausführungsgenauigkeit (EX)[13] Die Korrektheit einer vorhergesagten SQL-Abfrage wird gemessen, indem die Abfrage in der entsprechenden Datenbank ausgeführt und die Ergebnisse mit denen der echten Basisabfrage verglichen werden.
Effektiver Wirkungsgrad (VES)Die Definition von [33] ist die Messung der Effizienz einer effektiven SQL-Abfrage. Eine effektive SQL-Abfrage ist eine vorhergesagte SQL-Abfrage, deren Ausführungsergebnis mit dem zugrunde liegenden wahren Ergebnis identisch ist. Konkret wertet VES gleichzeitig ausVorhersage der Effizienz und Genauigkeit von SQL-Abfragen. Für einen Textdatensatz, der N Beispiele enthält, wird die VES wie folgt berechnet:

R(Y_n, Y_n) bezeichnet die relative Ausführungseffizienz der vorhergesagten SQL-Abfrage im Vergleich zur tatsächlichen Abfrage.
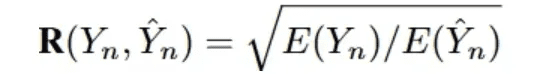
Die jüngste LLM-basierte Text-zu-SQL-Forschung hat sich auf diese vier Datensätze konzentriert: Spider [13], Spider-Realistic [41], Spider-SYN [40] und BIRD [33]; und die drei Evaluierungsmethoden EM, EX und VES, die im Mittelpunkt der folgenden Analyse stehen.
Methodologien
Aktuelle Implementierungen von LLM-basierten Anwendungen stützen sich stark auf die Paradigmen In-Context Learning (ICL) (Just-in-Time Engineering) [87-89] und Fine-Tuning (FT) [90,91], da leistungsstarke proprietäre und gut architektierte Open-Source-Modelle in großer Zahl veröffentlicht werden [45,86,92-95]. LLM-basierte Text-to-SQL-Systeme folgen diesen Paradigmen bei der Implementierung. In dieser Übersicht werden sie entsprechend diskutiert.
A. kontextuelles Lernen
In umfangreichen und anerkannten Forschungsarbeiten hat sich gezeigt, dass das Hint-Engineering eine entscheidende Rolle für die Leistung von LLMs spielt [28 , 96 ] und die SQL-Generierung unter verschiedenen Hint-Stilen beeinflusst [9 , 46]. Daher ist die Entwicklung von Text-zu-SQL-Methoden im Paradigma des kontextuellen Lernens (ICL) wertvoll, um vielversprechende Verbesserungen zu erzielen. Eine Implementierung eines LLM-basierten Text-zu-SQL-Prozesses, der eine ausführbare SQL-Abfrage Y erzeugt, kann wie folgt formuliert werden:

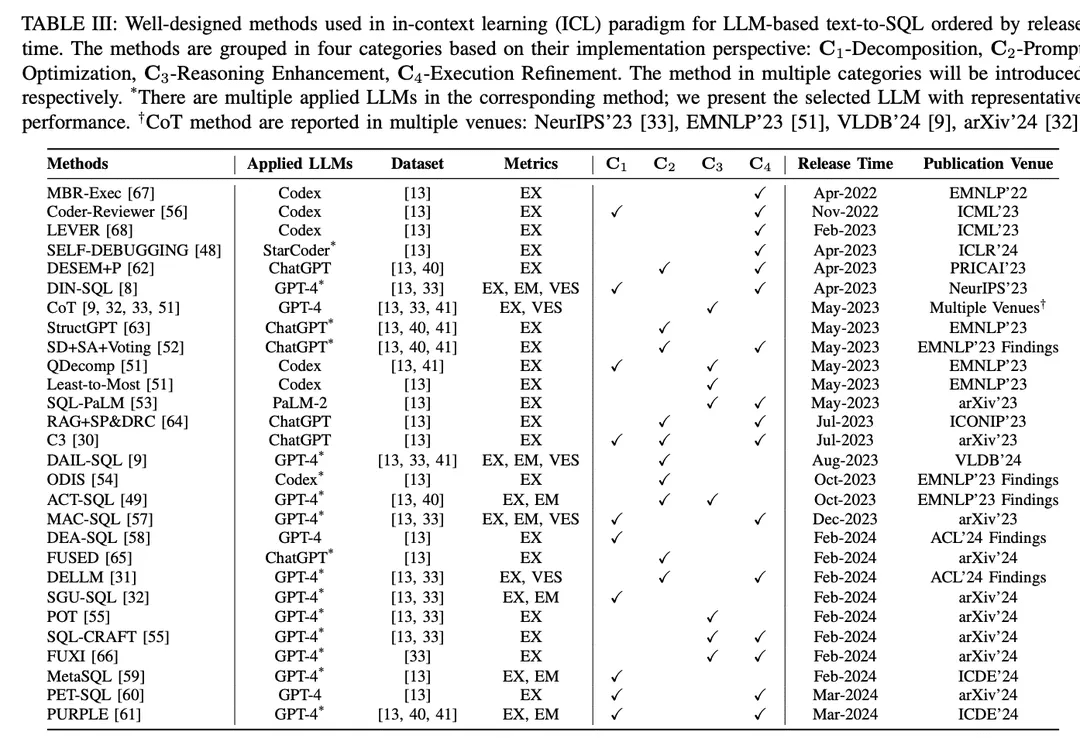
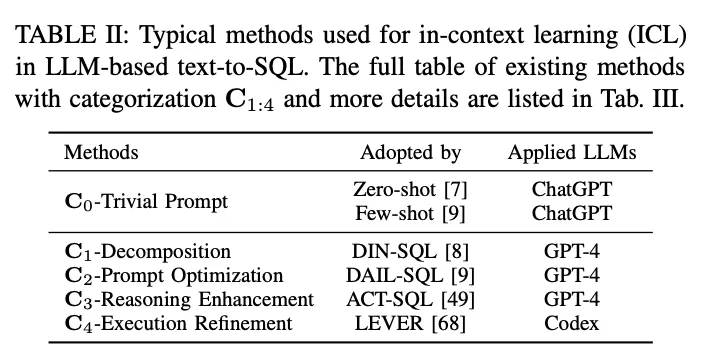
Im Paradigma des kontextuellen Lernens (ICL) wird ein Text-zu-SQL-Modell von der Stange (d. h. der Modellparameter θ ist eingefroren) verwendet, um vorhergesagte SQL-Abfragen zu generieren. LLM-basierte Text-zu-SQL-Aufgaben verwenden eine Vielzahl von gut konzipierten Methoden im ICL-Paradigma. Sie werden in fünf Kategorien C0:4 eingeteilt, darunter C0-Simple Hinting, C1-Decomposition, C2-Hint Optimisation, C3-Inference Enhancement und C4-Execution Refinement. In Tabelle II sind die Vertreter der einzelnen Kategorien aufgeführt.
C0-Triviale AufforderungLLM wurde auf massiven Daten trainiert und verfügt über eine starke Gesamtleistung bei verschiedenen nachgelagerten Aufgaben mit Null-Stichproben und einer geringen Anzahl von Hinweisen [90 , 97, 98 ], was in der Praxis weithin anerkannt und angewendet wird. In der Umfrage wurden die oben genannten Prompting-Methoden ohne aufwendiges Framing als triviale Prompts (false prompt engineering) kategorisiert. Wie bereits erwähnt, beschreibt Gl. 3 das LLM-basierte Text-zu-SQL-Verfahren, das auch als Zero-Sample-Prompting bezeichnet werden kann. Die Gesamteingabe P0 ergibt sich aus der Verkettung von I, S und Q. Die Eingabe P0 ist identisch mit der Gesamteingabe P0:
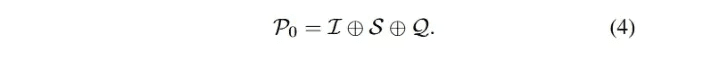
Um den Prompting-Prozess zu standardisieren, wurde OpenAI demo2 als (einfacher) Standard-Prompt für Text to SQL [30] eingerichtet.
NullprobeViele Forschungsarbeiten [7,27,46] verwenden Zero-Sample-Hinting und konzentrieren sich auf die Auswirkungen von Hint-Konstruktionsstilen und verschiedenen LLMs auf die Zero-Sample-Leistung von Text-to-SQL. In [7] wurde die Leistung verschiedener früh entwickelter LLMs [85, 99, 100] für die Basisfunktionalität von Text-zu-SQL sowie für verschiedene Hinting-Stile empirisch ausgewertet. Die Ergebnisse zeigen, dass das on-the-fly Design entscheidend für die Leistung ist, und durch die Fehleranalyse legt [7] nahe, dass mehr Datenbankinhalt die Gesamtgenauigkeit beeinträchtigen kann. Da die ChatGPT mit beeindruckenden Fähigkeiten in Dialogszenarien und Codegenerierung [101], [27] evaluierte seine Text-to-SQL-Leistung. Die Ergebnisse zeigen, dass ChatGPT im Vergleich zu modernen PLM-basierten Systemen eine ermutigende Text-to-SQL-Leistung aufweist. Um eine faire Vergleichbarkeit zu gewährleisten, haben [47] effektive Prompting-Konstrukte für LLM-basierte Text-to-SQL-Systeme aufgedeckt; sie untersuchten verschiedene Arten von Prompting-Konstrukten und schlussfolgerten auf der Grundlage des Vergleichs ein Prompting-Design für Null-Proben.
Primär- und Fremdschlüssel enthalten kontinuierliches Wissen über verschiedene Tabellen. In [49] wurde ihre Auswirkung untersucht, indem diese Schlüssel in verschiedene Hint-Stile für unterschiedliche Datenbankinhalte integriert und die Ergebnisse der Null-Stichprobe für Hinting analysiert wurden. Die Auswirkung von Fremdschlüsseln wurde auch in einer Benchmark-Evaluierung [9] untersucht, bei der fünf verschiedene Hint-Darstellungsstile einbezogen wurden, von denen jeder als eine Permutation von Direktiven, Regelbedeutungen und Fremdschlüsseln betrachtet werden kann. Zusätzlich zu den Fremdschlüsseln wurde in dieser Studie auch die Kombination von Null-Proben-Hinweisen und "Nicht-Interpretations"-Regelimplikationen untersucht, um prägnante Ausgaben zu sammeln. Unterstützt durch die Annotation von externem Wissen menschlicher Experten, folgte [33 ] den Standardhinweisen und erzielte Verbesserungen durch die Kombination des bereitgestellten annotierten Orakelwissens.
Mit der explosionsartigen Zunahme von Open-Source-LLMs sind diese Modelle nach ähnlichen Bewertungen [45, 46, 50] auch in der Lage, stichprobenlos Text-zu-SQL-Aufgaben zu lösen, insbesondere Codegenerierungsmodelle [46, 48]. Für die Zero-Sample-Hinting-Optimierung stellten [46] die Herausforderung dar, effektive Hinting-Templates für LLMs zu entwerfen; bisherigen Hinting-Konstrukten fehlte es an struktureller Einheit, was es schwierig machte, spezifische Elemente in den Hinting-Konstrukt-Templates zu identifizieren, die die Leistung von LLMs beeinflussen. Um diese Herausforderung anzugehen, untersuchten sie eine Reihe von einheitlicheren Hinweisschablonen, die mit verschiedenen Präfixen, Suffixen und Präfix-Postfixen abgestimmt waren.
Ein paar TippsDie Technik der kleinen Anzahl von Hints ist sowohl in praktischen Anwendungen als auch in der Forschung weit verbreitet und hat sich bei der Verbesserung der LLM-Leistung als effektiv erwiesen [ 28 , 102 ]. Das gesamte Eingabe-Hinting der LLM-basierten Text-zu-SQL-Hinting-Methode für eine kleine Anzahl von Hints kann als eine Erweiterung von Gleichung 3 formuliert werden:

In einer empirischen Studie wurde das few-shot hinting für text-to-SQL über mehrere Datensätze und verschiedene LLMs hinweg evaluiert [8 , 32] und zeigte eine gute Leistung im Vergleich zum zero-sample hinting. [33] liefert ein detailliertes Beispiel für einen One-Shot-Trigger eines Text-to-SQL-Modells zur Generierung präziser SQL. In [55] wird der Einfluss einer kleinen Anzahl von Beispielen untersucht. [52] konzentriert sich auf Sampling-Strategien, indem es die Ähnlichkeit und Vielfalt zwischen verschiedenen Beispielen untersucht, ein Benchmarking von Zufallsstichproben durchführt und verschiedene Strategien8 und ihre Kombinationen zum Vergleich bewertet. Zusätzlich zur ähnlichkeitsbasierten Auswahl evaluiert [9] die oberen Grenzen der Ähnlichkeitsauswahl für Maskierungsprobleme und Ähnlichkeitsmethoden mit einer unterschiedlichen Anzahl von weniger Beispielen. In einer Studie zur Stichprobenauswahl auf Schwierigkeitsstufen [51] wurde die Leistung des Codex [100] für kleine Stichproben mit der zufälligen und der auf der Schwierigkeit basierenden Auswahl von Instanzen mit kleinen Stichproben auf dem kategorialen Schwierigkeitsdatensatz [13, 41] verglichen. Es wurden drei schwierigkeitsbasierte Auswahlstrategien entwickelt, die auf der Anzahl der ausgewählten Stichproben bei unterschiedlichen Schwierigkeitsgraden basieren. In [49] wurde eine hybride Strategie zur Auswahl von Stichproben verwendet, die statische Beispiele und auf Ähnlichkeit basierende dynamische Beispiele für eine kleine Anzahl von Stichwörtern kombiniert. In ihrem Setup evaluieren sie auch die Auswirkungen verschiedener Eingabemuster und verschiedener statischer und dynamischer Stichprobengrößen.
Die Auswirkungen einer geringen Anzahl von Beispielen in verschiedenen Bereichen werden ebenfalls untersucht [54]. Wenn eine unterschiedliche Anzahl von domäneninternen und domänenexternen Beispielen einbezogen wurde, schnitten die domäneninternen Beispiele besser ab als die nullwertigen und domänenexternen Beispiele, dieMit zunehmender Anzahl von Beispielen wird die Leistung der bereichsinternen Beispiele besser. Um den detaillierten Aufbau von Eingabehinweisen zu erforschen, verglich [53] die Gestaltungsansätze von knappen und ausführlichen Hinweisen. Bei ersterem werden das Schema, die Spaltennamen sowie die Primär- und Fremdschlüssel nach Einträgen aufgeschlüsselt, während sie bei letzterem in natürlichsprachliche Beschreibungen umgewandelt werden.
C1-ZerlegungAls intuitive Lösung kann die Zerlegung von anspruchsvollen Benutzerproblemen in einfachere Teilprobleme oder deren Implementierung unter Verwendung mehrerer Komponenten die Komplexität der gesamten Text-zu-SQL-Aufgabe reduzieren [8, 51]. Bei weniger komplexen Problemen hat LLM das Potenzial, genauere SQL zu generieren.LLM-basierte Text-zu-SQL-Zerlegungsmethoden lassen sich in zwei Paradigmen einteilen:(1) Aufschlüsselung der TeilaufgabenDurch die Zerlegung der gesamten Text-zu-SQL-Aufgabe in besser handhabbare und effizientere Teilaufgaben (z. B. Schemaverknüpfung [71], Domänenklassifizierung [54]) wird zusätzliches Parsing zur Unterstützung der endgültigen SQL-Generierung bereitgestellt.(2) Zerlegung des TeilproblemsDecompose the user problem into sub-problems to reduce the complexity and difficulty of the problem, and then derive the final SQL query by solving these problems to generate sub-SQL.
DIN-SQL[DIN-SQL erzeugt zunächst die Schemaverknüpfung zwischen dem Benutzerproblem und der Zieldatenbank; das nachfolgende Modul zerlegt das Benutzerproblem in verwandte Unterprobleme und klassifiziert die Schwierigkeit. Auf der Grundlage der oben genannten Informationen generiert das SQL-Generierungsmodul die entsprechende SQL, und das Selbstkorrekturmodul identifiziert und korrigiert mögliche Fehler in der vorhergesagten SQL. Der Coder-Reviewer [56] schlägt einen Reordering-Ansatz vor, der ein Coder-Modell zur Generierung von Anweisungen und ein Reviewer-Modell zur Bewertung der Wahrscheinlichkeit von Anweisungen kombiniert.
Unter Bezugnahme auf Chain-of-Thought [103] und Least-to-Most-Hinweise [104] wird dieQDecompIn [51] wurde der Problemzerlegungshinweis eingeführt, der der Problemreduzierungsphase vom letzten bis zum letzten Hinweis folgt und den LLM anweist, die Zerlegung des ursprünglichen komplexen Problems als Zwischenschritt durchzuführen
C3 [30] besteht aus drei Hauptkomponenten: Klarheitshinweise, Kalibrierungshinweise und Konsistenz; diese Komponenten werden implementiert, indem ChatGPT verschiedene Aufgaben zugewiesen werden. Zunächst generiert die Komponente Klarheitshinweise Schemalinks und verfeinerte fragestellungsbezogene Schemata als Klarheitshinweise. Dann werden mehrere Dialogrunden über Text-zu-SQL-Hinweise als Kalibrierungshinweise verwendet, die mit klaren Hinweisen kombiniert werden, um die SQL-Generierung anzuleiten. Die generierten SQL-Abfragen werden durch konsistenz- und ausführungsbasierte Abstimmung gefiltert, um die endgültige SQL zu erhalten.
MAC-SQL[57] schlug ein kollaboratives Multi-Agenten-Framework vor; der Text-zu-SQL-Prozess wird durch die Zusammenarbeit von Agenten wie Selektoren, Dekomposierer und Verfeinerer durchgeführt. Der Selektor speichert relevante Tabellen für das Benutzerproblem; der Decomposer zerlegt das Benutzerproblem in Teilprobleme und liefert Lösungen; der Refiner schließlich validiert und optimiert die fehlerhafte SQL.
DEA-SQL [58] stellt ein Workflow-Paradigma vor, das darauf abzielt, die Aufmerksamkeit und den Problemlösungsumfang von LLM-basiertem Text-to-SQL durch Dekomposition zu verbessern. Der Ansatz zerlegt die Gesamtaufgabe so, dass das SQL-Generierungsmodul entsprechende vorausgehende (Informationsbestimmung, Problemklassifizierung) und nachfolgende (Selbstkorrektur, aktives Lernen) Teilaufgaben hat. Das Workflow-Paradigma ermöglicht es LLM, genauere SQL-Abfragen zu generieren
SGU-SQL [32] ist ein Structure-to-SQL-Framework, das inhärente Strukturinformationen zur Unterstützung der SQL-Generierung nutzt. Konkret baut das Framework Graphenstrukturen für Benutzerfragen bzw. entsprechende Datenbanken auf und verwendet dann kodierte Graphen, um strukturelle Verbindungen herzustellen [105 , 106]. Meta-Operatoren werden verwendet, um Benutzerprobleme mithilfe von Syntaxbäumen zu zerlegen, und schließlich werden Meta-Operatoren in SQL verwendet, um Eingabeaufforderungen zu entwerfen.
MetaSQL [59] stellt einen dreistufigen Ansatz für die SQL-Generierung vor: Zerlegung, Generierung und Sortierung. In der Dekompositionsphase wird eine Kombination aus semantischer Dekomposition und Metadaten verwendet, um Benutzerprobleme zu lösen. Unter Verwendung der zuvor verarbeiteten Daten als Input werden einige SQL-Kandidatenabfragen unter Verwendung des Text-zu-SQL-Modells generiert, das aus den Metadaten-Bedingungen erzeugt wurde. Schließlich wird eine zweistufige Sortierpipeline angewandt, um die globale optimale SQL-Abfrage zu erhalten.
PET-SQL [60] stellt einen zweistufigen Rahmen vor, der durch Hinweise erweitert wird. Zunächst weisen gut gestaltete Hinweise den LLM an, vorläufige SQL (PreSQL) zu generieren, wobei einige kleine Demonstrationen auf der Grundlage von Ähnlichkeiten ausgewählt werden. Dann werden auf der Grundlage von PreSQL Schema-Links gefunden und kombiniert, um den LLM zur Generierung von Final SQL (FinSQL) zu veranlassen. Schließlich wird FinSQL unter Verwendung mehrerer LLMs generiert, um die Konsistenz auf der Grundlage der Ausführungsergebnisse sicherzustellen.
C2-Prompt-OptimierungWie bereits beschrieben, wurde das Lernen in wenigen Minuten für LLMs ausgiebig untersucht [85]. Für LLM-basiertes Text-zu-SQL (Text-zu-SQL) und Kontextlernen haben triviale Wenig-Minuten-Methoden vielversprechende Ergebnisse erbracht [8, 9, 33], und eine weitere Optimierung des Wenig-Minuten-Hintings hat das Potenzial für eine bessere Leistung. Da die Genauigkeit der SQL-Generierung in handelsüblichen LLMs stark von der Qualität der entsprechenden Eingabehinweise abhängt [107], stehen viele Determinanten, die die Qualität der Hinweise beeinflussen, im Mittelpunkt der aktuellen Forschung [9] (z. B. Qualität und Quantität der Organisation der Oligohinweise, Ähnlichkeit zwischen dem Benutzerproblem und den Instanzen der Oligohinweise, externes Wissen/Hinweise).
DESEM [62] ist ein Cue-Engineering-Rahmenwerk mit De-Semantisierung und Skeleton-Retrieval. Das Framework setzt zunächst ein domänenspezifisches Wortmaskierungsmodul ein, um semantische Token zu entfernen, die die Absicht in Benutzerfragen bewahren. Anschließend wird ein einstellbares Hinting-Modul verwendet, um eine kleine Anzahl von Beispielen mit der gleichen Absicht wie die Frage abzurufen, und dies wird mit der Relevanzfilterung von Mustern kombiniert, um die SQL-Generierung für das LLM zu steuern.
QDecomp [Das Framework führt einen InterCOL-Mechanismus ein, der inkrementell dekomponierte Teilprobleme mit zugehörigen Tabellen- und Spaltennamen kombiniert. Durch eine schwierigkeitsbasierte Auswahl wird eine kleine Anzahl von QDecomp-Beispielen auf ihre Schwierigkeit hin untersucht. Zusätzlich zur Ähnlichkeits-Diversitäts-Stichprobe schlug [ 52 ] die SD+SA+Voting (similarity-diversity+pattern augmentation+voting) Stichprobenstrategie vor. Dabei wird zunächst eine kleine Anzahl von Beispielen unter Verwendung der semantischen Ähnlichkeit und der k-Means-Clustervielfalt ausgewählt, und dann werden die Hinweise mit Hilfe von Musterwissen (semantische oder strukturelle Augmentation) erweitert.
C3 Das Framework [30] besteht aus einer Komponente für eindeutige Hinweise, die Fragen und Schemata als Eingabe für die LLMs verwendet, und einer Kalibrierungskomponente, die Hinweise bereitstellt und einen eindeutigen Hinweis generiert, der ein Schema enthält, das redundante Informationen entfernt, die nicht mit der Frage des Benutzers zusammenhängen, sowie einen Schemalink. Das Retrieval Enhancement Framework führt sample-aware hints [64] ein, die das ursprüngliche Problem vereinfachen und das Problemskelett aus dem vereinfachten Problem extrahieren, um dann die Suche nach Beispielen im Repository auf der Grundlage der Ähnlichkeit der Skelette zu vervollständigen. Die abgerufenen Beispiele werden mit dem ursprünglichen Problem für eine kleine Anzahl von Hinweisen kombiniert.
ODIS [54] führt eine Stichprobenauswahl unter Verwendung von Präsentationen außerhalb des Bereichs und synthetischen Daten innerhalb des Bereichs ein, die eine kleine Anzahl von Präsentationen aus einer Mischung von Quellen abruft, um die Charakterisierung von Hinweisen zu verbessern
DAIL-SQL[DAIL Selection maskiert zunächst das domänenspezifische Vokabular der Benutzer und eine kleine Anzahl von Beispielproblemen und ordnet dann die Kandidatenbeispiele auf der Grundlage der eingebetteten euklidischen Distanz ein. Gleichzeitig wird die Ähnlichkeit zwischen vorhergesagten SQL-Abfragen berechnet. Schließlich erhält der Auswahlmechanismus Kandidatenbeispiele, die nach Ähnlichkeit sortiert sind und auf vordefinierten Kriterien basieren. Durch diesen Ansatz wird sichergestellt, dass eine kleine Anzahl von Beispielen eine gute Ähnlichkeit sowohl mit dem Problem als auch mit der SQL-Abfrage aufweist.
ACT-SQLIn [49] wurden dynamische Beispiele für die Auswahl auf der Grundlage von Ähnlichkeitswerten vorgestellt.
FUSED[65] schlägt vor, einen Pool von Präsentationen mit hoher Diversität durch mehrere manuelle Iterationen der Synthese zu erstellen, um die Diversität von "few-shot"-Präsentationen zu verbessern.FUSED's Pipeline sammelt Präsentationen, die durch Clustering fusioniert werden sollen, und fusioniert dann die gesampelten Präsentationen, um einen Pool von Präsentationen zu erstellen und so die Effektivität des "few-shot"-Lernens zu verbessern.
Wissen-zu-SQL [31] Das Framework zielt darauf ab, Datenexperten-LLMs (DELLMs) zu erstellen, um Wissen für die SQL-Generierung bereitzustellen.
DELLM DELLM generiert vier Arten von Wissen und gut konzipierte Methoden (z.B. DAIL-SQL [9], MAC-SQL [57 ]) beziehen das generierte Wissen ein, um eine bessere Leistung für LLM-basiertes Text-zu-SQL durch kontextuelles Lernen zu erreichen.
C3-Reasoning Enhancement:LLMs haben gute Fähigkeiten in Aufgaben gezeigt, die den gesunden Menschenverstand, symbolisches Denken und arithmetisches Denken beinhalten [108]. In Text-zu-SQL-Aufgaben treten numerisches Schließen und synonymes Schließen oft in realistischen Szenarien auf [ 33 , 41 ]. Jüngste Forschungen haben sich auf die Integration von gut konzipierten Methoden zur Verbesserung des schlussfolgernden Denkens für die Text-zu-SQL-Anpassung, die Verbesserung von LLMs zur Bewältigung der Herausforderungen komplexer Probleme, die anspruchsvolles schlussfolgerndes Denken erfordern3 , und die Selbstkonsistenz bei der SQL-Generierung konzentriert.
Die Chain-of-Thoughts (CoT)-Hinweistechnik [103] besteht aus einem umfassenden Denkprozess, der den LLM zu präzisem Denken anleitet und die Denkfähigkeit des LLM stimuliert. LLM-Text-zu-SQL-basierte Studien verwenden CoT-Hinweise als Regel-Hinweise [9], wobei die Anweisungen für die Schritt-für-Schritt-Denkweise in der Hinweiskonstruktion enthalten sind [9, 32, 33, 51]. Die einfache (primitive) CoT-Strategie für Text-zu-SQL-Aufgaben hat jedoch nicht das Potenzial gezeigt, das sie für andere Schlussfolgerungsaufgaben hat; die Forschung zur Anpassung von CoT ist noch nicht abgeschlossen [51]. Da CoT-Hinweise immer anhand von statischen Beispielen mit manuellen Anmerkungen demonstriert werden, erfordert dies eine empirische Beurteilung, um eine kleine Anzahl von Beispielen, für die manuelle Anmerkungen unerlässlich sind, effektiv auszuwählen.
Als Lösung.ACT-SQL In [49] wird eine Methode zur automatischen Generierung von CoT-Beispielen vorgeschlagen. Konkret trunkiert ACT-SQL bei einem Problem die Menge der Slices des Problems und zählt dann jede Spalte auf, die in der entsprechenden SQL-Abfrage erscheint. Jede Spalte wird über eine Ähnlichkeitsfunktion mit dem relevantesten Slice verknüpft und an einen CoT-Hinweis angehängt.
QDecomp [51] Durch eine systematische Studie zur Verbesserung der SQL-Generierung für LLMs in Verbindung mit CoT-Hinweisen wird ein neuartiger Rahmen vorgeschlagen, um die Herausforderung anzugehen, wie CoT Argumentationsschritte zur Vorhersage von SQL-Abfragen vorschlägt. Der Rahmen verwendet jedes Fragment einer SQL-Abfrage, um die logischen Schritte der CoT-Schlussfolgerung zu konstruieren, und verwendet dann natürlichsprachliche Vorlagen, um jedes Fragment einer SQL-Abfrage auszuarbeiten und sie in der logischen Reihenfolge der Ausführung anzuordnen.
Am wenigsten bis am meisten [104] ist eine weitere Hinweismethode, bei der das Problem in Teilprobleme zerlegt und diese dann nacheinander gelöst werden. Pilotversuche [51] deuten darauf hin, dass dieser Ansatz als iterativer Hinweis für Text-to-SQL-Parsing möglicherweise nicht erforderlich ist. Die Verwendung detaillierter Argumentationsschritte führt tendenziell zu mehr Problemen bei der Fehlerfortpflanzung.
Als eine Variante des CoT ist dieProgramm der Gedanken (PoT)Es wurden Hinting-Strategien [109] vorgeschlagen, um die arithmetische Argumentation des LLM zu verbessern.
Durch die Auswertung von [55] verbessert PoT SQL-generierte LLMs, insbesondere bei komplexen Datensätzen [33].
SQL-CRAFT In [55] wird vorgeschlagen, die LLM-basierte SQL-Generierung durch die Einbeziehung von PoT-Hinweisen für das Python-Augmented Reasoning zu erweitern: Die PoT-Politik erfordert, dass das Modell sowohl Python-Code als auch SQL-Abfragen generiert, wodurch das Modell gezwungen wird, Python-Code in seinen Reasoning-Prozess einzubeziehen.
Kohärenz mit sich selbst[110] ist eine Hinting-Strategie zur Verbesserung des LLM-Schlussfolgerns, die sich die Intuition zunutze macht, dass ein komplexes Schlussfolgerndes Problem typischerweise mehrere verschiedene Denkweisen zulässt, um zu einer einzigen richtigen Antwort zu gelangen. Bei Text-zu-SQL-Aufgaben gilt die Selbstkonsistenz für die Auswahl einer Reihe verschiedener SQLs und die Abstimmung für konsistente SQLs durch Ausführungsfeedback [30 , 53 ].
Gleichermaßen.SD+SA+Abstimmung [52] Der Rahmen verwirft Ausführungsfehler, die von einem deterministischen Datenbankmanagementsystem (DBMS) erkannt werden, und wählt die Vorhersage aus, die die meisten Stimmen erhält.
Darüber hinaus wird, angeregt durch die jüngsten Forschungsarbeiten über die Verwendung von Tools zur Erweiterung der Funktionalität des LLM, dasFUXI [66] wird vorgeschlagen, die SQL-Generierung für LLM durch den effizienten Aufruf von gut konzipierten Tools zu verbessern.
C4 - Verfeinerung der AusführungBei der Entwicklung von Standards für die korrekte SQL-Generierung steht immer die Frage im Vordergrund, ob die generierte SQL erfolgreich ausgeführt werden kann und den Inhalt abruft, um die Frage des Benutzers korrekt zu beantworten [13]. Da es sich um eine komplexe Programmieraufgabe handelt, ist die Generierung der korrekten SQL in einem Durchgang eine große Herausforderung. Intuitiv hilft die Berücksichtigung von Ausführungsrückmeldungen/-ergebnissen während der SQL-Generierung bei der Anpassung an die entsprechende Datenbankumgebung und ermöglicht es dem LLM, potenzielle Ausführungsfehler und Ergebnisse zu sammeln, um entweder die generierte SQL zu verfeinern oder eine Mehrheitsentscheidung zu treffen [30]. Text-to-SQL-Ansätze, die die Ausführung berücksichtigen, beziehen Ausführungsrückmeldungen auf zwei Arten ein:
1) Erneutes Feedback mit einer zweiten Runde von Aufforderungen generierenJede SQL-Abfrage, die in der ersten Antwort generiert wird, wird in der entsprechenden Datenbank ausgeführt, um ein Feedback von der Datenbank zu erhalten. Bei diesem Feedback kann es sich um Fehler oder Ergebnisse handeln, die an die zweite Runde von Aufforderungen angehängt werden. Durch das Lernen dieses Feedbacks im Kontext ist LLM in der Lage, die ursprüngliche SQL-Abfrage zu verfeinern oder neu zu generieren, um die Genauigkeit zu verbessern.
2) Ausführungsbasierte Auswahlrichtlinie für generiertes SQL verwendenWählen Sie mehrere generierte SQL-Abfragen aus dem LLM aus und führen Sie jede Abfrage in der Datenbank aus. Auf der Grundlage des Ausführungsergebnisses jeder SQL-Abfrage wird eine Auswahlstrategie (z. B. Selbstkonsistenz, Mehrheitsabstimmung [60]) verwendet, um eine SQL-Abfrage aus der SQL-Menge zu definieren, die die Bedingungen als die endgültige vorausgesagte SQL erfüllt.
MRC-EXEC [67] schlug ein Natural Language to Code (NL2Code)-Übersetzungsframework mit Ausführung vor, das jede gesampelte SQL-Abfrage bewertet und das Beispiel mit dem kleinsten Ausführungsergebnis auf der Grundlage des Bayes-Risikos auswählt [111].LEVER [68] schlägt eine Methode zur Validierung von NL2Code durch Ausführung vor, bei der die Generierungs- und Ausführungsmodule zum Sammeln von Stichproben des SQL-Satzes bzw. der Ausführungsergebnisse verwendet werden und dann ein lernender Validator die Wahrscheinlichkeit der Korrektheit ausgibt.
In ähnlicher Weise.SELBSTENTSTÖRUNG [Das Modell ist in der Lage, Fehler ohne menschliches Eingreifen zu korrigieren, indem es die Ausführungsergebnisse untersucht und die generierte SQL in natürlicher Sprache interpretiert.
Wie bereits erwähnt, wurde die zweistufige Implikation ausgiebig genutzt, um einen gut konzipierten Rahmen mit Umsetzungsfeedback zu kombinieren:1. Probenahme einer Reihe von SQL-Abfragen. 2. Mehrheitsentscheidung (selbstkonsistent).Konkret.C3[30] Der Rahmen eliminiert Fehler und identifiziert die konsistenteste SQL;Das Retrieval Enhancement Framework [64] führt dynamische Revisionsketten einDie SQL-Bibliothek wurde als selbstkorrigierendes Modul konzipiert, das feinkörnige Ausführungsmeldungen mit Datenbankinhalten kombiniert, um LLMs aufzufordern, generierte SQL-Abfragen in natürlichsprachliche Interpretationen umzuwandeln; LLMs wurden aufgefordert, semantische Lücken zu identifizieren und ihr eigenes generiertes SQL zu modifizieren.Obwohl Schemafilter-Methoden die SQL-Generierung verbessern, kann das generierte SQL nicht ausführbar sein.DESEM [62] fügte eine Fallback-Revision ein, um dieses Problem anzugehen; es DIN-SQL [8] entwickelte generische und sanfte Hinweise in seinem Selbstkorrekturmodul; die generischen Hinweise verlangen vom LLM, Fehler zu identifizieren und zu korrigieren, und die sanften Hinweise verlangen vom Modell, auf mögliche Probleme zu prüfen.
MultiagentensystemMAC-SQL[57] enthält einen Verfeinerungsagenten, der SQL-Fehler erkennt und automatisch korrigiert und SQLite-Fehler- und Ausnahmeklassen verwendet, um korrigiertes SQL zu regenerieren.SQL-CRAFT [55] Der Rahmen sieht eine interaktive Kalibrierung und eine automatische Kontrolle des Bestimmungsprozesses vor, um Über- oder Unterkorrekturen zu vermeiden. FUXI In [66] wird die Fehlerrückmeldung bei werkzeuggestütztem Reasoning für die SQL-Generierung betrachtet. Wissen-zu-SQL [31] haben einen Rahmen für das Präferenzlernen eingeführt, der das Feedback zur Datenbankausführung mit der direkten Präferenzoptimierung [112] kombiniert, um das vorgeschlagene DELLM zu verbessern.PET-SQL[60] schlugen eine Kreuzkonsistenz vor, die aus zwei Varianten besteht: 1) einfache Abstimmung: mehrere LLMs werden angewiesen, eine SQL-Abfrage zu generieren, und dann wird eine Mehrheitsabstimmung verwendet, um die endgültige SQL auf der Grundlage der Ergebnisse der verschiedenen Ausführungen zu entscheiden, und 2) feinkörnige Abstimmung: die einfache Abstimmung wird auf der Grundlage des Schwierigkeitsgrads verfeinert, um eine Verzerrung der Abstimmung abzuschwächen.
B. Feinabstimmung
Da die überwachte Feinabstimmung (SFT) der vorherrschende Ansatz für das Training von LLMs ist [29, 91], ist für Open-Source-LLMs (z.B. LLaMA-2 [94], Gemma [113]) der einfachste Weg zur schnellen Anpassung des Modells an eine bestimmte Domäne die Durchführung von SFT auf dem Modell unter Verwendung von gesammelten Domänenetiketten.Die SFT-Phase ist in der Regel die Anfangsphase eines gut konzipierten Trainings-Frameworks [112, 114], und die Text-zu-SQL-Feinabstimmungsphase. 114], sowie die Text-zu-SQL-Feinabstimmungsphase. Der Prozess der automatischen Regressionserzeugung für die SQL-Abfrage Y kann wie folgt formuliert werden:

Der SFT-Ansatz ist auch eine fiktive Feinabstimmungsmethode für Text-to-SQL und wurde von verschiedenen Open-Source-LLMs in der Text-to-SQL-Forschung weitgehend übernommen [9, 10 , 46 ]. Das Feinabstimmungsparadigma bevorzugt LLM-basierte Text-zu-SQL-Startpunkte gegenüber kontextuellen Lernansätzen (ICL). Es wurden mehrere Studien zur Erforschung besserer Feinabstimmungsmethoden veröffentlicht. Die gut durchdachten Feinabstimmungsmethoden werden je nach ihren Mechanismen in verschiedene Gruppen eingeteilt, wie in Tabelle IV dargestellt:
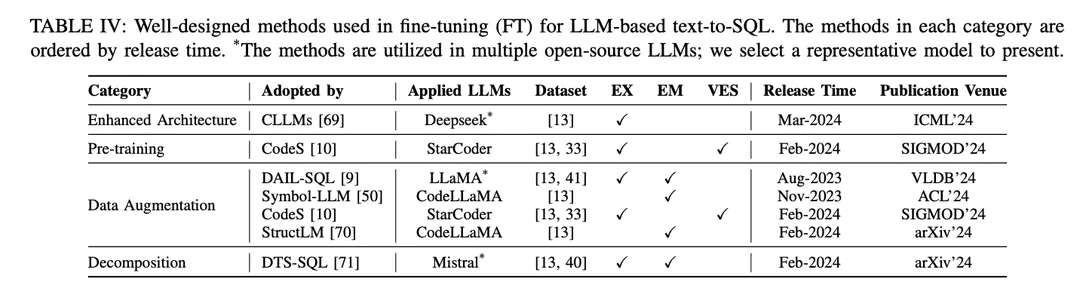
Verbesserte ArchitekturDer weit verbreitete Generative Pretrained Transformer (GPT) nutzt eine reine Decoder-Transformer-Architektur und herkömmliche autoregressive Dekodierung zur Texterzeugung. Jüngste Studien über die Effizienz von LLMs haben ein gemeinsames Problem aufgedeckt: Die Latenzzeit von LLMs ist hoch, da bei der Erzeugung langer Sequenzen mit autoregressiven Mustern ein Aufmerksamkeitsmechanismus eingebaut werden muss [115 , 116 ]. Bei LLM-basierten Text-to-SQL ist die Generierung von SQL-Abfragen im Vergleich zur traditionellen Sprachmodellierung deutlich langsamer [21 , 28 ], was eine Herausforderung für den Aufbau effizienter lokaler NLIDBs darstellt. Als eine der Lösungen zielt CLLM [69] darauf ab, die oben genannten Herausforderungen anzugehen und die SQL-Generierung durch eine verbesserte Modellarchitektur zu beschleunigen.
DatenerweiterungIm Feinabstimmungsprozess ist der direkteste Faktor, der die Modellleistung beeinflusst, die Qualität der Trainingsetiketten [117]. Feinabstimmung mit geringer Qualität oder fehlenden Trainingsetiketten ist ein "No-Brainer", und Feinabstimmung mit qualitativ hochwertigen oder erweiterten Daten übertrifft immer gut konzipierte Feinabstimmungsmethoden für Daten geringer Qualität oder Rohdaten [29, 74]. Bei der datengestützten Feinabstimmung von Text zu SQL wurden beträchtliche Fortschritte erzielt, wobei der Schwerpunkt auf der Verbesserung der Datenqualität im SFT-Prozess liegt.
[117] "Lernen aus verrauschten Etiketten mit tiefen neuronalen Netzen: ein Überblick".[74] Jüngste Fortschritte bei der Umwandlung von Text in SQL: ein Überblick über das, was wir haben und was wir erwarten[29] "Eine Übersicht über große Sprachmodelle"DAIL-SQL [9] ist ein Rahmenwerk für kontextuelles Lernen, das eine Sampling-Strategie verwendet, um weniger Beispielinstanzen zu erhalten. Die Einbeziehung von Stichprobeninstanzen in den SFT-Prozess verbessert die Leistung von Open-Source-LLM.Symbol-LLM [50] schlägt Anweisungen zur Datenerweiterung vor, die auf die injizierten und infundierten Phasen abgestimmt sind.CodeS [10] verbessert die Trainingsdaten durch bidirektionale Generierung mit Hilfe von ChatGPT.StructLM [70] wird auf mehrere strukturelle Wissensaufgaben trainiert, um die Gesamtfähigkeit zu verbessern.
vor der AusbildungPre-Training ist die grundlegende Phase des gesamten Feinabstimmungsprozesses, der darauf abzielt, Textgenerierungsfähigkeiten durch automatisches Regressionstraining auf einer großen Menge von Daten zu erhalten [118]. Traditionell werden aktuelle leistungsstarke proprietäre LLMs (z.B. ChatGPT [119], GPT-4 [86], Claude [120]) auf hybriden Korpora vortrainiert, die hauptsächlich von Dialogszenarien profitieren, die Textgenerierungsfähigkeiten zeigen [85]. Code-spezifische LLMs (z.B. CodeLLaMA [121], StarCoder [122]) werden auf Code-Daten vor-trainiert [100], und die Mischung verschiedener Programmiersprachen ermöglicht es LLMs, Code zu generieren, der den Benutzeranweisungen entspricht [123]. Die größte Herausforderung für Pre-Training-Techniken, die auf SQL als Teilaufgabe der Codegenerierung abzielen, besteht darin, dass SQL-/Datenbank-bezogene Inhalte nur einen kleinen Teil des gesamten vortrainierten Korpus ausmachen.
Infolgedessen haben Open-Source-LLMs mit relativ begrenzten Synthesefähigkeiten (im Vergleich zu ChatGPT, GPT-4) kein gutes Verständnis dafür, wie NL-Probleme während des Pre-Trainings in SQL umgewandelt werden können.Die Pre-Training-Phase des CodeS [10] Modells besteht aus drei Stufen des inkrementellen Pre-Trainings. Ausgehend von der grundlegenden code-spezifischen LLM [122], führt CodeS ein inkrementelles Pre-Training auf einem gemischten Trainingskorpus durch (einschließlich SQL-bezogener Daten, NL-zu-Code-Daten und NL-bezogener Daten). Das Text-zu-SQL-Verständnis und die Leistung werden deutlich verbessert.
ZersetzungDie Zerlegung einer Aufgabe in mehrere Schritte oder die Verwendung mehrerer Modelle zur Lösung einer Aufgabe ist eine intuitive Lösung zur Lösung komplexer Szenarien, wie zuvor im ICL-Paradigma in Kapitel IV-A beschrieben. Die proprietären Modelle, die in ICL-basierten Ansätzen verwendet werden, haben eine große Anzahl von Parametern, die sich auf einer anderen Parameterebene befinden als die Open-Source-Modelle, die in Feinabstimmungsansätzen verwendet werden. Diese Modelle sind von Natur aus in der Lage, die zugewiesenen Teilaufgaben gut auszuführen (durch Mechanismen wie das Lernen mit weniger Stichproben) [30, 57]. Um den Erfolg dieses Paradigmas in einem ICL-Ansatz zu replizieren, ist es daher wichtig, den Open-Source-Modellen die entsprechenden Teilaufgaben (z. B. Generierung von externem Wissen, Schema-Verknüpfung und Verfeinerung von Schemata) rationell zuzuweisen, um sie für die spezifischen Teilaufgaben feinabzustimmen, und die entsprechenden Daten für die Verwendung beim Feintuning zu konstruieren, um die Generierung der endgültigen SQL zu unterstützen.
DTS-SQL [71] schlägt ein zweistufiges dekomponiertes Text-zu-SQL-Feinabstimmungs-Framework vor und entwirft eine Schema-Link-12-Vorgenerierungsaufgabe vor der endgültigen SQL-Generierung.
rechnen Sie mit
Trotz bedeutender Fortschritte in der Text-to-SQL-Forschung gibt es noch einige Herausforderungen, die angegangen werden müssen. In diesem Abschnitt werden die verbleibenden Herausforderungen erörtert, die in der zukünftigen Arbeit überwunden werden sollen.
A. Robustheit in praktischen Anwendungen
Text-to-SQL, implementiert durch LLMs, verspricht Allgemeinheit und Robustheit in realen komplexen Anwendungsszenarien. Trotz der jüngsten beträchtlichen Fortschritte bei der Robustheit spezifischer Datensätze [ 37 , 41] ist ihre Leistung für reale Anwendungen noch nicht ausreichend [ 33]. Es gibt noch einige Herausforderungen, die in der zukünftigen Forschung zu bewältigen sind. Auf der Benutzerseite ist es ein Phänomen, dass der Benutzer nicht immer ein expliziter Fragesteller ist, was bedeutet, dass die Frage des Benutzers möglicherweise keine exakten Datenbankwerte hat oder sich vom Standarddatensatz unterscheidet, in dem Synonyme, falsche Schreibweisen und unscharfe Ausdrücke enthalten sein können [40].
Im Paradigma der Feinabstimmung wird das Modell beispielsweise auf explizit indikative Probleme mit konkreten Darstellungen trainiert. Da das Modell die Zuordnung von Problemen der realen Welt zu den entsprechenden Datenbanken nicht lernt, entsteht bei der Anwendung auf reale Szenarien eine Wissenslücke [33]. Wie in den entsprechenden Auswertungen auf Datensätzen mit Synonymen und unvollständigen Anweisungen [7 , 51] berichtet, enthalten die von ChatGPT generierten SQL-Abfragen etwa 40% fehlerhafte Ausführungen, was 10% niedriger ist als in der ursprünglichen Auswertung [51]. Gleichzeitig kann die Feinabstimmung mit nativem Text auf SQL-Datensätze nicht standardisierte Muster und Bezeichnungen enthalten. Zum Beispiel sind die Namen von Tabellen oder Spalten nicht immer genaue Repräsentationen ihres Inhalts, was zu Inkonsistenzen bei der Konstruktion der Trainingsdaten führt.
B. Rechnerische Effizienz
Die Recheneffizienz wird durch die Geschwindigkeit der Schlussfolgerungen und die Kosten der Rechenressourcen bestimmt, was sowohl bei Anwendungen als auch bei Forschungsarbeiten zu berücksichtigen ist [49, 69]. Mit der zunehmenden Komplexität von Datenbanken in den neuesten Text-to-SQL-Benchmarks [15, 33] enthalten Datenbanken mehr Informationen (einschließlich mehr Tabellen und Spalten) und die Token-Länge des Datenbankschemas nimmt entsprechend zu, was eine Reihe von Herausforderungen darstellt. Beim Umgang mit ultrakomplexen Datenbanken kann die Verwendung des entsprechenden Schemas als Eingabe auf die Herausforderung stoßen, dass die Kosten für den Aufruf proprietärer LLMs erheblich steigen und möglicherweise die maximale Tokenlänge des Modells überschreiten, insbesondere bei der Implementierung von Open-Source-Modellen mit kurzen Kontextlängen.
Eine weitere offensichtliche Herausforderung besteht darin, dass die meisten Studien vollständige Muster als Modelleingaben verwenden, was eine große Menge an Redundanz mit sich bringt [57]. Dem LLM die genauen gefilterten Muster, die für das Problem relevant sind, direkt von der Benutzerseite zur Verfügung zu stellen, um Kosten und Redundanz zu reduzieren, ist eine mögliche Lösung zur Verbesserung der Recheneffizienz [30]. Die Entwicklung einer genauen Methode zur Filterung von Mustern bleibt eine zukünftige Aufgabe. Während das Paradigma des Kontextlernens eine vielversprechende Genauigkeit erreicht hat, erhöhen gut konzipierte mehrstufige Frameworks oder erweiterte Kontextmethoden die Anzahl der API-Aufrufe, was die Leistung unter dem Gesichtspunkt der Recheneffizienz verbessert, aber auch zu einem erheblichen Anstieg der Kosten führt [8].
Bei verwandten Ansätzen [49] sollte der Kompromiss zwischen Leistung und Berechnungseffizienz sorgfältig bedacht werden, und die Entwicklung eines vergleichbaren (oder sogar besseren) Kontextlernansatzes mit geringeren Kosten für die Anwendungsprogrammierschnittstelle wäre eine praktische Umsetzung, die noch erforscht wird. Im Vergleich zu PLM-basierten Ansätzen sind LLM-basierte Ansätze deutlich langsamer in der Argumentation [ 21, 28]. Eine Beschleunigung der Schlussfolgerungen durch eine Verkürzung der Eingabelänge und eine Verringerung der Anzahl der Schritte im Implementierungsprozess ist für das kontextuelle Lernparadigma intuitiv. Für lokales LLM können, ausgehend von [69], weitere Beschleunigungsstrategien untersucht werden, um die Architektur des Modells in zukünftigen Untersuchungen zu verbessern.
Um diese Herausforderung zu bewältigen, würden die Anpassung des LLM an absichtliche Verzerrungen und die Entwicklung von Trainingsstrategien für verrauschte Szenarien den jüngsten Fortschritten zugute kommen. In der Zwischenzeit ist die Datenmenge in realen Anwendungen relativ kleiner als bei forschungsbasierten Benchmarks. Da die Skalierung einer großen Datenmenge durch manuelle Annotation hohe Arbeitskosten verursacht, wird die Entwicklung von Methoden zur Datenerweiterung, um mehr Frage-SQL-Paare zu erhalten, die LLMs unterstützen, wenn die Daten knapp sind. Darüber hinaus ist die Feinabstimmung von Open-Source-LLM für lokale Anpassungsstudien an kleinen Datensätzen potenziell von Vorteil. Darüber hinaus sollten Erweiterungen für mehrsprachige [ 42 , 124 ] und multimodale Szenarien [ 125 ] in der zukünftigen Forschung umfassend untersucht werden, was mehr Sprachgemeinschaften zugute käme und helfen würde, allgemeinere Datenbankschnittstellen zu entwickeln.
C. Datenschutz und Interpretierbarkeit
Als Teil der LLM-Forschung steht LLM-basiertes Text-to-SQL auch vor einigen allgemeinen Herausforderungen, die in der LLM-Forschung bestehen [4 , 126 , 127 ]. Aus der Sicht von Text-to-SQL führen diese Herausforderungen auch zu potenziellen Verbesserungen, die der LLM-Forschung sehr zugute kommen können. Wie bereits in Kapitel IV-A erwähnt, haben kontextuelle Lernparadigmen die jüngste Forschung sowohl in Bezug auf den Umfang als auch auf die Leistung dominiert, wobei die meisten Arbeiten mit proprietären Modellen implementiert wurden [8, 9]. Eine unmittelbare Herausforderung stellt der Datenschutz dar, da der Rückgriff auf proprietäre APIs zur Handhabung der Vertraulichkeit lokaler Datenbanken das Risiko von Datenlecks mit sich bringen kann. Die Verwendung lokaler Feinabstimmungsparadigmen kann dieses Problem teilweise beheben.
Nichtsdestotrotz ist die Leistung der Vanilla-Feinabstimmung derzeit suboptimal [9], und fortgeschrittene Feinabstimmungs-Frameworks können sich auf proprietäre LLMs zur Datenerweiterung verlassen [10]. Basierend auf dem aktuellen Stand der Dinge verdienen maßgeschneiderte Frameworks im Text-zu-SQL-Paradigma für die lokale Feinabstimmung große Aufmerksamkeit. Insgesamt stand die Entwicklung von Deep Learning immer vor Herausforderungen in Bezug auf die Interpretierbarkeit [127 , 128 ].
Als eine seit langem bestehende Herausforderung wurde ein großer Teil der Forschung durchgeführt, um dieses Problem zu lösen [ 129 , 130 ]. Die Interpretierbarkeit von LLM-basierten Implementierungen bleibt jedoch in der Text-zu-SQL-Forschung undiskutiert, entweder in kontextuellen Lern- oder Feinabstimmungsparadigmen. Ansätze mit Dekompositionsstufen erklären Text-zu-SQL-Implementierungen aus einer schrittweisen Generierungsperspektive [8, 51]. Darauf aufbauend bleibt die Kombination von fortgeschrittener Forschung im Bereich der Interpretierbarkeit [131, 132] zur Verbesserung der Leistung von Text-to-SQL und der Erklärung lokaler Modellarchitekturen in Bezug auf Datenbankwissen eine zukünftige Richtung.
D. Erweiterung
Als Teilbereich der LLM- und Natural Language Understanding-Forschung wurde ein Großteil der Forschung in diesen Bereichen durch die Verwendung von Text-to-SQL-Aufgaben [103 , 110] vorangetrieben. Die Text-zu-SQL-Forschung kann jedoch auch auf die breitere Forschung in diesen Bereichen ausgeweitet werden. So ist beispielsweise die SQL-Generierung Teil der Codegenerierung. Gut konzipierte Methoden zur Codegenerierung können auch bei Text-to-SQL eine gute Leistung erzielen [48, 68] und lassen sich auf eine breite Palette von Programmiersprachen verallgemeinern. Die Möglichkeit der Erweiterung einiger angepasster Text-zu-SQL-Frameworks auf NL-zu-Code-Studien kann ebenfalls diskutiert werden.
Beispielsweise erreichen Frameworks, die die Ausführungsausgabe in NL-to-Code integrieren, auch eine hervorragende Leistung bei der SQL-Generierung [8]. Versuche, den ausführungsorientierten Ansatz in Text-to-SQL mit anderen Fortschrittsmodulen [30, 31] auf die Codegenerierung auszuweiten, sind diskussionswürdig. Aus einer anderen Perspektive wurde bereits erörtert, dass Text-to-SQL die LLM-basierte Fragebeantwortung (QA) durch die Bereitstellung von Sachinformationen verbessern kann. Datenbanken können relationales Wissen als strukturelle Informationen speichern, und strukturbasierte QA hat das Potenzial, von Text-zu-SQL zu profitieren (z.B. wissensbasierte Fragenbeantwortung, KBQA [ 133 , 134 ]). Die Nutzung von Datenbankstrukturen zum Aufbau von Faktenwissen und die anschließende Kombination mit einem Text-to-SQL-System zum Informationsabruf hat das Potenzial, die QS bei der Gewinnung von genauerem Faktenwissen zu unterstützen [ 135 ]. Es ist zu erwarten, dass in Zukunft weitere Forschungen zu Text-to-SQL durchgeführt werden.
OlaChat Digital Intelligence Assistant Produkteinführung

OlaChat Digital Intelligence Assistant ist ein neues intelligentes Datenanalyseprodukt, das von Tencents PCG Big Data Platform Department auf den Markt gebracht wurde. Es nutzt große Modelle im Bereich der Datenanalyse in der Praxis der Landung und wurde in DataTalk, OlaIDE und andere interne Mainstream-Datenplattformen von Tencent integriert, um intelligente Unterstützung für den gesamten Prozess der Datenanalyse-Szenarien zu bieten. Es enthält eine Reihe von Funktionen wie text2sql, Indikatoranalyse, intelligente SQL-Optimierung usw. Von der Datenanalyse (Drag-and-Drop-Analyse, SQL-Abfrage) über die Datenvisualisierung bis hin zur Ergebnisinterpretation und -zuordnung trägt OlaChat umfassend dazu bei, die Datenanalyse einfacher und effizienter zu gestalten!
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...