
Ein 10.000 Wörter umfassender Artikel über die RAG-Optimierung in realen DB-GPT-Szenarien.
Vorwort
In den letzten zwei Jahren hat sich die Technologie der Retrieval-Augmented Generation (RAG, Retrieval-Augmented Generation) allmählich zu einem Kernbestandteil der erweiterten Intelligenz entwickelt. Durch die Kombination der dualen Fähigkeiten von Retrieval und Generierung kann RAG externes Wissen einbringen und bietet so mehr Möglichkeiten für die Anwendung großer Modelle in komplexen Szenarien. In praktischen Landungsszenarien gibt es jedoch oft Probleme wie geringe Abrufgenauigkeit, Störgeräusche, Integrität des Abrufs und unzureichende Professionalität, was zu ernsthaften LLM-Illusionen führt. In diesem Beitrag werden wir uns auf die Details der Wissensverarbeitung und des Abrufs von RAG in realen Landungsszenarien konzentrieren, wie man die RAG-Pineline-Verbindung optimiert und letztendlich die Abrufgenauigkeit verbessert.
Es ist einfach, eine RAG Smart Q&A App schnell zu erstellen, aber sie in einem realen Geschäftsszenario einzusetzen, erfordert eine Menge Vorbereitung.
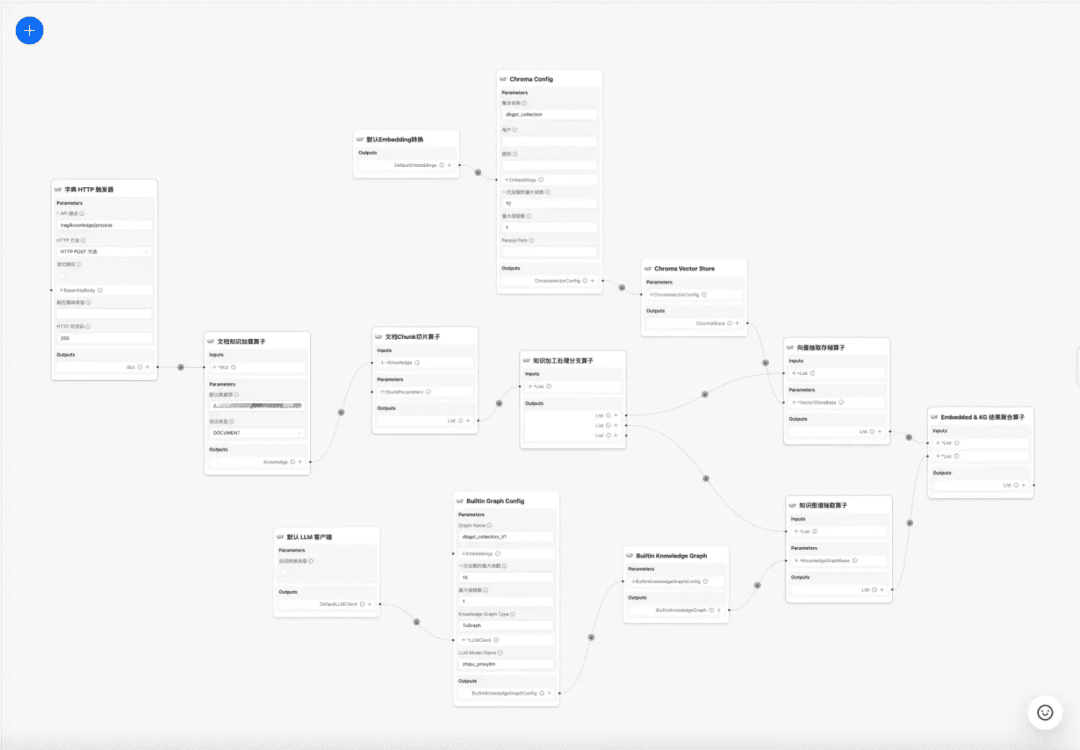
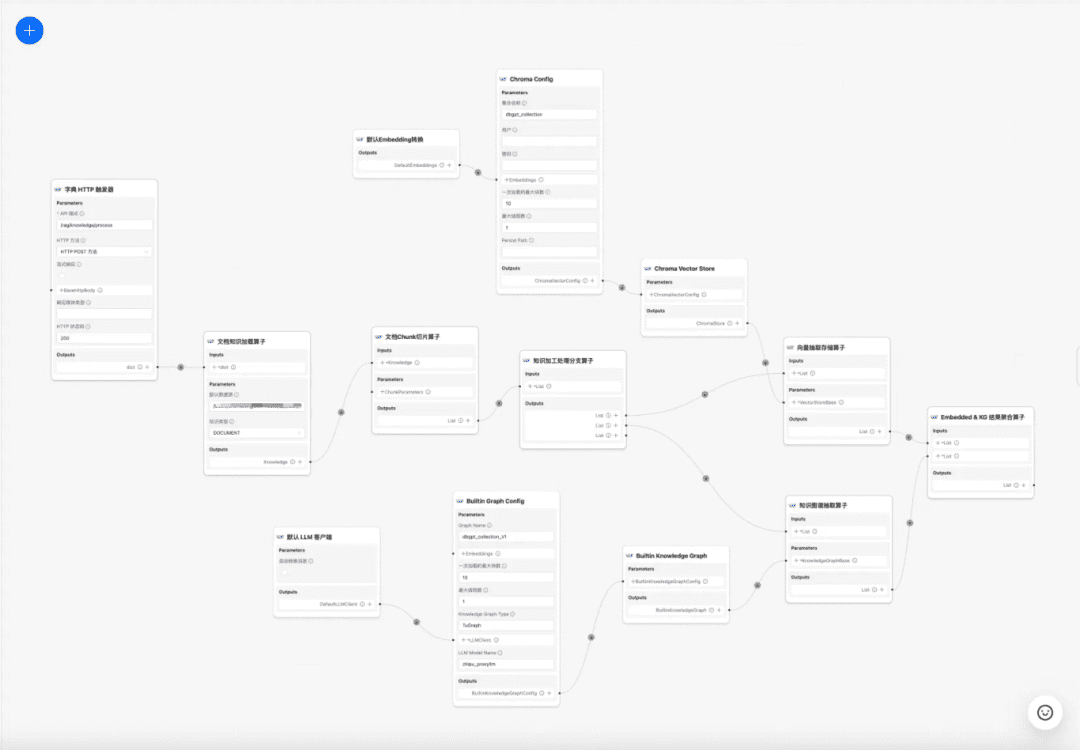
1.RAG-Schlüsselprozess Quellcode-Interpretation
ZentrumWissensverarbeitungim Gesang antwortenRAGEinige der wichtigsten Prozesse:
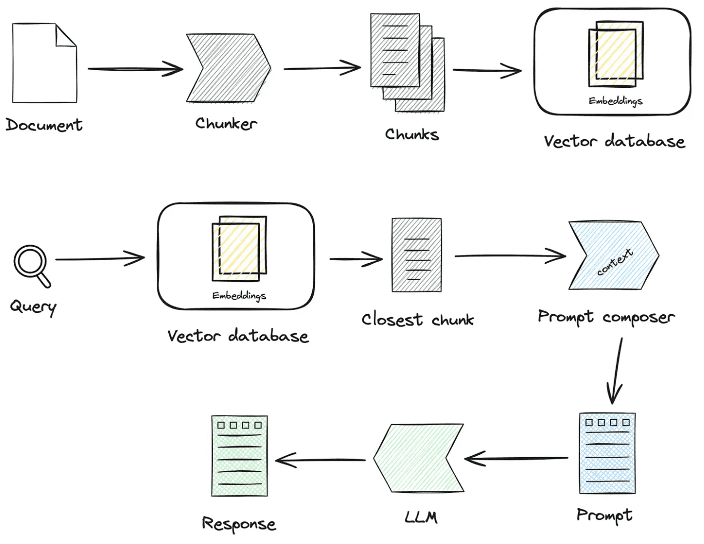
1. die Verarbeitung von Wissen
Laden von Wissen -> Wissenszerlegung -> Informationsextraktion -> Wissensverarbeitung (Einbettung/Graph/Schlüsselwörter) -> Wissensspeicherung
- Laden von Wissen
# 知识工厂进行实例化 KnowledgeFactory -> create() -> load() -> Document - knowledge - markdown - pdf - docx - txt - html - pptx - url - ...
Wie man expandiert:
from abc import ABC from typing import List, Any class Knowledge(ABC): def load(self) -> List[Document]: """Load knowledge from data loader.""" pass @classmethod def document_type(cls) -> Any: """Get document type.""" pass @classmethod def support_chunk_strategy(cls) -> List[ChunkStrategy]: """Return supported chunk strategy.""" return [ ChunkStrategy.CHUNK_BY_SIZE, ChunkStrategy.CHUNK_BY_PAGE, ChunkStrategy.CHUNK_BY_PARAGRAPH, ChunkStrategy.CHUNK_BY_MARKDOWN_HEADER, ChunkStrategy.CHUNK_BY_SEPARATOR, ] @classmethod def default_chunk_strategy(cls) -> ChunkStrategy: """ Return default chunk strategy. Returns: ChunkStrategy: default chunk strategy """ return ChunkStrategy.CHUNK_BY_SIZE
- Wissensschnipsel
ChunkManager: Leitet die geladenen Wissensdaten an den entsprechenden Chunk-Prozessor weiter, der sie entsprechend der vom Benutzer festgelegten Chunking-Politik und den Chunking-Parametern zuordnet.
class ChunkManager: """Manager for chunks.""" def __init__( self, knowledge: Knowledge, chunk_parameter: Optional[ChunkParameters] = None, extractor: Optional[Extractor] = None, ): """ Create a new ChunkManager with the given knowledge. Args: knowledge: (Knowledge) Knowledge datasource. chunk_parameter: (Optional[ChunkParameters]) Chunk parameter. extractor: (Optional[Extractor]) Extractor to use for summarization. """ self._knowledge = knowledge self._extractor = extractor self._chunk_parameters = chunk_parameter or ChunkParameters() self._chunk_strategy = ( chunk_parameter.chunk_strategy if chunk_parameter and chunk_parameter.chunk_strategy else self._knowledge.default_chunk_strategy().name ) self._text_splitter = self._chunk_parameters.text_splitter self._splitter_type = self._chunk_parameters.splitter_type
Erweiterung: Wenn Sie eine neue Slicing-Strategie in der Schnittstelle anpassen wollen
- Neue Slicing-Strategie
- Neue Splitter-Implementierungslogik
class ChunkStrategy(Enum):
"""Chunk Strategy Enum."""
CHUNK_BY_SIZE: _STRATEGY_ENUM_TYPE = (
RecursiveCharacterTextSplitter,
[
{
"param_name": "chunk_size",
"param_type": "int",
"default_value": 512,
"description": "The size of the data chunks used in processing.",
},
{
"param_name": "chunk_overlap",
"param_type": "int",
"default_value": 50,
"description": "The amount of overlap between adjacent data chunks.",
},
],
"chunk size",
"split document by chunk size",
)
CHUNK_BY_PAGE: _STRATEGY_ENUM_TYPE = (
PageTextSplitter,
[],
"page",
"split document by page",
)
CHUNK_BY_PARAGRAPH: _STRATEGY_ENUM_TYPE = (
ParagraphTextSplitter,
[
{
"param_name": "separator",
"param_type": "string",
"default_value": "\n",
"description": "paragraph separator",
}
],
"paragraph",
"split document by paragraph",
)
CHUNK_BY_SEPARATOR: _STRATEGY_ENUM_TYPE = (
SeparatorTextSplitter,
[
{
"param_name": "separator",
"param_type": "string",
"default_value": "\n",
"description": "chunk separator",
},
{
"param_name": "enable_merge",
"param_type": "boolean",
"default_value": False,
"description": (
"Whether to merge according to the chunk_size after "
"splitting by the separator."
),
},
],
"separator",
"split document by separator",
)
CHUNK_BY_MARKDOWN_HEADER: _STRATEGY_ENUM_TYPE = (
MarkdownHeaderTextSplitter,
[],
"markdown header",
"split document by markdown header",
)
- Extraktion von Wissen
- Vektorextraktion -> Einbettung, Implementierung
EmbeddingsStecker
@abstractmethod def embed_documents(self, texts: List[str]) -> List[List[float]]: """Embed search docs.""" @abstractmethod def embed_query(self, text: str) -> List[float]: """Embed query text.""" async def aembed_documents(self, texts: List[str]) -> List[List[float]]: """Asynchronous Embed search docs.""" return await asyncio.get_running_loop().run_in_executor( None, self.embed_documents, texts ) async def aembed_query(self, text: str) -> List[float]: """Asynchronous Embed query text.""" return await asyncio.get_running_loop().run_in_executor( None, self.embed_query, text )
# EMBEDDING_MODEL=proxy_openai
# proxy_openai_proxy_server_url=https://api.openai.com/v1
# proxy_openai_proxy_api_key={your-openai-sk}
# proxy_openai_proxy_backend=text-embedding-ada-002
## qwen embedding model, See dbgpt/model/parameter.py
# EMBEDDING_MODEL=proxy_tongyi
# proxy_tongyi_proxy_backend=text-embedding-v1
# proxy_tongyi_proxy_api_key={your-api-key}
## qianfan embedding model, See dbgpt/model/parameter.py
# EMBEDDING_MODEL=proxy_qianfan
# proxy_qianfan_proxy_backend=bge-large-zh
# proxy_qianfan_proxy_api_key={your-api-key}
# proxy_qianfan_proxy_api_secret={your-secret-key}
- Extraktion von Wissensgraphen -> Wissensgraphen
class TripletExtractor(LLMExtractor):
"""TripletExtractor class."""
def __init__(self, llm_client: LLMClient, model_name: str):
"""Initialize the TripletExtractor."""
super().__init__(llm_client, model_name, TRIPLET_EXTRACT_PT)
TRIPLET_EXTRACT_PT = (
"Some text is provided below. Given the text, "
"extract up to knowledge triplets as more as possible "
"in the form of (subject, predicate, object).\n"
"Avoid stopwords. The subject, predicate, object can not be none.\n"
"---------------------\n"
"Example:\n"
"Text: Alice is Bob's mother.\n"
"Triplets:\n(Alice, is mother of, Bob)\n"
"Text: Alice has 2 apples.\n"
"Triplets:\n(Alice, has 2, apple)\n"
"Text: Alice was given 1 apple by Bob.\n"
"Triplets:(Bob, gives 1 apple, Alice)\n"
"Text: Alice was pushed by Bob.\n"
"Triplets:(Bob, pushes, Alice)\n"
"Text: Bob's mother Alice has 2 apples.\n"
"Triplets:\n(Alice, is mother of, Bob)\n(Alice, has 2, apple)\n"
"Text: A Big monkey climbed up the tall fruit tree and picked 3 peaches.\n"
"Triplets:\n(monkey, climbed up, fruit tree)\n(monkey, picked 3, peach)\n"
"Text: Alice has 2 apples, she gives 1 to Bob.\n"
"Triplets:\n"
"(Alice, has 2, apple)\n(Alice, gives 1 apple, Bob)\n"
"Text: Philz is a coffee shop founded in Berkeley in 1982.\n"
"Triplets:\n"
"(Philz, is, coffee shop)\n(Philz, founded in, Berkeley)\n"
"(Philz, founded in, 1982)\n"
"---------------------\n"
"Text: {text}\n"
"Triplets:\n"
)
- Umgekehrte Index-Extraktion -> Segmentierung der Schlüsselwörter
- Sie können das es-Standardlexikon verwenden oder das Lexikon mit Hilfe des es-Plugin-Modus anpassen.
- Umgekehrte Index-Extraktion -> Segmentierung der Schlüsselwörter
- Speicherung von Wissen
Die gesamte Wissenspersistenz wird einheitlich erreichtIndexStoreBaseSchnittstelle, bietet derzeit drei Arten von Implementierungen: Vektordatenbanken, Graphdatenbanken, Volltextindizierung

- VectorStore, die Hauptlogik der Vektordatenbank befindet sich in load_document(), einschließlich der Erstellung des Indexschemas, des Batch-Schreibens von Vektordaten und so weiter.
# Base class hierarchy - VectorStoreBase - ChromaStore - MilvusStore - OceanbaseStore - ElasticsearchStore - PGVectorStore # Base class definition class VectorStoreBase(IndexStoreBase, ABC): """ Vector store base class. """ @abstractmethod def load_document(self, chunks: List[Chunk]) -> List[str]: """ Load document in index database. """ pass @abstractmethod async def aload_document(self, chunks: List[Chunk]) -> List[str]: """ Load document in index database asynchronously. """ pass @abstractmethod def similar_search_with_scores( self, text: str, topk: int, score_threshold: float, filters: Optional[MetadataFilters] = None, ) -> List[Chunk]: """ Perform a similar search with scores in the index database. """ pass def similar_search( self, text: str, topk: int, filters: Optional[MetadataFilters] = None, ) -> List[Chunk]: """ Perform a similar search in the index database. """ return self.similar_search_with_scores(text, topk, 1.0, filters)
- GraphStore , bietet der spezifische Graphenspeicher eine Implementierung des ternären Schreibens, was im Allgemeinen durch den Aufruf der Abfragesprache der spezifischen Graphendatenbank erfolgt. Zum Beispiel
TuGraphStoreEine spezifische Cypher-Anweisung wird auf der Grundlage der ternären Anweisung erstellt und ausgeführt.
- Die Graphenspeicherschnittstelle GraphStoreBase bietet eine einheitliche Abstraktion für die Graphenspeicherung und verfügt derzeit über integrierte
MemoryGraphStoreim Gesang antwortenTuGraphStoreImplementierung stellen wir Entwicklern auch eine Neo4j-Schnittstelle für den Zugriff zur Verfügung.
- Die Graphenspeicherschnittstelle GraphStoreBase bietet eine einheitliche Abstraktion für die Graphenspeicherung und verfügt derzeit über integrierte
# GraphStoreBase -> TuGraphStore -> Neo4jStore
def insert_triplet(self, subj: str, rel: str, obj: str) -> None:
"""Add triplet."""
# Create queries to merge nodes and relationship
subj_query = f"MERGE (n1:{self._node_label} {{id:'{subj}'}})"
obj_query = f"MERGE (n2:{self._node_label} {{id:'{obj}'}})"
rel_query = (
f"MERGE (n1:{self._node_label} {{id:'{subj}'}})"
f"-[r:{self._edge_label} {{id:'{rel}'}}]->"
f"(n2:{self._node_label} {{id:'{obj}'}})"
)
# Execute queries
self.conn.run(query=subj_query)
self.conn.run(query=obj_query)
self.conn.run(query=rel_query)
- FullTextStore: durch den Aufbau von es-Index, durch es eingebauten Worttrennungsalgorithmus für Worttrennung, und dann durch es zum Aufbau von Schlüsselwort->doc_id invertierten Index.
{
"analysis": {
"analyzer": {
"default": {
"type": "standard"
}
}
},
"similarity": {
"custom_bm25": {
"type": "BM25",
"k1": self._k1,
"b": self._b
}
}
}
self._es_mappings = {
"properties": {
"content": {
"type": "text",
"similarity": "custom_bm25"
},
"metadata": {
"type": "keyword"
}
}
}
# FullTextStoreBase
# ElasticDocumentStore
# OpenSearchStore
2. das Abrufen von Wissen
Frage -> Rewrite -> Ähnlichkeitssuche -> Rangfolge -> Kontextkandidaten
Als nächstes ist die Wissensabfrage, die aktuelle Community Retrieval-Logik ist vor allem in diese Schritte unterteilt, wenn Sie die Abfrage Rewriting-Parameter eingestellt, wird derzeit geben Sie eine Runde der Frage Rewriting durch das große Modell, und dann wird es auf die entsprechende Retriever nach Ihrem Wissen Verarbeitung Weg geroutet werden, wenn Sie durch die Vektoren verarbeitet werden, wird es durch die EmbeddingRetriever abgerufen werden, wenn Sie bauen Weg durch den Wissensgraphen konstruiert ist, wird es entsprechend dem Wissensgraphen abgerufen, wenn Sie das Rerank-Modell einrichten, wird es die Kandidatenwerte nach einem Grobscreening einem Feinscreening unterziehen, um die Kandidatenwerte relevanter für die Frage des Benutzers zu machen.
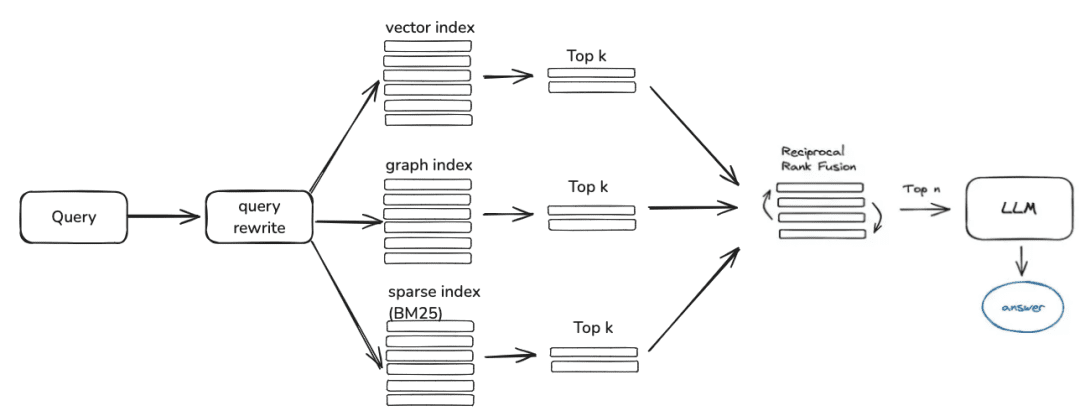
- EmbeddingRetriever
class EmbeddingRetriever(BaseRetriever): """Embedding retriever.""" def __init__( self, index_store: IndexStoreBase, top_k: int = 4, query_rewrite: Optional[QueryRewrite] = None, rerank: Optional[Ranker] = None, retrieve_strategy: Optional[RetrieverStrategy] = RetrieverStrategy.EMBEDDING, ): pass async def _aretrieve_with_score( self, query: str, score_threshold: float, filters: Optional[MetadataFilters] = None, ) -> List[Chunk]: """ Retrieve knowledge chunks with score. Args: query (str): Query text. score_threshold (float): Score threshold. filters: Metadata filters. Returns: List[Chunk]: List of chunks with score. """ queries = [query] new_queries = await self._query_rewrite.rewrite( origin_query=query, context=context, nums=1 ) queries.extend(new_queries) candidates_with_score = [ self._similarity_search_with_score( query, score_threshold, filters, root_tracer.get_current_span_id() ) for query in queries ] new_candidates_with_score = await self._rerank.arank( new_candidates_with_score, query ) return new_candidates_with_score
- index_store: spezifische Vektordatenbank
- top_k: Die Anzahl der zurückgegebenen Kandidaten-Chunks.
- query_rewrite: Funktion zum Umschreiben von Abfragen
- rerank: Funktion zur Neuordnung
- Abfrage:Originalabfrage
- score_threshold: Wert, standardmäßig werden Kontexte mit einem Ähnlichkeitswert kleiner als der Schwellenwert herausgefiltert
- Filter:
Optional[MetadataFilters]Der Metadaten-Informationsfilter kann hauptsächlich dazu verwendet werden, die Attribut-Informationen zu durchforsten und einige nicht übereinstimmende Kandidateninformationen auszusieben.
from enum import Enum from typing import Union, List from pydantic import BaseModel, Field class FilterCondition(str, Enum): """Vector Store Meta data filter conditions.""" AND = "and" OR = "or" class MetadataFilter(BaseModel): """Meta data filter.""" key: str = Field( ..., description="The key of metadata to filter." ) operator: FilterOperator = Field( default=FilterOperator.EQ, description="The operator of metadata filter." ) value: Union[str, int, float, List[str], List[int], List[float]] = Field( ..., description="The value of metadata to filter." )
- Grafik RAG
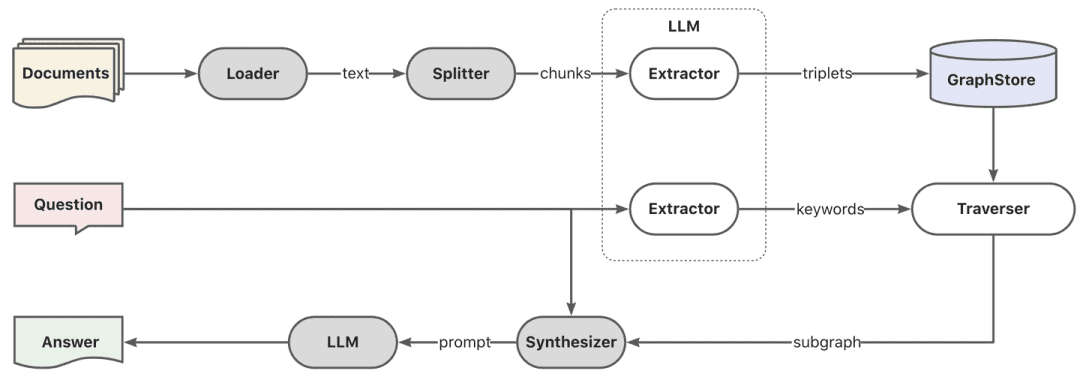
Erstens, Keyword-Extraktion wird durch das Modell durchgeführt, hier kann durch die traditionelle nlp Technik für Wort-Splitting, oder durch das große Modell für Wort-Splitting, und dann die Schlüsselwörter sind in Übereinstimmung mit den Synonymen zu tun, die Erweiterung, um die Keyword-Kandidaten-Liste zu finden, und es ist besser, die Explore-Methode aufrufen, um die lokalen Teilgraphen nach dem Schlüsselwort Kandidatenliste erinnern.
KEYWORD_EXTRACT_PT = (
"A question is provided below. Given the question, extract up to "
"keywords from the text. Focus on extracting the keywords that we can use "
"to best lookup answers to the question.\n"
"Generate as more as possible synonyms or alias of the keywords "
"considering possible cases of capitalization, pluralization, "
"common expressions, etc.\n"
"Avoid stopwords.\n"
"Provide the keywords and synonyms in comma-separated format."
"Formatted keywords and synonyms text should be separated by a semicolon.\n"
"---------------------\n"
"Example:\n"
"Text: Alice is Bob's mother.\n"
"Keywords:\nAlice,mother,Bob;mummy\n"
"Text: Philz is a coffee shop founded in Berkeley in 1982.\n"
"Keywords:\nPhilz,coffee shop,Berkeley,1982;coffee bar,coffee house\n"
"---------------------\n"
"Text: {text}\n"
"Keywords:\n"
)
def explore(
self,
subs: List[str],
direct: Direction = Direction.BOTH,
depth: Optional[int] = None,
fan: Optional[int] = None,
limit: Optional[int] = None,
) -> Graph:
"""Explore on graph."""
DBSchemaRetrieverDies ist teilweise eine schemaverknüpfende Suche nach ChatData-SzenarienHauptsächlich durch Schema-Verknüpfung durch zweistufige Ähnlichkeitssuche, zuerst die relevanteste Tabelle, dann die relevanteste Feldinformation.
Vorteile: Diese zweistufige Suche soll auch das Feedback der Community zur Erfahrung mit großen, breiten Tischen berücksichtigen.
def _similarity_search(self, query, filters: Optional[MetadataFilters] = None) -> List[Chunk]:
"""Similar search."""
# Perform similarity search with scores
table_chunks = self._table_vector_store_connector.similar_search_with_scores(
query, self._top_k, 0, filters
)
# Filter out chunks with 'separated' metadata
not_sep_chunks = [
chunk for chunk in table_chunks if not chunk.metadata.get("separated")
]
separated_chunks = [
chunk for chunk in table_chunks if chunk.metadata.get("separated")
]
# If no separated chunks, return the non-separated chunks
if not separated_chunks:
return not_sep_chunks
# Create tasks list for retrieving fields from separated chunks
tasks = [
lambda c=chunk: self._retrieve_field(c, query) for chunk in separated_chunks
]
# Run tasks concurrently with a concurrency limit of 3
separated_result = run_tasks(tasks, concurrency_limit=3)
# Combine and return results
return not_sep_chunks + separated_result
- table_vector_store_connector: ist für das Abrufen der wichtigsten Tabelle zuständig.
- field_vector_store_connector: ist für das Abrufen der wichtigsten Felder zuständig.
2. wissensverarbeitende und wissensabrufende Optimierungsideen
Derzeit gibt es bei den RAG-Smart-Quiz-Anwendungen mehrere Schwachstellen:
- Nachdem immer mehr Dokumente in der Wissensdatenbank vorhanden sind, ist die Suche verrauscht und die Auffindungsgenauigkeit ist nicht hoch.
- Unvollständige Rückrufe und Unvollständigkeit
- Rückrufe und die Absicht der Nutzer, eine Frage zu stellen, sind wenig relevant
- Wenn man nur statische Daten beantworten kann und nicht in der Lage ist, dynamisch auf Wissen zuzugreifen, führt dies zu einer langweiligen und stumpfen Antwortanwendung.
1. Optimierung der Wissensverarbeitung
Die Verarbeitung von unstrukturierten/halbstrukturierten/strukturierten Daten ist bereit, die Obergrenze der RAG-Anwendung zu bestimmen, so dass zunächst eine Menge feinkörniger ETL-Arbeit in der Wissensverarbeitung, der Indizierungsphase und der Hauptoptimierung der Richtung der Idee erforderlich ist:
- Unstrukturiert -> Strukturiert: Organisation von Wissensinformationen auf strukturierte Weise.
- Extrahieren Sie umfangreichere und vielfältigere semantische Informationen.
1.1 Wissen laden
Zweck: Genaues Parsing von Dokumenten ist erforderlich, um verschiedene Datentypen auf vielfältigere Weise zu identifizieren.
Optimierungsempfehlungen:
- Es wird empfohlen, docx, txt oder anderen Text vor der Verarbeitung für pdf oder markdown-Format, so dass Sie einige Erkennungs-Tools verwenden können, um besser den Inhalt des Textes zu extrahieren.
- Extrahiert Tabelleninformationen aus Text.
- Bewahren Sie Markdown- und PDF-Titelhierarchieinformationen für den nächsten hierarchischen Beziehungsbaum und andere Indizierungsmethoden, die Sie vorbereiten müssen.
- Behalten Sie Bildverknüpfungen, Formeln und andere Informationen bei, die ebenfalls einheitlich im Markdown-Format verarbeitet werden.
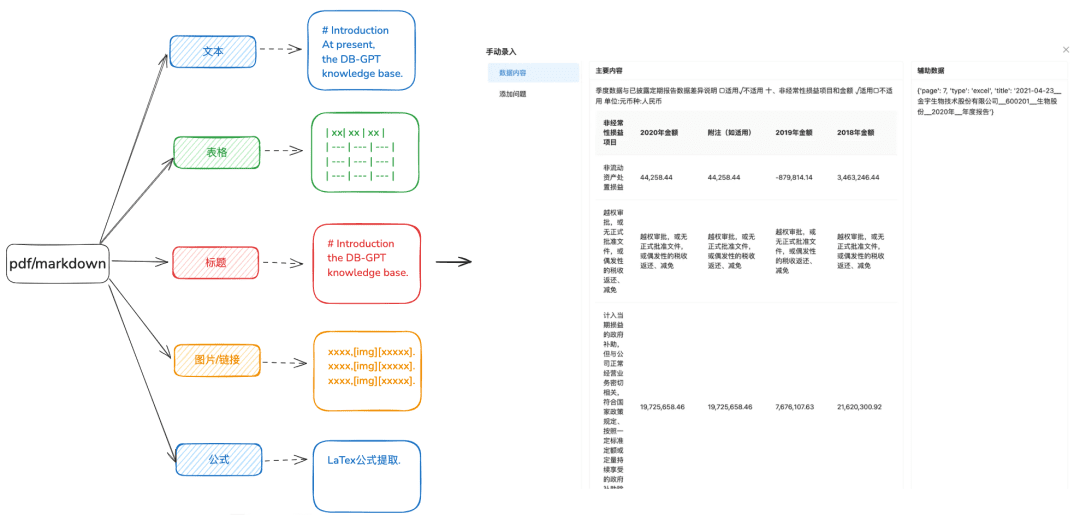
1.2 Chunk möglichst unversehrt in Scheiben schneiden
Zweck: Wahrung der kontextuellen Integrität und Relevanz, die in direktem Zusammenhang mit der Antwortgenauigkeit stehen.
Innerhalb der kontextuellen Grenzen des größeren Modells stellt das Chunking sicher, dass die Texteingabe in LLMs deren Tokengrenzen nicht überschreitet.
Optimierungsempfehlungen:
- Bilder + Tabellen werden als separate Chunks extrahiert, wobei Tabellen- und Bildunterschriften in den Metadaten verbleiben
- Der Inhalt des Dokuments wird so weit wie möglich gemäß der Kopfzeilenhierarchie oder dem Markdown-Header aufgeteilt, wobei die Integrität des Chunks so weit wie möglich erhalten bleibt.
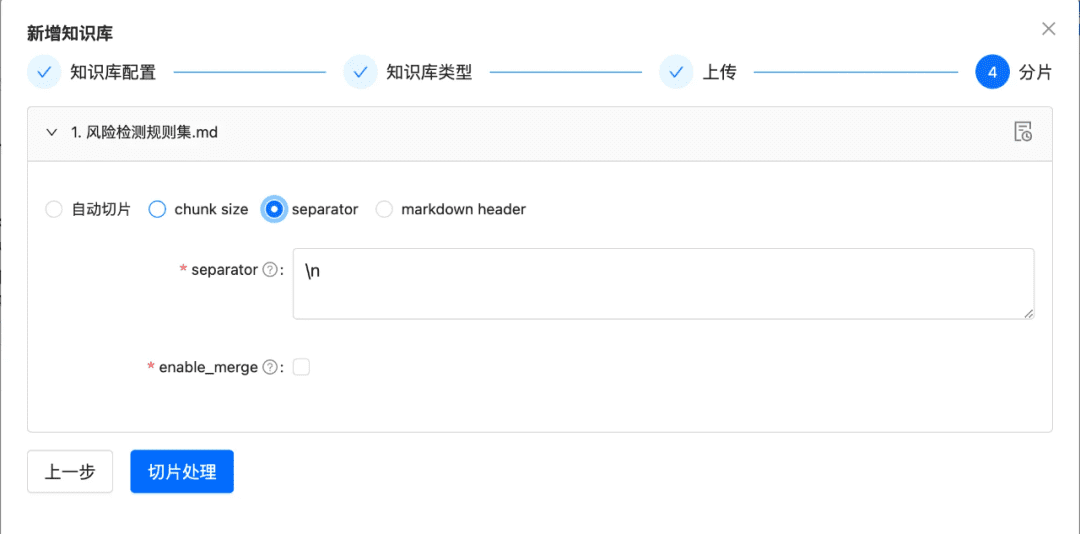
- Wenn ein benutzerdefiniertes Trennzeichen vorhanden ist, können Sie die Daten anhand des benutzerdefinierten Trennzeichens zerlegen.
1.3 Diversifizierte Informationsextraktion
Zusätzlich zur Einbettung der Vektorextraktion von Dokumenten können andere diversifizierte Informationsextraktionen die Daten von Dokumenten verbessern und den RAG-Recall-Effekt erheblich steigern.
- Wissenslandkarte
- Vorteile: 1. die mangelnde Vollständigkeit der NativeRAG, gibt es immer noch das Problem der Illusion, und die Genauigkeit des Wissens, einschließlich der Vollständigkeit des Wissens Grenzen, die Klarheit des Wissens Struktur und Semantik, ist eine semantische Ergänzung zu der Fähigkeit der Ähnlichkeit Retrieval.
- Szenarien: Für strenge berufliche Bereiche (Gesundheitswesen, O&M, usw.), in denen die Aufbereitung von Wissen eingeschränkt werden muss und in denen hierarchische Beziehungen zwischen Wissen klar festgelegt werden können.
- Wie man das erreicht:
1. auf das große Modell angewiesen, um ternäre Beziehungen (Entität, Beziehung, Entität) zu extrahieren.
2. sich auf die Aufbereitung, Bereinigung und Extraktion von strukturiertem Wissen von hoher Qualität durch manuelle oder benutzerdefinierte SOPs zu verlassen, um den Wissensgraphen zu erstellen.
- Doc Tree
- Anwendbare Szenarien: löst das Problem der unzureichenden kontextuellen Integrität, bietet aber auch Übereinstimmungen allein auf der Grundlage von Semantik und Schlüsselwörtern und kann Rauschen reduzieren
- Vorgehensweise: Aufbau eines Baumknotens aus Chunks auf der Titelebene, um eine multinomiale Baumstruktur zu bilden, bei der jeder Knoten der Ebene nur den Titel des Dokuments speichern muss und die Blattknoten den spezifischen Textinhalt speichern. Wenn eine Benutzerfrage auf einen relevanten nicht-blättrigen Titelknoten trifft, können auf diese Weise mit Hilfe des Baum-Traversal-Algorithmus die relevanten Daten der untergeordneten Knoten abgerufen werden. Auf diese Weise gibt es kein Problem mit der Integrität von Chunks.
Diesen Teil des Features werden wir Anfang nächsten Jahres auch in die Gemeinschaft einbringen.
- Die Extraktion von QA-Paaren erfordert eine Front-End-Extraktion von QA-Paarinformationen durch vordefinierte oder Modellextraktionsmethoden
- Anwendbare Szenarien:
- Die Fähigkeit, die Frage in den Abruf und direkten Rückruf zu treffen, direkt abrufen die Antwort der Benutzer will, gilt für einige FAQ-Szenarien, Recall-Integrität ist nicht genug Szenarien.
- Wie man das erreicht:
- Vordefiniert: Fügen Sie im Voraus einige Fragen für jeden Chunk hinzu.
- Modellextraktion: In einem gegebenen Kontext soll das Modell die Extraktion von QA-Paaren durchführen.
- Extraktion von Metadaten
- So erreichen Sie es: Extrahieren Sie entsprechend den Merkmalen ihrer eigenen Geschäftsdaten die Merkmale der aufzubewahrenden Daten, wie Tags, Kategorien, Zeit, Version und andere Metadatenattribute.
- Anwendbare Szenarien: Der Abruf kann auf der Grundlage von Metadatenattributen vorgefiltert werden, um den größten Teil des Rauschens herauszufiltern.
- Zusammenfassen und extrahieren
- Anwendbare Szenarien: Auflösung
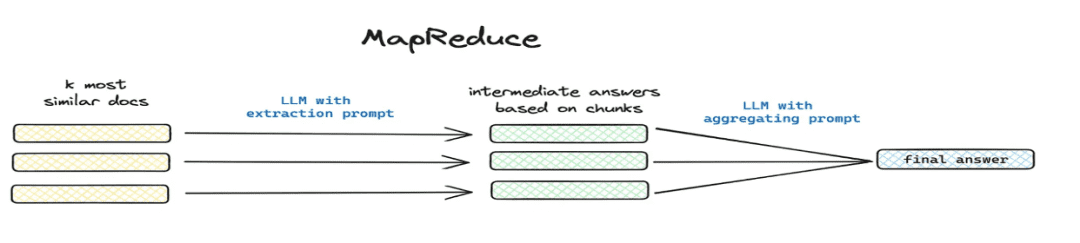
这篇文章讲了个啥(math.) Gattung总结一下und andere globale Problemszenarien. - Umsetzung: segmentierte Extraktion über Mapreduce usw., Extraktion von zusammenfassenden Informationen für jeden Chunk über ein Modell.
- Anwendbare Szenarien: Auflösung
1.4 Arbeitsablauf der Wissensverarbeitung
zum gegenwärtigen Zeitpunkt DB-GPT Die Wissensdatenbank bietet Wissensverarbeitungsfunktionen wie Upload von Dokumenten -> Parsing -> Slicing -> Embedding -> Extraktion von Wissensgraphen-Triaden -> Speicherung in einer Vektordatenbank -> Speicherung in einer Graphen-Datenbank usw., ist aber nicht in der Lage, komplexe und personalisierte Informationen aus Dokumenten zu extrahieren. Daher hoffen wir, durch den Aufbau einer Workflow-Vorlage für die Wissensverarbeitung den komplexen, visuellen, benutzerdefinierten Prozess der Wissensextraktion, -umwandlung und -verarbeitung zu vervollständigen. Daher hoffen wir, durch den Aufbau einer Workflow-Vorlage zur Wissensverarbeitung den komplexen, visuellen, benutzerdefinierbaren Prozess der Wissensextraktion, -umwandlung und -verarbeitung zu vervollständigen.
Workflow der Wissensverarbeitung:
https://www.yuque.com/eosphoros/dbgpt-docs/vg2gsfyf3x9fuglf
2. RAG Prozessoptimierung RAG Prozessoptimierung sind wir in das statische Dokument RAG und dynamische Datenerfassung RAG unterteilt, die meisten der aktuellen RAG beteiligt deckt nur das unstrukturierte Dokument statische Vermögenswerte, aber das eigentliche Geschäft von vielen Szenarien der Q & A ist durch das Werkzeug, um dynamische Daten + statische Wissensdaten zusammen zu erhalten, um das Szenario zu beantworten, nicht nur brauchen, um das statische Wissen abzurufen, sondern müssen auch RAG sein nicht nur das statische Wissen abrufen, sondern auch RAG benötigen, um die Informationen von Werkzeugen innerhalb der Werkzeug-Asset-Bibliothek abzurufen und den Erwerb von dynamischen Daten durchzuführen.
2.1 Statisches Wissen RAG-Optimierung
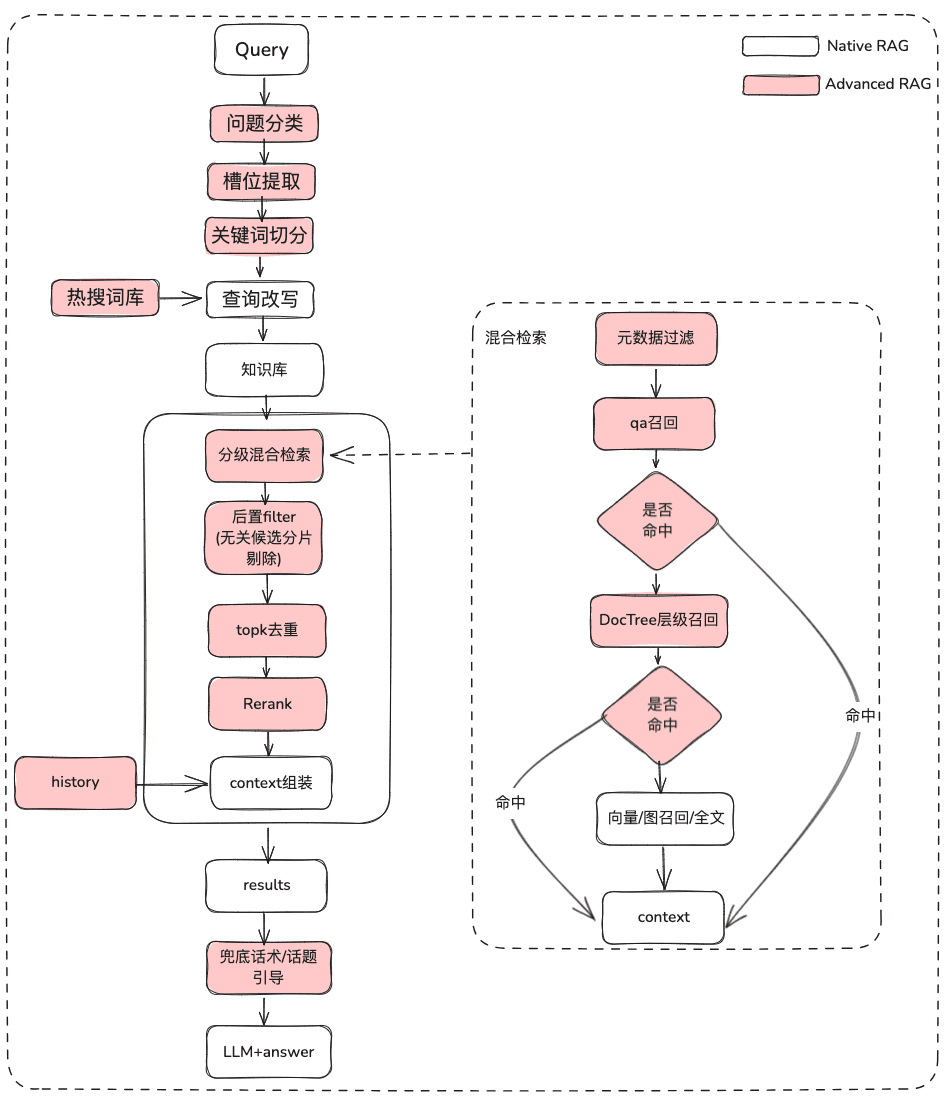
(1) Behandlung des ursprünglichen Problems
Zweck: Klärung der Benutzersemantik und Optimierung der ursprünglichen Frage des Benutzers von einer unscharfen, nicht beabsichtigten Abfrage zu einer abrufbaren Abfrage, die mehr Bedeutung hat.
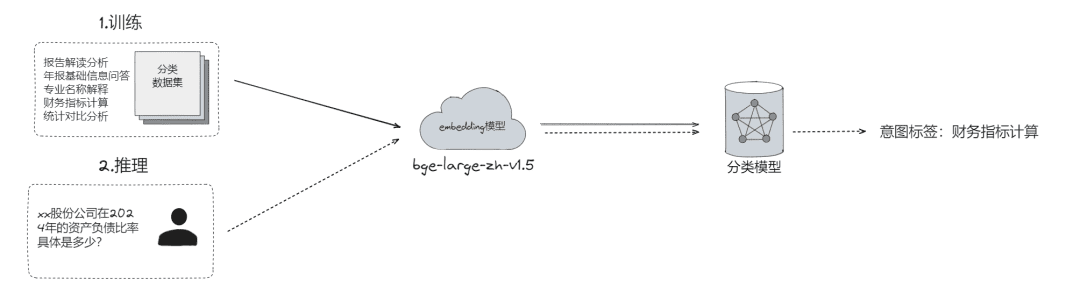
- Rohe Problemklassifizierung, mit der Probleme in folgende Kategorien eingeteilt werden können
- LLM-Klassifizierung (
LLMExtractor) - Aufbau von Einbettung + logistischer Regression zur Implementierung eines Zweiturm-Modells, text2nlu DB-GPT-Hub/src/dbgpt-hub-nlu/README.zh.md bei main - eosphoros-ai/DB-GPT-Hub
- LLM-Klassifizierung (
- Tipp: Benötigen Sie hohe Qualität Embedding Modell, empfehlen bge-v1.5-groß
- Fragen Sie den Benutzer zurück, und wenn die Semantik nicht klar ist, werfen Sie die Frage an den Benutzer zurück, um sie zu klären, und zwar in mehreren Runden der Interaktion
- Schlägt dem Benutzer auf der Grundlage der semantischen Relevanz und unter Verwendung eines durchsuchbaren Thesaurus eine Auswahlliste von Fragen vor.
- Slot-Extraktion, die darauf abzielt, wichtige Slot-Informationen in der Frage des Benutzers zu erhalten, wie z. B. Absicht, geschäftliche Attribute usw.
- LLM-Extraktion (
LLMExtractor)
- LLM-Extraktion (
- Die Frage umschreiben
- Neufassung des Hot Search Thesaurus
- vielschichtige Interaktion
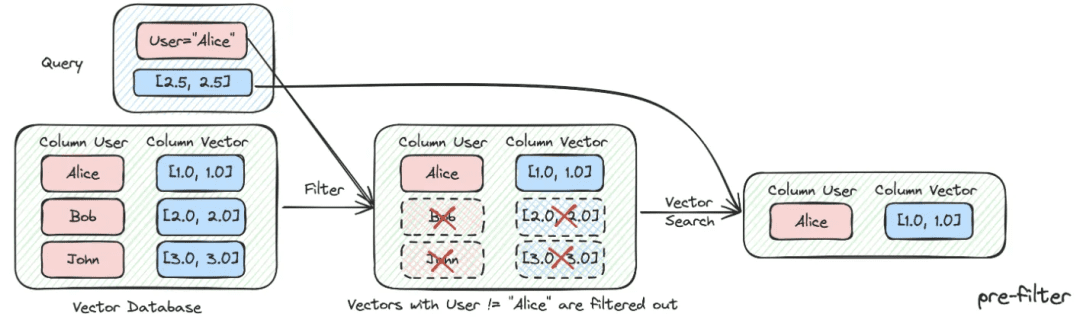
(2) Filterung von Metadaten
Wenn wir den Index in viele Chunks aufteilen und diese im selben Wissensraum gespeichert werden, wird die Abrufeffizienz zu einem Problem. Wenn Benutzer beispielsweise nach Informationen über "Zhejiang I Wu Technology Company" suchen, möchten sie keine Informationen über andere Unternehmen abrufen. Wenn Sie also zuerst nach dem Metadatenattribut "Firmenname" filtern können, wird dies die Effizienz und Relevanz erheblich verbessern.
async def aretrieve( self, query: str, filters: Optional[MetadataFilters] = None ) -> List[Chunk]: """ Retrieve knowledge chunks. Args: query (str): async query text. filters (Optional[MetadataFilters]): metadata filters. Returns: List[Chunk]: list of chunks """ return await self._aretrieve(query, filters)
(3) Multistrategie-Hybrid-Rückruf
- Festlegung von Prioritäten für verschiedene Abrufer je nach Abrufpriorität und Rückgabe von Inhalten, sobald diese abgerufen wurden
- Definieren Sie verschiedene Abrufe wie qa_retriever, doc_tree_retriever, die in die Warteschlange geschrieben werden sollen, und erreichen Sie einen vorrangigen Abruf durch die First-in-first-out-Eigenschaft der Warteschlange.
class RetrieverChain(BaseRetriever): """Retriever chain class.""" def __init__( self, retrievers: Optional[List[BaseRetriever]] = None, executor: Optional[Executor] = None, ): """Create retriever chain instance.""" self._retrievers = retrievers or [] self._executor = executor or ThreadPoolExecutor() async def retrieve(self, query: str, score_threshold: float, filters: Optional[dict] = None): """Perform retrieval with the given query, score threshold, and filters.""" for retriever in self._retrievers: candidates_with_scores = await retriever.aretrieve_with_scores( query=query, score_threshold=score_threshold, filters=filters ) if candidates_with_scores: return candidates_with_scores
- Indizierung von Mehrfachwissen/paralleler räumlicher Abruf
- Ermittlung von Kandidatenlisten durch parallelen Abruf durch verschiedene Indizierungsformen des Wissens, um die Vollständigkeit des Abrufs zu gewährleisten
(4) Nachfilterung
Wie filtern Sie nach dem Grobscreening der Kandidatenliste das Rauschen durch das Feinscreening?
- Aussortieren irrelevanter Kandidaten-Slice
- Ablehnung der Rechtzeitigkeit
- Business-Attribute genügen nicht den Anforderungen des Culling
- topk-Deduplizierung
- Neuordnung Es reicht nicht aus, sich auf den Abruf des Grobscreenings zu verlassen. Zu diesem Zeitpunkt benötigen wir einige Strategien, um die abgerufenen Ergebnisse neu zu ordnen, z. B. um Faktoren wie Kombinationsrelevanz, Übereinstimmung usw. neu zu justieren, um eine Ordnung zu erhalten, die besser mit unseren Geschäftsszenarien übereinstimmt. Denn nach diesem Schritt werden wir die Ergebnisse zur endgültigen Verarbeitung an LLM senden, so dass die Ergebnisse dieses Teils sehr wichtig sind.
- Feinscreening unter Verwendung relevanter Neuordnungsmodelle, entweder Open-Source-Modelle oder Modelle mit unternehmenssemantischer Feinabstimmung.
## Rerank model # RERANK_MODEL = bce-reranker-base #### If you do not set RERANK_MODEL_PATH, DB-GPT will read the model path from EMBEDDING_MODEL_CONFIG based on the RERANK_MODEL. # RERANK_MODEL_PATH = /Users/chenketing/Desktop/project/DB-GPT-NEW/DB-GPT/models/bce-reranker-base_v1 #### The number of rerank results to return # RERANK_TOP_K = 5
- Business RRF-gewichtetes Composite Score Culling auf der Basis verschiedener indizierter Rückrufe
score = 0.0 for q in queries: if d in result(q): score += 1.0 / (k + rank(result(q), d)) return score # where: # k is a ranking constant # q is a query in the set of queries # d is a document in the result set of q # result(q) is the result set of q # rank(result(q), d) is d's rank within the result(q) starting from 1
(5) Display-Optimierung + Touting / Themen-Leads
- Ausgabe des Modells mit Markdown-Formatierung
基于以下给出的已知信息,遵守规范约束,专业、简要回答用户的问题。 规范约束: 1. 如果已知信息包含的图片、链接、表格、代码块等特殊 markdown 标签格式的信息,确保在答案中包含原文这些图片、链接、表格和代码标签,不要丢弃不要修改,例如: - 图片格式:`` - 链接格式:`[xxx](xxx)` - 表格格式:`|xxx|xxx|xxx|` - 代码格式:```xxx```。 2. 如果无法从提供的内容中获取答案,请说:“知识库中提供的内容不足以回答此问题”,禁止胡乱编造。 3. 回答的时候最好按照 1.2.3. 点进行总结,并以 Markdown 格式显示。
2.2 Dynamische Wissens-RAG-Optimierung
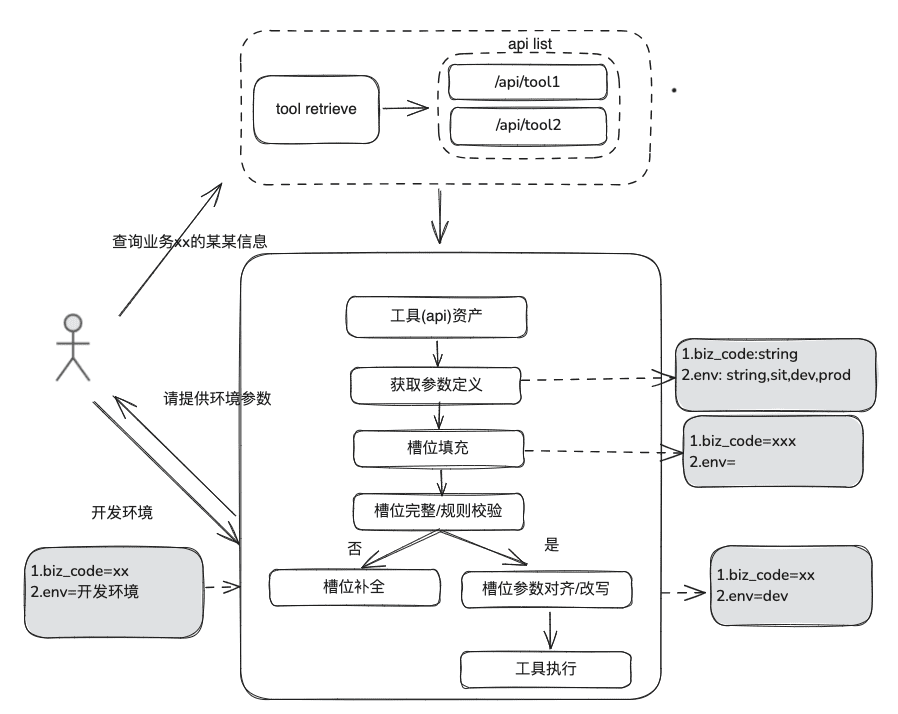
Dokumentation Wissen ist relativ statisch, kann nicht beantworten, personalisierte und dynamische Informationen, müssen sich auf einige Drittanbieter-Plattform-Tools zu beantworten, auf der Grundlage dieser Situation, wir brauchen einige dynamische RAG-Methoden, durch das Tool Asset-Definition -> Tool-Auswahl -> Tool-Validierung -> Tool-Ausführung, um dynamische Daten zu erhalten.
(1) Werkzeug-Bestandsbibliothek
Aufbau einer Tool-Asset-Bibliothek für den Unternehmensbereich zur Integration von Tool-APIs und Tool-Skripten, die auf verschiedenen Plattformen verstreut sind, und somit Bereitstellung von End-to-End-Nutzungsfunktionen für Intelligenz. Zusätzlich zur statischen Wissensdatenbank können wir beispielsweise Werkzeuge verarbeiten, indem wir Werkzeugbibliotheken importieren.

(2) Werkzeugrückruf
Der Werkzeugabruf folgt der Idee des RAG-Abrufs für statisches Wissen, und dann wird der gesamte Lebenszyklus der Werkzeugausführung verwendet, um die Ergebnisse der Werkzeugausführung zu erhalten.
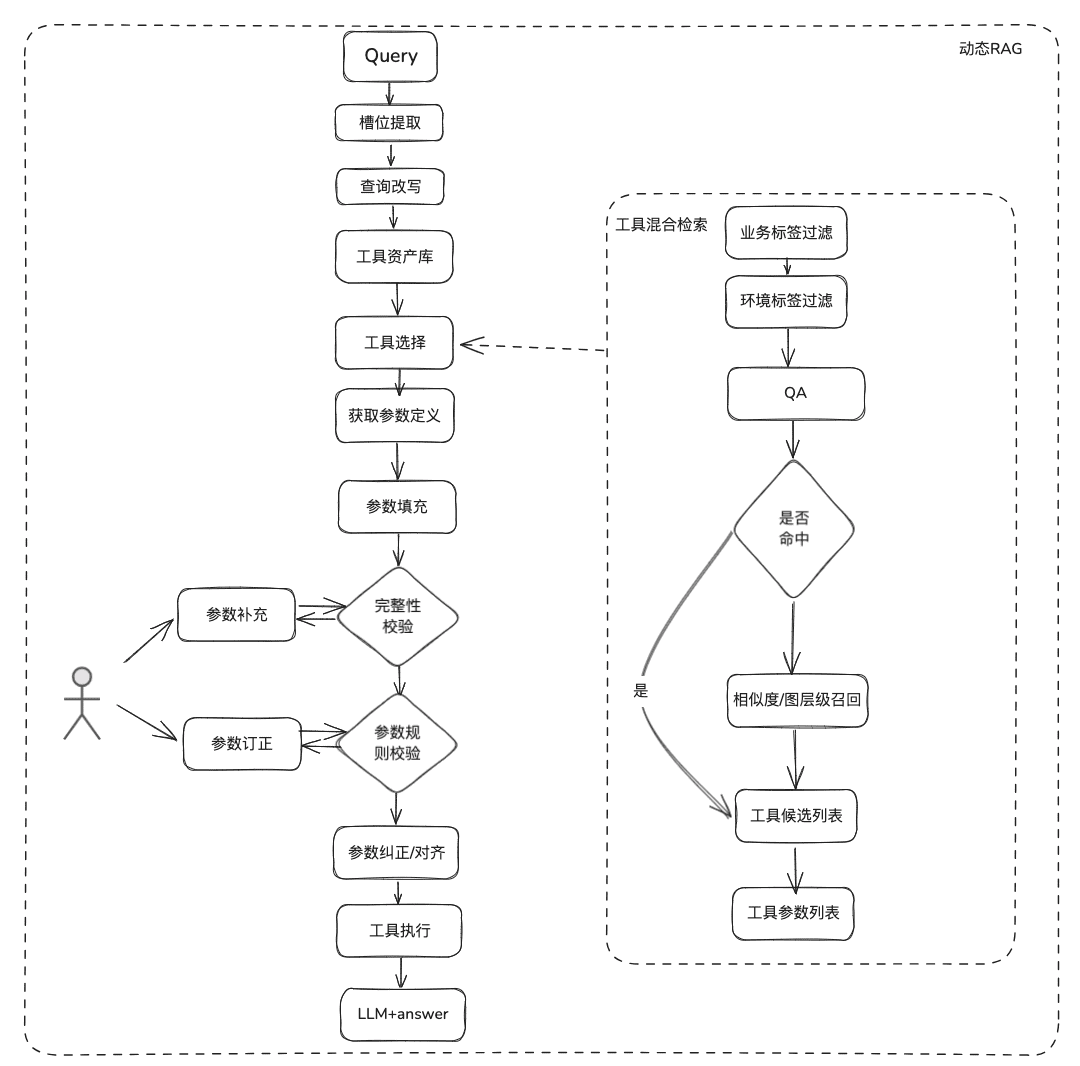
- Slot-Extraktion: Holen Sie sich LLM durch traditionelle nlp, um das Problem des Benutzers zu analysieren, einschließlich allgemeiner Geschäftstypen, Umgebungsmarker, Domänenmodellparameter usw.
- Werkzeugauswahl: Abruf nach dem Vorbild der statischen RAG mit zwei Hauptebenen, Abruf des Werkzeugnamens und Abruf der Werkzeugparameter.
- Das Tool Parameter Recall, das von der Idee her dem TableRAG ähnlich ist, ruft zuerst den Tabellennamen und dann den Feldnamen ab.
- Parameterfüllung: Die aus den Schlitzen extrahierten Parameter müssen mit den Werkzeugparameterdefinitionen der Rückrufe übereinstimmen.
- Sie können den Code ausfüllen, oder Sie können ihn vom Modell ausfüllen lassen.
- Optimierungsideen: Da die Parameternamen der gleichen Parameter der verschiedenen Plattform-Tools nicht einheitlich sind und es nicht bequem ist, sich an die Verwaltung zu wenden, wird vorgeschlagen, dass zunächst eine Runde der Domänenmodelldatenerweiterung durchgeführt werden kann, und nach Erhalt des gesamten Domänenmodells werden die erforderlichen Parameter vorhanden sein.
- Parameterkalibrierung
- Integritätsprüfung: führt eine Integritätsprüfung für die Anzahl der Parameter durch
- Parameter-Regelprüfung: Führt eine Regelprüfung für den Typ des Parameternamens, den Parameterwert, die Aufzählung usw. durch.
- Parameterkorrektur/-anpassung, dieser Teil dient hauptsächlich dazu, die Anzahl der Interaktionen mit dem Benutzer zu reduzieren, automatischer Abschluss der Benutzerparameter-Fehlerkorrektur, einschließlich Fallregeln, Aufzählungsregeln, usw. z.B.
2.3 RAG-Überprüfung
Bei der Bewertung des Smart Q&A-Prozesses müssen sowohl die Genauigkeit der Abrufrelevanz als auch die Relevanz des Modells Q&A separat bewertet und dann zusammen betrachtet werden, um festzustellen, wo der RAG-Prozess noch verbessert werden muss.
Bewertung der Indikatoren:
EvaluationMetric ├── LLMEvaluationMetric │ ├── AnswerRelevancyMetric ├── RetrieverEvaluationMetric │ ├── RetrieverSimilarityMetric │ ├── RetrieverMRRMetric │ └── RetrieverHitRateMetric
RAGRetrieverEvaluationMetric:RetrieverHitRateMetric:: Die Trefferquote misst die RAGretrieverDer Anteil der Rückrufe, die in den Top-k-Dokumenten der abgerufenen Ergebnisse erscheinen.RetrieverMRRMetric:Mean Reciprocal RankDie Genauigkeit jeder Anfrage wird durch die Analyse der Rangfolge der relevantesten Dokumente in den Suchergebnissen berechnet. Genauer gesagt ist sie der Durchschnitt des inversen Rangs der relevanten Dokumente für alle Abfragen. Wenn zum Beispiel das relevanteste Dokument an erster Stelle steht, ist sein inverser Rang 1; wenn es an zweiter Stelle steht, ist er 1/2 usw.RetrieverSimilarityMetricÄhnlichkeitsmetriken werden berechnet, um die Ähnlichkeit zwischen dem abgerufenen Inhalt und dem vorhergesagten Inhalt zu ermitteln.
模型生成Antwort-Indikator.
AnswerRelevancyMetric:: Relevanzmetrik für intelligente Antworten, die angibt, wie gut die Antwort des intelligenten Körpers mit der Frage des Nutzers übereinstimmt. Eine Antwort mit hoher Relevanz setzt nicht nur voraus, dass das Modell die Frage des Nutzers versteht, sondern auch, dass es eine Antwort generiert, die in engem Zusammenhang mit der Frage steht. Dies wirkt sich direkt auf die Benutzerzufriedenheit und die Nützlichkeit des Modells aus.
3.RAG Landing Case Sharing
1. die RAG im Bereich der Dateninfrastruktur
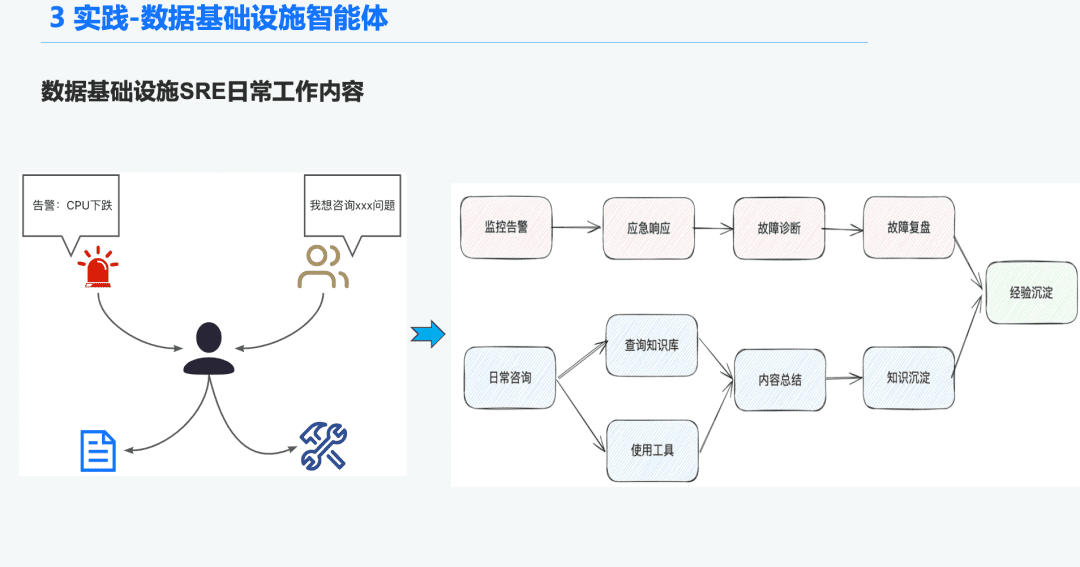
1.1 O&M Intelligence Hintergrund
Im Bereich der Dateninfrastruktur gibt es viele Ops SREs, die täglich eine große Anzahl von Warnmeldungen erhalten, so dass viel Zeit damit verbracht wird, auf Notfälle zu reagieren, was wiederum zur Fehlerbehebung und zur Überprüfung der Fehlerbehebung führt, was wiederum zu Erfahrung führt. Ein weiterer Teil der Zeit wird mit der Beantwortung von Benutzeranfragen verbracht, bei denen sie Fragen mit ihrem Wissen und ihrer Erfahrung bei der Verwendung der Tools beantworten müssen.
Daher hoffen wir, diese Probleme der Alarmdiagnose und der Beantwortung von Fragen zu lösen, indem wir eine allgemeine Intelligenz für die Dateninfrastruktur schaffen.
1.2 Strenge und professionelle RAG
Die traditionelle RAG + Agent Technologie kann allgemeine, weniger deterministische, einstufige Aufgabenszenarien lösen. Bei professionellen Szenarien im Bereich der Dateninfrastruktur muss jedoch der gesamte Retrievalprozess deterministisch, professionell und realistisch sein und erfordert schrittweises Denken.
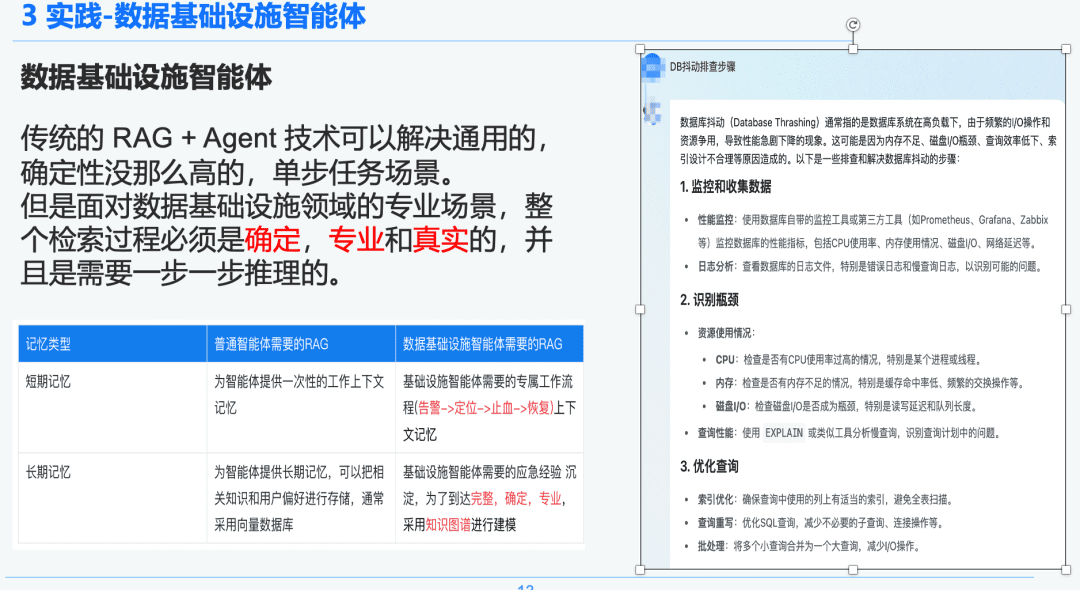
Auf der rechten Seite finden Sie eine allgemeine Zusammenfassung über NativeRAG, die für einen C-Suite-Benutzer, der nicht so viel Fachwissen hat, eine nützliche Information sein kann, und für einen Fachmann wird dieser Teil der Antwort nicht viel Sinn machen.
Wir vergleichen daher den Unterschied zwischen den allgemeinen Intelligenzen und den Intelligenzen der Dateninfrastruktur über die RAG:
- Allzweck-Intelligenzen: Herkömmliche RAGs erfordern nicht so viel intellektuelle Strenge und Fachwissen und eignen sich für einige Geschäftsszenarien, wie z. B. Kundenservice, Tourismus und Plattform-Q&A-Bots.
- Data Infrastructure Intelligence Body: Der RAG-Prozess ist streng und professionell und erfordert exklusive RAG-Workflows mit Kontexten, die (Alarmierung -> Lokalisierung -> Stoppen der Blutung -> Wiederherstellung) und eine strukturierte Extraktion von Fragen und Antworten sowie von Notfallerfahrungen, die von Experten ausgearbeitet wurden, um hierarchische Beziehungen herzustellen. Deshalb wählen wir Knowledge Graph als Datenträger.
1.3 Wissensverarbeitung
Aufgrund des Determinismus und der Spezifität der Dateninfrastruktur haben wir uns entschieden, sie als Wissensträger für die Diagnose von Notfallreaktionserfahrungen durch die Kombination von Wissensgraphen zu verwenden. In Kombination mit dem Notfallüberprüfungsprozess haben wir einen DB-Notfall-Wissensgraphen erstellt. Wir haben DB-Jitter als Beispiel genommen, mehrere Ereignisse, die DB-Jitter betreffen, einschließlich langsamer SQL-Probleme und Kapazitätsprobleme, und wir haben Beziehungen zwischen den einzelnen Notfallereignissen hergestellt.
Schließlich haben wir ein standardisiertes Wissensverarbeitungssystem von Wissen aus mehreren Quellen -> strukturierte Wissensextraktion -> Extraktion von Notfallbeziehungen -> Überprüfung durch Experten -> Wissensspeicherung Schritt für Schritt durch Standardisierung der Regeln für Notfallereignisse aufgebaut.

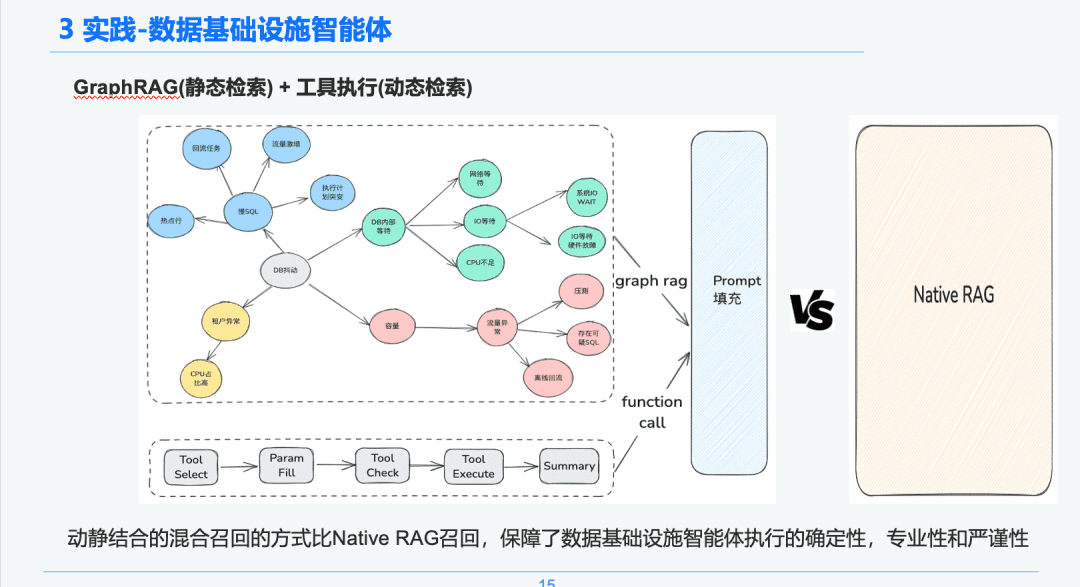
1.4 Wissensabfrage
In der Phase der intelligenten Suche verwenden wir GraphRAG als Träger der statischen Wissenssuche. Nachdem wir die DB-Jitter-Anomalie identifiziert haben, finden wir die Knoten, die mit dem DB-Jitter-Anomalie-Knoten verbunden sind, als Grundlage unserer Analyse, da jeder Knoten auch einige Metadaten-Informationen für jedes Ereignis in der Wissensextraktionsphase enthält, einschließlich des Ereignisnamens, der Ereignisbeschreibung, der zugehörigen Tools, der Tool-Parameter und so weiter.
Daher können wir die Rückgabeergebnisse über die Verknüpfung des Ausführungslebenszyklus des Ausführungswerkzeugs erhalten, um die dynamischen Daten zu erhalten, die als Grundlage für die Notfalldiagnose zur Fehlerbehebung dienen. Durch diesen dynamischen und statischen hybriden Rückrufansatz werden die Sicherheit, Professionalität und Strenge der Ausführung der Dateninfrastruktur-Intelligenzen im Vergleich zum reinen und einfachen RAG-Rückruf garantiert.
1,5 AWEL + Mittel
Schließlich wurde durch die AWEL+AGENT-Technologie der Gemeinschaft das Paradigma der AGENT-Orchestrierung genutzt, um einen Experten zu schaffen, der von der Absicht -> Notfalldiagnose-Experte -> Experte für die Ursachenanalyse ist.
Jeder Agent hat eine andere Funktion. Der Intent-Experte ist dafür verantwortlich, die Absicht des Benutzers zu erkennen und zu analysieren und Warnmeldungen zu identifizieren. Der Diagnose-Experte muss den zu analysierenden Grundursachenknoten mit Hilfe von GraphRAG ausfindig machen und spezifische Grundursacheninformationen erhalten. Der Analyseexperte muss die Daten jedes Ursachenknotens und den Bericht über die Überprüfung der historischen Analyse kombinieren, um einen diagnostischen Analysebericht zu erstellen.
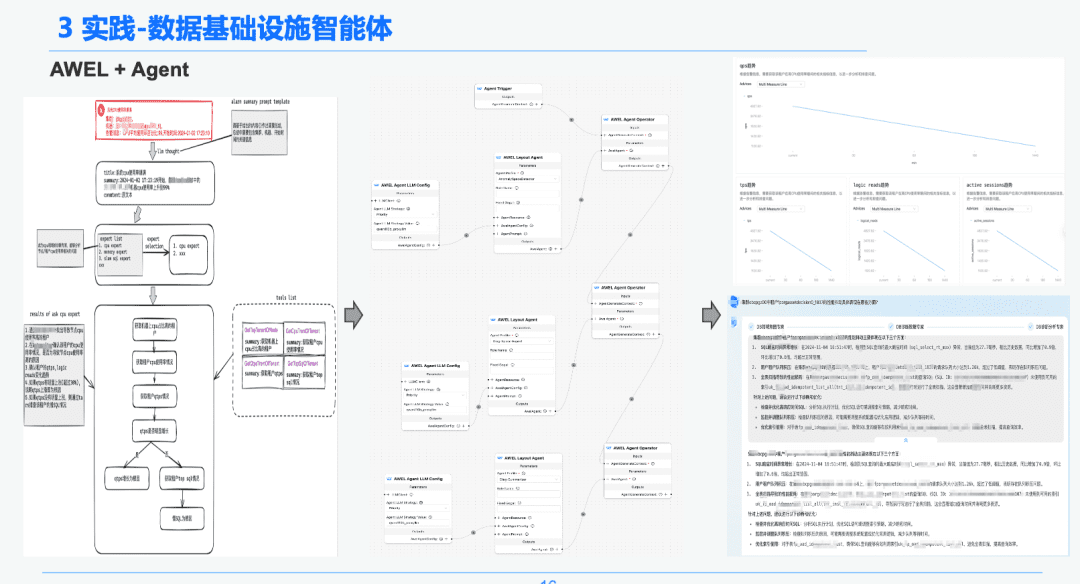
2. die RAG im Bereich der Analyse der Finanzberichterstattung
Neueste Praxis! Wie erstellt man einen Assistenten für die Analyse von Finanzberichten auf der Grundlage von DB-GPT?
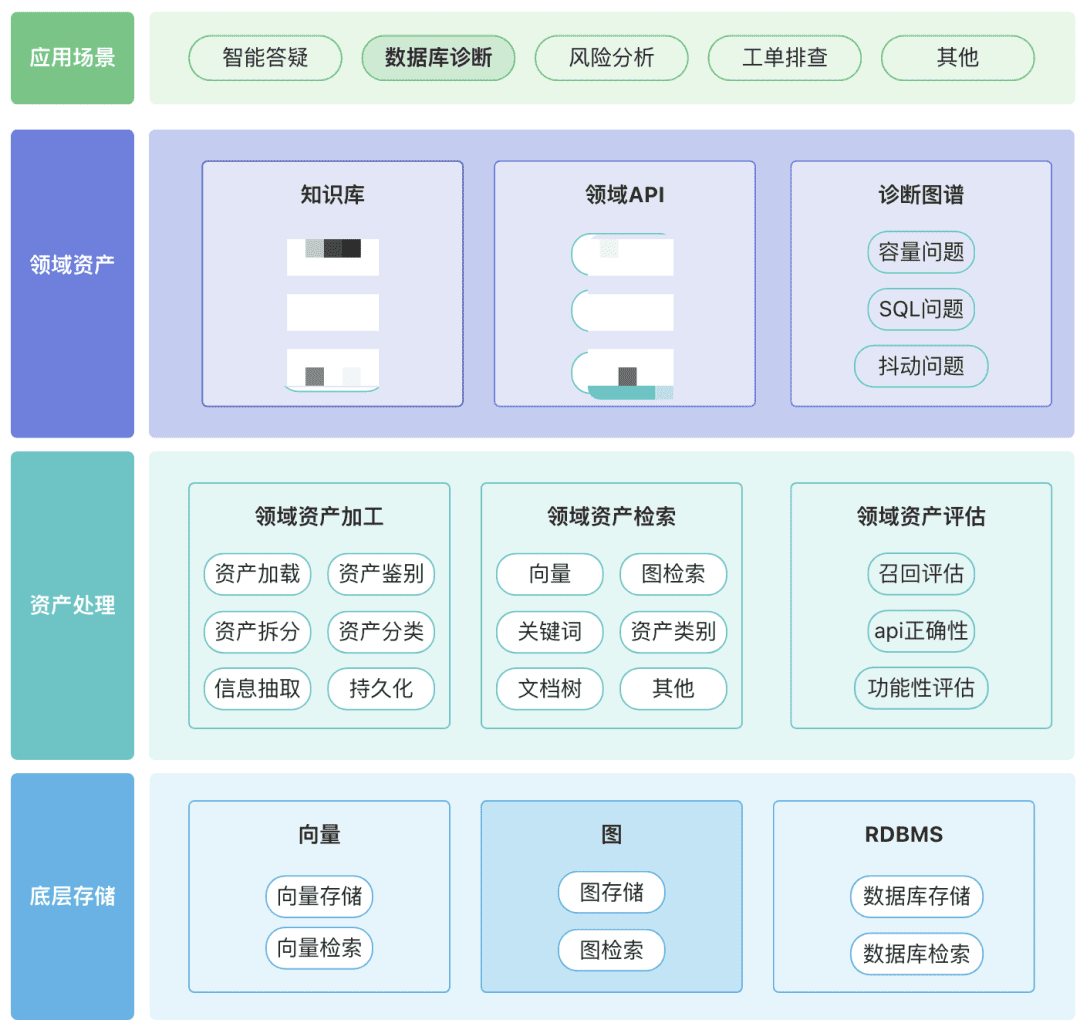
Sie können Ihr eigenes Repository von Domain-Assets, einschließlich Wissens-Assets, Tool-Assets und Wissensgraphen-Assets, rund um Ihre Domain aufbauen.
- Domänen-Assets: Zu den Domänen-Assets gehören Wissensdatenbanken, APIs und Tool-Skripte.
- Asset-Verarbeitung, die gesamte Asset-Datenverknüpfung umfasst die Domain-Asset-Verarbeitung, die Domain-Asset-Abfrage und die Domain-Asset-Auswertung.
- Unstrukturiert -> Strukturiert: kategorisiert in einer strukturierten Weise, korrekt organisierte Wissensinformationen.
- Extrahieren umfassenderer semantischer Informationen.
- Asset Retrieval:
- Hoffentlich handelt es sich um eine hierarchische, nach Prioritäten geordnete Suche und nicht um eine Einzelsuche.
- Die Nachfilterung ist wichtig, vorzugsweise durch die geschäftliche Semantik einiger Regeln.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...