VoiceCraft: Open-Source-Null-Sample-Sprachklonierung und Text-to-Speech-Tool

Allgemeine Einführung
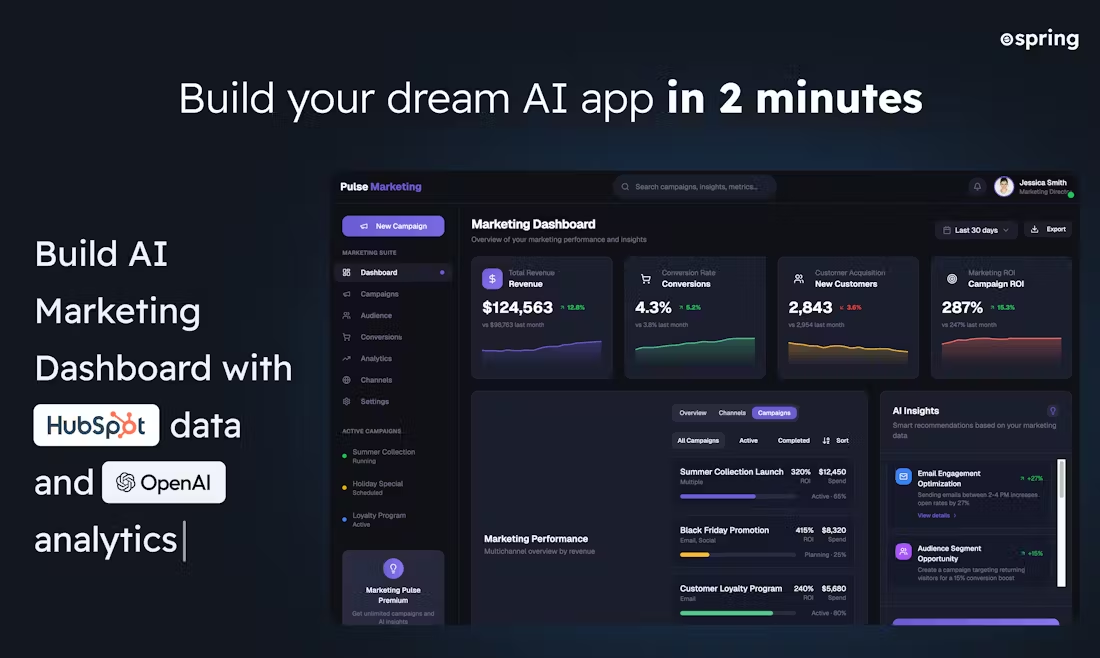
VoiceCraft ist ein Open-Source-Sprachbearbeitungs- und Null-Sample-Sprachsynthesewerkzeug, das auf dem Neural Codec-Sprachmodell basiert. Es verwendet eine innovative Methode zur Erzeugung kodierter Sequenzen, die das Einfügen, Löschen und Ersetzen bestehender Sprachsequenzen ermöglicht, um natürliche, kohärente bearbeitete Sprache zu erzeugen. Außerdem unterstützt VoiceCraft die Null-Sample-Sprachsynthese, wodurch die Notwendigkeit einer zusätzlichen Feinabstimmung für bestimmte Sprecher entfällt. Das Tool zeigt gute Leistungen bei verschiedenen Sprachverarbeitungsaufgaben und übertrifft die aktuellen SOTA-Modelle der Industrie deutlich.

Funktionsliste
- Sprachbearbeitung: Unterstützung von Einfüge-, Lösch- und Ersetzungsvorgängen, um eine natürliche und reibungslose Sprachbearbeitung zu ermöglichen.
- Null-Sample-Sprachsynthese: erzeugt die Stimme des Zielsprechers ohne zusätzliche Feinabstimmung.
- Auf der Grundlage der Transformer-Architektur werden kausale Maskierung und verzögerte Stapelungstechniken zur Verbesserung der Erzeugungsqualität eingesetzt.
- Open-Source-Modelle: kostenlos zum Herunterladen und Verwenden auf Huggingface und AI Express.
- Interaktive Benutzeroberfläche: Die Integration mit der Gradio-Bibliothek ermöglicht es den Benutzern, Modelle intuitiv zu steuern und zu testen.
Hilfe verwenden
Einbauverfahren
- Klonen Sie das Projekt-Repository in ein lokales Verzeichnis:
git clone git@github.com:jasonppy/VoiceCraft.git cd VoiceCraft - Stellen Sie sicher, dass Docker und das NVIDIA Container Toolkit auf Ihrem System installiert sind (Windows-Systeme verfügen über integrierte Treiber):
sudo apt-get install -y nvidia-container-toolkit-base - Erstellen Sie das Docker-Image:
docker build --tag "voicecraft" . - Starten Sie einen vorhandenen Container oder erstellen Sie einen neuen Container und geben Sie alle GPUs ein:
./start-jupyter.sh # Linux start-jupyter.bat # Windows - Öffnen Sie einen Browser und rufen Sie die auf dem Terminal angezeigte URL auf:
docker logs jupyter - Optional: Zugang zum Inneren des Containers von einem anderen Terminal aus:
docker exec -it jupyter /bin/bash export USER=(your_linux_username_used_above) export HOME=/home/$USER sudo apt-get update - Stellen Sie sicher, dass die Grafikkarte im Container sichtbar ist:
nvidia-smi - In Ihrem Browser öffnen
inference_tts.ipynbDie Zelle wird Schritt für Schritt ausgeführt.
Umgebungseinstellungen
- Erstellen und aktivieren Sie eine virtuelle Umgebung:
conda create -n voicecraft python=3.9.16 conda activate voicecraft - Installieren Sie die erforderlichen Abhängigkeiten:
pip install -e git+https://github.com/facebookresearch/audiocraft.git@c5157b5bf14bf83449c17ea1eeb66c19fb4bc7f0#egg=audiocraft pip install xformers==0.0.22 pip install torchaudio==2.0.2 torch==2.0.1 apt-get install ffmpeg apt-get install espeak-ng pip install tensorboard==2.16.2 pip install phonemizer==3.2.1 pip install datasets==2.16.0 pip install torchmetrics==0.11.1 pip install huggingface_hub==0.22.2 conda install -c conda-forge montreal-forced-aligner=2.2.17 openfst=1.8.2 kaldi=5.5.1068 mfa model download dictionary english_us_arpa mfa model download acoustic english_us_arpa conda install -n voicecraft ipykernel --no-deps --force-reinstall
Beispiel für eine Argumentation
- Begründung der Sprachbearbeitung:
python phonemize_encodec_encode_hf.py --dataset_size xs --download_to path/to/store_huggingface_downloads --save_dir path/to/store_extracted_codes_and_phonemes --encodec_model_path path/to/encodec_model --mega_batch_size 120 --batch_size 32 --max_len 30000 - Null-Proben-Sprachsynthese-Inferenz:
python tts_demo.py -h
Gradio
- Führen Sie es in Colab aus:
Open in Colab - Lokal laufen:
apt-get install -y espeak espeak-data libespeak1 libespeak-dev apt-get install -y festival* apt-get install -y build-essential apt-get install -y flac libasound2-dev libsndfile1-dev vorbis-tools apt-get install -y libxml2-dev libxslt-dev zlib1g-dev pip install -r gradio_requirements.txt python gradio_app.py
allgemeine Probleme
- Wie lässt sich die Natürlichkeit der erzeugten Sprache verbessern? Stellen Sie sicher, dass der Inhalt des Eingabetextes mit dem Stil und dem Kontext des Zielsprachmusters übereinstimmt.
- Was sollte ich tun, wenn die erzeugte Sprachdatei verrauscht ist? Versuchen Sie, Sprachsamples von höherer Qualität zu verwenden oder die Modellparameter anzupassen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...