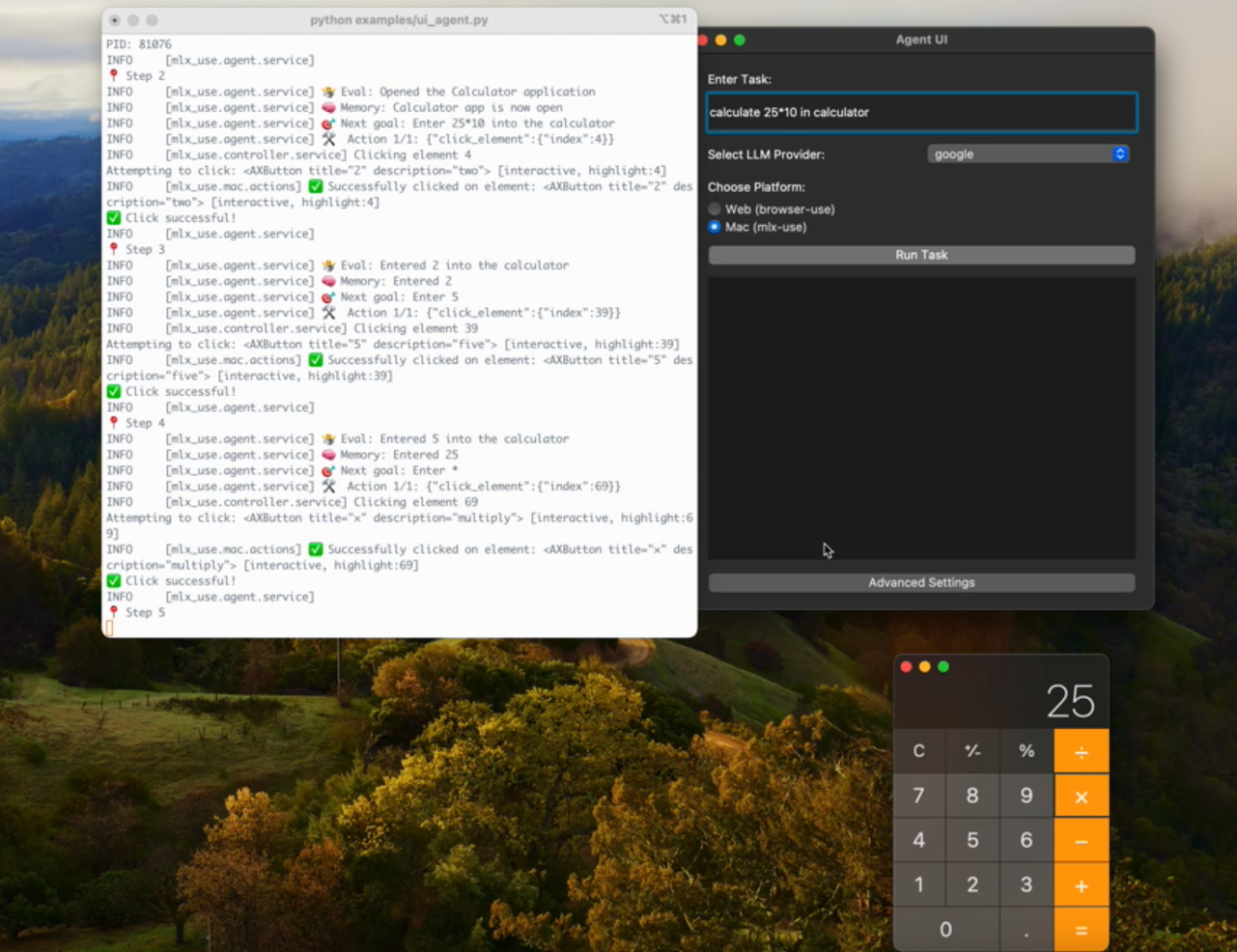
vLLM: Eine LLM-Inferenz- und Service-Engine zur effizienten Speichernutzung

Allgemeine Einführung
vLLM ist eine durchsatzstarke und speichereffiziente Reasoning- und Service-Engine, die für Large Language Modelling (LLM) entwickelt wurde. Ursprünglich vom Sky Computing Lab an der UC Berkeley entwickelt, ist es nun ein Gemeinschaftsprojekt, das sowohl von der Wissenschaft als auch von der Industrie vorangetrieben wird. vLLM zielt darauf ab, schnelle, benutzerfreundliche und kosteneffiziente LLM-Reasoning-Dienste mit Unterstützung für eine breite Palette von Hardware-Plattformen wie CUDA, ROCm, TPUs und mehr zu bieten. Zu seinen Hauptmerkmalen gehören optimierte Ausführungsschleifen, Zero-Overhead-Präfix-Caching und erweiterte multimodale Unterstützung.

Funktionsliste
- Reasoning mit hohem Durchsatz: Unterstützt massiv paralleles Reasoning, was die Reasoning-Geschwindigkeit deutlich erhöht.
- Speichereffizient: Verringern Sie den Speicherbedarf und verbessern Sie die Effizienz des Modellbetriebs durch Optimierung der Speicherverwaltung.
- Multi-Hardware-Unterstützung: Kompatibel mit CUDA, ROCm, TPU und anderen Hardware-Plattformen für einen flexiblen Einsatz.
- Null-Overhead-Präfix-Caching: Verringerung doppelter Berechnungen und Verbesserung der Inferenz-Effizienz.
- Multimodale Unterstützung: Unterstützt mehrere Eingabearten wie Text, Bild usw. zur Erweiterung der Anwendungsszenarien.
- Open-Source-Community: von Wissenschaft und Industrie gepflegt, ständig aktualisiert und optimiert.
Hilfe verwenden
Einbauverfahren
- Klonen Sie das vLLM-Projekt-Repository:
git clone https://github.com/vllm-project/vllm.git
cd vllm
- Installieren Sie die Abhängigkeit:
pip install -r requirements.txt
- Wählen Sie die richtige Dockerdatei für den Build auf der Grundlage der Hardwareplattform:
docker build -f Dockerfile.cuda -t vllm:cuda .
Leitlinien für die Verwendung
- Starten Sie den vLLM-Dienst:
python -m vllm.serve --model <模型路径>
- Sendet eine Begründungsanfrage:
import requests
response = requests.post("http://localhost:8000/infer", json={"input": "你好,世界!"})
print(response.json())
Detaillierte Funktionsweise
- Reasoning mit hohem DurchsatzDurch die Parallelisierung der Argumentationsaufgabe ist vLLM in der Lage, eine große Anzahl von Anfragen in kurzer Zeit für hochgradig gleichzeitige Szenarien zu bearbeiten.
- Effizienter SpeichervLLM verwendet eine optimierte Speicherverwaltungsstrategie, um den Speicherbedarf zu reduzieren und eignet sich daher für den Einsatz in Umgebungen mit eingeschränkten Ressourcen.
- Unterstützung mehrerer HardwareBenutzer können die richtige Dockerdatei für die Erstellung entsprechend ihrer Hardwarekonfiguration auswählen und flexibel auf verschiedenen Plattformen einsetzen.
- Null-Overhead-Präfix-CachingDurch die Zwischenspeicherung der Ergebnisse von Präfixberechnungen reduziert vLLM wiederholte Berechnungen und verbessert die Effizienz der Schlussfolgerungen.
- multimodale UnterstützungvLLM unterstützt nicht nur die Texteingabe, sondern kann auch eine Vielzahl von Eingabearten wie Bilder verarbeiten, was die Anwendungsszenarien erweitert.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel

Keine Kommentare...