
VBDeepSeek: ein Open-Source-Tool zur Erstellung von Wortschatzmaterialien für die Klasse 4 mit DeepSeek

Allgemeine Einführung
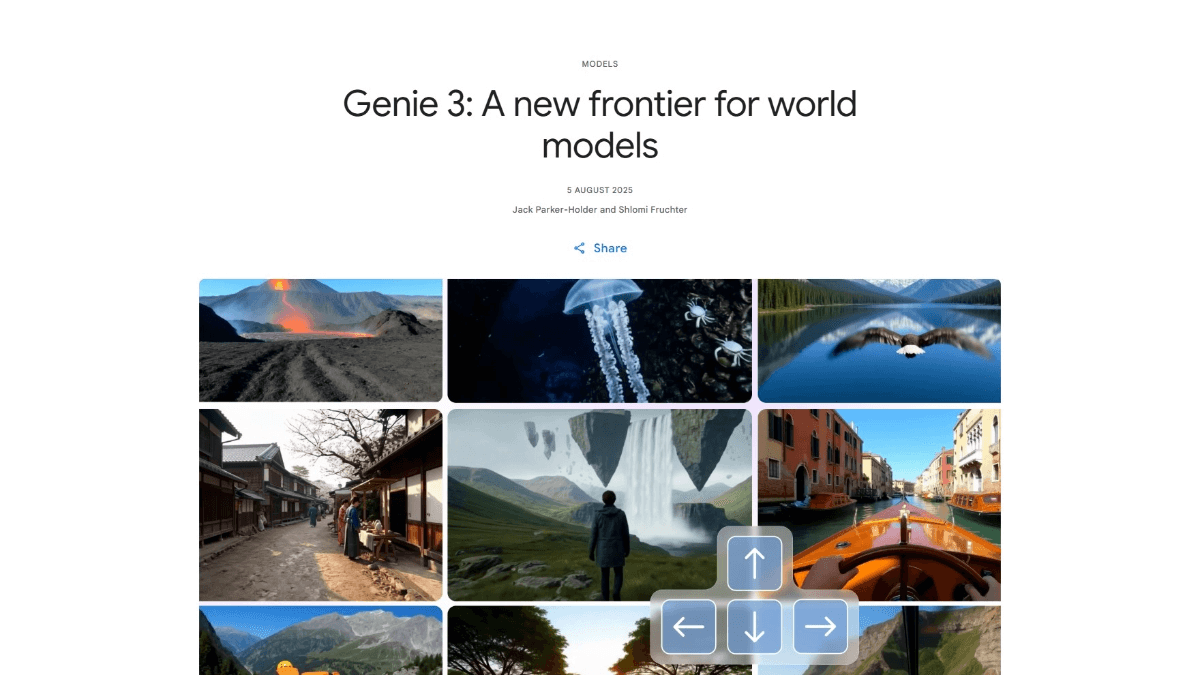
"Vocabulary Book by DeepSeek" ist ein Open-Source-Projekt, das auf der Grundlage des großen Modells von DeepSeek entwickelt wurde und Englischlernenden helfen soll, den Wortschatz von College English Level 4 (CET-4) effizient zu beherrschen. Das Projekt wird auf GitHub gehostet und vom Entwickler vxiaozhi erstellt. Durch das Python-Skript in Kombination mit den leistungsstarken Sprachgenerierungsfunktionen von DeepSeek werden automatisch Vokabellernmaterialien generiert, die Wortbedeutungen, Wortstämme, Beispielsätze und Einprägungstechniken enthalten. Das Tool organisiert die Wörter in alphabetischer Reihenfolge, hat ein klares Ausgabeformat, unterstützt die Speicherung von JSON-Dateien und eignet sich für Schüler, Lehrer oder Selbstlerner. Der Projektcode ist offen und 80% oder mehr wird automatisch von DeepSeek generiert, was die innovative Anwendung von KI im Bildungsbereich widerspiegelt. Ganz gleich, ob Sie sich auf die 4. Klasse vorbereiten oder Ihren Wortschatz verbessern möchten, dieses Tool bietet eine praktische Lernunterstützung.

Funktionsliste
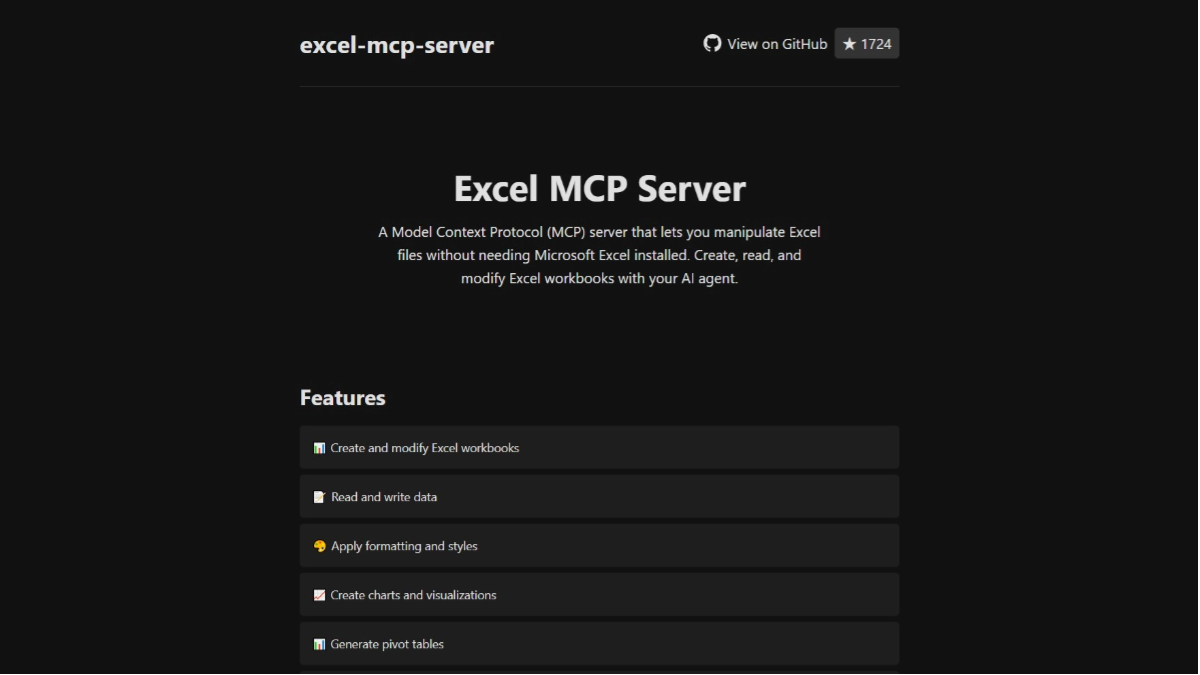
- Automatische Generierung von Vokabellernmaterial für Klasse 4DeepSeek: Ruft die DeepSeek-Schnittstelle auf, um Wortbedeutungen, Wurzelanalysen, Beispielsätze und Gedächtnistipps zu generieren.
- Alphabetische SpeicherungCET-4-Wörter in JSON-Dateien von A bis Z nach dem Anfangsbuchstaben aufteilen, einfach zu finden und zu verwalten.
- Hilfreiche BilderzeugungGenerierung wortbezogener mnemotechnischer Bilder durch Skripte zur Verbesserung des Gedächtnisses.
- ArtikelgeneratorVokabel-Lernartikel im Markdown-Format erzeugen, die mit einem Buchstaben beginnen und sich für Blogs oder die Organisation von Notizen eignen.
- Open-Source-UnterstützungDer vollständige Python-Code wird zur Verfügung gestellt, und es steht den Benutzern frei, die Funktionalität zu ändern oder zu erweitern.
Hilfe verwenden
Einbauverfahren
"Vocabulary Book by DeepSeek" ist ein auf Python basierendes Tool, das eine bestimmte Programmierumgebung benötigt, um zu laufen. Nachfolgend finden Sie die detaillierten Schritte zur Installation und Nutzung:
1. die Vorbereitung der Umwelt
- Installation von PythonVergewissern Sie sich, dass Python 3.8 oder höher auf Ihrem System installiert ist. Sie können es von der Python-Website herunterladen und installieren.
- Klonprojekt: Öffnen Sie ein Terminal oder eine Befehlszeile und geben Sie den folgenden Befehl ein, um das Projekt lokal herunterzuladen:
git clone https://github.com/vxiaozhi/vocabulary-book-by-deepseek.git cd vocabulary-book-by-deepseek
- Installation von AbhängigkeitenDas Projekt benötigt mehrere Python-Bibliotheken. Führen Sie den folgenden Befehl aus, um sie zu installieren:
pip install -r requirements.txtwenn nicht
requirements.txtkann die Kernbibliothek manuell installiert werden:pip install requests openai pillow - Konfigurieren der DeepSeek-API: DeepSeek-API-Schlüssel ist erforderlich. Nachdem Sie sich für ein DeepSeek-Konto angemeldet haben, erhalten Sie den Schlüssel auf der DeepSeek-Plattform und geben ihn im Abschnitt für den API-Aufruf in der Projektkonfigurationsdatei oder im Code ein.
2. die Nutzung der Hauptfunktionen
Das Projekt besteht aus zwei Kernskripten: der Worthilfe und der Hilfsbilderzeugung. Im Folgenden wird der detaillierte Arbeitsablauf beschrieben:
(1) Erstellen von Wortstudienmaterialien
- Wortdaten vorbereitenProjekte werden standardmäßig bereitgestellt.
data/cet4/JSON-Dateien, sortiert nach den Buchstaben A-Z im Verzeichnis (z. B.A.jsonundB.json). Jede Datei enthält eine Liste von Wörtern, die mit dem entsprechenden Buchstaben beginnen. - Laufende Skripte::
- Öffnen Sie ein Terminal und wechseln Sie in das Projektverzeichnis.
- Führen Sie den folgenden Befehl aus, um eine Wortanalyse zu erstellen:
python cet4_word_helper.py - Das Skript liest die
data/cet4/Die Wörter in der Liste werden verwendet, um Wortbedeutungen, Wortstämme, Beispielsätze und Gedächtnistipps über die DeepSeek-API zu generieren, und die Ergebnisse werden in derresult/cet4/JSON-Datei in dem Verzeichnis (z. B.A.json).
- Ergebnisse anzeigenJSON-Datei: Beispiel für die Struktur der generierten JSON-Datei:
{ "word": "abandon", "meaning": "放弃", "root": "a-(加强) + bandon(控制)", "example": "He had to abandon his car in the snow.", "memory_tip": "想象一个人在雪地里放弃aband控制on车。" }
(2) Erzeugung mnemotechnischer Bilder
- Führen Sie das Skript zur Bilderzeugung aus::
- Führen Sie den folgenden Befehl aus:
python gen_words_img.py - Das Skript wird auf der Grundlage des
result/cet4/Die Wortdaten im Skript werden verwendet, um mnemonische Bilder zu erzeugen, die standardmäßig im angegebenen Verzeichnis gespeichert werden (Sie müssen den Ausgabepfad im Skript konfigurieren).
- Führen Sie den folgenden Befehl aus:
- Benutzerdefinierte EinstellungenModifikation
gen_words_img.pyParameter, wie Bildgröße, Auflösung oder Stil, um sicherzustellen, dass Bilder erzeugt werden, die den Anforderungen entsprechen.
(3) Generierung von Vokabelartikeln
- Führen Sie das Skript zur Artikelerstellung aus::
- Umsetzung:
python gen_articles.py - Skript lesen
result/cet4/in der JSON-Datei und erzeugt 26 Markdown-Dateien (wie die2025-02-11-cet4-A.md), speichern aufresult/cet4_articles/Katalog.
- Umsetzung:
- AusgabeformatJede Datei enthält Analysen von Wörtern mit Anfangsbuchstaben, die zum Lernen oder zum Austausch geeignet sind. Beispiel:
--- title: "四级词汇-A开头单词" date: 2025-02-11 --- ## abandon 词义:放弃 词根:a-(加强) + bandon(控制) 例句:He had to abandon his car in the snow. 记忆技巧:想象一个人在雪地里放弃aband控制on车。
3. operationelle Überlegungen
- API-Schlüssel-SicherheitDeepSeek-API-Schlüssel sollten nicht direkt in Skripten kodiert werden; es wird empfohlen, Umgebungsvariablen zu verwenden, um sie zu speichern:
export DEEPSEEK_API_KEY='你的密钥' - NetzanschlussStellen Sie sicher, dass das Netzwerk frei ist, wenn Sie das Skript ausführen, da es auf die DeepSeek-API angewiesen ist.
- Überprüfung des DateipfadsWenn
data/cet4/vielleichtresult/cet4/Das Verzeichnis fehlt, Sie müssen die Konfiguration des Skriptpfads manuell erstellen oder anpassen. - Erweiterte FunktionalitätDer Code kann nach Bedarf geändert werden, z. B. um die Unterstützung von Wörtern der Stufe 6 hinzuzufügen oder um das Ausgabeformat anzupassen.
4. die Bedienung von Sonderfunktionen
- StapeldateiGenerieren Sie Wortprofile für alle Buchstaben auf einmal, indem Sie das Hauptskript nur einmal ausführen.
- Bildgestütztes GedächtnisErstellte Hilfsmittel können in elektronische Notizen importiert oder ausgedruckt werden, um textbasiertes Lernen zu begleiten.
- Artikel teilenMarkdown-Dateien können direkt für Blogbeiträge verwendet oder in Tools wie Notion importiert werden, um Studiennotizen zu organisieren.
Cline Einsatzstichwörter
Aufgabe1
用 Python 写一个 cet4 单词助记工具,对单词进行词义词根分析、例举例句、并提供一些高效的记忆技巧和窍门。 详细需求如下:
1. 单词已经按照字母归类存储在data/cet4/目录下,分别为: A.json B.json ... Z.json
2. 读取每一个 data/cet4/目录下 每个JSON文件中的所有单词,对每个单词调用OpenAI的接口生成该单词的词义、词根、例句、记忆技巧信息。
3. 生成的单词信息保存到 result/cet4/目录下,分别为: A.json B.json ... Z.json
Aufgabe2
用 Python3.8 写一个单词助记图片生成工具gen_words_img.py, 详细需求如下:
1. 读取每一个 result/cet4/目录下 每个JSON文件中的所有单词信息,每个单词信息包括word、analysis、draw_explain、draw_prompt 4个字段。
2. 对每个单词调用replicate的接口(接口具体实现在provider_replicate.py:replicate_run)生成该单词的图片。
3. 生成的图片文件保存到 result/cet4_imgs/目录下,文件名称格式为:{first_letter_of_word}/{word}.jpg。如果对应图片文件已存在,则跳过本图片文件的生成。
4. 假设所有依赖库已经安装。
Aufgabe3
用 Python3.8 写一个文章生成工具gen_articles.py, 为26个英文字母各生成一个文件,共26个文件,文件名格式为:2025-02-11-cet4-{letter}.md, 每个文件的内容组成如下:
"""
---
layout: post
title: "四级词汇-{letter}开头单词"
subtitle: "四级词汇-{letter}开头单词"
date: 2025-02-11
author: "vxiaozhi"
catalog: true
tags:
- english
- cet4
---
{{ for all word begin with letter}}
## word
{word.analysis}
{{end}}
"""
其中 word.analysis 通过读取 result/cet4/{letter}.json 获得,result/cet4/{letter}.json存储了{letter}开头的全部单词的信息,如果result/cet4/{letter}.json 不存在,则跳过该letter对应文件的生成。
更多约束如下:
1、2025-02-11-cet4-{letter}.md 保存到 result/cet4_articles 目录下。
2、Python 使用 3.8 版本。
3、假设所有Python依赖库已经安装。© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel

Keine Kommentare...