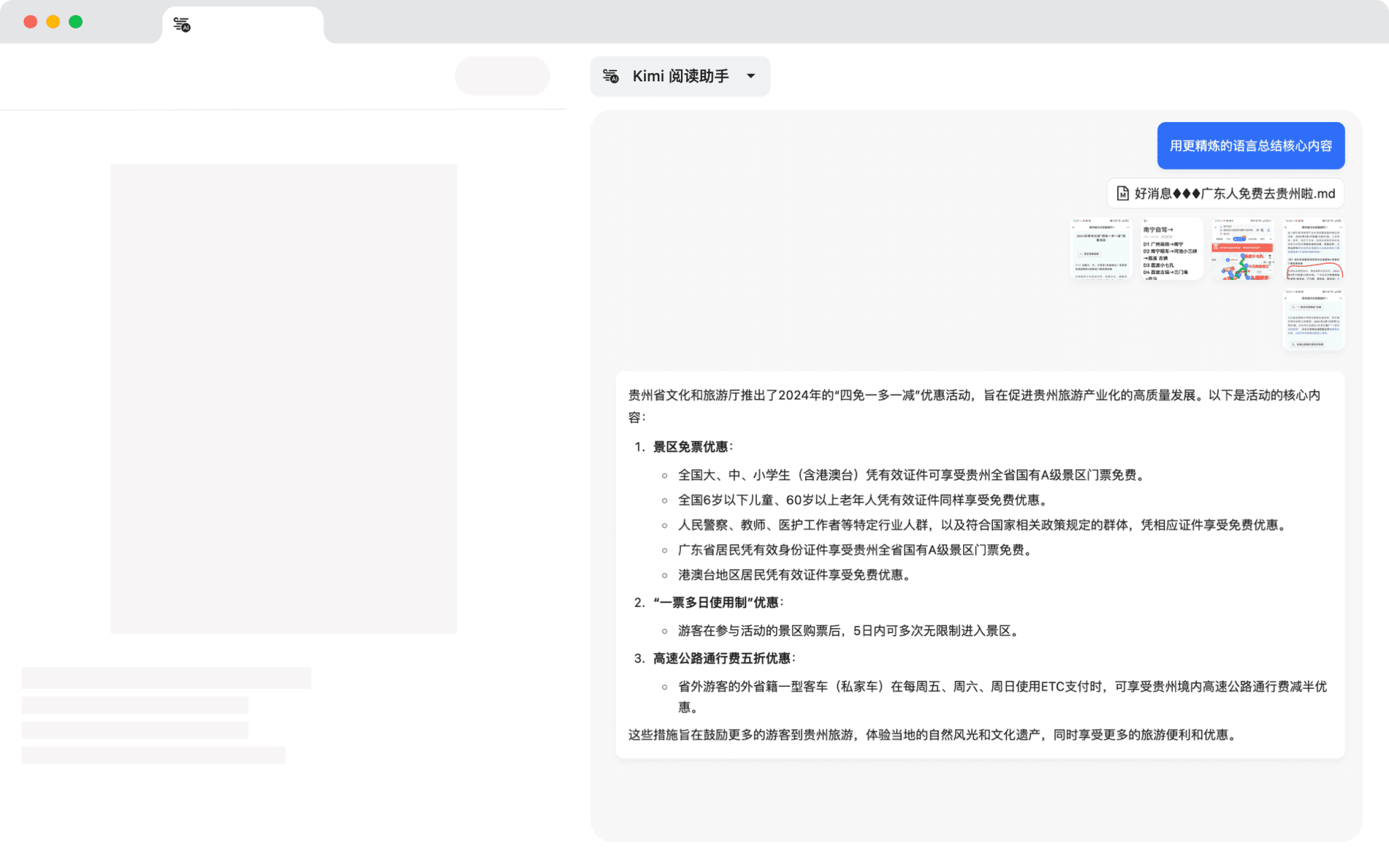
Vanna Local Deployment: Effiziente Text2SQL-Konvertierungen mit Leichtigkeit

Vanna ist ein hoch angesehenes Text2SQL Open-Source-Framework, das natürliche Sprache in SQL-Abfrageanweisungen umwandelt. Dieser Artikel beschreibt, wie man Vanna lokal einsetzt und mit einer MySQL-Datenbank und dem Deepseek Die Modelle sind so konfiguriert und getestet, dass Sie schnell mit dem Tool arbeiten können. Alle Vorgänge basieren auf realen Tests, um sicherzustellen, dass die Schritte klar und praktikabel sind.
Python-Umgebung einrichten
Um Vanna auszuführen, benötigen Sie zunächst eine stabile Python-Umgebung. Hier ist eine Schritt-für-Schritt-Anleitung für die Konfiguration von Vanna, die Miniconda3 als Beispiel verwendet.
Installation von Miniconda3
- Laden Sie das Installationspaket herunter:
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh - Führen Sie das Installationsskript aus:
sh Miniconda3-latest-Linux-x86_64.sh - Konfigurieren Sie die Umgebungsvariablen:
vim /etc/profileFügen Sie sie der Datei hinzu:
export PATH="/data/apps/miniconda3/bin:$PATH"Speichern und aktualisieren Sie die Konfiguration:
source /etc/profile - Wenn Sie das Programm deinstallieren müssen, können Sie einfach das Installationsverzeichnis löschen:
rm -rf /data/apps/miniconda3/
Erstellen einer virtuellen Umgebung
- Erstellen Sie eine Python 3.10-Umgebung:
conda create -n test python=3.10 - Aktivieren Sie die Umgebung (muss bei einem neuen Terminal oder nach einem Neustart wirksam werden):
conda activate test - Andere gängige Befehle:
- Verlassen Sie die Umgebung:
conda deactivate - Umweltinformationen anzeigen:
conda info --env
- Verlassen Sie die Umgebung:
Nach Abschluss der oben genannten Schritte verfügen Sie über eine eigenständige virtuelle Python-Umgebung, die die Grundlage für den Einsatz von Vanna bildet.
Vanna Einsatz und Konfiguration
Nachdem die Python-Umgebung fertig ist, können wir uns nun der Kernkonfiguration von Vanna widmen. Die folgenden Schritte beziehen sich auf die offizielle Dokumentation (https://vanna.ai/docs/) und verwenden die MySQL-Datenbank als Beispiel.
Konfiguration der Datenbankverbindung
Vergewissern Sie sich zunächst, dass Sie sich mit Ihrem MySQL-Konto, Passwort und Port ordnungsgemäß bei der Datenbank anmelden können. Nachdem Sie eine erfolgreiche Verbindung getestet haben, öffnen Sie die MySQL-Konfigurationsseite in der offiziellen Vanna-Dokumentation (wählen Sie MySQL in der linken Menüleiste). Auf der Seite wird ein Beispiel für einen Verbindungscode angezeigt, wie unten dargestellt:
Passen Sie auf der Grundlage Ihrer Datenbankinformationen die Parameter im Code an (z. B. Host, Benutzer, Kennwort usw.), um sicherzustellen, dass Vanna reibungslos eine Verbindung herstellen kann.
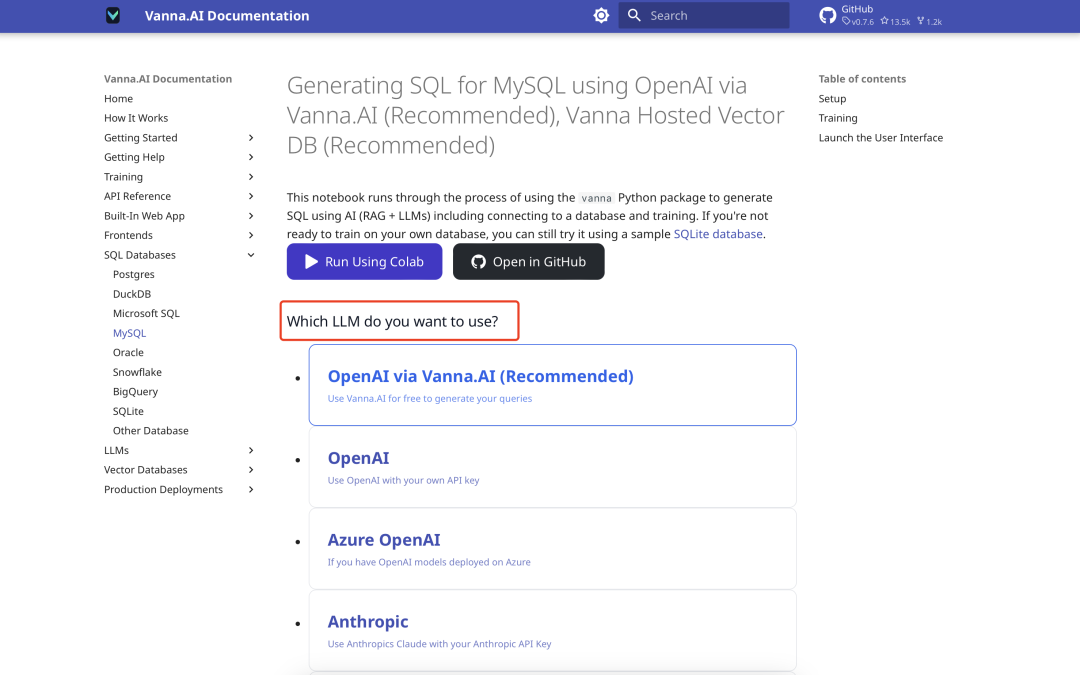
Auswahl eines Sprachmodells
Vanna unterstützt eine Vielzahl von Large Language Models (LLMs). Die offizielle Seite fordert zur Modellauswahl auf, zum Beispiel Ollama oder API-Aufrufe. Das Deepseek-Modell für silikonbasierte Abläufe wird hier als Beispiel dargestellt.
- Ollama ErfahrungVersuche, das quantisierte Deepseek-7b-Modell einzusetzen, haben zu schlechten Ergebnissen geführt, und es wird empfohlen, diese Option nicht zu nutzen.
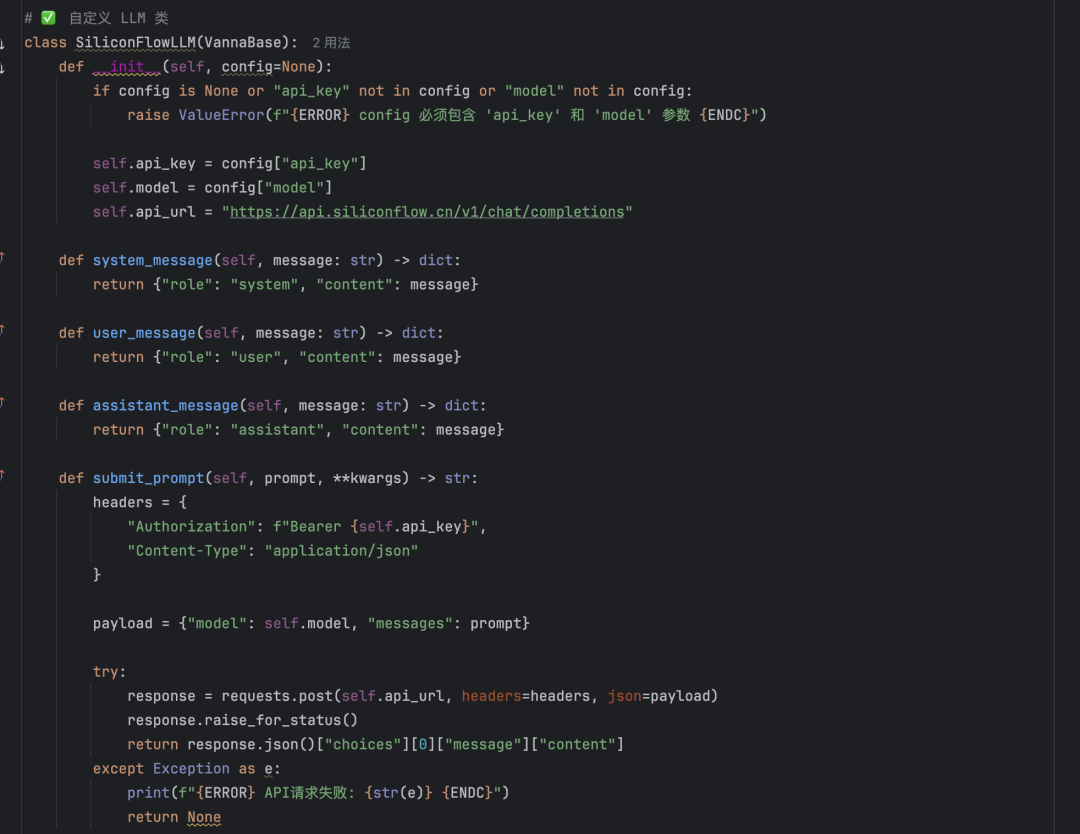
- Deepseek-APIAufrufen von Deepseek-Modellen über In-Silico-Flows bringt eine bessere Leistung. Beachten Sie jedoch, dass benutzerdefinierte LLM-Klassen erforderlich sind, um Modelle zu verwenden, die nicht offiziell unterstützt werden. Siehe das Vanna Open Source Projekt's Mistral Implementierung (mistral.py) eine entsprechend an Deepseek angepasste Klasse erstellen.
Der Konfigurationsbildschirm sieht wie folgt aus:
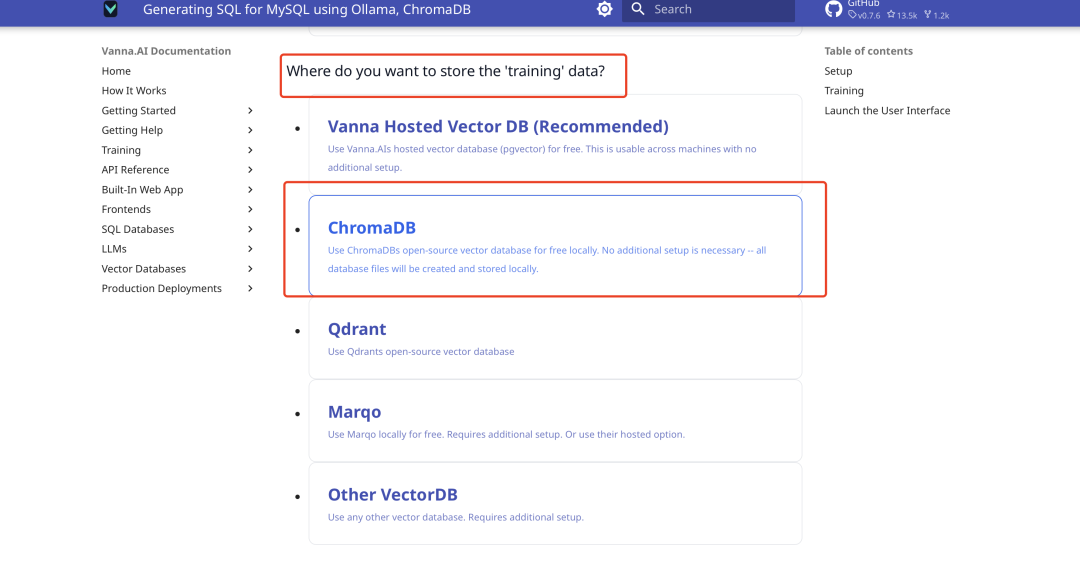
Einrichtung der Vektordatenbank
Vanna integriert standardmäßig ChromaDB als kleine Vektordatenbank, eine zusätzliche Installation ist nicht erforderlich. Die offizielle Dokumentation generiert Code entsprechend Ihrer Wahl, wie unten gezeigt:
Installation von Abhängigkeiten und Vorbereitung des Codes
- Installieren Sie Vanna und seine Abhängigkeiten in einer aktivierten virtuellen Umgebung:
pip install vanna - Erstellen einer
.pyDatei, kopieren Sie den offiziell generierten Code hinein. Nachfolgend finden Sie einen Beispielcode für die Anpassung von MySQL und Deepseek (Sie müssen die Parameter entsprechend der tatsächlichen Situation anpassen):from vanna.remote import VannaDefault vn = VannaDefault(model='deepseek', api_key='your_api_key') vn.connect_to_mysql(host='localhost', dbname='test_db', user='root', password='your_password', port=3306)
Datentraining
Vanna unterstützt drei Arten von Trainingsdaten: SQL-Anweisungen, Produktdokumentation und Beschreibungen der Tabellenstruktur der Datenbank. Wir empfehlen hier die Verwendung der Tabellenstrukturbeschreibung, da sie intuitiver wirkt. Die Trainingsschritte sind wie folgt:
- Bereiten Sie die Daten der Tabellenstruktur vor (z. B. DDL-Datei).
- Verwenden Sie den offiziell bereitgestellten Schulungscode:
vn.train(ddl="CREATE TABLE employees (id INT, name VARCHAR(255), salary INT)") - Der Ausbildungsprozess wird im Folgenden dargestellt:
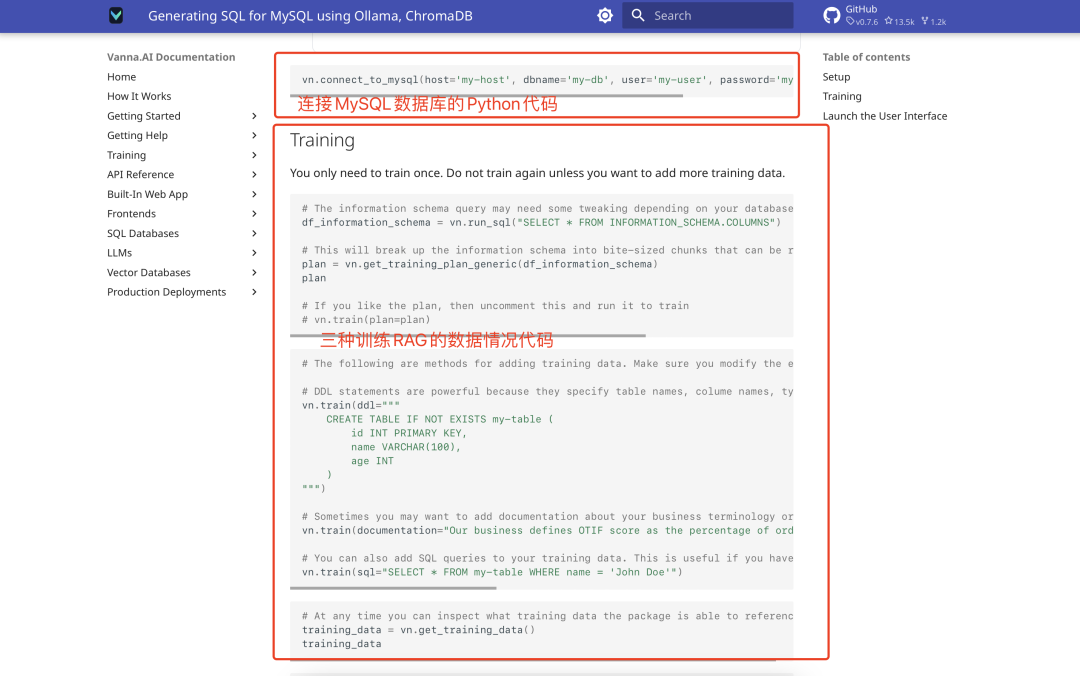
Es werden weitere Trainingsergebnisse angezeigt:
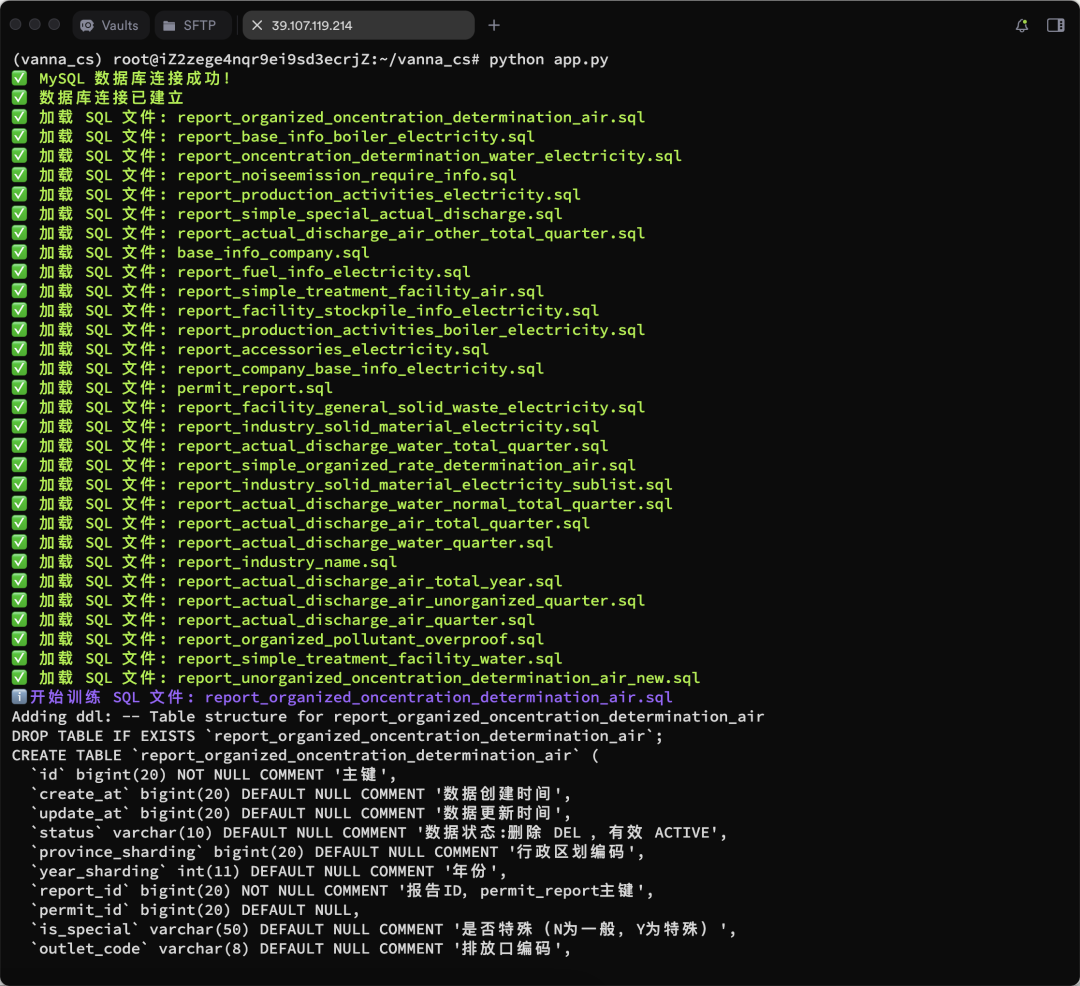
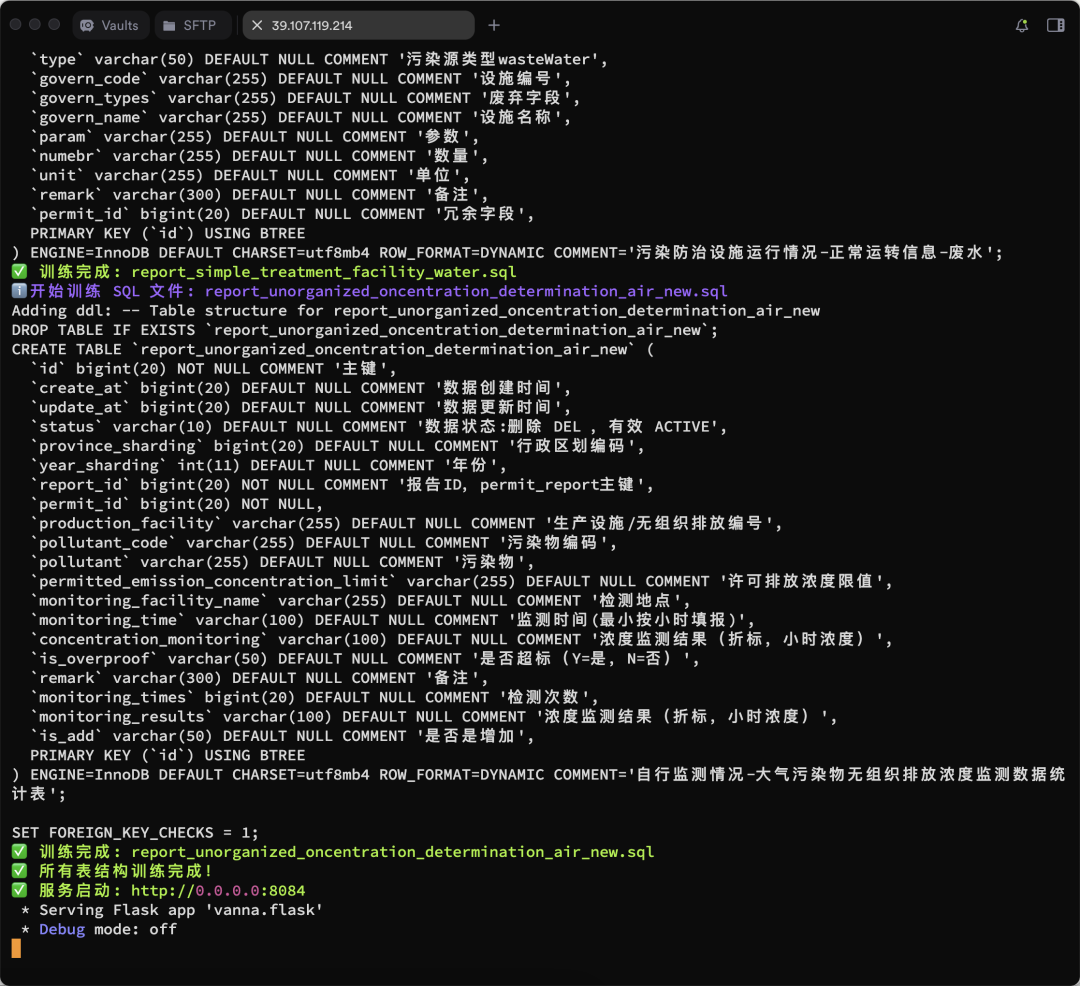
Ausführen der Webschnittstelle
Sobald das Training abgeschlossen ist, führen Sie den folgenden Flask-API-Code aus, um die Web-UI von Vanna zu starten:
from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn)
app.run()
Zugriff auf die lokale Adresse (normalerweise http://127.0.0.1:5000), können Sie über die Schnittstelle SQL-Abfragen durchführen.
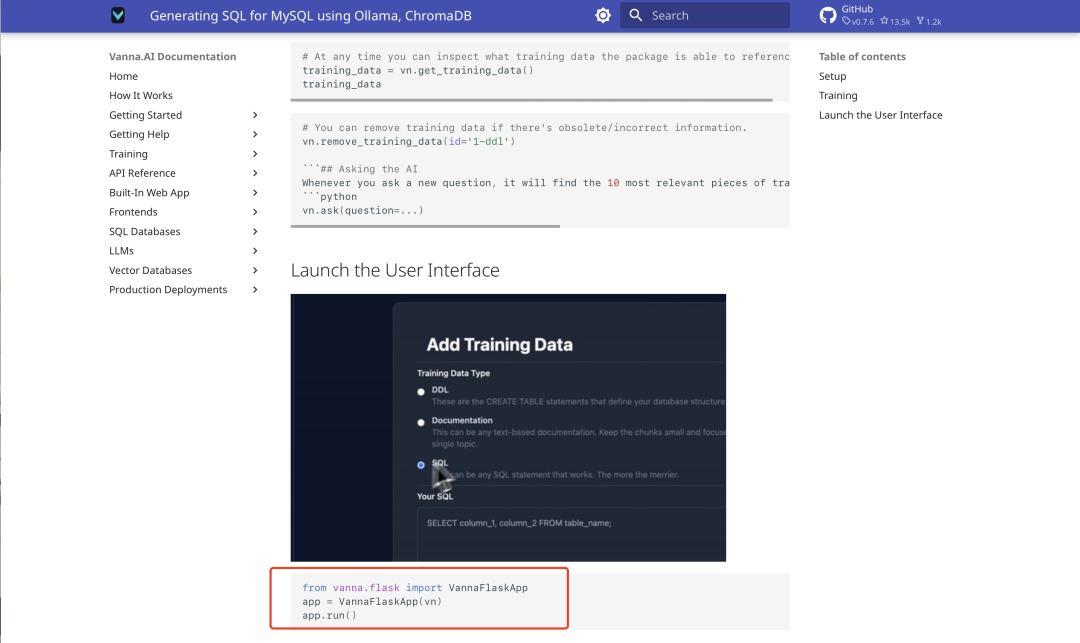
Anzeige des Rückfrageeffekts
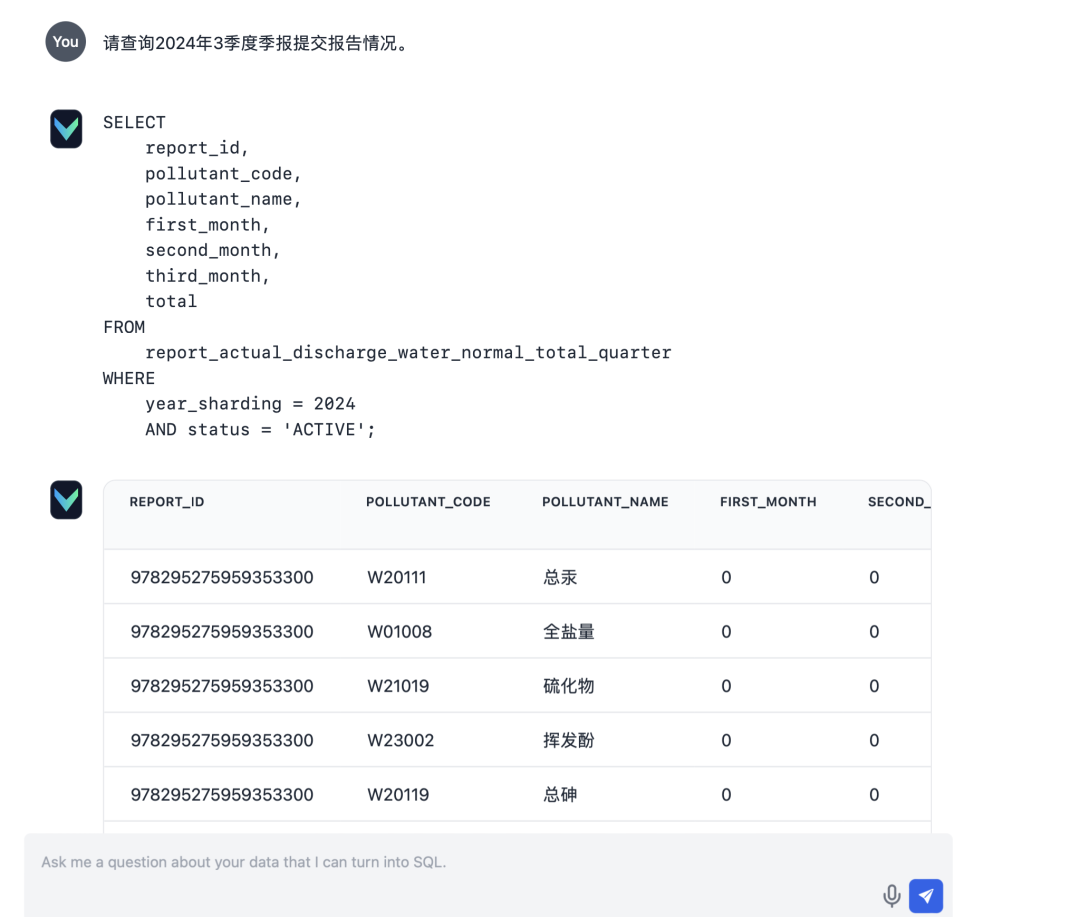
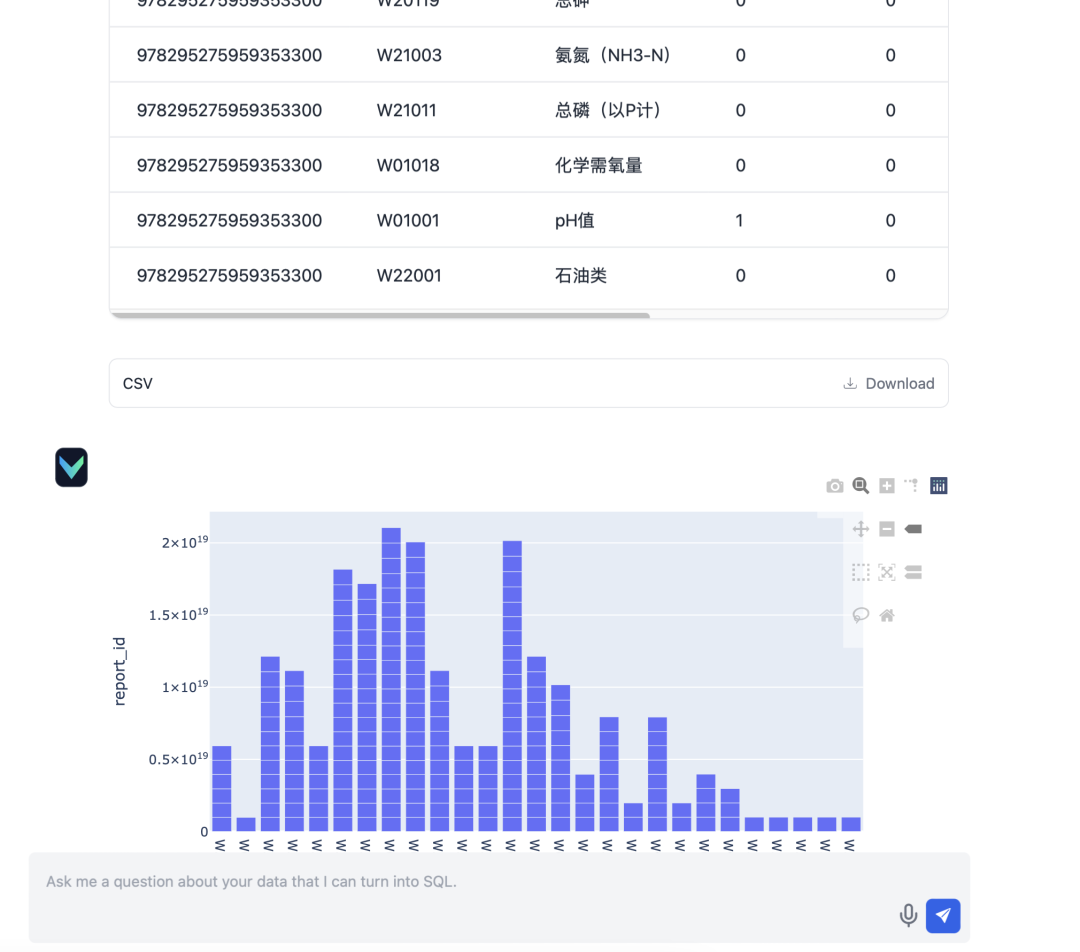
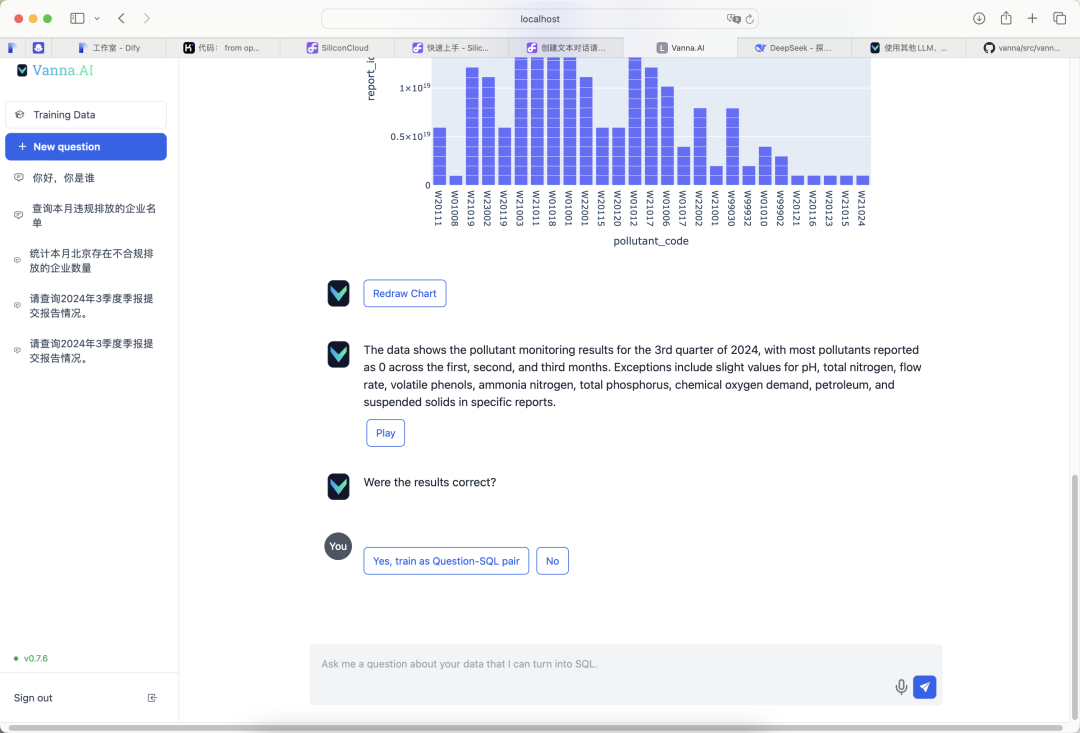
Nach der Bereitstellung funktionierte die Q&A-Funktionalität von Vanna zufriedenstellend. Hier sind ein paar aktuelle Testergebnisse:
- Eingabe: "Bitte erkundigen Sie sich nach dem Stand der Einreichung der Berichte für den Quartalsbericht für das Märzquartal 2024."

- Eingabe: "Anzahl der Statistiken"
- Eingabe: "Schadstoffstatistik"
Zusammenfassung und Empfehlungen
Wenn Sie diese Schritte befolgen, können Sie Vanna erfolgreich lokal einsetzen und effiziente Text2SQL-Funktionalität in Kombination mit MySQL- und Deepseek-Modellen implementieren. Im Vergleich zu anderen Tools hat Vanna offensichtliche Vorteile in Bezug auf Benutzerfreundlichkeit und Effektivität. Anfängern wird empfohlen, die Verwendung von Tabellenstrukturen zum Trainieren von Daten zu bevorzugen und die Konfiguration des Sprachmodells an die tatsächlichen Bedürfnisse anzupassen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...