Informationssilos durchbrechen: Dify fügt dem lokalisierten KI-Assistenten DeepSeek eine vernetzte Suche hinzu

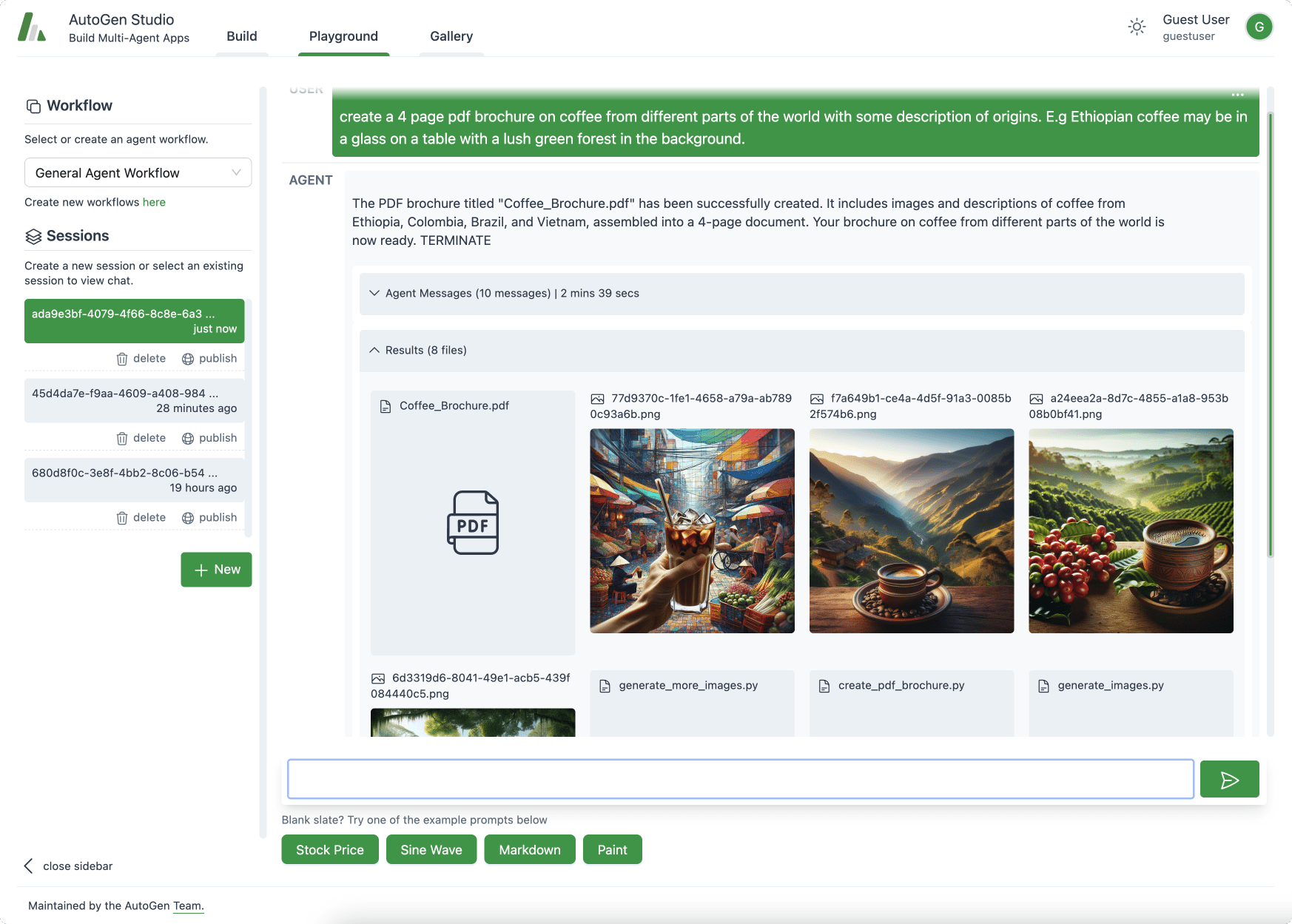
Stellen Sie sich vor, wie es wäre, eine private KI-Anwendung zu haben, die in sich geschlossen und vertraulich ist und die in der Lage ist, lokale Texte zu analysieren, jederzeit genaue Gespräche zu führen und über das Internet zu suchen. In diesem Artikel führen wir Sie Schritt für Schritt durch den Prozess der Erstellung einer solchen Anwendung. DeepSeek + Ollama + Dify Der KI-Assistent ist ein voll funktionsfähiger, privater KI-Assistent, der schnell eingesetzt werden kann.
DeepSeek Es handelt sich um ein bahnbrechendes Open-Source-Modell für große Sprachen, dessen fortschrittliche algorithmische Architektur und die Fähigkeit der "reflektierenden Kette" die KI-Dialoginteraktion intelligenter und natürlicher machen. Mit der privaten Bereitstellung können Sie die Sicherheit Ihrer Daten vollständig kontrollieren und den Bereitstellungsplan flexibel an Ihre Bedürfnisse anpassen, indem Sie Ihre eigene "AI-Betriebssystem" .
Dify Als dieselbe Open-Source-Plattform für die Entwicklung von KI-Anwendungen bietet sie auch eine vollständige Lösung für die private Bereitstellung und eine leistungsstarke Unterstützung von Drittanbieter-Tools. Beinhaltet Netzwerksuche, Dokumentenanalysefunktionen usw. Dify unterstützt über 1000 Open-Source- oder Closed-Source-Modelle aus der ganzen Welt). Gleichzeitig unterstützt Dify mehr als 1000 Open-Source- oder Closed-Source-Modelle aus der ganzen Welt, sodass Sie jedes Modell aufrufen können, um Ihre KI-Anwendungen zu unterstützen.
Die nahtlose Integration von DeepSeek in die Dify-Plattform stellt nicht nur den Datenschutz sicher, sondern erleichtert Entwicklern auch den Einstieg in die Erstellung leistungsstarker KI-Apps auf lokalen Servern, so dass Unternehmen oder Teams die Leistungsfähigkeit von DeepSeek voll ausschöpfen können. "Datenautonomie" und "flexible Anpassung" . Wenn Sie zwischenPrivater Einsatz von DeepSeek + Dify: Aufbau eines sicheren und kontrollierbaren lokalen KI-Assistenzsystems können Sie direkt zum Bereich Netzwerksuche springen.
Dify X DeepSeek Vorteile der privaten Bereitstellung:
- Rufen Sie 1000+ Modellmöglichkeiten auf: Dify ist eine modellneutrale Plattform, die die Inferenzfähigkeiten verschiedener großer Modelle in vollem Umfang nutzt (PS: kann über mehrere von Dify unterstützte dritte MaaS-Plattformen aufgerufen werden) DeepSeek R1 Modell, um das Problem der instabilen offiziellen API-Aufrufe zu lösen (siehe das Ende der detaillierten Konfigurationsmethode)
- Ausgezeichnete Leistung: Ein Dialogerlebnis, das mit einem Geschäftsmodell vergleichbar ist, das eine Vielzahl komplexer Szenarien problemlos bewältigt.
- Isolierung der Umwelt: Läuft vollständig offline, so dass kein Risiko eines Datenverlusts besteht.
- Daten können kontrolliert werden: Sie haben die volle Kontrolle über die Daten und erfüllen die Anforderungen der Branche.
 Vorab-PositionierungErwerben Sie einen Server (VPS oder VDS), der die folgenden Bedingungen erfüllt:Hardware-Umgebung:
Vorab-PositionierungErwerben Sie einen Server (VPS oder VDS), der die folgenden Bedingungen erfüllt:Hardware-Umgebung:
- CPU >= 2 Kerne
- Videospeicher/RAM ≥ 16 GiB (empfohlen)
Software-Umgebung:
- Docker
- Docker Compose
- Ollama
- Dify Gemeinschaftsausgabe
Start des Einsatzes 1. Ollama installieren
So wie Mobiltelefone in der Regel über einen App-Shop verfügen, der das schnelle Auffinden und Herunterladen von Apps ermöglicht, haben auch KI-Modelle ihren eigenen "App-Shop".
Ollama ist ein plattformübergreifender Open-Source-Client für die Verwaltung großer Modelle (macOS, Windows, Linux), der entwickelt wurde, um große Sprachmodelle (LLMs) wie DeepSeek, Llama, Mistral und andere nahtlos einzusetzen.
Große Modelle können mit einem einzigen Befehl installiert und bereitgestellt werden. Alle LLM-Nutzungsdaten werden lokal auf dem Rechner gespeichert, so dass der Datenschutz und die Sicherheit zur Erfüllung von Compliance-Anforderungen gewährleistet sind.
Besuchen Sie die Ollama-Website (https://ollama.com/) und folgen Sie den Anweisungen auf der Website, um den Ollama-Client herunterzuladen und zu installieren. Nachdem die Installation abgeschlossen ist, führen Sie ollama -v im Terminal aus, um die Versionsnummer auszugeben.
~ ollama -v
ollama version is 0.5.5
Wählen Sie das geeignete DeepSeek-Modell für die Bereitstellung auf der Grundlage der tatsächlichen Umgebungskonfiguration. Für die Erstinstallation wird das Modell der Größe 7B empfohlen.
Das Suffix B gibt die Trainingsparameter des Modells an. Theoretisch gilt: Je höher der Parameter, desto besser ist die Leistung des Modells und desto mehr Grafikspeicher wird benötigt.
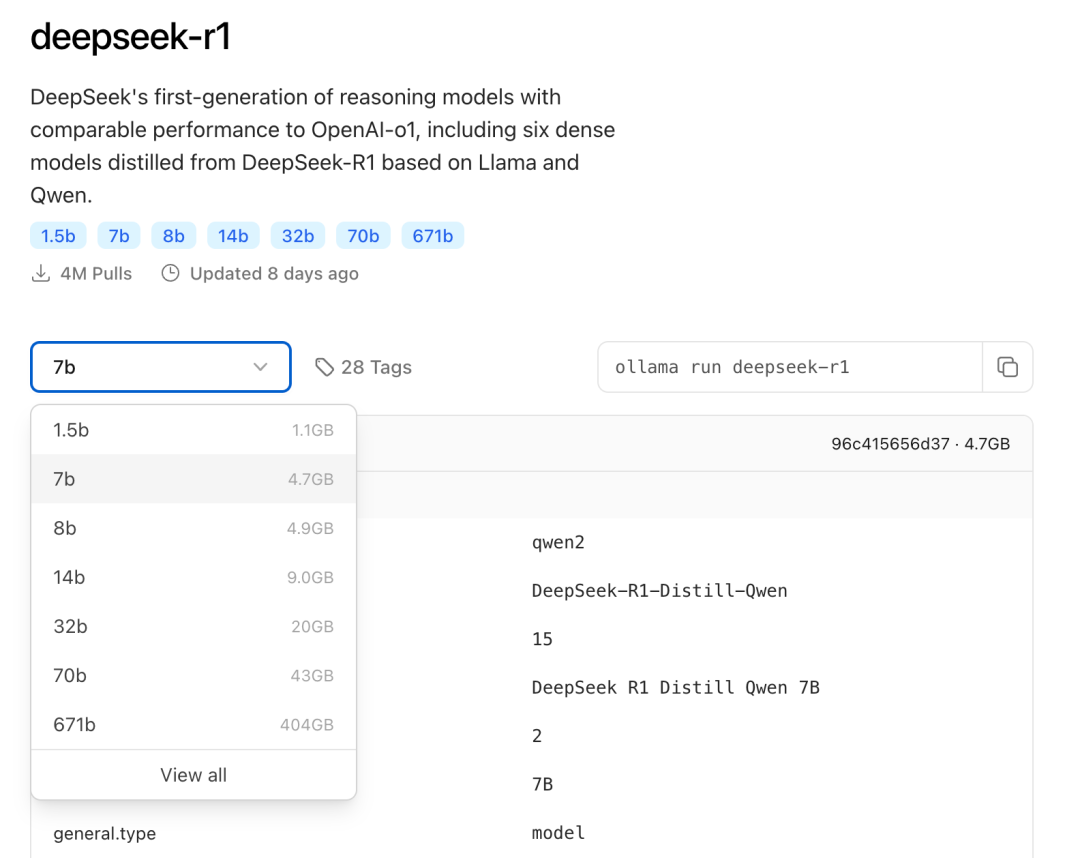
Befehl ausführen ollama run deepseek-r1:7b Installieren Sie das Modell DeepSeek R1. 
2. die Dify Community Edition installieren
Genauso wie ein Haus Sanitäranlagen und Strom braucht, braucht es auch eine voll funktionsfähige Küche, damit der Koch köstliche Speisen zubereiten kann, und hier kommt Dify ins Spiel. Als beliebtes Open-Source-Projekt auf GitHub verfügt Dify über eine eingebaute Toolchain, die die gesamte Bandbreite dessen abdeckt, was für die Entwicklung einer KI-App benötigt wird. Mit den leistungsstarken Modellierungsfunktionen von DeepSeek kann jeder schnell seine ideale KI-App erstellen, ohne komplexe Code-Kenntnisse haben zu müssen.
Besuchen Sie die GitHub-Projektadresse von Dify und führen Sie die folgenden Befehle aus, um das Ziehen des Code-Repositorys und den Installationsprozess abzuschließen.
git clone https://github.com/langgenius/dify.git
cd dify/docker
cp .env.example .env
docker compose up -d # 如果版本是 Docker Compose V1,使用以下命令:docker-compose up -d
Nach der Ausführung des Befehls gibt das Terminal automatisch den Status und die Port-Zuordnung aller Container aus. Falls es zu Unterbrechungen oder Fehlern kommt, stellen Sie bitte sicher, dass Docker und Docker Compose installiert sind.
Setzen Sie die Dify Community Edition ein:
https://docs.dify.ai/zh-hans/getting-started/install-self-hosted/docker-compose
Dify Community Edition verwendet standardmäßig Port 80, und Ihre privatisierte Dify-Plattform kann über einen Link zu http://your_server_ip erreicht werden.
Zum Umschalten von Zugangsports lesen Sie bitte dieses Dokument: https://docs.dify.ai/zh-hans/getting-started/install-self-hosted/faq#id-5.-ru-he-xiu-gai-ye-mian-duan-kou
3. die Verbindung zwischen DeepSeek und Dify
Nach der Bereitstellung des DeepSeek-Modells mit der Dify Community Edition klicken Sie auf den Link http://your_server_ip, um die Dify-Plattform zu betreten, und klicken Sie dann auf die obere rechte Ecke Avatar → Einstellungen → Modellanbieter Wählen Sie Ollama und tippen Sie auf Modell hinzufügen.
Wählen Sie den LLM-Modelltyp.
- Modellname, geben Sie den Modellnamen des eingesetzten Modells ein. Das oben eingesetzte Modell ist deepseek-r1 7b, geben Sie also ein: deepseek-r1:7b.
- Base URL, geben Sie die Adresse ein, unter der der Ollama-Client läuft, normalerweise http://your_server_ip:11434. Bei Verbindungsproblemen lesen Sie bitte die FAQ am Ende dieses Artikels.
- Alle anderen Optionen werden auf ihren Standardwerten belassen. Nach der DeepSeek-Modellbeschreibung beträgt die maximale Länge 32.768 Token.
Beginn der Entwicklung von KI-Anwendungen
In den folgenden Abschnitten erfahren Sie, wie Sie verschiedene Arten von KI-Anwendungen erstellen können:
- Einfache Dialoganwendung
- Einfache Dialoganwendungen mit Funktionen zur Dokumentenanalyse
- Programmierbare Anwendungen mit vernetzter Suche
DeepSeek AI Chatbot (einfache Anwendung)
- Tippen Sie auf "Create a Blank App" auf der linken Seite der Dify-Plattform-Startseite, wählen Sie den App-Typ "Chat Assistant" und geben Sie ihm einen einfachen Namen.
- Wählen Sie in der oberen rechten Ecke unter Anwendungstyp das Ollama-Framework innerhalb der
deepseek-r1:7bModelle.
- Überprüfen Sie, ob die KI-Anwendung funktioniert, indem Sie Inhalte in das Vorschaudialogfeld eingeben. Wenn Sie eine Antwort erhalten, bedeutet dies, dass die Erstellung der KI-Anwendung abgeschlossen ist.
- Tippen Sie auf die Schaltfläche Veröffentlichen oben rechts in der App, um einen Link zur KI-App zu erhalten und sie mit anderen zu teilen oder in eine andere Website einzubetten.
DeepSeek AI Chatbot + Wissensdatenbank
Eine große Herausforderung bei der Sprachmodellierung in großem Maßstab (LLM) besteht darin, dass die Trainingsdaten nicht in Echtzeit aktualisiert werden und die Datenmenge möglicherweise nicht ausreicht, was dazu führen kann, dass das Modell "Phantom"-Antworten erzeugt.
Um dieses Problem zu lösen, wurde die Retrieval Augmented Generation (RAG) Technologie entwickelt. Durch das Abrufen von relevantem Wissen und die Versorgung des Modells mit den erforderlichen Kontextinformationen werden diese Informationen in den Prozess der Inhaltsgenerierung einbezogen, wodurch die Genauigkeit und das Fachwissen der Antwort verbessert werden.
In der Praxis, wenn Sie interne Dokumente oder Fachinformationen hochladen, kann die Wissensdatenbankfunktion von Dify die Rolle von RAG eine Rolle dabei, LLM dabei zu helfen, gezieltere Antworten auf der Grundlage spezialisierter Informationen zu geben, was den Mangel an Modell-Trainingsdaten effektiv ausgleicht.
1. eine Wissensdatenbank erstellen
Laden Sie Dokumente in die Wissensdatenbank hoch, die von der KI analysiert werden sollen. Um sicherzustellen, dass das DeepSeek-Modell den Inhalt des Dokuments richtig versteht, wird empfohlen, den Text mit einem "Eltern-Kind-Segmentierungsmodell" zu verarbeiten - dieses Modell bewahrt die hierarchische Struktur und den Kontext des Dokuments besser.
Detaillierte Informationen zur Konfiguration finden Sie in diesem Dokument:
https://docs.dify.ai/zh-hans/guides/knowledge-base/create-knowledge-and-upload-documents
2. die Integration der Wissensbasis in KI-Anwendungen
Fügen Sie dem "Kontext" der KI-Anwendung eine Wissensdatenbank hinzu und geben Sie die entsprechende Frage in das Dialogfeld ein. lLM wird zunächst den für die Frage relevanten Kontext aus der Wissensdatenbank entnehmen, ihn dann zusammenfassen und eine qualitativ hochwertigere Antwort geben.
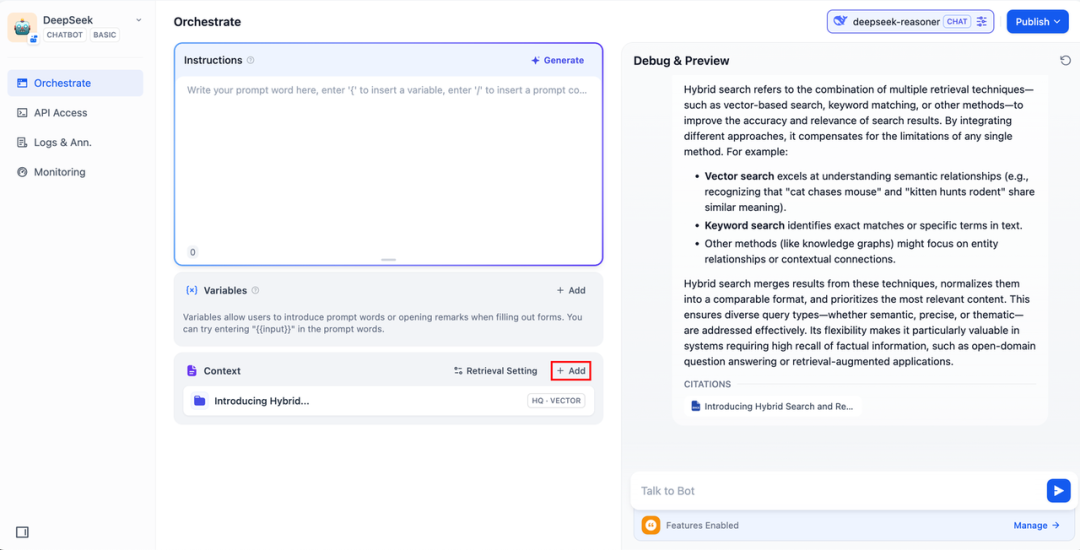
DeepSeek AI Chatflow / Workflow (vernetzte Suche)
Chatablauf / Arbeitsablauf Apps können Ihnen helfen, KI-Apps mit komplexeren Funktionen zu orchestrieren und zu erstellen, wie z. B. DeepSeek die Fähigkeit zu geben, eine vernetzte Suche, Datei- und Spracherkennung und mehr durchzuführen. Aus Platzgründen zeigen die folgenden Abschnitte, wie Sie DeepSeek mit Aktivieren von vernetzten Suchfunktionen .
Um die App direkt zu nutzen, können Sie die DSL-Datei über den unten stehenden Link herunterladen und in die Dify-Plattform importieren.
Adresse für das Herunterladen der DSL-Anwendungsdatei:
https://assets-docs.dify.ai/2025/02/41a3564694dd3f2803ad06a29f5b3fef.yml
- Tippen Sie auf "Create a Blank App" auf der linken Seite der Dify-Plattform-Startseite, wählen Sie eine App vom Typ "Chatflow" oder "Workflow" und benennen Sie sie einfach.
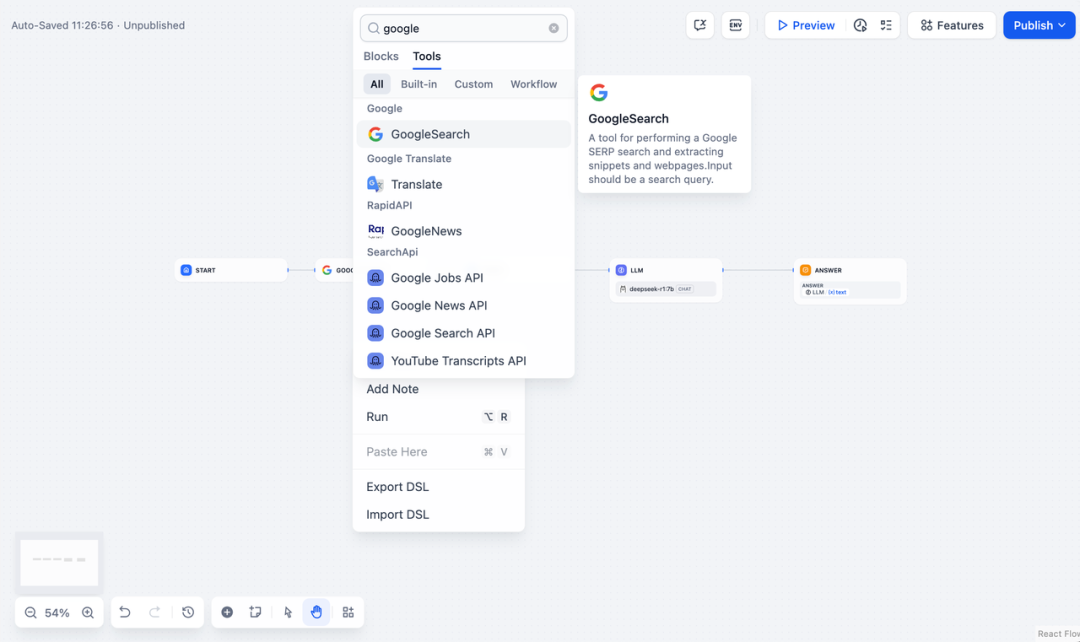
2. hinzufügenSuche im InternetKnoten, geben Sie den API-Schlüssel ein, um die Funktionalität des Knotens zu aktivieren. Geben Sie in das Feld Abfrage den API-Schlüssel ein, den der ursprüngliche Knoten liefert. {{#sys.query#}} Variablen.
Besuchen Sie die folgende Website, um einen API-Schlüssel zu erhalten:
https://serpapi.com/users/sign_in
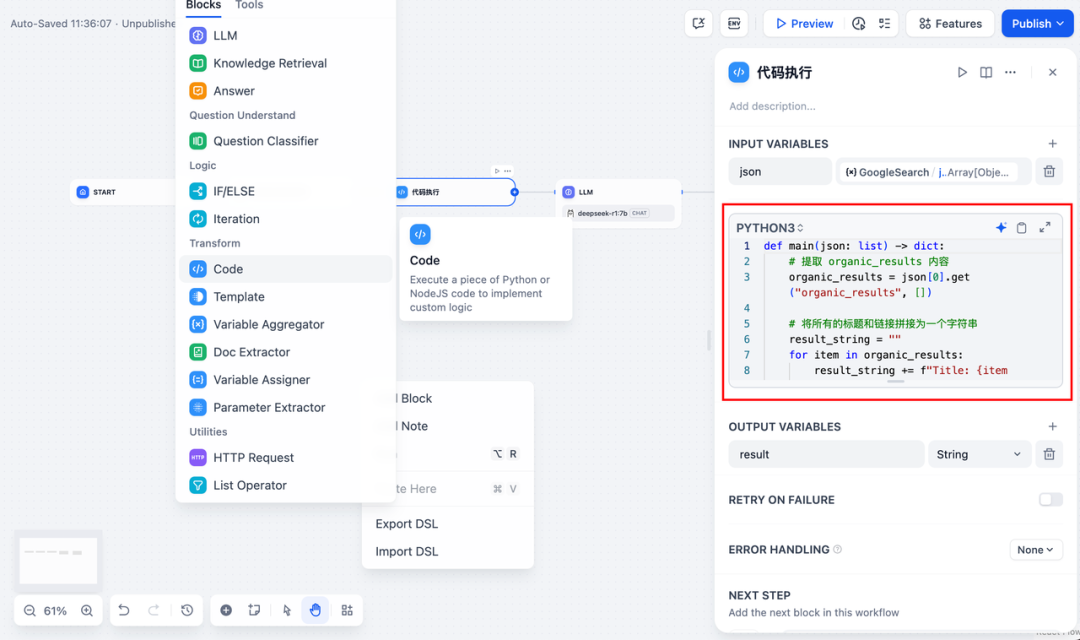
3. hinzufügenCode-AusführungKnoten. Da die Ausgabe des Suchwerkzeugs ein Stück JSON-Code ist, müssen Sie einen Codeausführungsknoten hinzufügen, um den erforderlichen Inhalt zu extrahieren. Füllen Sie die Eingabevariable mit der JSON-Ausgabevariable des Suchwerkzeugs und geben Sie den folgenden Code in den Codeausführungsknoten ein:
def main(json: list) -> dict:
# 提取 organic_results 内容
organic_results = json[0].get("organic_results", [])
# 将所有的标题和链接拼接为一个字符串
result_string = ""
for item in organic_results:
result_string += (
f"Title: {item['title']}\n"
f"Link: {item['link']}\n"
f"Snippet: {item['snippet']}\n\n"
)
# 返回拼接后的字符串作为 result
return {
"result": result_string,
}
- Um einen LLM-Knoten hinzuzufügen, wählen Sie das Ollama-Framework in der
deepseek-r1:7bModell und fügen Sie das Wort "System Prompt" innerhalb der{{#sys.query#}}um die vom Benutzer eingegebenen Befehle des Startknotens zu verarbeiten.
Im Falle von API-Anomalien können diese flexibel durch die Lastausgleichsfunktion oder den Ausnahmebehandlungsknoten behandelt werden.
LastausgleichAPI-Anfragen können auf mehrere API-Endpunkte verteilt werden, wie unter https://docs.dify.ai/zh-hans/guides/model-configuration/load-balancing im Detail beschrieben.
Mechanismus zur Behandlung von AusnahmenFähigkeit, im Falle von Knotenfehlern Fehlermeldungen auszugeben, ohne den Hauptprozess zu unterbrechen. Eine ausführliche Beschreibung finden Sie unter: https://docs.dify.ai/zh-hans/guides/workflow/error-handling
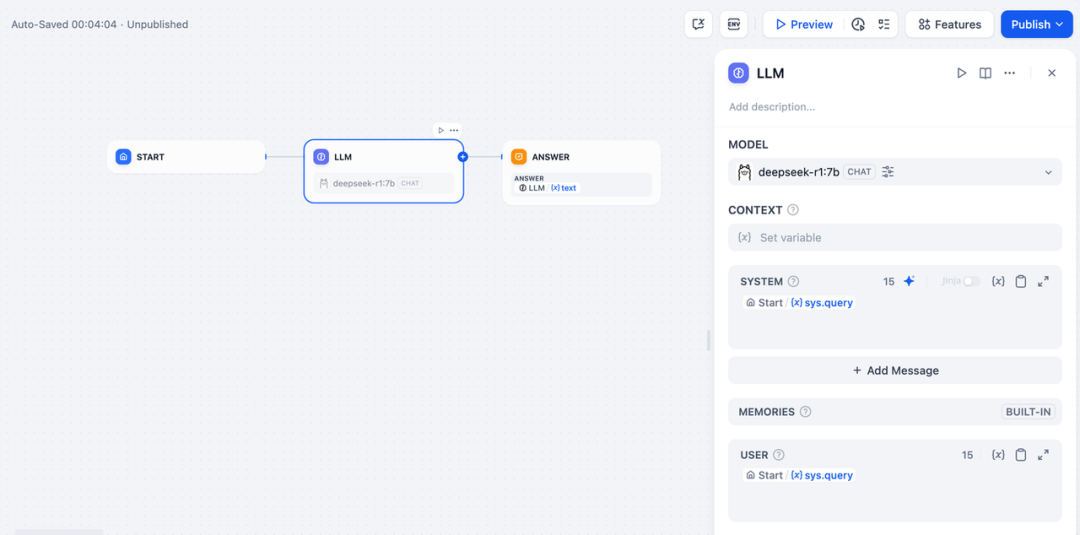
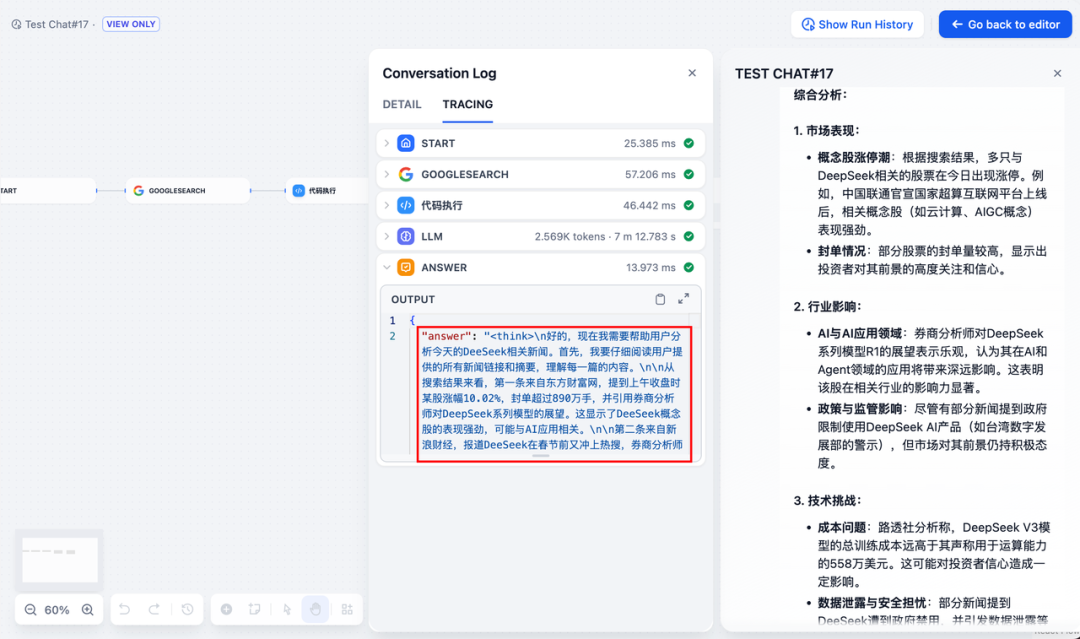
- Fügen Sie den Endknoten hinzu, verweisen Sie auf die Ausgangsvariablen des LLM-Knotens und schließen Sie die Konfiguration ab. Sie können zu Testzwecken Inhalte in das Vorschaufeld eingeben. Das Erzeugen einer Antwort bedeutet, dass die Erstellung der KI-Anwendung abgeschlossen ist und Sie den LLM-Schlussfolgernden Prozess im Protokoll sehen können.
allgemeine Probleme
1) Verbindungsfehler bei der Docker-Bereitstellung
Die folgenden Fehler können bei der Bereitstellung von Dify und Ollama mit Docker auftreten:
HTTPConnectionPool(host=127.0.0.1, port=11434): Max retries exceeded with URL: /cpi/chat
(Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7f8562812c20>:
Failed to establish a new connection: [Errno 111] Connection refused'))
HTTPConnectionPool(host=localhost, port=11434): Max retries exceeded with URL: /cpi/chat
(Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7f8562812c20>:
Failed to establish a new connection: [Errno 111] Connection refused'))
Fehlerursache: Dieser Fehler tritt auf, weil der Ollama-Dienst im Docker-Container nicht zugänglich ist. localhost zeigt normalerweise auf den Container selbst, nicht auf den Host oder einen anderen Container. Um dieses Problem zu beheben, müssen Sie den Ollama-Dienst für das Netzwerk freigeben.
macOS-Umgebungskonfigurationsmethode:
Wenn Ollama als macOS-Anwendung läuft, müssen Sie die Umgebungsvariablen mit launchctl setzen:
- Setzen Sie die Umgebungsvariablen, indem Sie launchctl setenv aufrufen:
launchctl setenv OLLAMA_HOST "0.0.0.0" - Starten Sie die Ollama-Anwendung neu.
- Wenn die obigen Schritte nicht funktionieren, können Sie die folgende Methode verwenden: Das Problem ist, dass Sie sich innerhalb von Docker mit host.docker.internal verbinden müssen, um auf den Host von Docker zuzugreifen, daher funktioniert das Ersetzen von localhost durch host.docker.internal: http://host. docker.internal:11434
Methode zur Konfiguration der Linux-Umgebung: Wenn Ollama als systemd-Dienst ausgeführt wird, sollten Sie die s ystemctl Setzen von Umgebungsvariablen:
- Durch den Aufruf der
systemctl edit ollama.serviceBearbeiten Sie den systemd-Dienst. Dadurch wird ein Editor geöffnet. - Für jede Umgebungsvariable wird die
[Service]Fügen Sie eine Zeile unter dem AbschnittEnvironment::[Service] Environment="OLLAMA_HOST=0.0.0.0" - Speichern und beenden.
- Laden Sie systemd neu und starten Sie Ollama neu:
systemctl daemon-reload systemctl restart ollama
Methode zur Konfiguration der Windows-Umgebung:
Unter Windows erbt Ollama Ihre Benutzer- und Systemumgebungsvariablen.
- Klicken Sie zunächst auf Ollama in der Taskleiste, um das Programm zu beenden.
- Systemumgebungsvariablen über die Systemsteuerung bearbeiten
- Bearbeiten oder erstellen Sie neue Variablen für Ihr Benutzerkonto, z. B.
OLLAMA_HOSTundOLLAMA_MODELSusw. - Klicken Sie zum Speichern auf OK / Übernehmen
- In einem neuen Terminalfenster ausführen
ollama
2) Wie ändere ich die Adresse und die Portnummer des Ollama-Dienstes?
Ollama Standard-Bindung 127.0.0.1 Port 11434, auf den Sie über den OLLAMA_HOST Umgebungsvariablen ändern die Bindungsadresse.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...