Tongyi Wanxiang Video-Upgrade, gekrönt VBench, Video-Unterstützung für die Erzeugung von Chinesisch, Objektiv Textur Ziehen voll
Das Jahr 2025 hat gerade erst begonnen und die KI-Videogeneration steht vor einem technologischen Durchbruch?
Heute Morgen kündigte Ali's Tongyi Wanphase Video Generation Model ein umfangreiches Upgrade auf Version 2.1 an.
Es gibt zwei Versionen des neuen Modells, und zwarTomix 2.1 Extreme und Professional, wobei ersteres auf hohe Leistung und letzteres auf hohe Ausdruckskraft abzielt..
Der Einführung zufolge hat Tongyi Wanxiang die Gesamtleistung des Modells dieses Mal umfassend verbessert, insbesondere bei der Verarbeitung komplexer Bewegungen, der Wiederherstellung der realen physikalischen Gesetze, der Verbesserung der Filmtextur und der Optimierung der zu befolgenden Anweisungen, was eine neue Tür für die künstlerische Gestaltung der KI öffnet.
Werfen wir einen Blick auf den Effekt der Videogenerierung und sehen wir, ob er Sie verblüffen kann.
Beginnen wir zum Beispiel mit dem klassischen "Steak Cut": Die Maserung des Steaks ist deutlich zu erkennen, die Oberfläche ist mit einer dünnen, glitzernden Fettschicht überzogen, und die Klinge schneidet langsam an den Muskelfasern entlang, das Fleisch ist Q-förmig und voll von Details. 
Prompt: In einem Restaurant schneidet ein Mann ein dampfend heißes Steak. In einer Nahaufnahme von oben hält der Mann ein scharfes Messer in der rechten Hand, setzt das Messer auf das Steak und schneidet in der Mitte des Steaks entlang. Die Person ist schwarz gekleidet und trägt weißen Nagellack an den Händen. Der Hintergrund ist ein Bokeh mit einem weißen Teller mit gelben Speisen und einem braunen Tisch.
Der Gesichtsausdruck des kleinen Mädchens, die Hand- und Körperbewegungen sind natürlich und koordiniert, und auch der Wind, der durch das Haar fegt, entspricht den Gesetzen der Bewegung.

Aufforderung:Niedliches junges Mädchen, das in einem Blumenbusch steht und seine Hände mit ihrem Herzen vergleicht, während alle möglichen kleinen Herzen um sie herum tanzen. Sie trägt ein rosa Kleid, ihr langes Haar weht im Wind und sie hat ein süßes Lächeln. Der Hintergrund ist ein Frühlingsgarten mit Blumen in voller Blüte und hellem Sonnenschein. HD realistische Fotografie, Nahaufnahme Nahaufnahme, weiches natürliches Licht.
Ist das Modell stark genug, um eine weitere Bewertung durchzuführen. Im VBench Leaderboard, der maßgeblichen Liste für die Bewertung von Videogeneratoren, wird dasDas aufgerüstete Tongyi Wanxiang steht mit einer Gesamtpunktzahl von 84,7% an der Spitze der Liste und übertrifft damit in- und ausländische Modelle der Videogeneration wie Gen3, Pika und CausVid... Es sieht so aus, als ob die Wettbewerbslandschaft für die Videoerstellung eine weitere Welle der Veränderung erlebt hat.
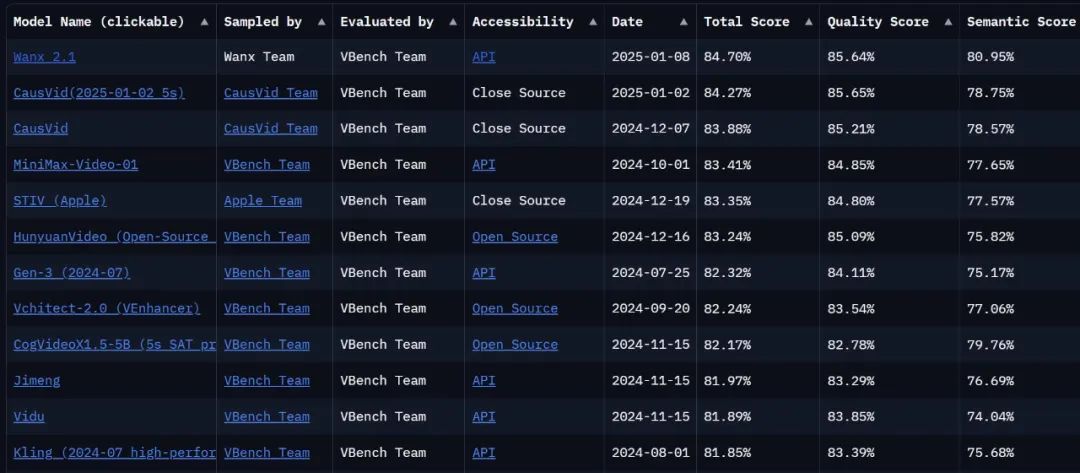
Link zur Liste: https://huggingface.co/spaces/Vchitect/VBench_Leaderboard
Von nun an können die Nutzer die neueste Generation von Modellen auf der Tongyi Wanxiang Website nutzen. Ebenso können Entwickler die große Modell-API in AliCloud Bai Lian aufrufen.
Offizielle Website-Adresse: https://tongyi.aliyun.com/wanxiang/
Erfahrung aus erster HandErhöhte Ausdruckskraft und die Möglichkeit, mit Spezialeffekt-Schriften zu spielen
In jüngster Zeit hat es eine schnelle Rate der Iteration von großen Modellen für die Video-Generierung, hat die neue Version von Tongyi Wanxiang erreicht eine Generation Ebene der Verbesserung? Wir haben einige Praxistests durchgeführt.
AI-Video kann jetzt schreiben.
Erstens können sich KI-generierte Videos endlich vom "Ghostwriting" verabschieden.
Bisher waren die gängigen KI-Videogenerierungsmodelle auf dem Markt nicht in der Lage, Chinesisch und Englisch korrekt zu generieren, solange die Stelle, an der der Text stehen sollte, ein Haufen unlesbaren Mülls ist. Jetzt wurde dieses Branchenproblem von Tongyi Wanxiang 2.1 gelöst.
Es wurdeDas erste Videogenerierungsmodell mit der Fähigkeit, chinesischen Text zu generieren und sowohl englische als auch chinesische Texteffekte zu unterstützen..
Die Nutzer können nun durch die Eingabe einer kurzen Textbeschreibung Texte und Animationen mit filmischen Effekten erzeugen.
Zum Beispiel tippt ein Kätzchen vor einem Computer, und auf dem Bildschirm erscheinen sieben große Worte "Work or Eat".

In dem von Tongyi Wanxiang erstellten Video sitzt die Katze am Arbeitsplatz und spielt ernsthaft mit der Tastatur und der Maus, die wie eine zeitgenössische Schreibmaschine aussehen, und die aufpoppenden Untertitel in Verbindung mit dem automatisch generierten Soundtrack verleihen dem Ganzen eine witzige Note.
Dann gibt es noch das englische Wort "Synced", das aus einem kleinen orangefarbenen, quadratischen Kästchen hervorlugt.

Ob auf Chinesisch oder Englisch, Tongyi Wanxiang macht es richtig, ohne Tippfehler oder "Ghostwriting".
Darüber hinaus unterstützt es die Anwendung von Schriftarten in einer Vielzahl von Szenarien, dieDazu gehören Schriften mit Spezialeffekten, Posterschriften und Schriften, die in realen Szenarien angezeigt werden..
In der Nähe des Eiffelturms am Ufer der Seine zum Beispiel blüht ein brillantes Feuerwerk in der Luft auf, und während die Kamera sich nähert, wird die rosafarbene Zahl "2025" immer größer, bis sie das gesamte Bild ausfüllt.

Kräftige Bewegung ist nicht mehr "gruselig"
In der Vergangenheit hatten die von der KI generierten Videos entweder fliegende Hände und Füße, verwandelten sich in eine lebende Person oder zeigten bizarre Bewegungen, bei denen sie sich nur umdrehten, aber nicht den Kopf drehten. 
Durch fortschrittliche Algorithmusoptimierung und Datentraining ist Tongyi Wanxiang in der Lage, stabile und komplexe Bewegungen in einer Vielzahl von Szenarien zu erzeugen, insbesondere im Hinblick auf großflächige Gliedmaßenbewegungen und präzise Gliedmaßenrotation.
Andererseits sind die Bewegungen des Mannes in dem unten generierten Video fließend und natürlich, während er läuft, ohne dass die linken oder rechten Beine nicht zu unterscheiden oder verdreht sind. Und auch die Details kommen nicht zu kurz: Jedes Mal, wenn der Mann mit den Zehen den Boden berührt, hinterlässt er eine Spur und hebt den feinen Sand leicht an.

Aufforderung: Goldenes Sonnenlicht auf dem glitzernden Meer bei Sonnenuntergang, ein gut aussehender junger Mann läuft am Strand entlang, ruhige Kamerafahrt.
Die Kameraführung ist mit der eines Meisterfilmers vergleichbar.
Der große Regisseur Spielberg sagte einmal, dass das Geheimnis eines guten Films in der Sprache der Kamera liegt. Um atemberaubendes Filmmaterial zu produzieren, hassen es die Kameraleute, in den Himmel zu steigen und über die Mauern zu fliegen. 
Aber im Zeitalter der KI ist es viel einfacher, einen Film zu 'machen'.
Wir brauchen nur einen einfachen Textbefehl einzugeben, wie z. B. "Objektiv links", "Objektiv weiter", "Objektiv vorwärts" usw., und Tongyi Wanxiang wird in der Lage seinAutomatische Ausgabe eines angemessenen Videos entsprechend dem Hauptinhalt des Videos und den Anforderungen der Kamera..
Wir tippen Prompt: Rockband spielt auf dem Vorplatz, während die Kamera weiterfährt, konzentriert sie sich auf den Gitarristen in einer Lederjacke, dessen langes, wirres Haar im Takt schwingt. Die Finger des Gitarristen springen schnell über die Saiten, während der Rest der Band im Hintergrund ihr Bestes gibt.

ein vollständiges Bild von allem 2.1 Die Anweisungen wurden genau befolgt. Das Video beginnt mit dem Gitarristen und dem Schlagzeuger, die leidenschaftlich spielen. Während die Kamera langsam näher kommt, verschwimmt der Hintergrund und zoomt heraus, um die Haltung und die Handbewegungen des Gitarristen zu betonen.
Lange Textbefehle gehen nicht verloren
Damit KI-generierte Videos beeindruckend sind, sind präzise Textanweisungen unerlässlich.
Manchmal hat das große Modell jedoch ein begrenztes Gedächtnis, und wenn es mit Textbefehlen konfrontiert wird, die verschiedene Szenenwechsel, Charakterinteraktionen und komplexe Aktionen enthalten, neigt es dazu, den Überblick über die Details zu verlieren oder die logische Reihenfolge durcheinander zu bringen.
Der neue Tongyi Manxiang ist ein großer Schritt nach vorn, was die Befolgung langer Textanweisungen angeht.
Prompt: Ein Motorradfahrer rast mit halsbrecherischer Geschwindigkeit eine enge Stadtstraße entlang, um einer gewaltigen Explosion in einem nahe gelegenen Gebäude auszuweichen, während die Flammen heftig züngeln und einen hellen orangefarbenen Schimmer verbreiten und Trümmer und Metallsplitter durch die Luft fliegen, was das Chaos am Tatort noch vergrößert. Der dunkel gekleidete Fahrer, der sich über den Lenker beugt und ihn fest umklammert, sieht konzentriert aus, während er mit halsbrecherischer Geschwindigkeit vorwärts fährt, unbeeindruckt von dem Feuer, das hinter ihm wütet. Dichter schwarzer Rauch, den die Explosion hinterlassen hat, füllt die Luft und hüllt den Hintergrund in ein apokalyptisches Chaos. Doch der Fahrer bleibt unerbittlich und schlängelt sich mit Präzision und extremer Kinematographie, ultrafeinen Details, beeindruckendem 3D und kohärenter Action durch das Chaos.

In dieser langen Textbeschreibung oben sind die engen Straßen, die hellen Flammen, der dichte schwarze Rauch, die umherfliegenden Trümmer und die Reiter in dunkler Kleidung ...... alles Details, die Tongyi Manxiang eingefangen hat.
Tongyi Wanxiang verfügt auch über eine stärkere Fähigkeit, Konzepte zu kombinieren, um eine Vielzahl unterschiedlicher Ideen, Elemente oder Stile genau zu verstehen und sie zu völlig neuen Videoinhalten zusammenzufügen.
Das Bild eines alten Mannes im Anzug, der aus einem Ei schlüpft und mit großen Augen auf den weißhaarigen alten Mann in der Kamera starrt, ist ziemlich lustig, gepaart mit dem Gackern eines Hahns.

Spezialisiert auf Karikatur-Ölgemälde und andere Stile
Die neue Version von Tongyi Manphase erzeugt auch filmische Videobilder und bietet eine gute Unterstützung für verschiedene Kunststile, wie z. B. Cartoon, Kino-Farbe, 3D-Stil, Ölmalerei, klassischer Stil usw.
Sieh dir dieses niedliche kleine animierte 3D-Monster an, das auf einer Weinrebe steht und herumtanzt.

Aufforderung: Ein flauschiges, glückliches, kleines, grünes Titi-Monster steht auf einem Weinzweig und singt fröhlich, drehen Sie die Kamera gegen den Uhrzeigersinn.
Darüber hinaus unterstützt es verschiedene Seitenverhältnisse, darunter 1:1, 3:4, 4:3, 16:9 und 9:16, die sich besser an verschiedene Endgeräte wie Fernseher, Computer und Mobiltelefone anpassen lassen. 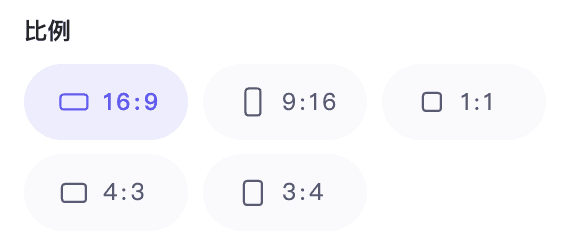
Ausgehend von der obigen Vorstellung können wir mit Tongyi Mansei bereits kreativ arbeiten, um Inspiration in "Realität" zu verwandeln.
Natürlich ist diese Reihe von Fortschritten auch auf AliClouds Upgrades im Basismodell der Videoerstellung zurückzuführen.
Basismodell deutlich optimiertStruktur, Ausbildung, Bewertung und umfassende "Umgestaltung".
Am 19. September letzten Jahres stellte AliCloud auf der Yunqi-Konferenz das Tongyi Wanphase Video Generation Model vor, das die Möglichkeit bietet, HD-Videos in Film- und Fernsehqualität zu erzeugen. Als ein vollständig selbst entwickeltes visuelles Generierungsmodell von AliCloud verwendet es Diffusion + Transformator Die Architektur unterstützt Aufgaben der Bild- und Videogenerierungsklasse und bietet branchenführende visuelle Generierungsfähigkeiten mit vielen Innovationen bei Modell-Frameworks, Trainingsdaten, Annotationsmethoden und Produktdesign.
In diesem verbesserten Modell hat das Team von Tongyi Wanxiang (nachstehend "das Team" genannt) außerdemSelbstentwickelte effiziente VAE- und DiT-Architekturendie für die Modellierung von räumlich-zeitlichen Kontextbeziehungen verbessert wurde, wodurch die Generierung erheblich optimiert wurde.
Flow Matching ist ein in den letzten Jahren aufkommender Rahmen für das Training generativer Modelle, der einfacher zu trainieren ist, eine vergleichbare oder sogar bessere Qualität als Diffusionsmodelle durch Continuous Normalising Flow erreicht und eine schnellere Inferenzgeschwindigkeit aufweist, und der allmählich auf den Bereich der Videogenerierung angewendet wird. Das bereits veröffentlichte Videomodell Movie Gen von Meta verwendet beispielsweise Flow Matching.
Für die Auswahl der Trainingsmethoden verwendet Tongyi Wanxiang 2.1 dieFlussanpassungsschema auf der Grundlage linearer Rauschtrajektorienund wurde eingehend für den Rahmen entwickelt, was zu einer verbesserten Modellkonvergenz, Generierungsqualität und Effizienz führt.

Tongyi Wanxiang 2.1 Diagramm der Videoerstellungsarchitektur
Für Video-VAE hat das Team ein innovatives Videocodec-Schema entwickelt, das Caching-Mechanismen und kausale Faltung kombiniert.. Unter anderem kann der Caching-Mechanismus die notwendigen Informationen bei der Videoverarbeitung aufrechterhalten und so die wiederholten Berechnungen reduzieren und die Recheneffizienz verbessern; die kausale Faltung kann die zeitlichen Merkmale des Videos erfassen und sich an die inkrementellen Änderungen des Videoinhalts anpassen.
Anstelle des direkten E2E-Dekodierungsprozesses für lange Videos ersetzt die Implementierung den direkten E2E-Dekodierungsprozess für lange Videos, indem sie das Video in Teile aufteilt und die Zwischenfunktionen zwischenspeichert, so dass die Nutzung der Grafikkarte nur von der Größe der Teile abhängt, unabhängig von der Länge des Originalvideos, so dass das Modell unbegrenzte Längen von 1080P-Videos effizient kodieren und dekodieren kann. Laut dem Team bietet diese Schlüsseltechnologie einen gangbaren Weg für das Training von Videos beliebiger Länge.
Die folgende Abbildung zeigt den Vergleich der Ergebnisse der verschiedenen VAE-Modelle. In Bezug auf die Berechnungseffizienz des Modells (Frame/Verzögerung) und die Rekonstruktion der Videokompression (Peak Signal to Noise Ratio, PSNR) erreicht die von Tongyi Wanxiang verwendete VAE immer noch die folgenden Ergebnisse, ohne dass die Parameter dominierenBranchenführende Videokomprimierung und Rekonstruktionsqualität.
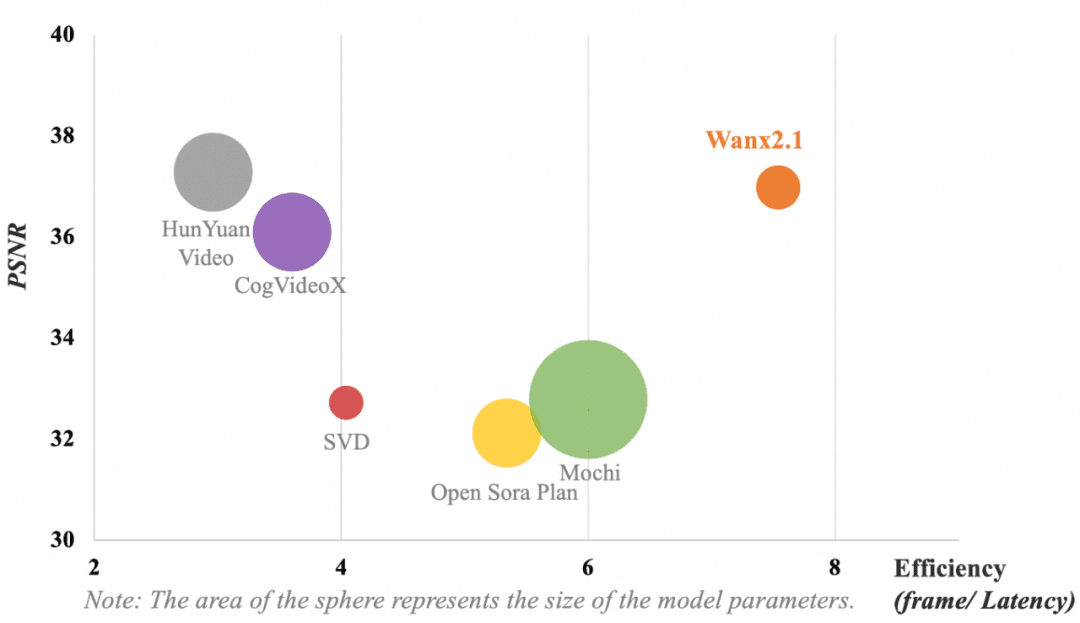
Hinweis: Die Kreisfläche stellt die Größe der Modellparameter dar.
Das Hauptziel des Teams bei der Entwicklung von DiT (Diffusion Transformer) war es, leistungsstarke räumlich-zeitliche Modellierungsfähigkeiten zu erreichen und gleichzeitig einen effizienten Trainingsprozess zu gewährleisten. Dies erforderte eine Reihe von innovativen Änderungen.
Erstens hat das Team zur Verbesserung der Modellierungsfähigkeit von räumlich-zeitlichen Beziehungen den Mechanismus der räumlich-zeitlichen vollen Aufmerksamkeit eingeführt, der es dem Modell ermöglicht, die komplexe Dynamik der realen Welt genauer zu simulieren. Zweitens werden durch die Einführung des Parameter-Sharing-Mechanismus die Trainingskosten effektiv reduziert und gleichzeitig die Leistung verbessert. Darüber hinaus optimierte das Team die Leistung bei der Texteinbettung, indem es den Cross-Attention-Mechanismus zur Einbettung von Textmerkmalen nutzte, wodurch eine bessere Textkontrollierbarkeit erreicht und der Rechenaufwand verringert wurde.
Dank dieser Verbesserungen und Versuche erreicht die DiT-Struktur der verallgemeinerten Universalphase eine deutlichere Konvergenzüberlegenheit bei gleichen Rechenkosten.
Zusätzlich zu den Innovationen in der Modellarchitektur hat das TeamEs wurden einige Optimierungen in den Bereichen Training und Inferenz für ultralange Sequenzen, Datenkonstruktionspipeline und Modellbewertung vorgenommen.Dadurch kann das Modell komplexe generative Aufgaben mit verbesserten Effizienzvorteilen effizient bewältigen.
Wie man mit Millionen von ultralangen Sequenzen effizient trainiert
Beim Umgang mit sehr langen visuellen Sequenzen stehen große Modelle oft vor Herausforderungen auf mehreren Ebenen, wie z. B. Rechenleistung, Speicherplatz, Trainingsstabilität und Inferenzlatenz, und benötigen daher effiziente Lösungen, um sie zu bewältigen.
Zu diesem Zweck kombinierte das Team die Charakteristika der neuen Modellauslastung und die Hardwareleistung des Trainingsclusters, um eine verteilte, speicheroptimierte Trainingsstrategie zu entwickeln, die die Trainingsleistung unter der Prämisse der Gewährleistung der Modelliterationzeit optimiert, und schließlichBranchenführende MFU und effizientes Training von 1 Million ultralanger Sequenzen.
Einerseits innoviert das Team die verteilte Strategie, indem es das parallele 4D-Training mit DP, FSDP, RingAttention und Ulysses einführt, was sowohl die Trainingsleistung als auch die verteilte Skalierbarkeit verbessert. Andererseits wendet das Team zur Speicheroptimierung eine hierarchische Speicheroptimierungsstrategie an, um den Aktivierungsspeicher zu optimieren und das Speicherfragmentierungsproblem auf der Grundlage des durch die Sequenzlänge verursachten Berechnungs- und Kommunikationsvolumens zu lösen.
Das Team verwendet FlashAttention3 für die räumlich-zeitliche Berechnung der vollen Aufmerksamkeit und wählt die geeignete CP-Strategie für die Partitionierung, indem es die Rechenleistung von Trainingsclustern unterschiedlicher Größe kombiniert. Gleichzeitig beseitigt das Team rechnerische Redundanz für einige Schlüsselmodule, reduziert den Zugriffs-Overhead und verbessert die rechnerische Effizienz durch eine effiziente Kernel-Implementierung. Im Hinblick auf das Dateisystem nutzt das Team die Lese-/Schreibeigenschaften des Hochleistungsdateisystems im AliCloud-Trainingscluster voll aus und verbessert die Lese-/Schreibleistung durch Slicing Save/Load.

4D Parallele verteilte Ausbildungsstrategie
Gleichzeitig entschied sich das Team für ein gestaffeltes Speichernutzungsschema, um die OOM-Probleme zu lösen, die durch Dataloader Prefetch, CPU Offloading und Save Checkpoint während des Trainings verursacht wurden. Um die Stabilität des Trainings zu gewährleisten, nutzte das Team außerdem die intelligente Planung, die Erkennung langsamer Maschinen und die Selbstheilungsfähigkeiten des AliCloud-Trainingsclusters, um fehlerhafte Knoten automatisch zu identifizieren und die Aufgabe schnell neu zu starten.
Einführung der Automatisierung bei der Datenerstellung und Modellbewertung
Große Modelle der Videogenerierung können nicht ohne qualitativ hochwertige Daten in großem Maßstab und eine effektive Modellbewertung trainiert werdenErsteres stellt sicher, dass das Modell verschiedene Szenarien und komplexe räumlich-zeitliche Abhängigkeiten lernt und die Generalisierung verbessert, was den Eckpfeiler der Modellschulung bildet; letzteres hilft, die Leistung des Modells zu überwachen, damit es die erwarteten Ergebnisse besser erreicht, und wird zur Wetterfahne der Modellschulung.
Für die Datenerstellung hat das Team eine automatische Datenerstellungspipeline mit hoher Qualität als Kriterium entwickelt, die in hohem Maße mit der menschlichen Präferenzverteilung in Bezug auf visuelle Qualität, Bewegungsqualität usw. übereinstimmt, so dass qualitativ hochwertige Videodaten mit hoher Vielfalt, ausgewogener Verteilung und anderen Merkmalen automatisch erstellt werden können.
Für die Modellbewertung entwickelte das Team ebenfalls eine umfassende Reihe automatischer Metriken, die mehr als zwei Dutzend Dimensionen wie ästhetische Bewertung, Bewegungsanalyse und Einhaltung von Befehlen umfassen, sowie gezielte und geschulte professionelle Bewerter, die in der Lage sind, sich an menschlichen Präferenzen zu orientieren. Dank des effektiven Feedbacks dieser Metriken konnte der Modell-Iterations- und Optimierungsprozess erheblich beschleunigt werden.
Man kann sagen, dass die synergetischen Innovationen in verschiedenen Aspekten wie Architektur, Schulung und Bewertung es dem aktualisierten Tongyi Wanphase-Videogenerationsmodell ermöglicht haben, signifikante Generationenverbesserungen in der Praxis zu erzielen.
GPT-3-Momente für die VideoerzeugungWie lange noch?
Seit Februar letzten Jahres ist OpenAIs Sora Seit seiner Einführung hat sich das Modell der Videoerstellung zum wettbewerbsintensivsten Bereich in der Welt der Technik entwickelt. Sowohl im Inland als auch in Übersee bringen Start-ups und Tech-Giganten ihre eigenen Tools zur Videoerstellung auf den Markt. Im Vergleich zur Texterstellung ist die Erstellung von KI-Videos jedoch mehr als eine Schwierigkeitsstufe, um den Grad der Akzeptanz zu erreichen.
Wenn, wie OpenAI-CEO Sam Altman sagt, Sora den GPT-1-Moment im großen Modell der Videogenerierung darstellt, dann können wir darauf aufbauen, um die präzise Steuerung von Textbefehlen und die Fähigkeit zu erreichen, Winkel und Kamerapositionen anzupassen, um die Konsistenz der Charaktere zu gewährleisten. Wenn wir auf dieser Grundlage aufbauen, um eine präzise Steuerung der KI mit Textbefehlen, einstellbaren Winkeln und Kamerapositionen sowie einer konsistenten Charakterisierung und anderen Videogenerierungsfunktionen zu erreichen, und die einzigartige Fähigkeit der KI hinzufügen, Stile und Szenen schnell zu ändern, könnten wir bald einen neuen "GPT-3-Moment" erleben.
Vom Standpunkt der technologischen Entwicklung aus betrachtet, ist das Modell der Videogenerierung ein Prozess der Überprüfung der Skalierungsgesetze. In dem Maße, wie sich die Fähigkeiten des Basismodells verbessern, wird die KI mehr und mehr menschliche Befehle verstehen und in der Lage sein, immer realistischere und angemessenere Umgebungen zu schaffen.
Aus praktischer Sicht können wir es gar nicht abwarten: Seit letztem Jahr haben Menschen in den Bereichen Kurzvideos, Animation und sogar Film und Fernsehen damit begonnen, KI zur Videogenerierung für kreative Erkundungen einzusetzen. Wenn es uns gelingt, die Grenzen der Realität zu durchbrechen und mit der KI der Videogeneration bisher unvorstellbare Dinge zu tun, steht eine neue Runde des industriellen Wandels vor der Tür.
Nun scheint Tongyi Manxiang den ersten Schritt getan zu haben.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...