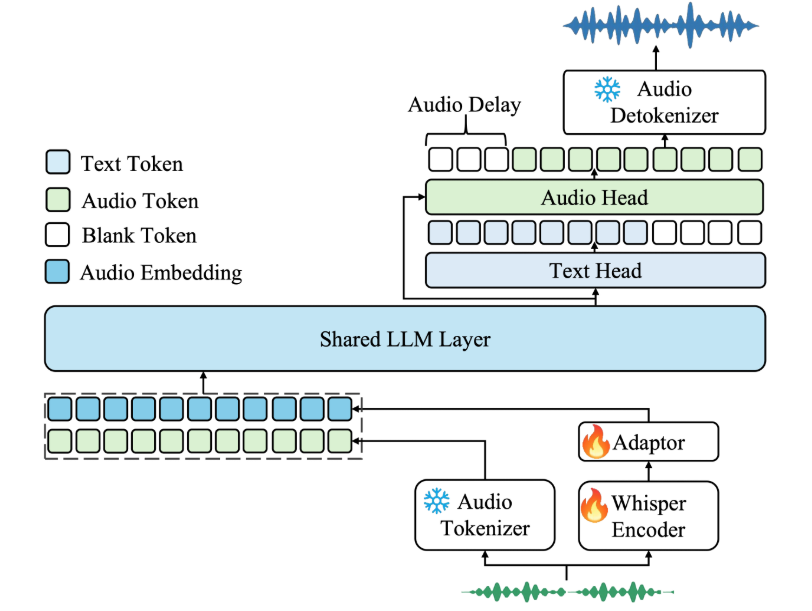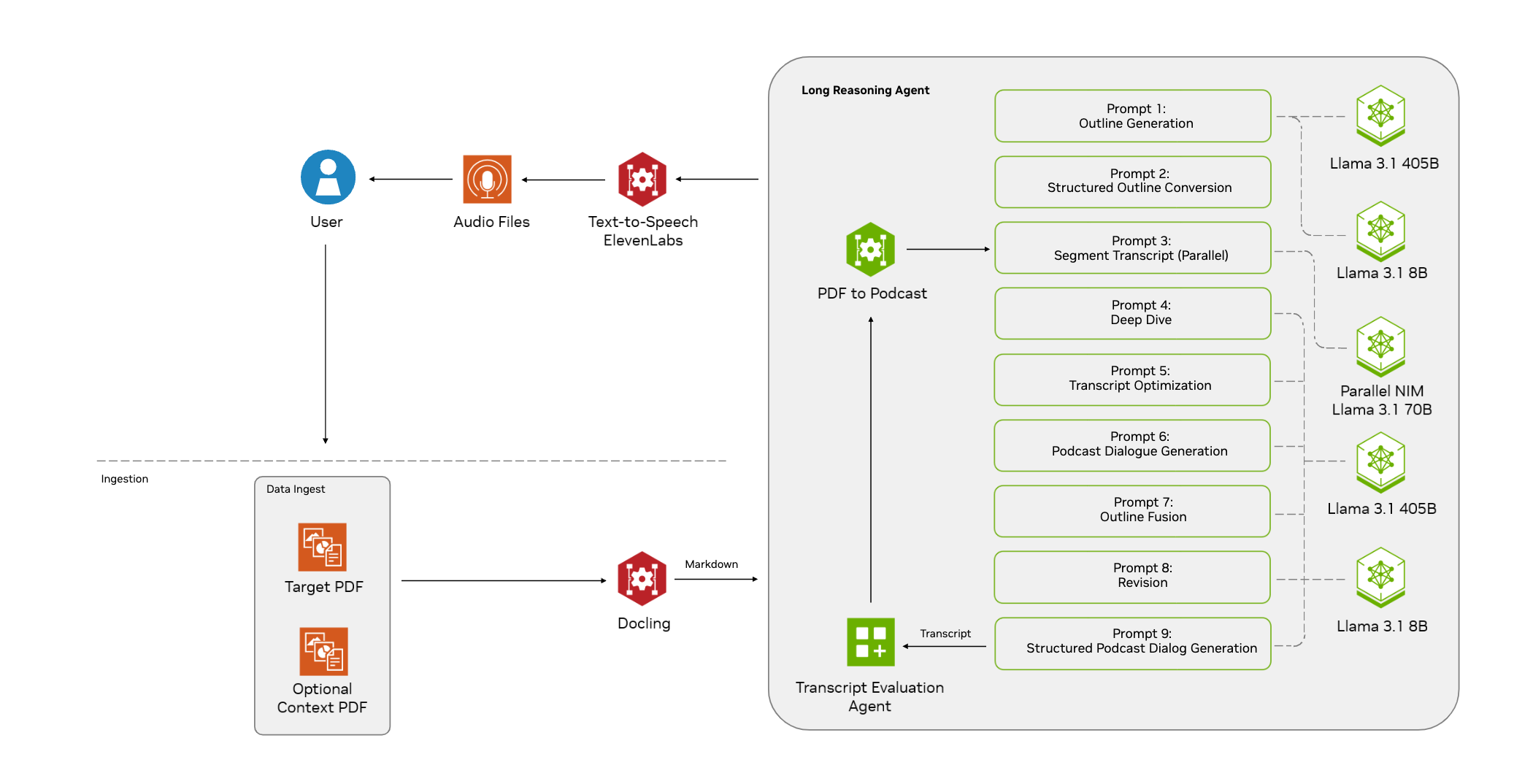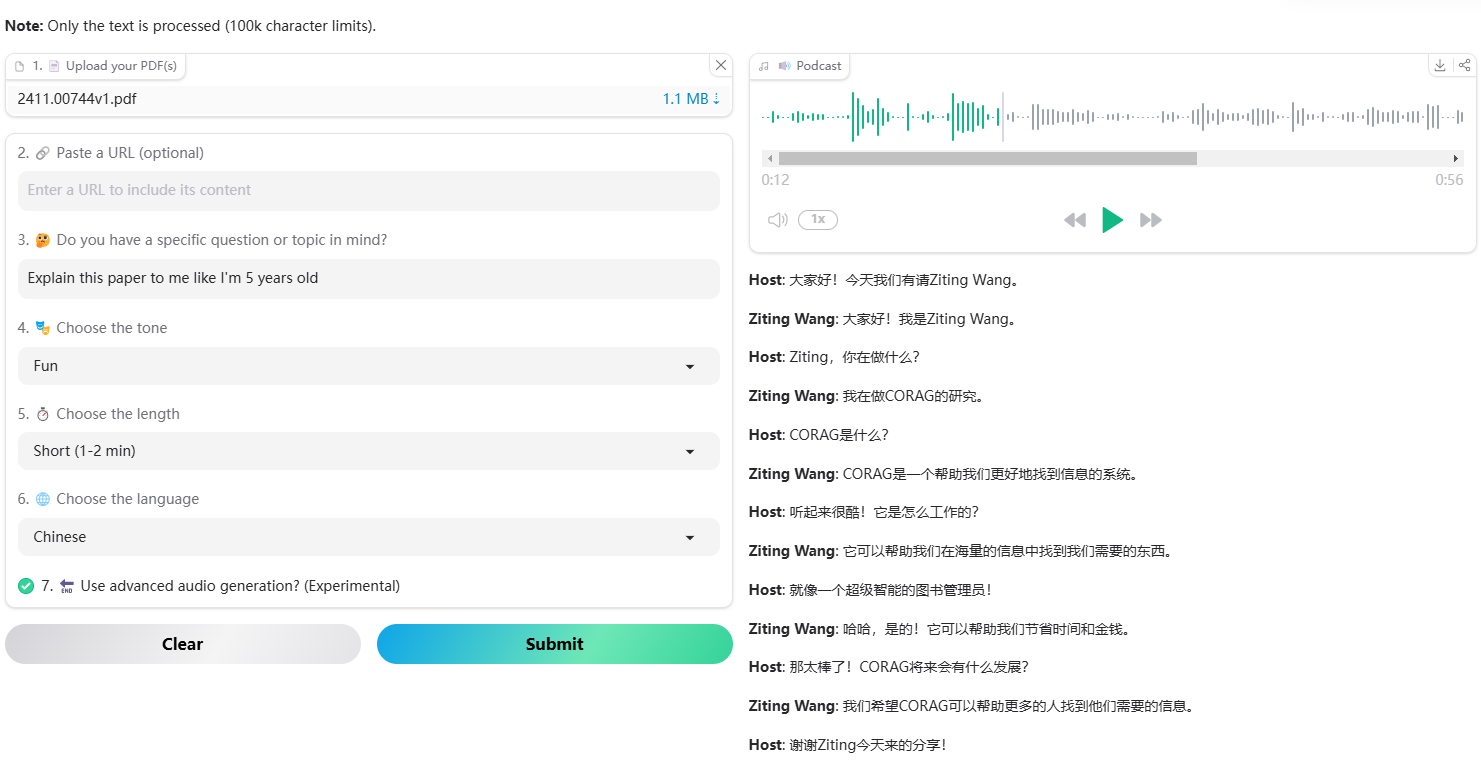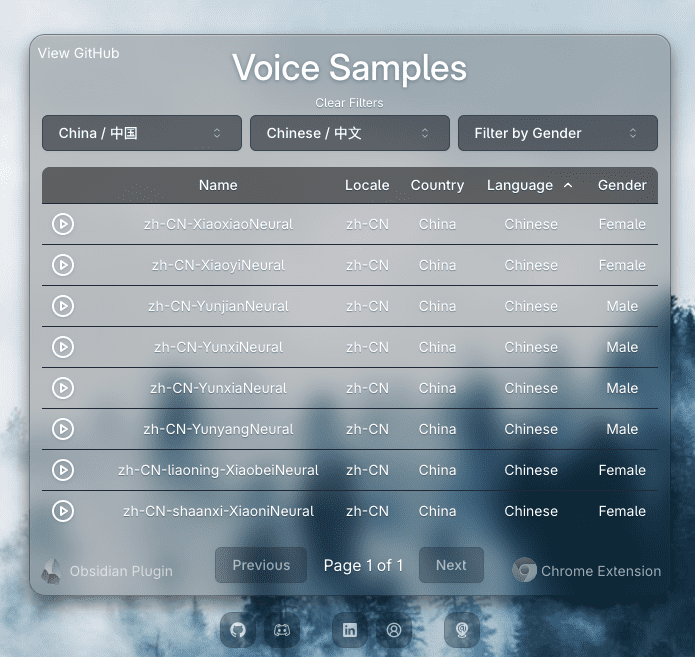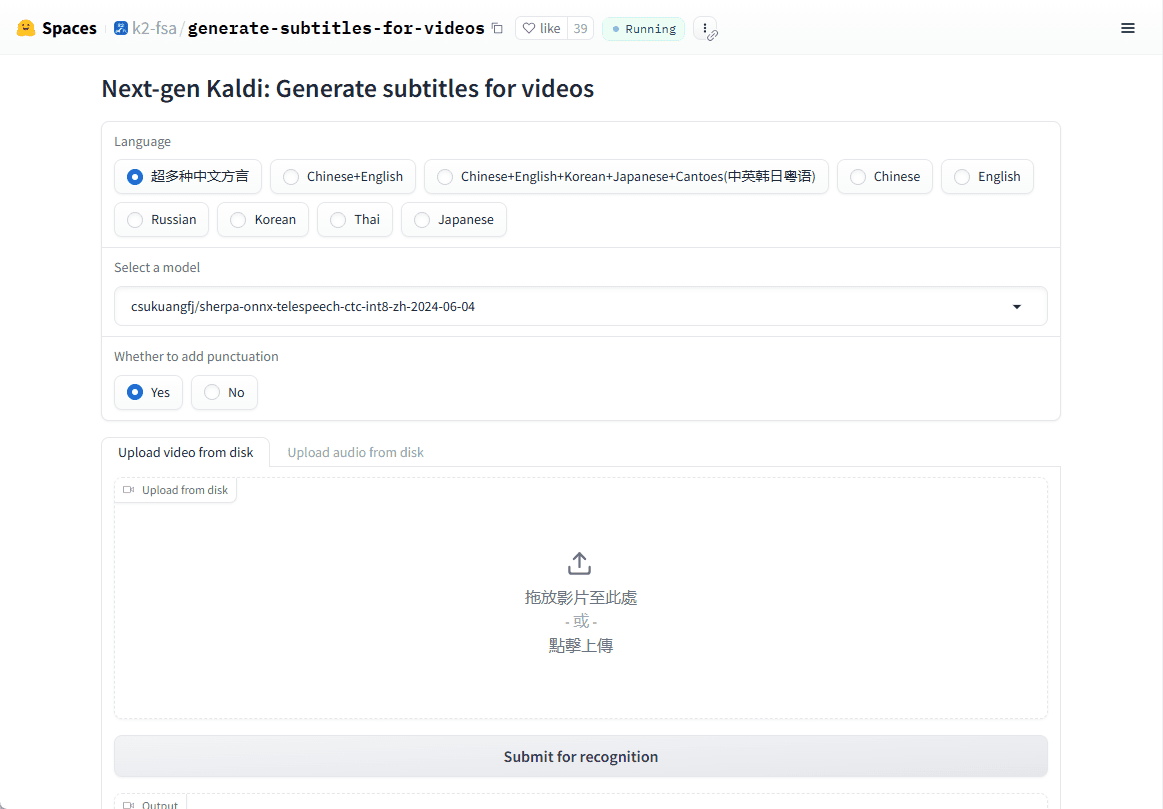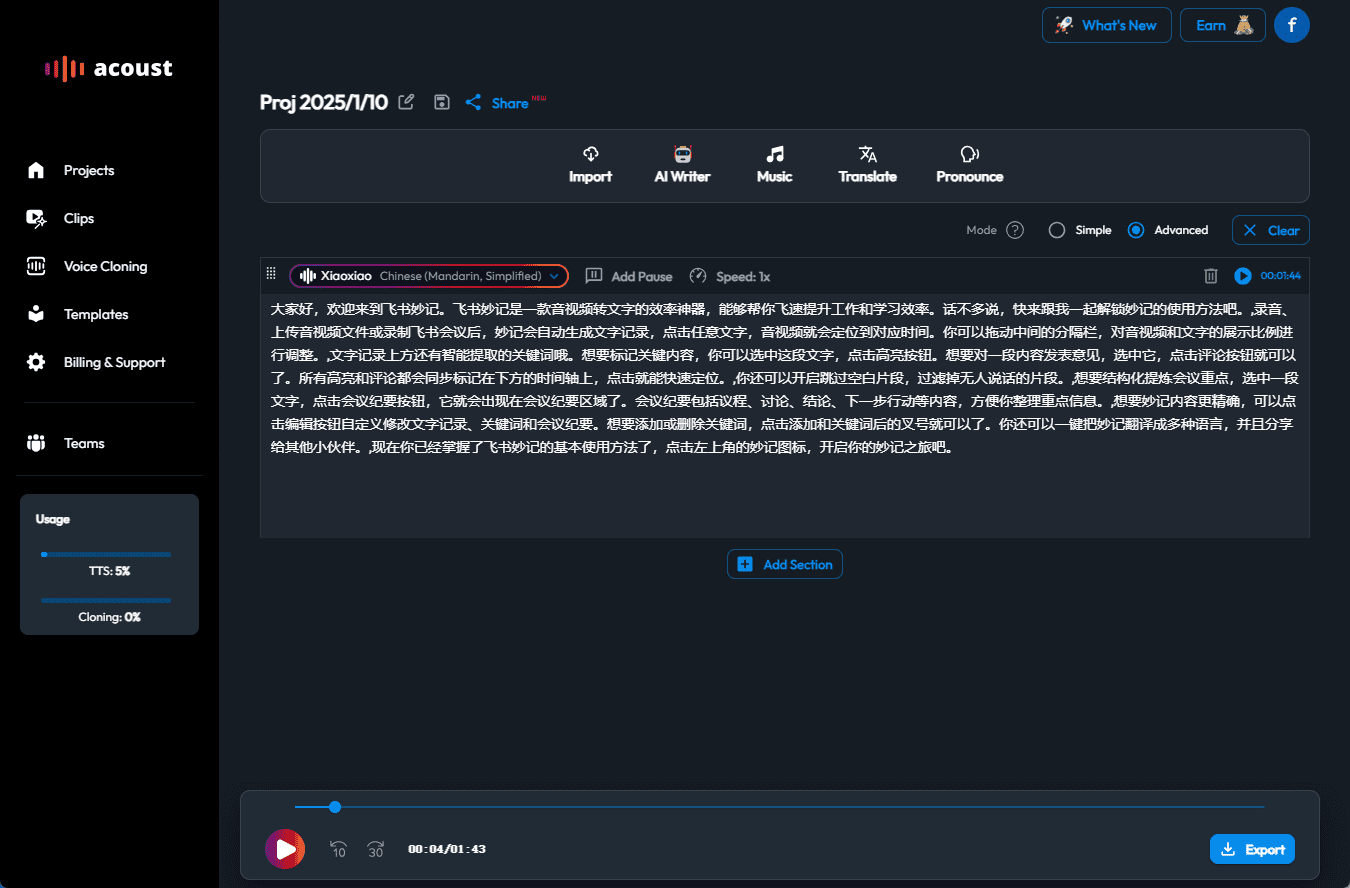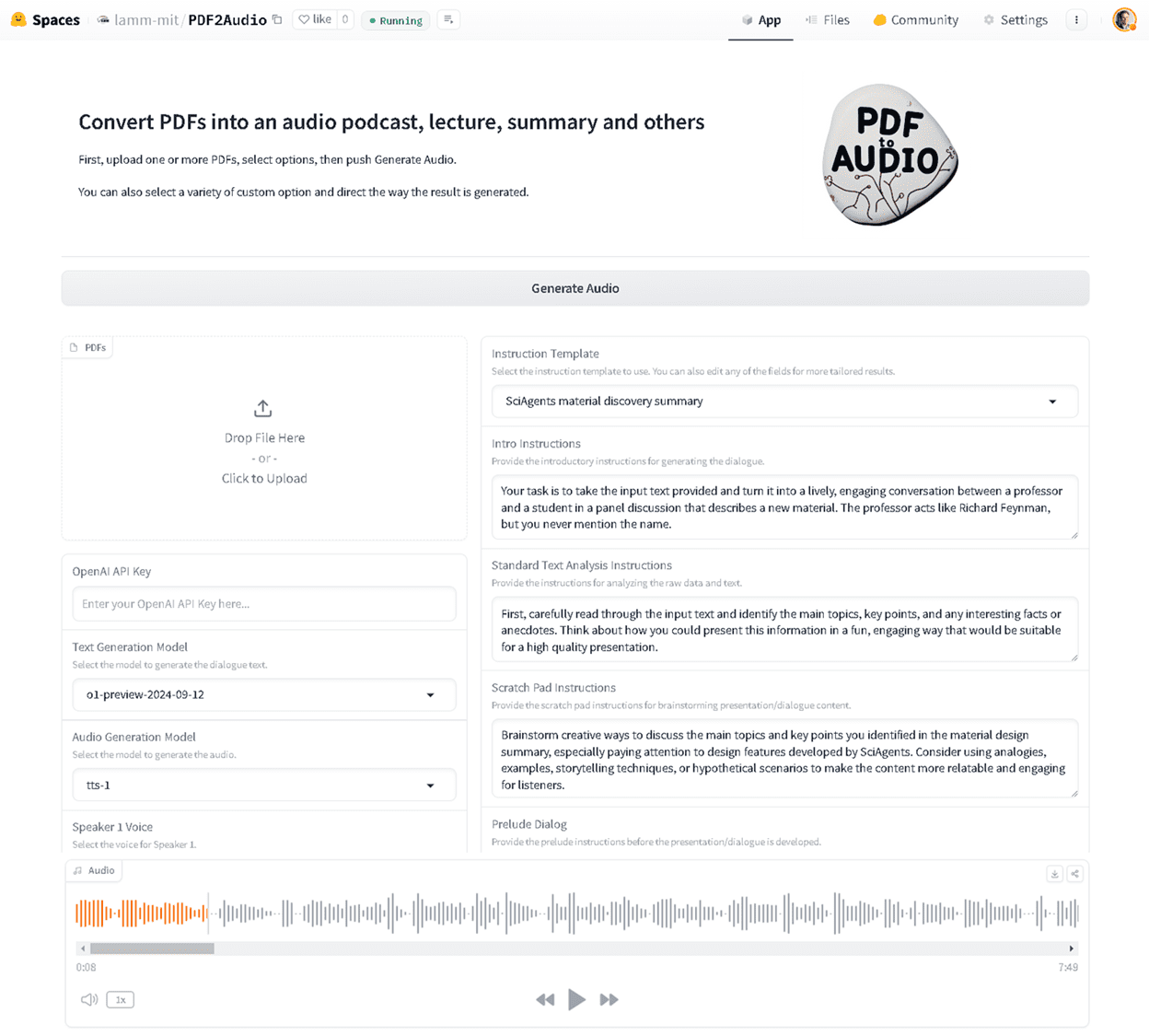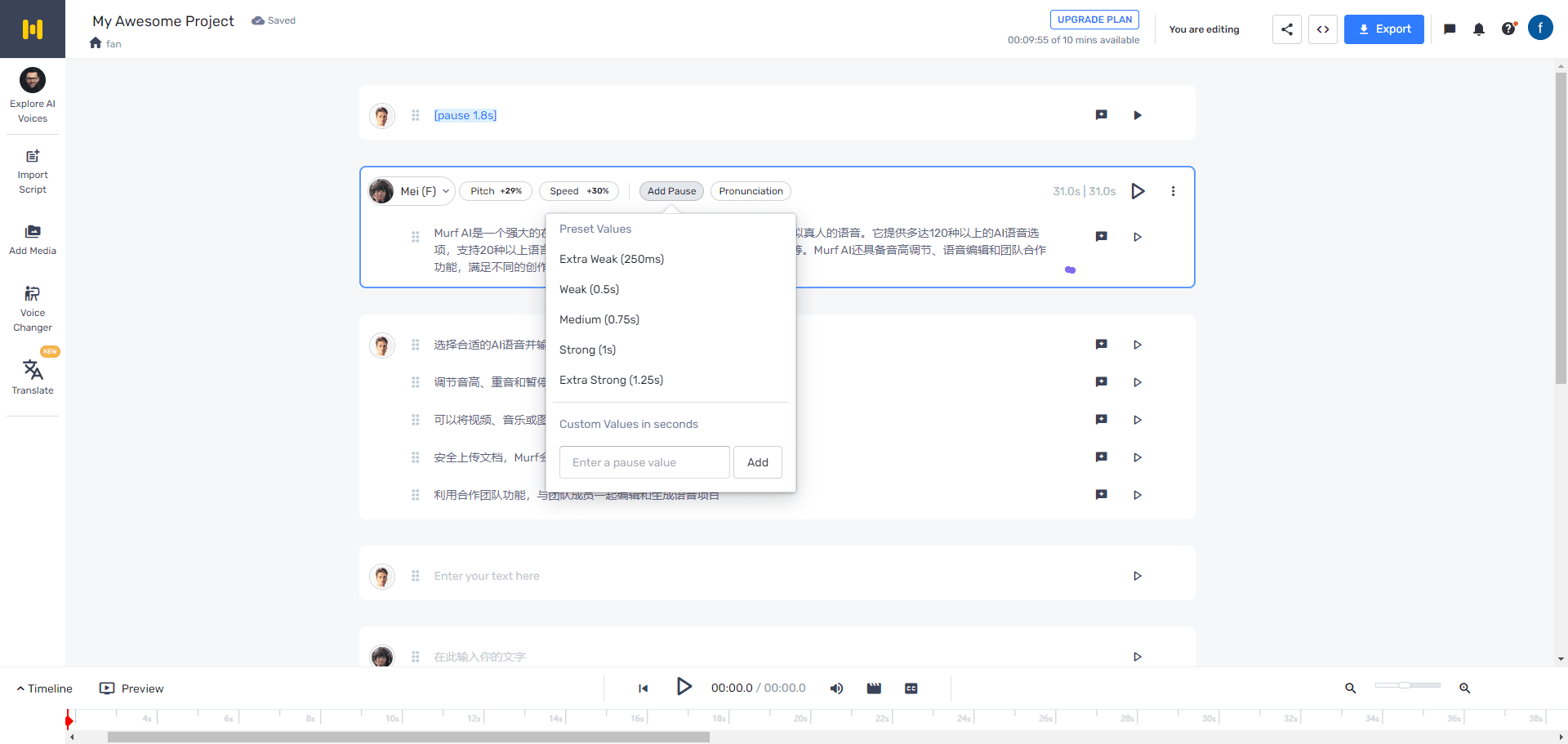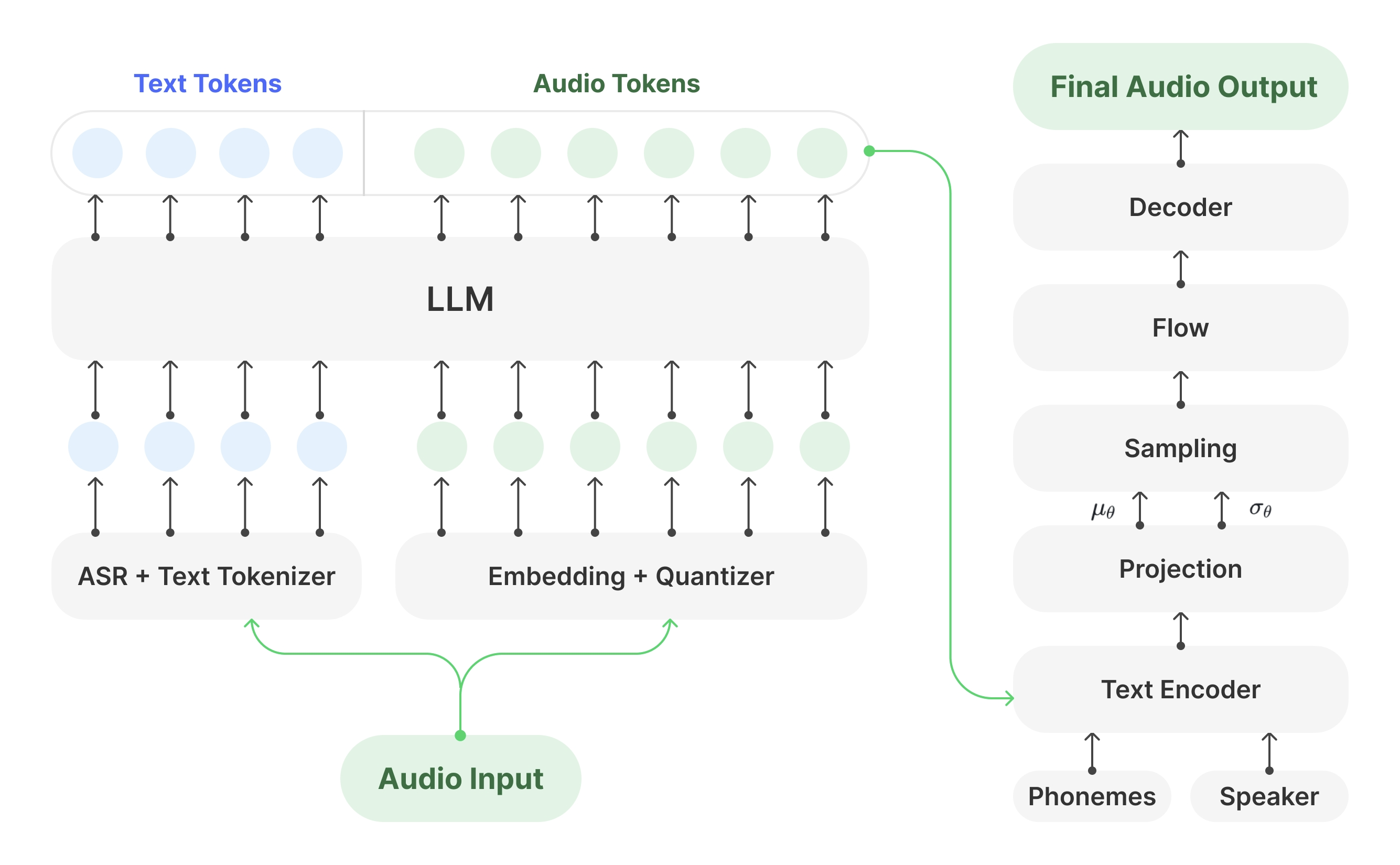
Muyan-TTS: Personalisiertes Podcast-Sprachtraining und -synthese
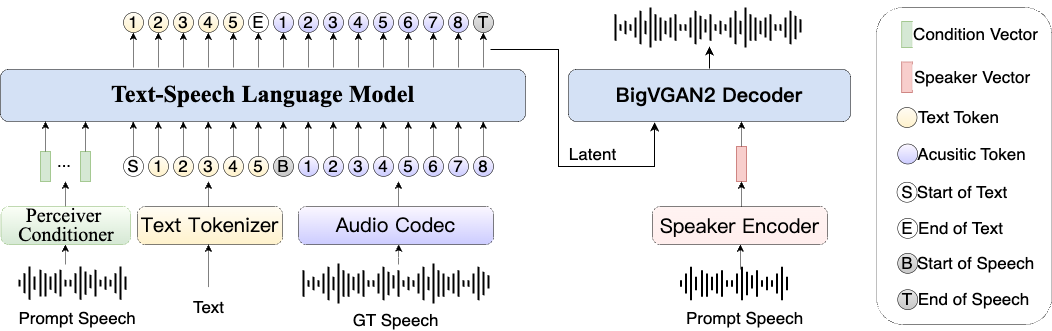
Synthesis Muyan-TTS ist ein Open-Source-Text-to-Speech-Modell (TTS), das für Podcasting-Szenarien entwickelt wurde. Es ist mit über 100.000 Stunden Podcast-Audiodaten vortrainiert und unterstützt die Null-Sample-Sprachsynthese, um qualitativ hochwertige natürliche Sprache zu erzeugen. Das Modell basiert auf Llama-3.2-3...