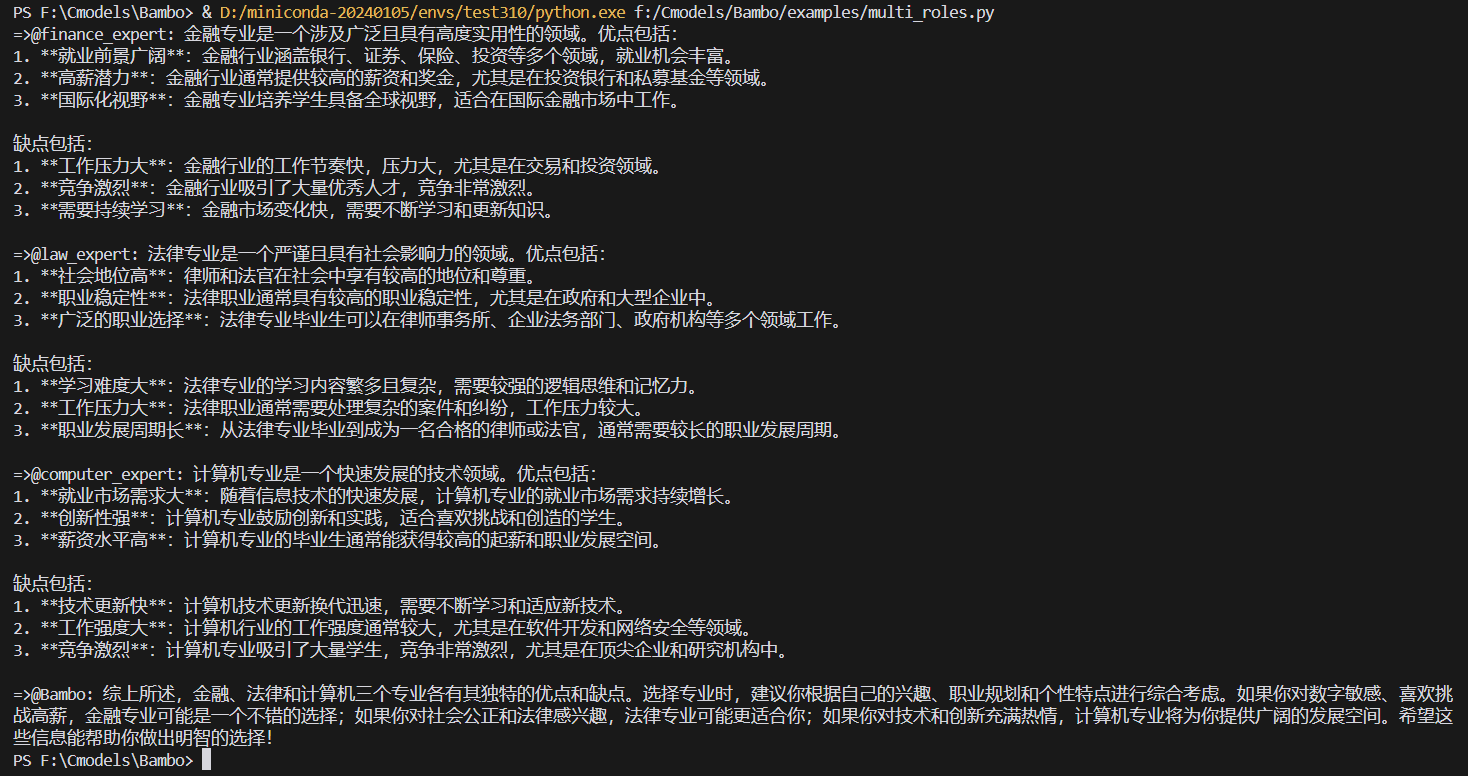
StreamingT2V: Dynamische und skalierbare Generierung von Text zu langen Videos

Allgemeine Einführung
StreamingT2V ist ein öffentliches Projekt, das vom Picsart AI-Forschungsteam entwickelt wurde und sich auf die Erzeugung kohärenter, dynamischer und skalierbarer langer Videos auf der Grundlage von Textbeschreibungen konzentriert. Diese Technologie verwendet einen fortschrittlichen autoregressiven Ansatz, der ein zeitlich konsistentes Video garantiert, das eng mit dem Beschreibungstext übereinstimmt und eine hohe Bildqualität beibehält. Sie ist in der Lage, Videos mit einer Geschwindigkeit von bis zu 1200 fps und einer Länge von bis zu zwei Minuten zu generieren, wobei eine Skalierung auf längere Zeiträume möglich ist. Die Effektivität der Technik ist nicht durch ein bestimmtes Text2Video-Modell begrenzt, d. h. Verbesserungen des Modells werden die Videoqualität weiter verbessern.

Funktionsliste
Unterstützt die Erstellung von Videos mit bis zu 1200 fps und einer Länge von bis zu zwei Minuten.
Bewahrt die zeitliche Konsistenz von Videos und Bildern mit hoher Bildqualität
Dynamische Videogenerierung, die eng mit der Textbeschreibung übereinstimmt
Unterstützung mehrerer Basismodell-Anwendungen zur Verbesserung der Qualität der erzeugten Videos
Unterstützung von Text-zu-Video- und Bild-zu-Video-Konvertierung
Online-Demo von Gradio bereitstellen
Hilfe verwenden
Klonen Sie das Projekt-Repository und installieren Sie die erforderliche Umgebung
Laden Sie die Gewichte herunter und ordnen Sie sie dem richtigen Katalog zu
Beispielcode für die Konvertierung von Text in Video oder Bild in Video ausführen
Auf der Projektseite finden Sie detaillierte Ergebnisse und Demos
Inferenzzeit
ModelscopeT2V als Basismodell
| Bildrate | Schnellere Vorschau-Inferenzzeit (256×256) | Berechnungszeit für das Endergebnis (720×720) |
|---|---|---|
| 24 Rahmen | 40 Sekunden. | 165 Sekunden. |
| 56 Rahmen | 75 Sekunden | 360 Sekunden |
| 80 Rahmen | 110 Sekunden. | 525 Sekunden. |
| 240 Bilder | 340 Sekunden. | 1610 Sekunden (etwa 27 Minuten) |
| 600 Rahmen | 860 Sekunden. | 5128 Sekunden (etwa 85 Minuten) |
| 1200 Bilder. | 1710 Sekunden (etwa 28 Minuten) | 10225 Sekunden (etwa 170 Minuten) |
AnimateDiffals Basismodell
| Bildrate | Schnellere Vorschau-Inferenzzeit (256×256) | Berechnungszeit für das Endergebnis (720×720) |
|---|---|---|
| 24 Rahmen | 50 Sekunden. | 180 Sekunden. |
| 56 Rahmen | 85 Sekunden. | 370 Sekunden. |
| 80 Rahmen | 120 Sekunden. | 535 Sekunden. |
| 240 Bilder | 350 Sekunden. | 1620 Sekunden (etwa 27 Minuten) |
| 600 Rahmen | 870 Sekunden. | 5138 Sekunden (~85 Minuten) |
| 1200 Bilder. | 1720 Sekunden (etwa 28 Minuten) | 10235 Sekunden (etwa 170 Minuten) |
SVDAls Grundmodell
| Bildrate | Schnellere Vorschau-Inferenzzeit (256×256) | Berechnungszeit für das Endergebnis (720×720) |
|---|---|---|
| 24 Rahmen | 80 Sekunden. | 210 Sekunden. |
| 56 Rahmen | 115 Sekunden. | 400 Sekunden. |
| 80 Rahmen | 150 Sekunden. | 565 Sekunden. |
| 240 Bilder | 380 Sekunden. | 1650 Sekunden (etwa 27 Minuten) |
| 600 Rahmen | 900 Sekunden. | 5168 Sekunden (~86 Minuten) |
| 1200 Bilder. | 1750 Sekunden (ca. 29 Minuten) | 10265 Sekunden (~171 Minuten) |
Alle Messungen wurden mit dem NVIDIA A100 (80 GB) Grafikprozessor durchgeführt. Wenn die Anzahl der Frames 80 überstieg, wurde eine Zufallsmischung verwendet. Bei der Zufallsmischung wurde diechunk_sizeund der Wert vonoverlap_sizesind auf 112 bzw. 32 festgelegt.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel

Keine Kommentare...