
Step-Video-T2V: Ein Vincennes-Videomodell, das mehrsprachige Eingaben und die Erzeugung langer Videos unterstützt
Allgemeine Einführung
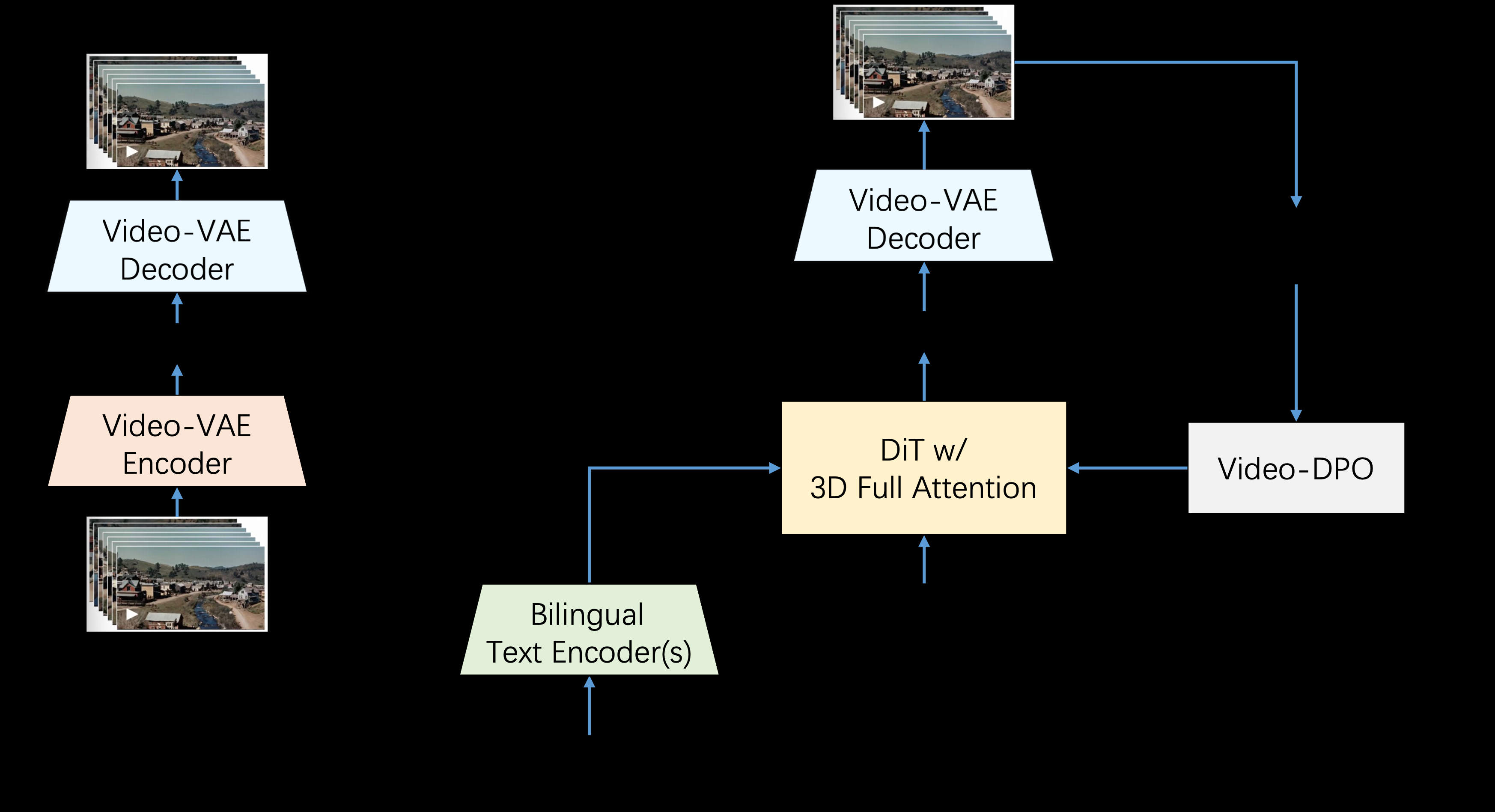
Step-Video-T2V ist ein fortschrittliches Text-zu-Video-Konvertierungsmodell von StepFun AI (Step Star). Das Modell hat 3 Milliarden Parameter und ist in der Lage, Videos mit bis zu 204 fps zu erzeugen. Mit einem stark komprimierten variablen Auto-Encoder (VAE) erreicht das Modell eine räumliche Komprimierung von 16x16 und eine zeitliche Komprimierung von 8x, was die Effizienz des Trainings und der Inferenz verbessert.Step-Video-T2V zeigt gute Leistungen im Bereich der Videogenerierung, insbesondere in Bezug auf die Videobewegung und die Effizienz. Allerdings gibt es noch einige Herausforderungen bei der Verarbeitung komplexer Bewegungen. Das Modell ist quelloffen und Nutzer können auf GitHub auf den Code zugreifen und dazu beitragen.
Funktionsliste
- Erzeugen Sie Videos in hoher Qualität: Erzeugen Sie Videos mit bis zu 204 fps und 3 Milliarden Parametern.
- Tiefes Komprimierungsverfahren: 16x16 räumliche Komprimierung und 8x zeitliche Komprimierung unter Verwendung eines tiefen Komprimierungs-Variations-Self-Encoders.
- Zweisprachige Unterstützung: Unterstützt Textbenachrichtigungen in Englisch und Chinesisch.
- Open Source und Unterstützung durch die Gemeinschaft: Modelle und Benchmark-Datensätze sind Open Source, um Innovationen zu fördern und die Urheber zu unterstützen.
Hilfe verwenden
Einbauverfahren
- Klonen von GitHub-Repositories:
git clone https://github.com/stepfun-ai/Step-Video-T2V.git - Rufen Sie den Projektkatalog auf:
cd Step-Video-T2V - Erstellen und aktivieren Sie eine virtuelle Umgebung:
conda create -n stepvideo python=3.10 conda activate stepvideo - Installieren Sie die Abhängigkeit:
pip install -e . pip install flash-attn --no-build-isolation ## flash-attn是可选的
Leitlinien für die Verwendung
Video generieren
- Bereiten Sie Textaufforderungen vor, die in einer Datei gespeichert werden sollen, z. B.
prompt.txt::飞机在蓝天中飞翔 - Führen Sie das Skript zur Videoerstellung aus:
python generate_video.py --input prompt.txt --output video.mp4
Detaillierte Funktionsabläufe
- Erzeugen von Videos in hoher Qualität::
- Texteingabe: Der Benutzer gibt einen Text ein, der den Inhalt des Videos beschreibt.
- Modellverarbeitung: Das Step-Video-T2V-Modell analysiert den Text und erzeugt ein Video.
- Videoausgabe: Das erzeugte Video wird im MP4-Format gespeichert, das von den Benutzern jederzeit angesehen und weitergegeben werden kann.
- Technologie der Tiefenkompression::
- Räumliche Komprimierung: Verbessern Sie die Effizienz der Videoerstellung durch die Technologie der räumlichen 16x16-Komprimierung.
- Temporale Komprimierung: Die Geschwindigkeit und Qualität der Videoerstellung wird durch die 8-fache temporale Komprimierungstechnologie weiter optimiert.
- Zweisprachige Unterstützung::
- Englisch-Unterstützung: Benutzer können englischen Text eingeben, und das Modell analysiert und generiert automatisch das entsprechende Video.
- Chinesisch-Unterstützung: Benutzer können chinesischen Text eingeben, das Modell kann auch das entsprechende Video generieren, um die Bedürfnisse mehrsprachiger Benutzer zu unterstützen.
- Open Source und Unterstützung durch die Gemeinschaft::
- Offener Quellcode: Benutzer können auf den vollständigen Code des Modells auf GitHub zugreifen, um ihn selbst einzusetzen und zu ändern.
- Beitrag der Gemeinschaft: Nutzer können Code-Beiträge einreichen, um an der Verbesserung und Optimierung des Modells mitzuwirken.
Einzel-GPU-Inferenz und Quantifizierung
Das Step-Video-T2V Projekt unterstützt Single-GPU Inferenz und Quantisierung, was den benötigten Grafikspeicher erheblich reduziert. Bitte beachten SieVerwandte BeispieleWeitere Einzelheiten.
Best Practice Reasoning-Einstellungen
Step-Video-T2V schneidet bei der Inferenz gut ab und generiert durchgängig qualitativ hochwertige und dynamische Videos. Unsere Experimente zeigen jedoch, dass Variationen der Inferenz-Hyperparameter die Qualität der Generierung beeinflussen.
| Modelle | infer_steps | cfg_skala | zeit_verschiebung | num_frames |
|---|---|---|---|---|
| Schritt-Video-T2V | 30-50 | 9.0 | 13.0 | 204 |
| Schritt-Video-T2V-Turbo (Inferenzschritt) Destillation) | 10-15 | 5.0 | 17.0 | 204 |
Modell Download
| Modellierung | 🤗 Umarmungsgesicht | 🤖 Modelscope |
|---|---|---|
| Schritt-Video-T2V | Herunterladen von | Herunterladen von |
| Schritt-Video-T2V-Turbo (Inferenzschritt-Destillation) | Herunterladen von | Herunterladen von |
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...