Die erste Finanzindustrie Begründung großen Modell Regulus-FinX1 Open Source! Du Xiaoman schwere Produktion, die sich auf finanzielle komplexe Analyse und Entscheidungsfindung
Du Xiaoman veröffentlicht das weltweit erste große Denkmodell für die Finanzindustrie - Regulus-FinX1!
Das Modell ist das erste GPT-O1-ähnliche Inferenz-Makromodell im Finanzbereich, das ein innovatives"Gedankenkette + Prozessbelohnungen + Verstärkungslernen"Das Trainingsparadigma verbessert das logische Denken erheblich und kann den vollständigen Denkprozess aufzeigen, der durch das O1-Modell nicht offengelegt wird, was tiefere Einblicke in die finanzielle Entscheidungsfindung ermöglicht. Regulus-FinX1 ZieleAnalyse-, Entscheidungs- und Datenverarbeitungsaufgaben in FinanzszenarienEs wurde eine tiefgreifende Optimierung durchgeführt.
Xuan Yuan-FinX1 wird von Du Xiaoman AI-Lab entwickelt, und diese Version ist eine Vorabversion, die jetzt in der Open-Source-Gemeinschaft offen istKostenloser Download. Nachfolgende optimierte Versionen werden auch weiterhin als Open Source zum Download und zur Nutzung zur Verfügung stehen.
Github-Adresse: https://github.com/Duxiaoman-DI/XuanYuan
Benchmarking-Ergebnisse
Die erste Generation von Regulus-FinX1 zeigte eine hervorragende Leistung bei FinanceIQ, einem Finanzbenchmark. Auf demCPA, Bankqualifikation10 Arten von finanziellen Qualifikationen, wie z. B. Qualifikationen im Wertpapierbereich usw.In der Kategorie der Aktuare sind die Punktzahlen aller bisherigen großen Modelle im Allgemeinen niedrig, während XuanYuan-FinX1 seine Punktzahl von 37,5 auf 65,7 deutlich verbessert hat, was zeigt, dass es für finanzielles logisches Denken und mathematisches Schlussfolgern verwendet werden kann, und es kann für finanzielles logisches Denken und mathematisches Schlussfolgern verwendet werden. Vor allem in der Kategorie Aktuariat erzielten alle bisherigen großen Modelle im Allgemeinen eine niedrige Punktzahl, während XuanYuan-FinX1 seine Punktzahl von 37,5 auf 65,7 verbesserte, was seinen starken Vorteil beim logischen Denken im Finanzbereich und bei mathematischen Berechnungen deutlich macht. 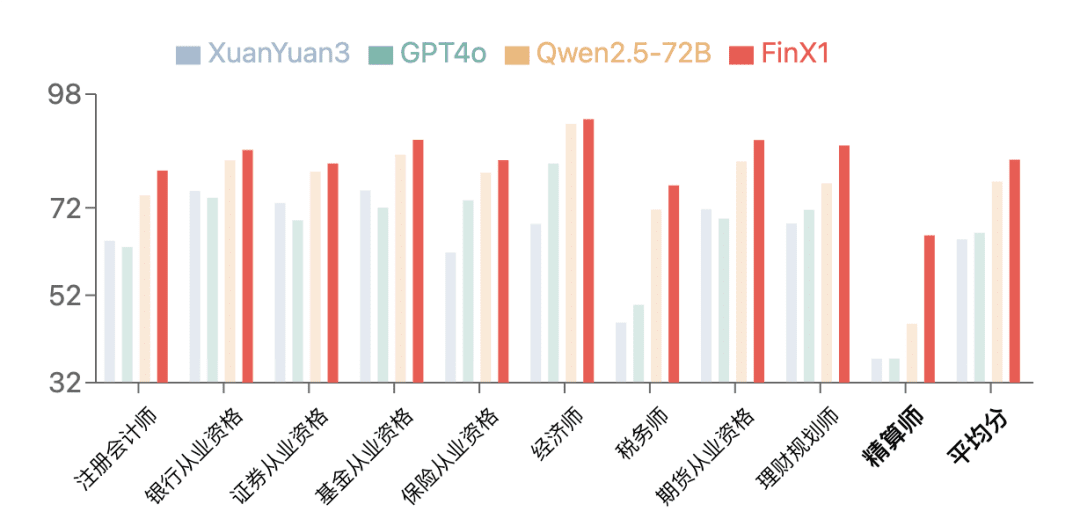
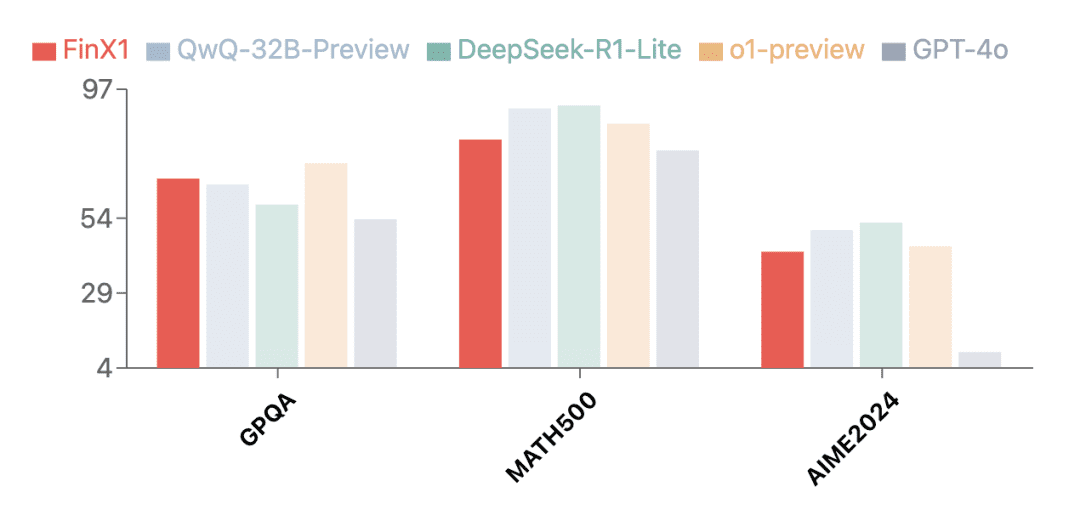
Neben dem Finanzbereich hat die erste Generation von Regulus-FinX1 auch hervorragende Allzweckfähigkeiten bewiesen. Die Testergebnisse auf mehreren maßgeblichen Bewertungssätzen zeigen, dass Regulus-FinX1 nicht nur in derGPQA (Wissenschaftliches Denken)undMATH-500 (Mathematik)im Gesang antwortenAIME2024 (Mathematikwettbewerb)Es hat auch GPT-4o übertroffen und rangiert zusammen mit O1 und der neu veröffentlichten Inferenzversion des Big Model in China in der Spitzengruppe, was seine starke grundlegende Inferenzfähigkeit bestätigt.
Die "Black Box" durchbrechen: Darstellung der vollständigen Denkkette
Eines der Merkmale von Regulus FinX1 ist, dass es den gesamten Denkprozess darstellen kann, bevor es eine Antwort generiert, und so eine vollständig transparente Denkkette von der Zerlegung des Problems bis zur endgültigen Schlussfolgerung aufbaut. Durch diesen Mechanismus verbessert Regulus FinX1 nicht nur die Interpretierbarkeit der Argumentation, sondern löst auch das "Blackbox"-Problem traditioneller großer Modelle und bietet Finanzinstituten ein glaubwürdigeres Instrument zur Entscheidungsunterstützung.

Regulus Beispiel für die Erstellung einer Gedankenkette für FinX1
Schwerpunkt auf finanzieller Komplexität und analytischer Entscheidungsfindung
Als der GPT-O1 von OpenAI die Aufmerksamkeit der Branche mit seiner überlegenen "Denkleistung" auf sich zog, entstand ein zentrales Angebot:Wie kann diese tiefgreifende Denkfähigkeit in professionellen Finanzszenarien einen erheblichen Wert schaffen?Du Xiaoman Regulus FinX1 gibt innovative Antworten -Zum ersten Mal wurde die tiefgreifende Schlussfolgerungsfähigkeit großer Modelle in den Finanzbereich eingeführt, wodurch die Anwendung großer Modelle in derVerwenden Sie diese Funktion, um von allgemeinen Szenarien bis hin zu zentralen Geschäftsebenen wie Risikokontrollentscheidungen vorzudringen.
Im Zuge der Umstellung auf digitale Intelligenz im Finanzsektor wird die"Entscheidungsfindungs- und Risikokontrollkapazitäten", "Forschungs- und Analysekapazitäten" und "Datenintelligenzkapazitäten".sind die Schlüsseldimensionen, die die geschäftliche Innovation und Wertsteigerung vorantreiben. Diese Fähigkeiten bringen dem Institut eine nachhaltige Wertsteigerung durch genaue Risikoerkennung und -kontrolle, eingehende Marktforschung und Wertentdeckung bzw. effiziente Datenmodellierung und -analyse.
Regulus FinX1 integriert durch ein innovatives Trainingsparadigma tiefgreifende Denkfähigkeiten mit Finanzfachwissen, so dass diese drei Fähigkeiten in spezifischen Szenarien voll zur Geltung kommen und neue intelligente Lösungen für die Finanzbranche entstehen.

01 Fähigkeit zur Entscheidungsfindung und Risikokontrolle
Die Fähigkeit zur Entscheidungsfindung und Risikokontrolle ist die Lebensader von Finanzinstituten, die mit ihrem soliden Betrieb und ihrer nachhaltigen Entwicklung verbunden ist. Bei den Kernaufgaben der Risikoidentifizierung und -vorhersage, der Konstruktion von Risikokontrollmodellen und der Strategieformulierung kann Regulus FinX1 mit seinen leistungsstarken Argumentationsfähigkeiten und dem vollständigen Chain-of-Mind-Mechanismus systematisch die Korrelations- und Leitungspfade zwischen Risikofaktoren analysieren und den Instituten umfassende und tiefgreifende Risikoerkenntnisse liefern. So kann Regulus FinX1 beispielsweise auf der Grundlage des von der Benutzerautorisierung hochgeladenen Bankwassers aus Tausenden von Transaktionsdatensätzen Risikosignale wie hochfrequenten Lotteriekonsum, Spielkonsum usw. genau identifizieren und die Rückzahlungsfähigkeit und das Kreditrisiko des Benutzers in Verbindung mit der Einkommenshöhe und der Schuldenlast wissenschaftlich bewerten.

Regulus FinX1 antwortete auf den Beitrag
02 Forschung und analytische Fähigkeiten
Forschungs- und Analysefähigkeiten sind die Grundlage für finanzielle Entscheidungen, die die Wissenschaft der Kapitalallokation durch tiefgreifende Einblicke auf Makro-, Branchen- und Unternehmensebene verbessern. Regulus FinX1 ist in der Lage, mehrdimensionale Analysen von makroökonomischen Daten, Marktstimmung, politischen Auswirkungen usw. durchzuführen und komplexe Sachverhalte durch eine klare Logikkette schrittweise zu zerlegen. Bei der Vorhersage der Zinssenkung der US-Notenbank im Jahr 2025 auf der Grundlage von Wirtschaftsdaten untersucht das Modell beispielsweise eine breite Palette von Möglichkeiten durch die Analyse einer Vielzahl von Wirtschaftsfaktoren und auf der Grundlage verschiedener hypothetischer Szenarien und zeigt umfassend und objektiv die Aussicht auf eine Zinssenkung der US-Notenbank im Jahr 2025 auf, die derzeit mit den prognostischen analytischen Ansichten einer Reihe von Institutionen übereinstimmt. 
03 Fähigkeiten zur Datenanalyse
Data-Intelligence-Fähigkeiten sind eine wichtige Unterstützung für Finanzinstitute, um eine präzise Entscheidungsfindung zu erreichen, deren Kern eine effiziente Datenverarbeitung und tiefgreifende Analysefähigkeiten sind. Regulus FinX1 kann Finanzinstituten helfen, die Geschäftslogik und den Wert hinter den Daten schnell zu erkennen. Wenn beispielsweise die vierteljährlichen Finanzdaten eines Unternehmens in Regulus FinX1 eingegeben werden, kann das Modell die Kerninformationen genau extrahieren und die Qualität der Vermögenswerte, die Liquidität und die Geschäftsdynamik visuell darstellen. Durch die Analyse von Schlüsselindikatoren wie "Liquiditätsdruck" und "Expansionsdrang" fügt Regulus FinX1 qualitative Erklärungen auf der Grundlage quantitativer Vergleiche hinzu, die potenzielle Risiken und Wachstumschancen hinter den Finanzdaten aufzeigen und Unternehmen dabei helfen, ihre Entscheidungsfindung zu optimieren. 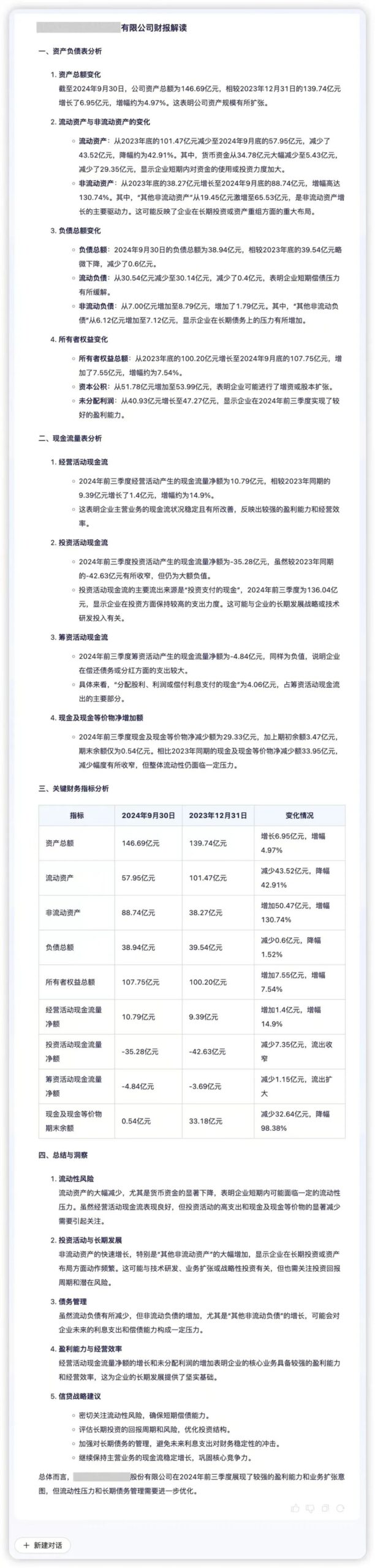
Technische Umsetzung von Regulus-FinX1
Um große Modelle mit O1-ähnlichen Argumentationsfähigkeiten zu erreichen, insbesondere in komplexen Entscheidungsanalyseszenarien im Finanzbereich, schlagen wir eine technische Lösung vor, die nach umfassender Erforschung und Validierung drei Schlüsselschritte umfasst:Auf dem Weg zu einem stabilen Modell zur Generierung von Gedankenketten, einem dualen Belohnungsmodell zur Verbesserung von Finanzentscheidungen und der Feinabstimmung von Reinforcement Learning unter doppelter Anleitung von PRM und ORM.
01 Erste Konstruktion eines stabilen generativen Modells der Gedankenkette
Für die komplexen Entscheidungsanalyseszenarien im Finanzbereich haben wir ein Basismodell mit stabiler Denkkettengenerierungsfähigkeit entwickelt. Der erste Schritt ist die Datensynthese von hochwertigen COT/Antworten, die zunächst den Denkprozess auf der Grundlage der Frage und dann die endgültige Antwort auf der Grundlage der Frage und des Denkprozesses generieren. Mit dieser Strategie ist das Modell in der Lage, sich auf jede Phase der Aufgabe zu konzentrieren und kohärentere Gedankenketten und Antworten zu erzeugen.
Für verschiedene Bereiche (z. B. Mathematik, logisches Denken, Finanzanalyse usw.) haben wir spezielle Datensynthesemethoden entwickelt, z. B. für Finanzanalyseaufgaben haben wir eine iterative Synthesemethode entwickelt, um die Vollständigkeit des Analyseprozesses zu gewährleisten, und haben dann das Modell auf der Grundlage des XuanYuan 3.0-Modells unter Verwendung der Befehlsfeinabstimmung und unter Verwendung eines einheitlichen Denkprozess Antwort-Ausgabeformat (wir werden diesmal auch die grobkörnigen Denkknoten offenlegen), und gleichzeitig konzentrieren wir uns auf die Erstellung einer größeren Anzahl von Langtextdaten, um die Fähigkeit des Modells zur Verarbeitung langer Kontexte zu verbessern, so dass es "einen detaillierten Denkprozess erzeugen kann, bevor es eine Antwort generiert". Damit wird eine solide Grundlage für das anschließende prozessüberwachte Training und die Optimierung des Reinforcement Learning geschaffen.
02 Ein doppeltes Belohnungsmodell zur Verbesserung von Finanzentscheidungen
Um die Leistung des Modells in finanziellen Entscheidungsszenarien zu bewerten, haben wir dieZwei komplementäre Belohnungsmodelle, ergebnisorientiert (ORM) und prozessorientiert (PRM). ORM setzt die technische Lösung von XuanYuan 3.0 fort, die durch Kontrastlernen und inverses Verstärkungslernen trainiert wird; PRM ist unsere Innovation für den Argumentationsprozess, der sich auf die Lösung der Schwierigkeit der Bewertung von Finanzproblemen mit offenem Ende konzentriert (z. B. Marktanalyse, Investitionsentscheidungen usw.).
Für die Konstruktion der Trainingsdaten von PRM verwenden wir verschiedene Strategien für unterschiedliche Szenarien: Für Fragen mit eindeutigen Antworten wie Risikobewertungen verwenden wir eine auf MCTS basierende Reverse-Validierungsmethode; für offene Fragen zur Finanzanalyse kommentieren wir sie in Bezug auf Dimensionen wie Korrektheit, Notwendigkeit und Logik durch mehrere große Modelle und lösen das Problem des Datenungleichgewichts durch Downsampling und aktives Lernen. Während des Trainings verwendet PRM eine überwachte Feinabstimmung, um das Modell durch die Bewertung jedes Denkschritts zu optimieren.03 Reinforcement Learning Fine-Tuning mit Dual-Guidance von PRM und ORMIn der Reinforcement Learning-Phase verwenden wir den PPO-Algorithmus zur Modelloptimierung, der PRM und ORM als Belohnungssignale verwendet. Für den Denkprozess zwischen und wird PRM verwendet, um jeden Denkschritt zu bewerten, so dass Fehler im Denkpfad rechtzeitig erkannt und korrigiert werden können; für den Antwortteil werden unterschiedliche Bewertungsstrategien für verschiedene Fragetypen verwendet: Regelabgleich wird verwendet, um die Belohnungen für finanzielle Fragen mit einer eindeutigen Antwort zu berechnen (z. B. Risikobewertung), und Regelabgleich wird verwendet, um die Belohnungen für offene Fragen zu berechnen ( z.B. Marktanalysen) werden ganzheitlich mit ORM bewertet. Techniken wie dynamische KL-Koeffizienten und Dominanzfunktionsnormalisierung werden gleichzeitig eingeführt, um den Trainingsprozess zu stabilisieren. DieseAusbildungsmechanismen auf der Grundlage doppelter BelohnungenDadurch werden nicht nur die Einschränkungen eines Modells mit nur einer Belohnung überwunden, sondern auch die Argumentationsfähigkeit des Modells in finanziellen Entscheidungsszenarien durch stabiles Training mit Verstärkungslernen erheblich verbessert.
Wie man sieht, liegt der Schlüssel zu diesem Weg in der Konstruktion von Denkketten und der Bewertung von Belohnungsmodellen für offene Probleme in der Finanzanalyse, die sich von der Mathematik oder Logik unterscheiden, und wir sind immer noch dabei, zu optimieren und zu iterieren, und werden weiterhin effektivere technische Wege erforschen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel




Keine Kommentare...