Schneller Einsatz des RAG 3-Packs für Dify mit GPUStack
GPUStack Es handelt sich um eine Open-Source-Plattform für Big-Model-as-a-Service, die verschiedene heterogene GPU/NPU-Ressourcen wie Nvidia, Apple Metal, Huawei Rise und Moore Threads effizient integrieren und nutzen kann, um eine lokale private Bereitstellung von Big-Model-Lösungen zu ermöglichen.
GPUStack kann unterstützen RAG Die drei wichtigsten Modelle, die im System benötigt werden: das Chat-Dialogmodell (das große Sprachmodell), das Einbettungsmodell für Text und das Rerank-Neuordnungsmodell sind in einer dreiteiligen Suite verfügbar, und es ist ein sehr einfacher und narrensicherer Vorgang, die vom RAG-System benötigten lokalen privaten Modelle einzusetzen.
Hier erfahren Sie, wie Sie GPUStack und Dify mit dem Dify um mit dem Dialogmodell, dem Einbettungsmodell und dem Rerankermodell, die von GPUStack eingesetzt werden, zusammenzuarbeiten.
Installation von GPUStack
Installieren Sie online auf Linux oder macOS mit den folgenden Befehlen, ein sudo-Passwort ist während des Installationsprozesses erforderlich: curl -sfL https://get.gpustack.ai | sh -
Wenn Sie keine Verbindung zu GitHub herstellen können, um einige Binärdateien herunterzuladen, verwenden Sie den folgenden Befehl, um sie mit dem --tools-download-base-url Der Parameter gibt an, dass der Download von Tencent Cloud Object Storage erfolgen soll:curl -sfL https://get.gpustack.ai | sh - --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
Führen Sie Powershell als Administrator unter Windows aus und installieren Sie es online mit dem folgenden Befehl:Invoke-Expression (Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content
Wenn Sie keine Verbindung zu GitHub herstellen können, um einige Binärdateien herunterzuladen, verwenden Sie den folgenden Befehl, um sie mit dem --tools-download-base-url Der Parameter gibt an, dass der Download von Tencent Cloud Object Storage erfolgen soll:Invoke-Expression "& { $((Invoke-WebRequest -Uri 'https://get.gpustack.ai' -UseBasicParsing).Content) } --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
Wenn Sie die folgende Ausgabe sehen, wurde der GPUStack erfolgreich bereitgestellt und gestartet:
[INFO] Install complete. GPUStack UI is available at http://localhost. Default username is 'admin'. To get the default password, run 'cat /var/lib/gpustack/initial_admin_password'. CLI "gpustack" is available from the command line. (You may need to open a new terminal or re-login for the PATH changes to take effect.)
Folgen Sie dann den Anweisungen in der Skriptausgabe, um das anfängliche Passwort für die Anmeldung bei GPUStack zu erhalten, und führen Sie den folgenden Befehl aus:
unter Linux oder macOS:cat /var/lib/gpustack/initial_admin_password
Unter Windows:Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustackinitial_admin_password") -Raw
Greifen Sie auf die GPUStack-Benutzeroberfläche in einem Browser mit dem Benutzernamen admin und dem Passwort zu, das Sie oben als Initialpasswort erhalten haben.
Nachdem Sie das Passwort zurückgesetzt haben, geben Sie GPUStack ein: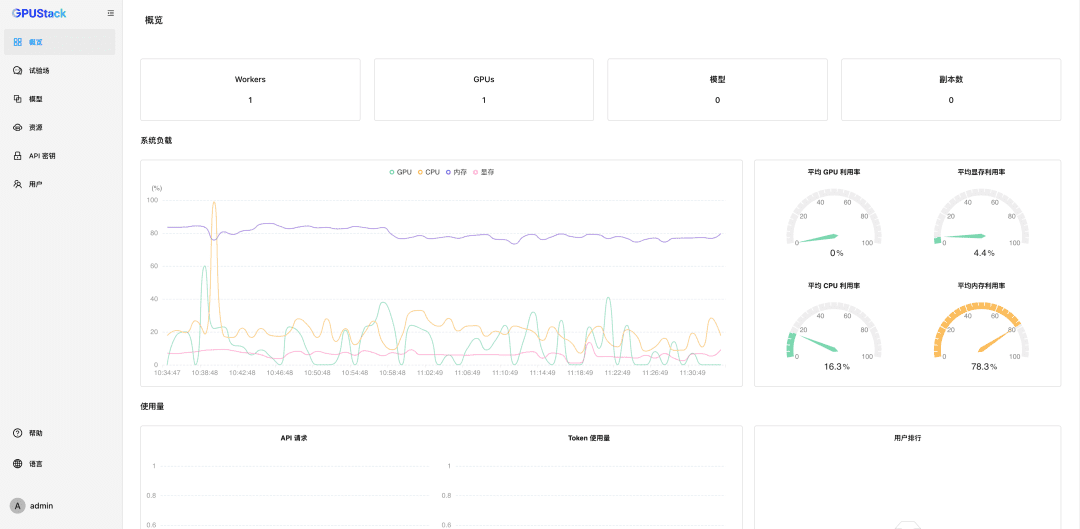
Nanomanagement GPU-Ressourcen
GPUStack unterstützt GPU-Ressourcen für Linux-, Windows- und macOS-Geräte und verwaltet diese GPU-Ressourcen anhand der folgenden Schritte.
Andere Knotenpunkte müssen authentifiziert werden Token Treten Sie dem GPUStack-Cluster bei und führen Sie den folgenden Befehl auf dem GPUStack-Server-Knoten aus, um einen Token zu erhalten:
unter Linux oder macOS:cat /var/lib/gpustack/token
Unter Windows:Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustacktoken") -Raw
Sobald Sie das Token haben, führen Sie den folgenden Befehl auf den anderen Knoten aus, um den Worker zum GPUStack hinzuzufügen und die GPUs auf diesen Knoten zu verwalten (ersetzen Sie http://YOUR_IP_ADDRESS durch Ihre GPUStack-Zugangsadresse und YOUR_TOKEN durch das Authentifizierungs-Token, mit dem Sie den Worker hinzugefügt haben):
unter Linux oder macOS:curl -sfL https://get.gpustack.ai | sh - --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
Unter Windows:Invoke-Expression "& { $((Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content) } --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
Mit den obigen Schritten haben wir eine GPUStack-Umgebung erstellt und mehrere GPU-Knoten verwaltet, die dann für die Bereitstellung privater großer Modelle verwendet werden können.
Einsatz von privaten Makromodellen
Besuchen Sie GPUStack und verteilen Sie Modelle im Menü Modelle. GPUStack unterstützt die Verteilung von Modellen aus HuggingFace, Ollama Library, ModelScope und privaten Modell-Repositories; ModelScope wird für nationale Netzwerke empfohlen.
GPUStack-Unterstützung vLLM und llama-box ist vLLM für die Produktionsinferenz optimiert und in Bezug auf Gleichzeitigkeit und Leistung besser für die Produktionsanforderungen geeignet. vLLM wird jedoch nur auf Linux-Systemen unterstützt. llama-box ist eine flexible, plattformübergreifende Inferenzmaschine, die lama.cpp Es unterstützt Linux-, Windows- und macOS-Systeme und unterstützt nicht nur GPU-Umgebungen, sondern auch CPU-Umgebungen für die Ausführung großer Modelle, wodurch es sich besser für Szenarien eignet, die Multiplattform-Kompatibilität erfordern.
GPUStack wählt automatisch das passende Inferenz-Backend auf der Grundlage des Typs der Modelldatei aus, wenn das Modell bereitgestellt wird. GPUStack verwendet llama-box als Backend, um den Modelldienst auszuführen, wenn das Modell im GGUF-Format vorliegt, und vLLM als Backend, um den Modelldienst auszuführen, wenn es nicht im GGUF-Format vorliegt.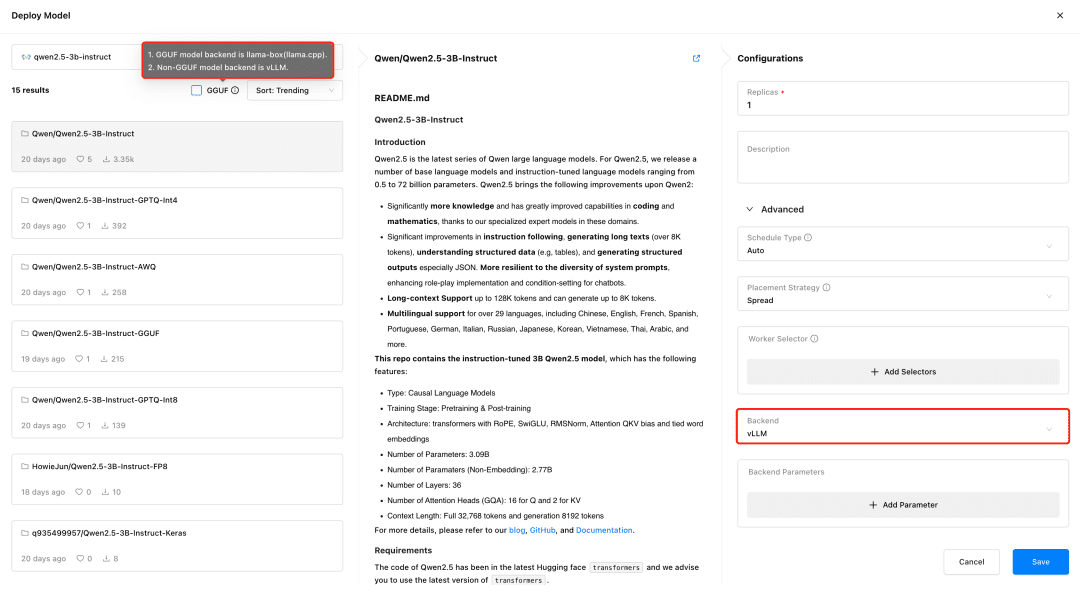
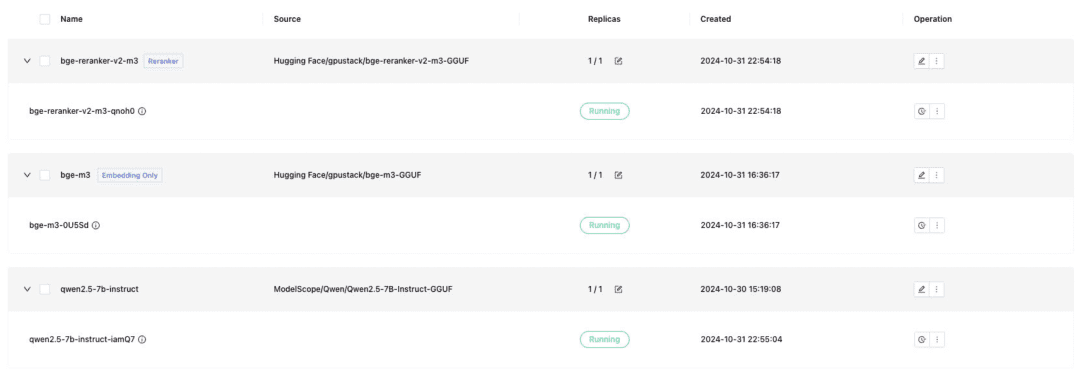
Setzen Sie das Textdialogmodell, das Texteinbettungsmodell und das Rerankermodell ein, die für das Andocken an Dify erforderlich sind, und denken Sie daran, beim Einsetzen das GGUF-Format zu überprüfen:
- Qwen/Qwen2.5-7B-Instruct-GGUF
- gpustack/bge-m3-GGUF
- gpustack/bge-reranker-v2-m3-GGUF
GPUStack unterstützt auch multimodale VLM-Modelle, deren Einsatz die Verwendung eines vLLM-Inferenz-Backends erfordert:
Qwen2-VL-2B-Anleitung 

Sobald das Modell bereitgestellt ist, kann ein RAG-System oder eine andere generative KI-Anwendung über die von GPUStack bereitgestellte OpenAI/Jina-kompatible API mit dem GPUStack-Modell verbunden werden, gefolgt von Dify, um mit dem GPUStack-Modell zu kommunizieren.
Dify integriert GPUStack-Modelle
Dify installieren
Um Dify mit Docker auszuführen, müssen Sie eine Docker-Umgebung vorbereiten und darauf achten, Konflikte zwischen Dify und dem Port 80 von GPUStack zu vermeiden, andere Hosts zu verwenden oder den Port zu ändern. Führen Sie den folgenden Befehl aus, um Dify zu installieren:git clone -b 0.10.1 https://github.com/langgenius/dify.gitBesuchen Sie die UI-Oberfläche von Dify unter http://localhost, um das Administratorkonto zu initialisieren und sich anzumelden.
cd dify/docker/
cp .env.example .env
docker compose up -d
Um ein GPUStack-Modell zu integrieren, fügen Sie zunächst ein Chat-Dialogmodell hinzu. Wählen Sie in der oberen rechten Ecke von Dify "Einstellungen - Modellanbieter", suchen Sie den GPUStack-Typ in der Liste und wählen Sie Modell hinzufügen:
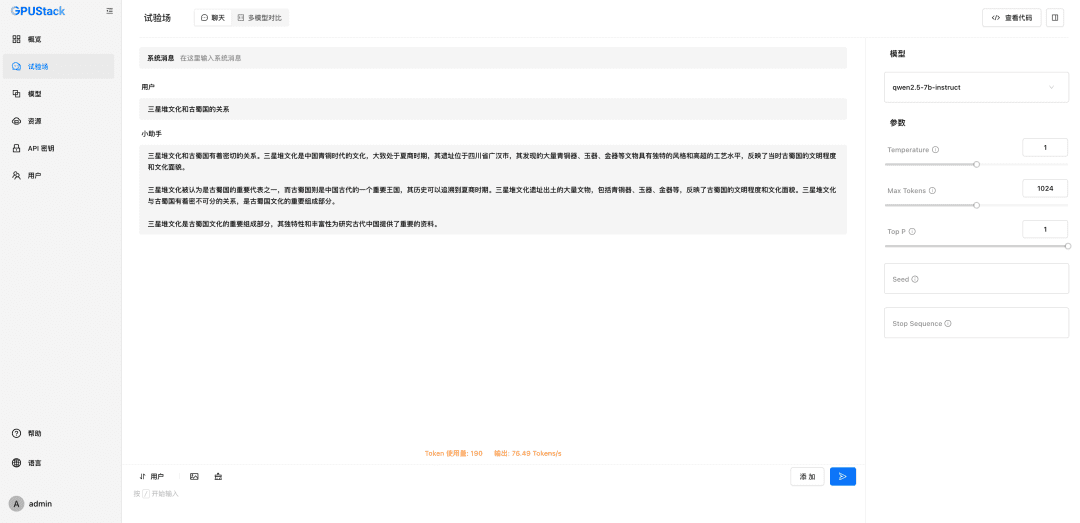
Geben Sie den Namen des LLM-Modells, das auf dem GPUStack eingesetzt wird (z. B. qwen2.5-7b-instruct), die Zugangsadresse des GPUStack (z. B. http://192.168.0.111) und den generierten API-Schlüssel sowie die Kontextlängen der Modelleinstellungen 8192 und max Token 2048: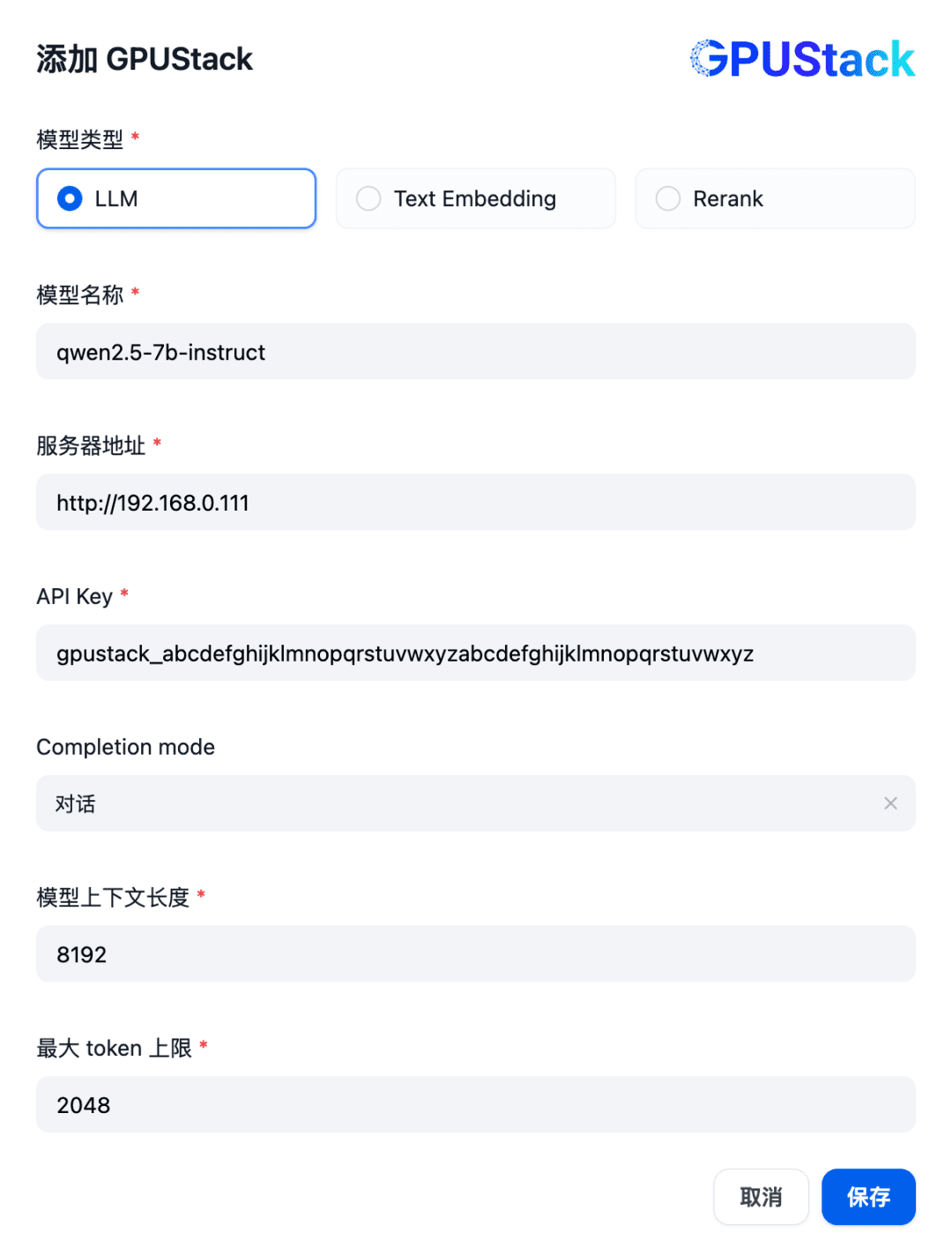
Als nächstes fügen Sie das Einbettungsmodell hinzu. Wählen Sie oben im Modellanbieter den Typ GPUStack aus und wählen Sie Modell hinzufügen: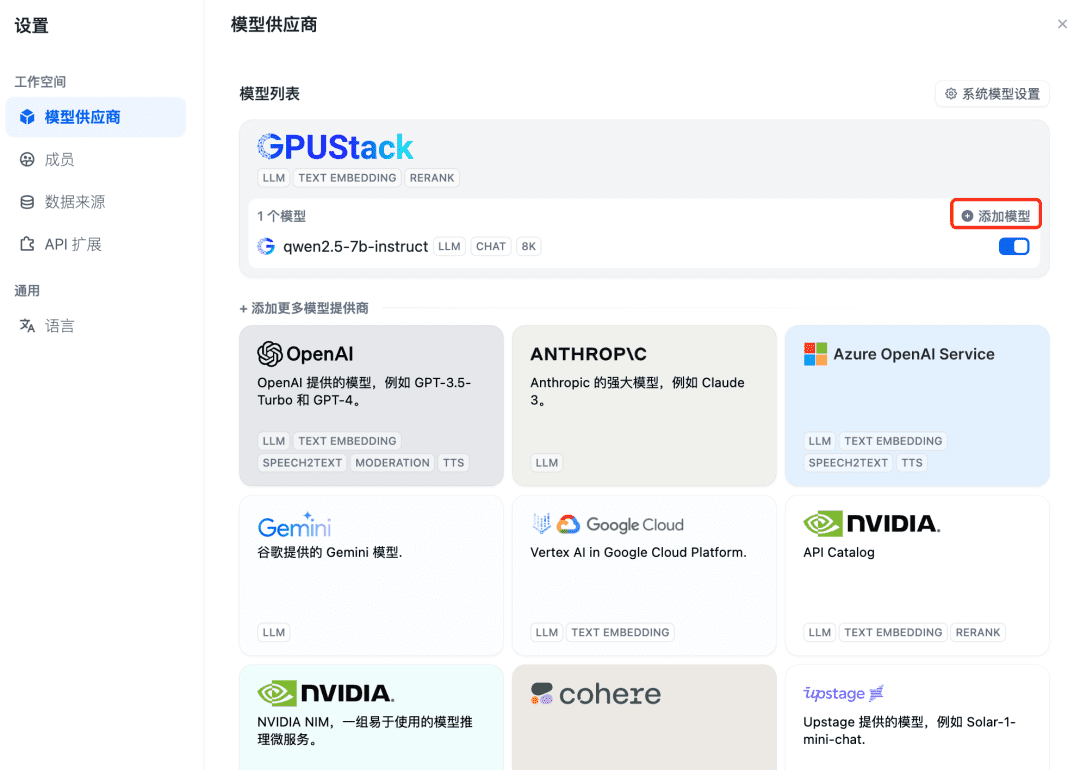
Fügen Sie ein Modell des Typs Texteinbettung hinzu und geben Sie den Namen des auf dem GPUStack eingesetzten Einbettungsmodells (z. B. bge-m3), die Zugangsadresse des GPUStack (z. B. http://192.168.0.111) und den generierten API-Schlüssel sowie eine Kontextlänge von 8192 für die Modelleinstellungen ein: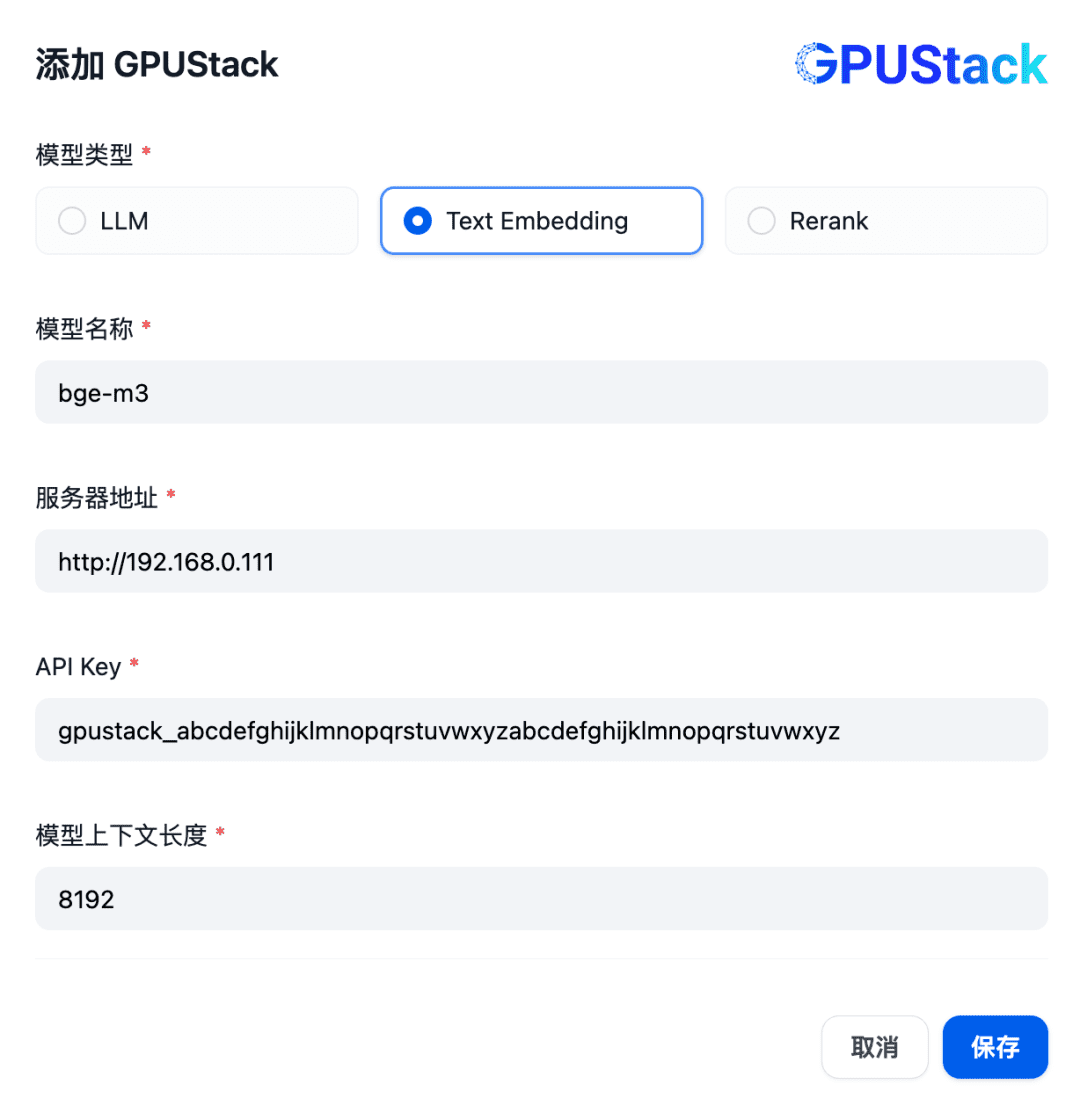
Um ein Rerank-Modell hinzuzufügen, wählen Sie den GPUStack-Typ aus, wählen Sie Modell hinzufügen, fügen Sie ein Modell des Typs Rerank hinzu, geben Sie den Namen des Rerank-Modells, das auf dem GPUStack eingesetzt wird (z. B. bge-reranker-v2-m3), die Zugangsadresse des GPUStack (z. B. http://192.168. 0.111) und den generierten API-Schlüssel, sowie die Kontextlänge 8192 für die Modelleinstellungen: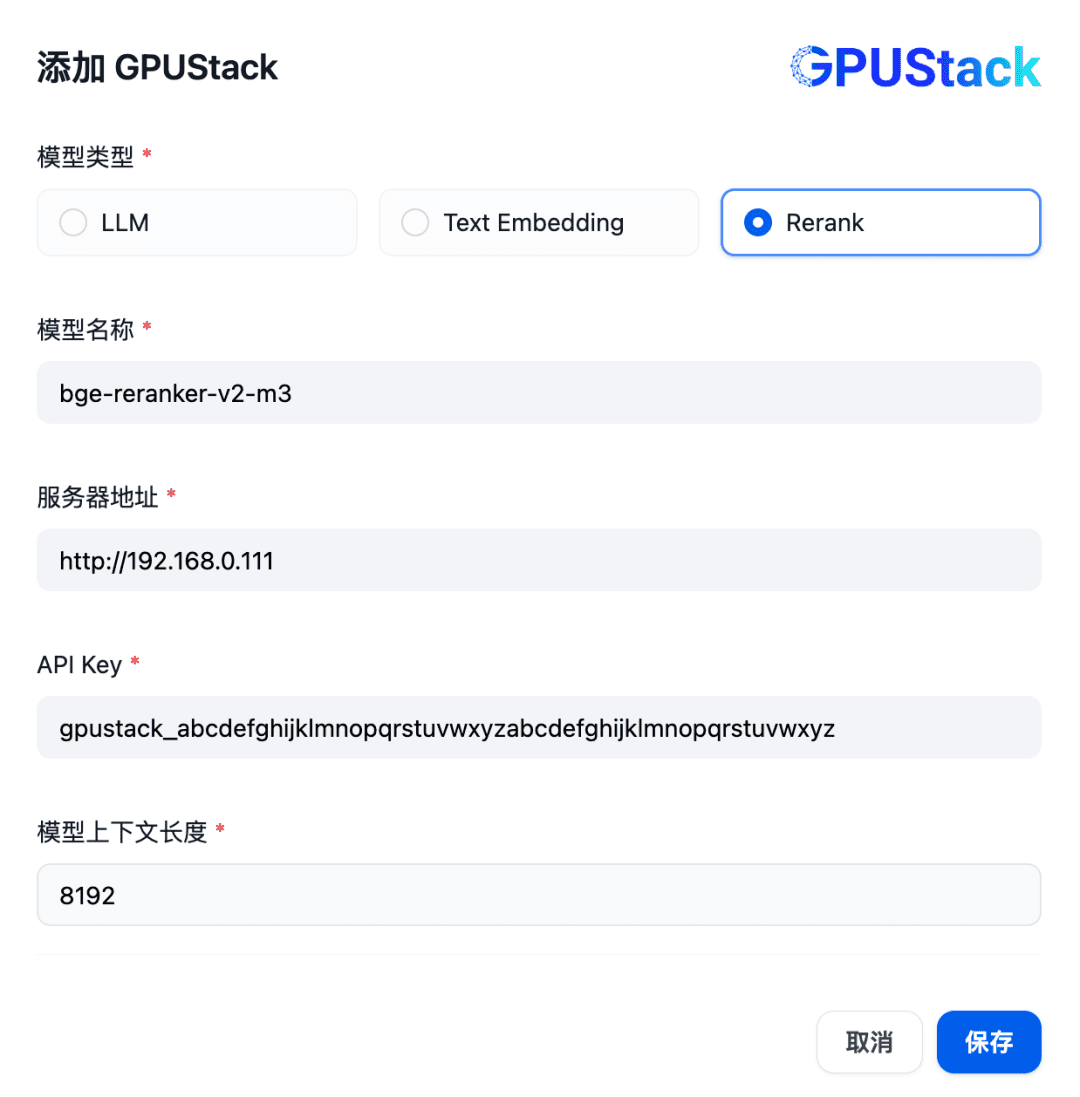
Aktualisieren Sie nach dem Hinzufügen und bestätigen Sie dann beim Modellanbieter, dass die Systemmodelle für die drei oben hinzugefügten Modelle konfiguriert sind: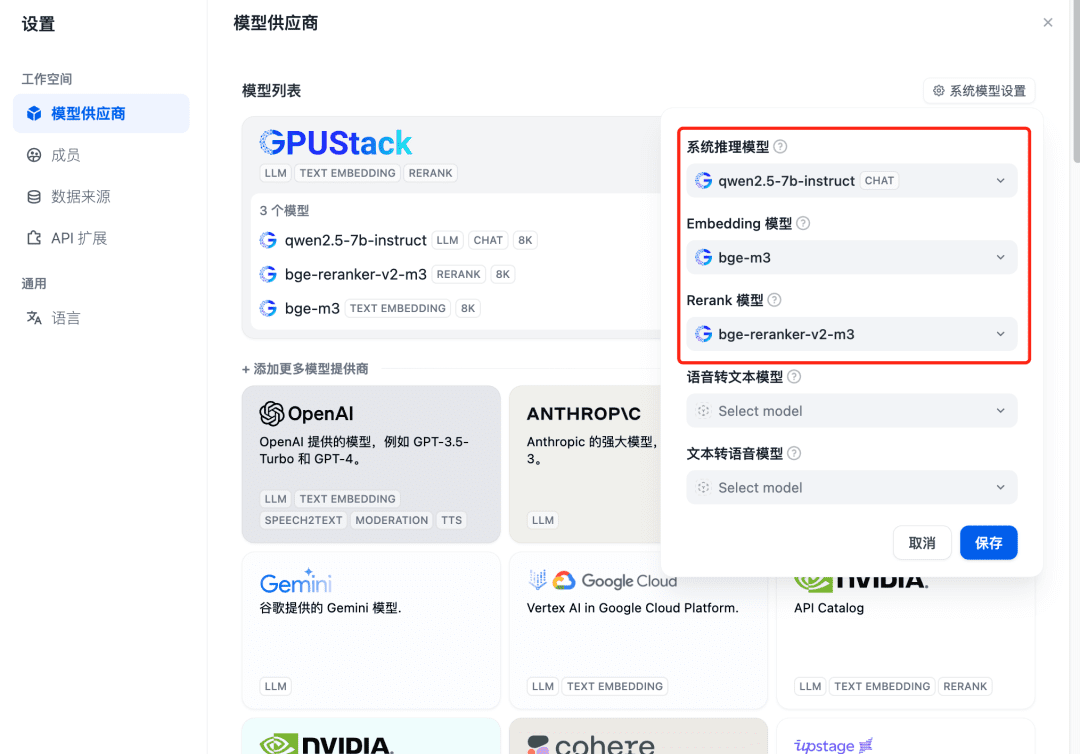
Modelle im RAG-System verwenden Wählen Sie die Wissensdatenbank von Dfiy, wählen Sie Wissensdatenbank erstellen, importieren Sie eine Textdatei, bestätigen Sie die Option Modell einbetten, verwenden Sie die empfohlene hybride Suche für die Sucheinstellungen und schalten Sie das Modell Rerank ein: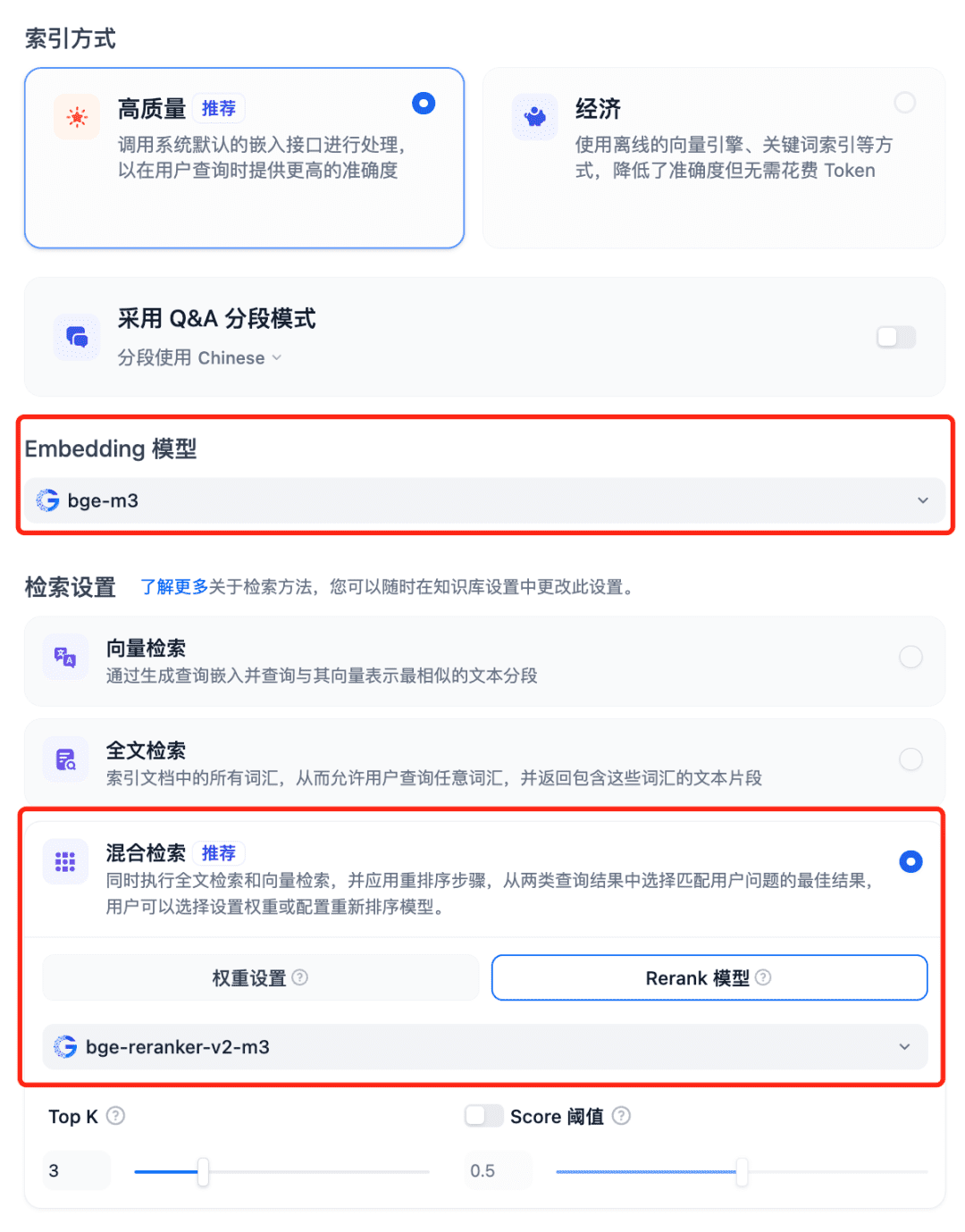
Speichern Sie und beginnen Sie mit der Vektorisierung des Dokuments. Wenn die Vektorisierung abgeschlossen ist, ist die Wissensdatenbank einsatzbereit.
Recall-Tests können verwendet werden, um die Recall-Effektivität der Wissensbasis zu bestätigen, und das Rerank-Modell wird verfeinert, um mehr relevante Dokumente abzurufen, um bessere Recall-Ergebnisse zu erzielen: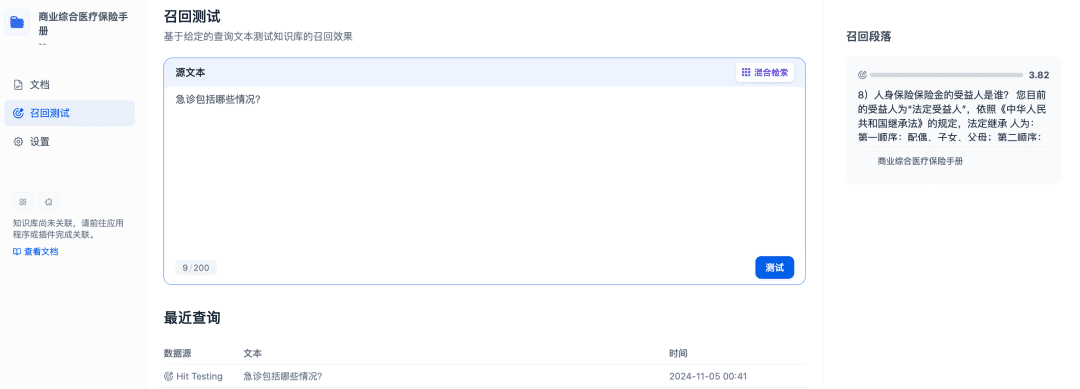
Als Nächstes erstellen Sie eine Chat-Assistenten-App im Chat-Raum: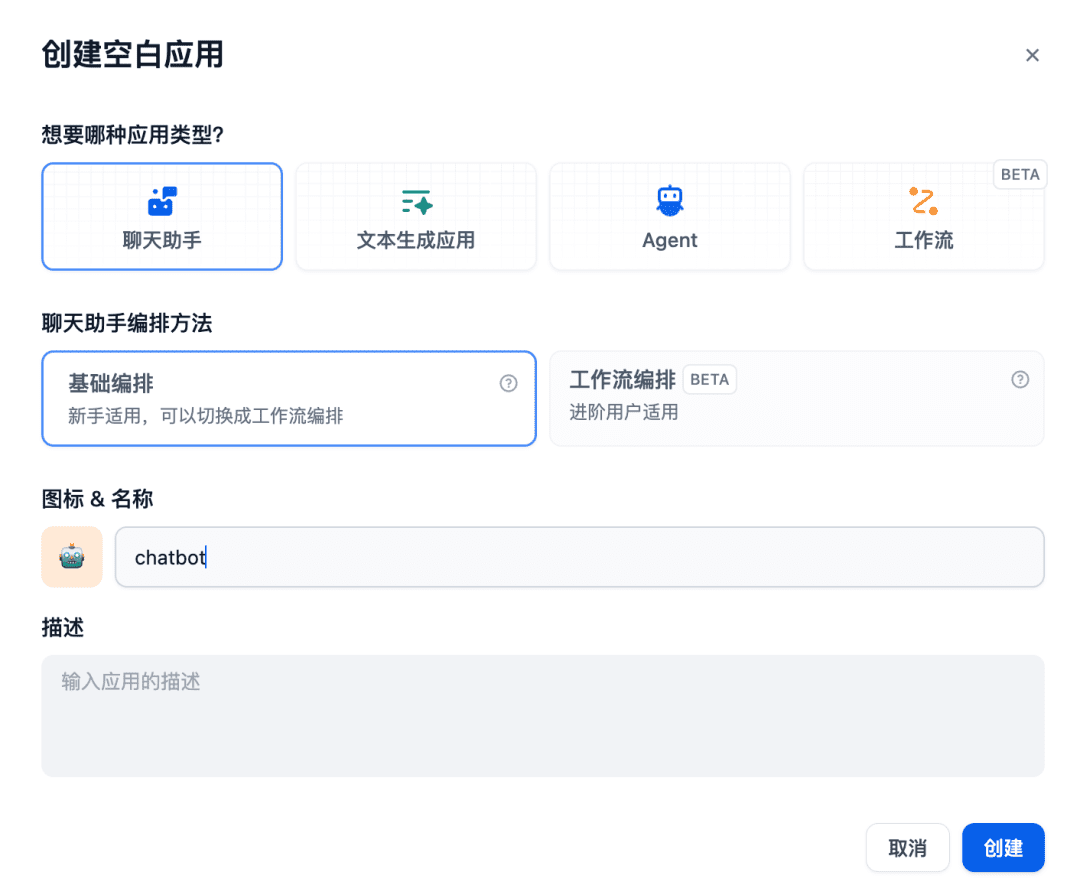
Die relevante Wissensbasis wird dem zu verwendenden Kontext hinzugefügt, woraufhin das Chat-Modell, das Einbettungsmodell und das Reranker-Modell zusammenarbeiten, um die RAG-Anwendung zu unterstützen, wobei das Einbettungsmodell für die Vektorisierung, das Reranker-Modell für die Feinabstimmung des Inhalts des Rückrufs und das Chat-Modell für die Beantwortung auf der Grundlage des Inhalts der Frage und des Kontexts des Rückrufs zuständig ist: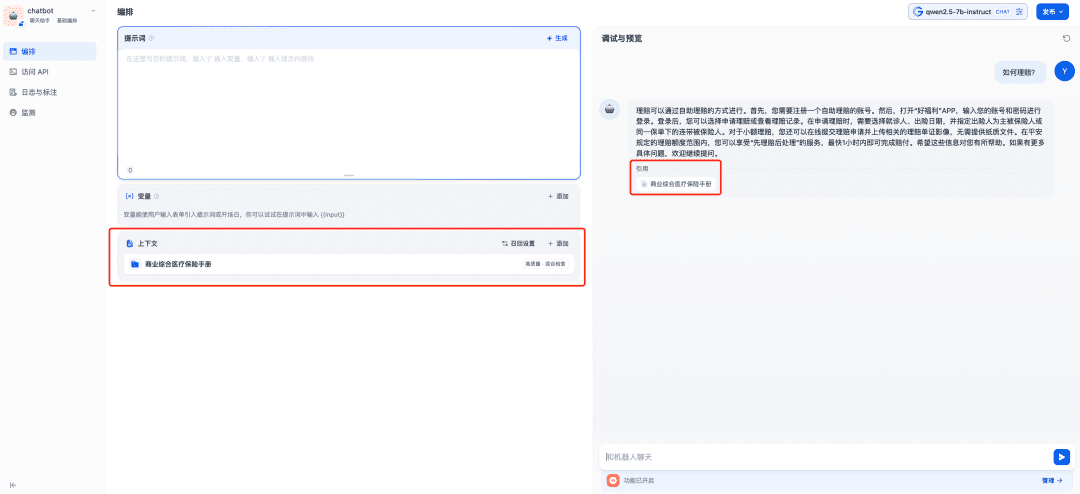
Andere RAG-Systeme können ebenfalls über OpenAI / Jina kompatible APIs mit GPUStack verbunden werden und die Vorteile der verschiedenen Chat-, Embedding- und Reranker-Modelle nutzen, die von der GPUStack-Plattform zur Unterstützung von RAG-Systemen bereitgestellt werden.
Im Folgenden finden Sie eine kurze Beschreibung der Funktion GPUStack.
GPUStack Eigenschaften
- Heterogene GPU-Unterstützung: Unterstützung für heterogene GPU-Ressourcen, unterstützt derzeit Nvidia, Apple Metal, Huawei Rise und Moore Threads sowie andere Arten von GPU/NPUs
- Unterstützung mehrerer Inferenz-Backends: vLLM und llama-box (llama.cpp) werden unterstützt, wobei sowohl die Anforderungen an die Produktionsleistung als auch die Kompatibilität mit mehreren Plattformen berücksichtigt werden.
- Multiplattform-Unterstützung: Unterstützt Linux-, Windows- und macOS-Plattformen und deckt sowohl amd64- als auch arm64-Architekturen ab.
- Unterstützung mehrerer Modelltypen: Unterstützt verschiedene Modelltypen wie das LLM-Textmodell, das VLM-Multimodalmodell, das Einbettungsmodell für Text und das Reranker-Reordering-Modell.
- Unterstützung mehrerer Modell-Repositories: Unterstützt die Bereitstellung von Modellen aus HuggingFace, Ollama Library, ModelScope und privaten Modell-Repositories.
- Vielfältige automatische/manuelle Planungsstrategien: Unterstützt verschiedene Planungsstrategien wie kompakte Planung, dezentrale Planung, spezifizierte Worker-Tag-Planung, spezifizierte GPU-Planung und so weiter.
- Verteilte Inferenz: Wenn ein einzelner Grafikprozessor ein großes Modell nicht ausführen kann, kann die Funktion für verteilte Inferenz von GPUStack verwendet werden, um das Modell automatisch auf mehreren Grafikprozessoren auf verschiedenen Hosts auszuführen
- CPU-Reasoning: Wenn keine GPU oder nicht genügend GPU-Ressourcen vorhanden sind, kann GPUStack CPU-Ressourcen verwenden, um große Modelle auszuführen, und unterstützt zwei CPU-Reasoning-Modi: GPU&CPU-Hybrid-Reasoning und reines CPU-Reasoning.
- Multimodellvergleich: GPUStack in Spielplatz Eine Multi-Modell-Vergleichsansicht wird bereitgestellt, um den Q&A-Inhalt und die Leistungsdaten mehrerer Modelle gleichzeitig zu vergleichen, um die Auswirkungen verschiedener Modelle, verschiedener Gewichte, verschiedener Prompt-Parameter, verschiedener Quantisierungen, verschiedener GPUs und verschiedener Inferenz-Backends auf das Modell zu bewerten.
- GPU- und LLM-Beobachtungsdaten: Bietet umfassende Leistungs-, Nutzungs-, Statusüberwachungs- und Nutzungsdatenmetriken zur Bewertung der GPU- und LLM-Nutzung
GPUStack bietet alle Funktionen der Unternehmensklasse, die für den Aufbau einer privaten großen Model-as-a-Service-Plattform erforderlich sind. Als Open-Source-Projekt erfordert es eine sehr einfache Installation und Einrichtung, um eine private große Model-as-a-Service-Plattform zu erstellen.
Zusammenfassungen
Die obige Anleitung ist eine Konfigurationsanleitung für die Installation von GPUStack und die Integration von GPUStack-Modellen mit Dify. Die Open-Source-Adresse des Projekts lautet: https://github.com/gpustack/gpustack.
GPUStack als barrierearme, einfach zu bedienende, sofort einsatzbereiteOpen-Source-PlattformSie kann Unternehmen dabei helfen, heterogene GPU-Ressourcen schnell zu integrieren und zu nutzen und in kurzer Zeit eine private Big Model-as-a-Service-Plattform auf Unternehmensniveau aufzubauen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Verwandte Beiträge




Keine Kommentare...