 (jemandem eine Stelle etc.) anbieten
(jemandem eine Stelle etc.) anbieten
Visual RAG für PDF mit Vespa - eine Python-basierte Demo-Anwendung

 (jemandem eine Stelle etc.) anbieten
(jemandem eine Stelle etc.) anbieten
Thomas kam im April 2024 als Senior Software Engineer zu Vespa. In seiner letzten Tätigkeit als KI-Berater baute er eine umfangreiche PDF-Sammlung auf der Grundlage von Vespas RAG Anwendungen.
PDFs sind in der Unternehmenswelt allgegenwärtig, und die Möglichkeit, in ihnen zu suchen und Informationen abzurufen, ist ein häufiger Anwendungsfall. Die Herausforderung besteht darin, dass viele PDFs typischerweise in eine oder mehrere der folgenden Kategorien fallen:
- Da es sich um gescannte Dokumente handelt, kann der Text nicht einfach extrahiert werden, so dass eine OCR verwendet werden muss, was die Komplexität noch erhöht.
- Sie enthalten eine große Anzahl von Schaubildern, Tabellen und Diagrammen, die nicht leicht abrufbar sind, selbst wenn der Text extrahiert werden kann.
- Sie enthalten viele Bilder, die manchmal wertvolle Informationen enthalten.
Beachten Sie, dass der Begriff ColPali Es gibt zwei Bedeutungen:
- besondere Modellierung und eine damit verbundene ein Papier oder eine These zu diskutieren (alt) Es trainiert einen LoRa-Adapter auf dem VLM (PaliGemma), um gemeinsame Text- und Bildeinbettungen (eine Einbettung für jeden Fleck im Bild) für die "Post-Interaktion" auf der Grundlage der ColBERT Methoden zur Erweiterung visueller Sprachmodelle.
- Sie stellt auch eine visuelle Dokumentensuche dar Ausrichtungen die die Fähigkeiten von VLMs mit effizienten Post-Interaktionsmechanismen kombiniert. Diese Richtung ist nicht auf das spezifische Modell im Originalbeitrag beschränkt, sondern kann auch auf andere VLMs angewandt werden, wie z. B. unser Vorschlag, ColQwen2 und Vespas Notizbuch .
In diesem Blog-Beitrag erfahren Sie, wie Sie eine Echtzeit-Demo-Anwendung erstellen, die visuelles RAG auf Vespa mit ColPali-Embeds zeigt. Wir beschreiben die Architektur der Anwendung, das Benutzererlebnis und den Technologie-Stack, der zur Erstellung der Anwendung verwendet wurde.
Hier sind einige Screenshots der Demo-Anwendung:
Das erste Beispiel ist keine übliche Abfrage, aber es zeigt die Leistungsfähigkeit der visuellen Suche für bestimmte Arten von Abfragen. Dies ist ein gutes Beispiel für das Paradigma "What You See Is What You Search (WYSIWYS)".
Die Ähnlichkeitszuordnung hebt die ähnlichsten Abschnitte hervor, so dass die Nutzer leicht erkennen können, welche Teile der Seite für die Suchanfrage am relevantesten sind.
 Das zweite Beispiel, eine häufigere Benutzeranfrage, zeigt die Leistungsfähigkeit von ColPali in Bezug auf die semantische Ähnlichkeit.
Das zweite Beispiel, eine häufigere Benutzeranfrage, zeigt die Leistungsfähigkeit von ColPali in Bezug auf die semantische Ähnlichkeit. 
Da er aus erster Hand erfahren hat, wie schwierig es ist, PDFs durchsuchbar zu machen, ist Thomas besonders an den neuesten Entwicklungen im Bereich der visuellen Sprachmodellierung (VLM) interessiert.
Nach der Lektüre des vorherigen Beitrags über ColPali Vespa Blog Beiträge Zusammenarbeit mit Jo Bergum Nach einer Reihe eingehender Diskussionen wurde er dazu inspiriert, ein Projekt zum Aufbau einer visuellen RAG-Anwendung mit Vespa vorzuschlagen.
Bei Vespa haben die Mitarbeiter die Möglichkeit, ein Arbeitsprogramm vorzuschlagen, das sie in jedem Iterationszyklus durchführen möchten. Solange die vorgeschlagene Arbeit mit den Unternehmenszielen übereinstimmt und es keine anderen dringenden Prioritäten gibt, können wir loslegen. Für Thomas, der aus der Beratungsbranche kommt, ist diese Autonomie wie ein frischer Wind.
TL;DR
Wir haben eine Demo-Anwendung in EchtzeitDieser Artikel zeigt, wie man PDF-basiertes Visual RAG mit ColPali-Einbettung in Vespa und Python mit nur FastHTML implementiert.
Wir stellen auch Reproduktionscodes zur Verfügung:
- Ein lauffähiges NotizbuchDamit können Sie Ihre eigene Vespa-Anwendung einrichten, um Visual RAG zu implementieren.
- FastHTML-Anwendung Code, den Sie verwenden können, um eine Webanwendung einzurichten, die mit der Vespa-Anwendung interagiert.
Ziele des Projekts
Das Projekt verfolgt zwei Hauptziele:
1. eine Echtzeit-Demonstration aufzubauen
Auch wenn Entwickler mit einer Demo mit JSON-Terminalausgabe als Benutzeroberfläche zufrieden sein können, bevorzugen die meisten Anwender eine Webschnittstelle.
 Dies wird uns ermöglichen, das PDF Visual RAG in Vespa auf der Grundlage der ColPali-Einbettung zu demonstrieren, von dem wir glauben, dass es für eine breite Palette von Bereichen und Anwendungsfällen wie Recht, Finanzen, Bauwesen, Wissenschaft und Medizin relevant ist.
Dies wird uns ermöglichen, das PDF Visual RAG in Vespa auf der Grundlage der ColPali-Einbettung zu demonstrieren, von dem wir glauben, dass es für eine breite Palette von Bereichen und Anwendungsfällen wie Recht, Finanzen, Bauwesen, Wissenschaft und Medizin relevant ist.
Wir sind zuversichtlich, dass dies in Zukunft wichtig sein wird, aber wir haben noch keine praktischen Anwendungen gesehen, die dies belegen.
Gleichzeitig haben wir dadurch viele wertvolle Erkenntnisse in Bezug auf Effizienz, Skalierbarkeit und Benutzerfreundlichkeit gewonnen. Außerdem waren wir sehr neugierig (oder ein wenig nervös), ob es schnell genug war, um ein gutes Nutzererlebnis zu bieten.
Wir wollten auch einige der nützlichen Funktionen der Vespa hervorheben, zum Beispiel:
- Sortieren nach Stufe
- Vorschläge für Schlüsselwort-Assoziationen
- Multivektor-MaxSim-Berechnung
2. eine Open-Source-Vorlage erstellen
Wir möchten eine Vorlage für andere bereitstellen, damit diese ihre eigenen Visual RAG-Anwendungen erstellen können.
Diese Vorlage sollte für andere ausreichend seinEinfacherEs besteht keine Notwendigkeit, eine große Anzahl von spezifischen Programmiersprachen oder Frameworks zu beherrschen.
Erstellen eines Datensatzes
Für unsere Demo wollten wir einen PDF-Datensatz verwenden, der eine große Menge an wichtigen Informationen in Form von Bildern, Tabellen und Diagrammen enthält. Außerdem benötigen wir einen ausreichend großen Datensatz, um zu demonstrieren, dass es nicht möglich ist, alle Bilder direkt in das VLM hochzuladen (und den Abrufschritt zu überspringen).
ausnutzen gemini-1.5-flash-8bDie maximale Anzahl der eingegebenen Bilder beträgt derzeit 3600.
Da es keinen öffentlichen Datensatz gab, der unseren Anforderungen entsprach, beschlossen wir, unseren eigenen zu erstellen.
Als stolze Norweger haben wir mit Freude festgestellt, dass der Norwegian Government Global Pension Fund (GPFG, auch bekannt als Petroleum Fund) seit 2000 Jahresberichte und Governance-Dokumente auf seiner Website veröffentlicht. Auf der Website wird das Urheberrecht nicht erwähnt und die jüngstenVertretungenWir haben bewiesen, dass er der transparenteste Fonds der Welt ist, daher sind wir zuversichtlich, dass wir diese Daten zu Demonstrationszwecken verwenden können.
Der Datensatz umfasst 116 verschiedene PDF-Berichte aus den Jahren 2000 bis 2024, die insgesamt 6992 Seiten umfassen.
Der Datensatz, der Bilder, Texte, URLs, Seitenzahlen, generierte Fragen, Abfragen und ColPali-Einbettungen enthält, ist jetzt im Internet veröffentlicht. hier sind.

Generierung synthetischer Abfragen und Fragen
Wir generieren auch synthetische Abfragen und Fragen für jede Seite. Diese können für zwei Zwecke verwendet werden:
- Bereitstellung von Vorschlägen für Schlüsselwort-Assoziationen für das Suchfeld während der Eingabe durch den Benutzer.
- Für Bewertungszwecke.
Die Hinweise, die wir zur Erstellung von Fragen und Abfragen verwenden, stammen aus der Dieser großartige Blogbeitrag von Daniel van Strien.
您是一名投资者、股票分析师和金融专家。接下来您将看到挪威政府全球养老基金(GPFG)发布的报告页面图像。该报告可能是年度或季度报告,或关于责任投资、风险等主题的政策报告。
您的任务是生成检索查询和问题,这些查询和问题可以用于在大型文档库中检索此文档(或基于该文档提出问题)。
请生成三种不同类型的检索查询和问题。
检索查询是基于关键词的查询,由 2-5 个单词组成,用于在搜索引擎中找到该文档。
问题是自然语言问题,文档中包含该问题的答案。
查询类型如下:
1. 广泛主题查询:覆盖文档的主要主题。
2. 具体细节查询:涵盖文档的某个具体细节或方面。
3. 可视元素查询:涵盖文档中的某个可视元素,例如图表、图形或图像。
重要指南:
- 确保查询与检索任务相关,而不仅仅是描述页面内容。
- 使用基于事实的自然语言风格来书写问题。
- 设计查询时,以有人在大型文档库中搜索此文档为前提。
- 查询应多样化,代表不同的搜索策略。
将您的回答格式化为如下结构的 JSON 对象:
{
"broad_topical_question": "2019 年的责任投资政策是什么?",
"broad_topical_query": "2019 责任投资政策",
"specific_detail_question": "可再生能源的投资比例是多少?",
"specific_detail_query": "可再生能源投资比例",
"visual_element_question": "总持有价值的时间趋势如何?",
"visual_element_query": "总持有价值趋势"
}
如果没有相关的可视元素,请在可视元素问题和查询中提供空字符串。
以下是需要分析的文档图像:
请基于此图像生成查询,并以指定的 JSON 格式提供响应。
只返回 JSON,不返回任何额外说明文本。
Wir verwenden gemini-1.5-flash-8b Generieren Sie Fragen und Abfragen.
zur Kenntnis nehmen
Beim ersten Durchlauf stellten wir fest, dass einige sehr langwierige Ausgaben erzeugt wurden, so dass wir einen neuen Abschnitt in die generationconfig Hinzufügen der maxOutputTokens=500Das ist sehr hilfreich.
Außerdem sind uns einige Merkwürdigkeiten in den generierten Fragen und Abfragen aufgefallen, wie z. B. das mehrfache Auftreten von "string" in den Fragen. Wir wollen die generierten Fragen und Abfragen noch eingehender überprüfen.
Python durchgängig verwenden
Unsere Zielgruppe ist die wachsende Data-Science- und KI-Community. Diese Gemeinschaft wird wahrscheinlich einer der größten Beitragszahler für Python auf GitHub sein. Octoverse StatusberichtEiner der Hauptgründe, warum sie als die beliebteste (und am schnellsten wachsende) Programmiersprache gilt, ist, dass sie eine der beliebtesten Programmiersprachen der Welt ist.
Wir müssen Python am Backend für die in die Abfrage eingebetteten Schlussfolgerungen verwenden (unter Verwendung der colpali-engine-Library), bis Vespa nativ die ColpaliEmbedder (In Entwicklung, siehe Github-Problem). Wenn andere Sprachen (und deren Frameworks) für das Frontend verwendet werden, erhöht sich die Komplexität des Projekts, wodurch es für andere schwieriger wird, die Anwendung zu reproduzieren.
Deshalb haben wir beschlossen, die gesamte Anwendung in Python zu erstellen.
Wahl des Front-End-Frameworks
Streamlit und Gradio
Wir geben zu, dass es sehr einfach ist, einfache PoCs (Proof of Concepts) mit Gradio und Streamlit zu erstellen, und wir haben sie in der Vergangenheit auch für diesen Zweck verwendet. Aber es gibt zwei Hauptgründe, warum wir uns gegen sie entschieden haben:
- Wir brauchten eine professionell aussehende Benutzeroberfläche, die in einer Produktionsumgebung verwendet werden konnte.
- Wir brauchen eine gute Leistung. Ein paar Sekunden Wartezeit oder ein gelegentliches Einfrieren der Benutzeroberfläche sind für die Anwendung, die wir präsentieren wollen, nicht ausreichend.
So gerne wir auch trainieren, so wenig mögen wir die Meldung "Running" in der oberen rechten Ecke des Streamlit-Bildschirms.
FastHTML als Retter in der Not
Wir sind. Antwort.ai ihrer treuen Fans. Als sie also Anfang dieses Jahres FastHTML3Wenn das der Fall ist, probieren wir es gerne aus.
FastHTML ist ein Framework zur Erstellung moderner Webanwendungen mit reinem Python. Laut seiner Vision (der Zukunft)::
FastHTML ist ein universelles, vollwertiges Web-Programmiersystem, das in die gleiche Kategorie wie Django, NextJS und Ruby on Rails fällt. Seine Vision ist es, der einfachste Weg zu sein, um schnelle Prototypen zu erstellen, aber auch der einfachste Weg, um skalierbare, leistungsstarke und reichhaltige Anwendungen zu erstellen.
FastHTML verwendet die zugrunde liegende Sternchen im Gesang antworten uvicorn.
Es kommt mit Pico-CSS für das Styling. Da Leandro, ein erfahrener Webentwickler im Team, Tailwind CSS ausprobieren wollte, zusammen mit unserem kürzlich entdeckten shad4fastWir haben uns für eine Kombination von FastHTML und shadcn/ui Die schönen UI-Komponenten in der
Pyvespa
Unser Vespa-Python-Kunde pyvespa In der Vergangenheit wurde es hauptsächlich für das Prototyping von Vespa-Anwendungen verwendet. Wir haben jedoch kürzlich daran gearbeitet, mehr Unterstützung für Vespa-Funktionen durch pyvespa bereitzustellen. Das Deployment in die Produktion wird nun unterstützt und die erweiterte Konfiguration von Vespa über pyvespa wurde hinzugefügt! services.xml Funktion der Datei. Für Details, siehe diese Beispiele und Details im Notizbuch.
Daher können die meisten Vespa-Anwendungen, die keine eigenen Java-Komponenten benötigen, mit pyvespa erstellt werden.
Eine Anekdote:
Die erweiterten Konfigurationsmöglichkeiten von pyvespa werden durch die Tatsache beeinflusst, dass FastHTML ft-inspiriert von der Art und Weise, wie Komponenten umhüllt und in HTML-Tags umgewandelt werden. In pyvespa haben wir eine vt-Komponente führt eine ähnliche Operation durch und wandelt sie in eine Vespa um services.xml Stichworte. Interessierte Leserinnen und Leser können sich informieren über Diese PR Erfahren Sie mehr. Dieser Ansatz spart uns eine Menge Arbeit im Vergleich zur Implementierung benutzerdefinierter Klassen für alle unterstützten Tags.
Außerdem ermöglichte uns der Prozess der Erstellung einer Vespa-Anwendung mit pyvespa eine praktische Validierung.
Software
Als ColPali-Embedder mit nativer Unterstützung für Vespa ist er noch in der WIP wissen wir, dass die GPU benötigt wird, um die Inferenz abzuschließen. Aus unseren Experimenten in Colab schließen wir, dass eine T4-Instanz ausreichend ist.
Um die Einbettung zu generieren, bevor die PDF-Seiten des Datensatzes in Vespa eingebettet werden, haben wir die Verwendung eines serverlosen GPU-Anbieters (Modal (einer unserer Favoriten). Da der Datensatz jedoch "nur" 6.692 Seiten umfasst, haben wir ein Macbook M2 Pro verwendet und 5-6 Stunden gearbeitet, um diese Einbettungen zu erstellen.
Treuhandschaft
Hier gibt es eine Reihe von Möglichkeiten. Wir könnten uns für einen traditionellen Cloud-Anbieter wie AWS, GCP oder Azure entscheiden, aber das würde einen höheren Aufwand für uns bedeuten, um die Infrastruktur einzurichten und zu verwalten, und es würde es für andere schwieriger machen, die Anwendung zu replizieren.
Wir haben gelernt, dass Gesicht umarmen Räume Sie bieten einen Hosting-Service an, bei dem Sie nach Bedarf GPUs hinzufügen können. Außerdem gibt es eine Schaltfläche "Diesen Bereich klonen", die es anderen sehr leicht macht, die Anwendung zu kopieren.
Wir fanden Antwort.ai Erzeugt eine Wiederverwendbare Bibliothekendie verwendet werden kann, um FastHTML-Anwendungen auf Hugging Face Spaces einzusetzen. Bei weiteren Recherchen fanden wir jedoch heraus, dass ihr Ansatz das Docker SDK verwendet, um Spaces zu manipulieren, und dass es eigentlich einfachere Wege gibt, dies zu tun.
Durch den Einsatz von Benutzerdefinierte Python-Räume.
Boden huggingface-hub Dokumentation::
Obwohl dies kein offizieller Arbeitsablauf ist, können Sie Ihren eigenen Python + Interface Stack in Spaces ausführen, indem Sie Gradio als SDK wählen und eine Front-End-Schnittstelle auf Port 7860 bereitstellen.
Anekdote 2: Es gibt einen Tippfehler in der Dokumentation, der besagt, dass der Port, über den der Dienst bereitgestellt wird, 7680. Glücklicherweise haben wir nicht lange gebraucht, um herauszufinden, dass der richtige Anschluss der folgende sein sollte 7860und reichte eine PRvon Julien Chaumond, CTO von Hugging Face, zusammengeführt und der Fehler behoben. Aufgaben der Checkliste abgeschlossen!
visuelles Sprachmodell
Für den Teil "Generierung" der visuellen RAG benötigen wir ein visuelles Sprachmodell (VLM) zur Generierung von Antworten auf der Grundlage der von Vespa erhaltenen Dokumente mit dem höchsten K-Ranking.
Vespa Native Unterstützung LLM(Large Language Model), entweder extern oder intern integriert, aber VLM (Visual Language Model) wird in Vespa noch nicht nativ unterstützt.
Mit OpenAI, Anthropic und Google, die im letzten Jahr alle hervorragende visuelle Sprachmodelle (VLMs) veröffentlicht haben, wächst das Feld schnell. Aus Leistungsgründen wollten wir ein kleineres Modell wählen, da Google die Zwillinge API in letzter Zeit die Erfahrung der Entwickler verbessert hat, haben wir beschlossen, die gemini-1.5-flash-8b.
Natürlich ist eine quantitative Bewertung verschiedener Modelle empfehlenswert, bevor man sich für ein Modell in einer Produktionsumgebung entscheidet, aber das würde den Rahmen dieses Projekts sprengen.
bauen
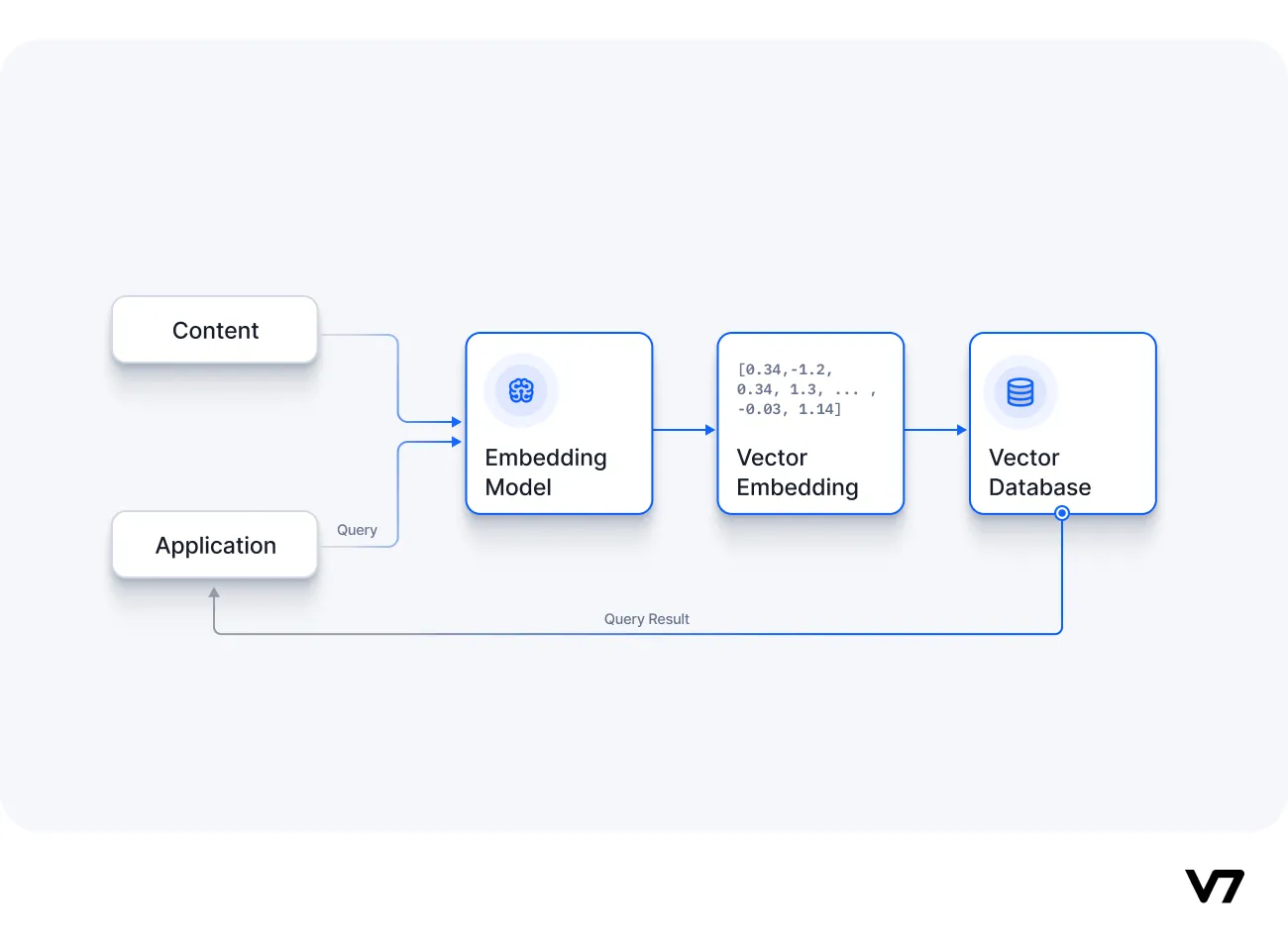
Mit dem vorhandenen Technologie-Stack können wir mit der Erstellung der Anwendung beginnen. Die High-Level-Architektur der Anwendung sieht wie folgt aus:

Vespa Anwendung
Zu den wichtigsten Komponenten der Vespa-Anwendung gehören:
- Dokumente, die Felder und Typen enthalten Schemadefinition.
- Profil des Ranges Definition.
- eine
services.xmlKonfigurationsdatei.
Alle von ihnen. möglich Definiert in Python mit pyvespa, aber wir empfehlen, auch die generierten Konfigurationsdateien zu überprüfen, was durch den Aufruf der app.package.to_files() zu implementieren. Ausführliche Informationen finden Sie unter pyvespa-Dokumentation.
Rangliste Konfiguration
Eines der am meisten unterschätzten Merkmale der Vespa ist die Rangfolge nach Etappen Funktion. Sie ermöglicht die Definition mehrerer Ranking-Profile, von denen jedes unterschiedliche (oder geerbte) Ranking-Phasen enthalten kann, die auf Inhaltsknoten (Phase 1 und Phase 2) oder Containerknoten ausgeführt werden können (Weltbühne).
So können wir viele verschiedene Anwendungsfälle getrennt behandeln und für jede Situation das ideale Gleichgewicht zwischen Latenz, Kosten und Qualität finden.
Lesen Sie, was unser CEO Jon Bratseth über die architektonische Umkehrung der Verlagerung der Rechenleistung auf die Datenseite der Gleichung zu sagen hat. Dieser Blogbeitrag.
Für diese Anwendung haben wir 3 verschiedene Ranking-Konfigurationen definiert:
zur Kenntnis nehmen abrufen (Daten)Der Schritt besteht darin, die Abfrage durch den yql angegeben, und dieRanking-Strategiewird in der Rangordnungskonfigurationsdatei angegeben (die Teil des Anwendungspakets ist, das zum Zeitpunkt der Bereitstellung bereitgestellt wird).
1. reines ColPali
Der in unserer Anwendung für diesen Ranking-Modus verwendete yql lautet:
select title, text from pdf_page where targetHits:{100}nearestNeighbor(embedding,rq{i}) OR targetHits:{100}nearestNeighbor(embedding,rq{i+1}) .. targetHits:{100}nearestNeighbor(embedding,rq{n}) OR userQuery();
Wir werden auch hnsw.exploreAdditionalHits Der Parameter wird auf 300 eingestellt, um sicherzustellen, dass während der Abrufphase keine relevanten Treffer übersehen werden. Bitte beachten Sie, dass dies mit Leistungseinbußen verbunden ist.
darunter auch rq{i} ist die i-te in der Abfrage Token (die als Parameter in der HTTP-Anfrage angegeben werden muss).n ist die maximale Anzahl der abzurufenden Abfrage-Token (in dieser Anwendung werden 64 verwendet).
Diese Ranking-Konfiguration verwendet die max_sim_binary Ranking-Ausdruck, der die optimierte Hamming-Distanz-Berechnungsfunktion in Vespa nutzt (weitere Informationen unter Skalierung von ColPali auf Milliardenbeträge. Dies wird in der ersten Stufe des Rankings verwendet, und die 100 besten Treffer werden unter Verwendung der vollständigen Fließkommadarstellung der ColPali-Einbettung neu gereiht.
2. rein textbasiertes Ranking (BM25)
In diesem Fall stützen wir uns nur auf die weakAnd Rufen Sie das Dokument ab.
select title, text from pdf_page where userQuery();
In der Ranking-Phase verwenden wir bm25 Durchführung der Phase I des Rankings (keine Phase II).
Beachten Sie, dass wir für eine optimale Leistung wahrscheinlich eine Kombination aus textbasierten und bildbasierten Einstufungsmerkmalen verwenden werden (z. B. unter Verwendung der Integration der wechselseitigen Rangliste), aber in dieser Demonstration wollen wir die Unterschiede zwischen ihnen aufzeigen und nicht die optimale Kombination finden.
3. mischen BM25 + ColPali
In der Retrieval-Phase verwenden wir das gleiche yql wie in der reinen ColPali-Ranking-Konfiguration.
Wir stellten fest, dass ColPali bei einigen, vor allem kürzeren Suchanfragen viele Seiten ohne Text (nur mit Bildern) gefunden hat, während viele der gesuchten Antworten auf Seiten mit Text zu finden waren.
Um dieses Problem zu lösen, fügten wir eine zweite Stufe hinzu, die den BM25-Score und den ColPali-Score kombiniert und eine lineare Kombination der beiden Scores verwendet (max_sim + 2 * (bm25(title) + bm25(text))).
Diese Methode basiert auf einfachen Heuristiken, aber es wäre vorteilhafter, die optimalen Gewichtungen für verschiedene Merkmale durch Ranking-Experimente zu ermitteln.
Fragmentgenerierung in Vespa
Im Such-Frontend ist es üblich, Auszüge aus dem Ausgangstext mit bestimmten Wörtern in einem fett (Schriftart) (Hervorgehoben) Anzeige.

Die Anzeige von Ausschnitten passender Suchbegriffe im Kontext ermöglicht es den Nutzern, schnell festzustellen, ob die Ergebnisse ihren Informationsbedürfnissen wahrscheinlich entsprechen.
In Vespa wird diese Funktion als "dynamische Snippets" bezeichnet, und es gibt verschiedene Parameter, die angepasst werden können, z. B. wie viel Umgebungskontext einbezogen werden soll und welche Beschriftungen zur Hervorhebung passender Wörter verwendet werden.
In dieser Demo zeigen wir zum Vergleich sowohl den Ausschnitt als auch den gesamten extrahierten Text der Seite.
Um das visuelle Rauschen in den Ergebnissen zu reduzieren, haben wir die Stoppwörter (und, in, der usw.) aus der Suchanfrage des Benutzers entfernt, damit sie nicht hervorgehoben werden.
Erfahren Sie mehr über die dynamischen Segmente von Vespa.
Abfrage von Empfehlungen in Vespa
Eine gängige Funktion bei der Suche sind die "Suchvorschläge", die angezeigt werden, während der Nutzer tippt.
Echte Nutzeranfragen werden oft verwendet, um vorberechnete Ergebnisse zu liefern, aber hier haben wir keinen Nutzerverkehr zu analysieren.

In diesem Beispiel verwenden wir eine einfache Teilstringsuche, die ein vom Benutzer eingegebenes Präfix mit einer aus einer PDF-Seite generierten relevanten Frage vergleicht, um Vorschläge zu machen.
Die yql-Abfrage, mit der wir diese Vorschläge erhalten, lautet:
select questions from pdf_page where questions matches (".*{query}.*")
Ein Vorteil dieses Ansatzes ist, dass alle Fragen, die in den Empfehlungen auftauchen, durch die verfügbaren Daten bestätigt werden können!
Wir hätten dafür sorgen können, dass die Seite, die die vorgeschlagene Frage generiert, immer unter den ersten drei Antworten erscheint (indem wir in der Sortierkonfiguration eine Ähnlichkeitsmetrik zwischen der Benutzerabfrage und der vom Dokument generierten Frage hinzugefügt hätten), aber das wäre im Hinblick auf die Demonstration der Funktionsweise des ColPali-Modells ein bisschen "geschummelt" gewesen.
Benutzererfahrung
Wir sind in der glücklichen Lage, dass der leitende Wissenschaftler von Jo Bergum Er bekam großartiges UX-Feedback von uns. Er drängte uns, die UX "schnell und flüssig" zu gestalten. Die Menschen sind an Google gewöhnt, daher besteht kein Zweifel daran, dass Geschwindigkeit für das Nutzererlebnis bei der Suche (und RAG) entscheidend ist. In der KI-Gemeinschaft wird dies immer noch etwas unterschätzt, denn viele Menschen scheinen damit zufrieden zu sein, 5-10 Sekunden auf eine Antwort zu warten. Und wir wollen Antwortzeiten in Millisekunden erreichen.
Aufgrund seines Feedbacks müssen wir einen gestaffelten Anfrageprozess einrichten, um zu vermeiden, dass wir auf die Rückgabe des vollständigen Bildes und des Ähnlichkeitszuordnungstensors von Vespa warten müssen, bevor wir die Ergebnisse anzeigen können.
Die Lösung besteht darin, zunächst nur die wichtigsten Daten aus den Ergebnissen zu extrahieren. Für uns bedeutet das, dass wir nur die titleundurlundtextundpage_nosowie eine verkleinerte (unscharfe) Version des Bildes (32x32 Pixel) für die Anzeige der ersten Suchergebnisse. Auf diese Weise können wir die Ergebnisse sofort anzeigen und das Laden des vollständigen Bildes und der Ähnlichkeitszuordnung im Hintergrund fortsetzen.
Der gesamte UX-Prozess ist unten dargestellt:
 Die Hauptursachen für Verzögerungen sind:
Die Hauptursachen für Verzögerungen sind:
- Inferenzzeit für die Generierung von ColPali-Einbettungen (erfolgt auf der GPU, abhängig von der Anzahl der Token in der Abfrage)
- Deshalb haben wir beschlossen, die
@lru_cacheDekorator, um zu vermeiden, dass die Einbettung für dieselbe Abfrage mehrmals neu berechnet wird.
- Deshalb haben wir beschlossen, die
- Umarmende Netzwerklatenz zwischen Face Spaces und Vespa (einschließlich TCP-Handshakes)
- Die Übertragungszeit für vollständige Bilder ist ebenfalls beträchtlich (etwa 0,5 MB pro Bild).
- Die Größe des Ähnlichkeitsabbildungstensors ist größer (
n_query_tokensxn_images(x 1030 Patches x 128).
- Die Erstellung eines Hybridbildes mit Ähnlichkeitsabbildung ist eine rechenintensive Aufgabe, die jedoch mit dem
fastcore(in Form eines Nominalausdrucks)@threadedDer Dekorator wird in einer Multithreading-Hintergrundaufgabe ausgeführt, bei der jedes Bild seinen entsprechenden Endpunkt abfragt, um zu prüfen, ob die Ähnlichkeitszuordnung bereit ist.
Stresstest
Wir waren besorgt über die Leistung unserer Anwendung bei einem starken Anstieg des Datenverkehrs und führten daher ein einfaches Stresstest-Experiment durch. Das Experiment wurde mit Hilfe eines Browser-Entwicklungstools durchgeführt, um Anfragen zu senden /fetch_results Der cURL-Befehl wurde kopiert (mit nicht aktivierter Zwischenspeicherung) und in einer Schleife über 10 parallele Terminals ausgeführt. (An diesem Punkt haben wir die @lru_cache Dekorateur).
am Ende
Obwohl die Tests sehr einfach waren, zeigten die ersten Tests, dass der Engpass beim Suchdurchsatz die Berechnung der ColPali-Einbettungen auf den GPUs im Huggingface-Raum war, während das Vespa-Backend problemlos mehr als 20 Abfragen pro Sekunde bei sehr geringem Ressourcenverbrauch bewältigen konnte. Wir denken, dass dies für Demos mehr als ausreichend ist. Wenn wir skalieren müssen, wäre unser erster Schritt, eine größere GPU-Instanz für den Huggingface-Raum zu aktivieren.
Die Vespa-Anwendung zeigt eine gute Leistung unter Last, wie die folgenden Diagramme zeigen.


Überlegungen zur Verwendung von FastHTML
Die wichtigste Erkenntnis aus dem Einsatz von FastHTML ist, dass es die Grenzen zwischen Front-End- und Back-End-Entwicklung aufhebt. Der Code ist eng integriert, was es uns allen ermöglicht, jeden Teil der Anwendung zu verstehen und dazu beizutragen. Dies sollte nicht unterschätzt werden.
Wir haben es sehr genossen, dass wir die Entwicklungswerkzeuge des Browsers nutzen konnten, um den Front-End-Code zu untersuchen und das meiste davon tatsächlich zu sehen und zu verstehen.
Der Entwicklungs- und Bereitstellungsprozess wird im Vergleich zur Verwendung eines eigenständigen Front-End-Frameworks erheblich vereinfacht.
Sie ermöglicht uns die Nutzung uv Geschäftsführung Eigentum Abhängigkeiten, was die Art und Weise, wie wir in Python mit Abhängigkeiten umgehen, drastisch verändert.
Thomas' Ansicht:
Als Entwickler mit einem datenwissenschaftlichen und KI-Hintergrund, der Python bevorzugt, aber mit mehreren JS-Frameworks gearbeitet hat, waren meine Erfahrungen sehr positiv. Ich fühlte mich besser in der Lage, mich mit Front-End-bezogenen Aufgaben zu beschäftigen, ohne dem Projekt zu viel Komplexität zu verleihen. Ich habe es sehr genossen, dass ich jeden Teil der Anwendung verstehen konnte.
Der Blick von Andreas:
Ich arbeite schon lange an Vespa, habe mich aber noch nicht viel mit Python oder Frontend-Entwicklung befasst. In den ersten ein oder zwei Tagen fühlte ich mich ein wenig überfordert, aber es ist so aufregend, dass ich mit dem gesamten Stack arbeiten kann und die Auswirkungen meiner Änderungen fast in Echtzeit sehe! Mit Hilfe des großen Sprachmodells ist es einfacher denn je, in eine unbekannte Umgebung einzusteigen. Mir hat es sehr gut gefallen, dass wir Ähnlichkeitszuordnungen mit viel geringerer Latenz und geringerem Ressourcenverbrauch erstellen konnten, indem wir die Ähnlichkeit von Bildfeldern durch Tensorausdrücke in Vespa berechnet haben (die Vektoren sind bereits im Speicher abgelegt) und sie mit den Suchergebnissen zurückgegeben haben.
Leandros Ansicht:
Als Entwickler mit einer soliden Grundlage in der Webentwicklung mit React, JavaScript, TypeScript, HTML und CSS war der Wechsel zu FastHTML relativ einfach. Das direkte HTML-Element-Mapping des Frameworks war sehr konsistent mit meinem Vorwissen, was die Lernkurve reduzierte. Die größte Herausforderung bestand darin, sich an die Python-basierte Syntax von FastHTML zu gewöhnen, die sich von der Standard-HTML/JS-Struktur unterscheidet.
Ist visuelle Technologie alles, was Sie brauchen?
Wir haben gesehen, dass die Verwendung der späten Interaktionseinbettung auf Token-Ebene aus dem Vision Language Model (VLM) für bestimmte Arten von Abfragen sehr leistungsfähig ist, aber wir sehen sie nicht als Einheitslösung, sondern eher als ein sehr wertvolles Werkzeug im Werkzeugkasten.
Neben ColPali gab es im vergangenen Jahr weitere Innovationen im Bereich der visuellen Suche. Zwei besonders interessante Ansätze sind:
- Dokument-Screenshot-Einbettungen (DSE)5 - Ein duales Kodierungsmodell zur Erzeugung dichter Einbettungen für Screenshots von Dokumenten und zur Verwendung dieser Einbettungen für die Suche.
- IBM Docling - Eine Bibliothek zum Parsen verschiedener Dokumenttypen (z. B. PDF, PPT, DOCX usw.) in Markdown, die OCR vermeidet und stattdessen Computer-Vision-Modelle verwendet.
Vespa unterstützt die Kombination dieser Ansätze und ermöglicht es Entwicklern, die attraktivste Balance zwischen Latenz, Kosten und Qualität für bestimmte Anwendungsfälle zu finden.
Wir können uns eine Anwendung vorstellen, die qualitativ hochwertige Textextraktion mit Docling oder ähnlichen Tools, intensives Retrieval durch Einbettung von Screenshots in Dokumente und intensives Retrieval durch Textmerkmale und ColPali-ähnliche Modellierung der MaxSim Die Ergebnisse werden sortiert. Wenn Sie die Leistung wirklich verbessern wollen, können Sie all diese Funktionen sogar mit Funktionen wie den folgenden kombinieren XGBoost vielleicht LichtGBM Die Kombination aus dem GBDT-Modell der
ColPali ist zwar ein leistungsfähiges Werkzeug, um schwer zu extrahierende Informationen in Texten abrufbar zu machen, aber es ist kein Allheilmittel und sollte mit anderen Ansätzen kombiniert werden, um eine optimale Leistung zu erzielen.
fehlende Verbindung
Die Modellierung ist vorübergehend, während die Bewertung dauerhaft ist.
Das Hinzufügen von automatisierten Auswertungen würde den Rahmen dieser Demo sprengen, aber wir empfehlen Ihnen dringend, einen Auswertungsdatensatz für Ihren eigenen Anwendungsfall zu erstellen. Sie können LLM-as-a-judge zum Bootstrapping verwenden (siehe dies Blog-BeiträgeErfahren Sie mehr darüber, wie wir Ihnen suche.vespa.ai (Dies zu erkennen).
Vespa bietet eine Reihe von einstellbaren Parametern, und durch die Bereitstellung quantitativer Rückmeldungen zu verschiedenen Experimenten können Sie die attraktivsten Kompromisse für Ihren spezifischen Anwendungsfall finden.
zu einem Urteil gelangen
Wir haben eine Live-Demo-Anwendung erstellt, die zeigt, wie man in Vespa mit ColPali-Einbettung eine visuelle RAG-Abfrage von PDFs durchführt.
Wenn Sie bis hierher gelesen haben, sind Sie vielleicht an dem Code interessiert. Sie finden den Code in der hier (literarisch) Finden Sie den Code für die App.
Erstellen Sie jetzt Ihre eigene visuelle RAG-Anwendung!
Wer mehr über visuelles Retrieval, ColPali oder Vespa erfahren möchte, kann sich gerne anschließen! Vespas Slack-Gemeinschaft Stellen Sie eine Frage, suchen Sie Hilfe in der Community oder informieren Sie sich über die neuesten Entwicklungen bei Vespa.
allgemeine Probleme
Erfordert die Verwendung von ColPali den Einsatz eines Grafikprozessors für die Inferenz?
Derzeit müssen wir die GPU nutzen, um Abfragen in einer angemessenen Zeitspanne zu beantworten.
Für die Zukunft erwarten wir, dass sich die Qualität und Effizienz (z.B. kleinere Einbettungen) von ColPali-ähnlichen Modellen verbessern und weitere ähnliche Modelle entstehen werden, wie wir es bei der ColBERT-Modellfamilie gesehen haben, z.B. bei answer.ai's antwortai-colbert-klein-v1Das ColBERT-Modell wurde zum ersten Mal entwickelt, und seine Leistung übertrifft die des ursprünglichen ColBERT-Modells, obwohl es weniger als ein Drittel der Größe des ursprünglichen Modells hat.
Siehe auch Vespa Blog Erfahren Sie mehr über die Verwendung von Vespas answerai-colbert-small-v1.
Ist es möglich, ColPali in Verbindung mit einem Abfragefilter in Vespa zu verwenden?
können. In dieser Anwendung fügen wir die Seite zum published_year Feld, aber seine Funktionalität als Filteroption wurde noch nicht in das Frontend implementiert.
Wann wird Vespa nativ ColPali-Einbettungen unterstützen?
Siehe auch Dieses GitHub-Problem.
Lässt sich dies auf Milliarden von Dokumenten übertragen?
Ja, Vespa unterstützt die horizontale Skalierung und ermöglicht es Ihnen, den Kompromiss zwischen Latenz, Kosten und Qualität für bestimmte Anwendungsfälle anzupassen.
Kann diese Demo angepasst werden, um ColQwen2 zu unterstützen?
Es ist möglich, aber es gibt einige Unterschiede bei der Berechnung von Ähnlichkeitskarten.
Siehe auch Dieses Notizbuch Das ist der Ausgangspunkt.
Kann ich diese Demo mit meinen eigenen Daten durchführen?
Unbedingt! Durch die Einstellung der vorgesehenen Notizbuch Indem Sie auf Ihre Daten verweisen, können Sie Ihre eigene Vespa-Anwendung für das visuelle RAG einrichten. Sie können auch die mitgelieferte Webanwendung als Ausgangspunkt für Ihr eigenes Frontend verwenden.
bibliographie
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...