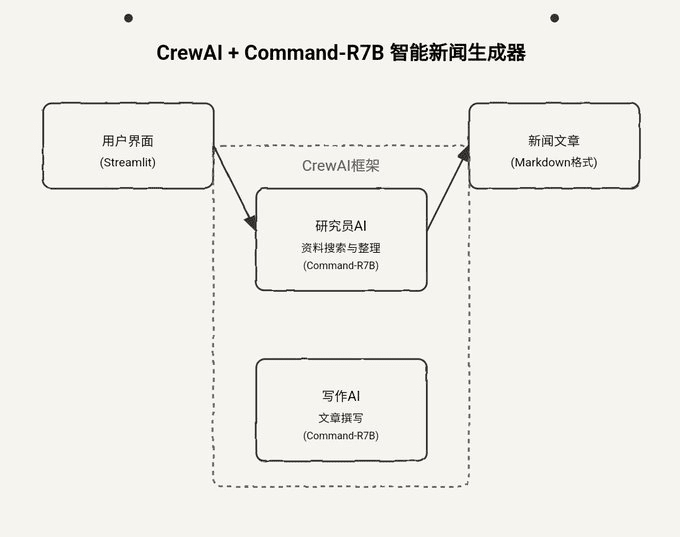
Native RAG-Anwendungen mit DeepSeek R1 und Ollama
kurz
Dieses Dokument beschreibt die Verwendung des DeepSeek R1 und Ollama die Erstellung lokalisierter RAG-Anwendungen (Retrieval Augmented Generation). Es ist auch eine gute Möglichkeit, das Beste aus dem Aufbau einer lokalen RAG-Anwendung mit LangChain Der Nachtrag.
Wir werden den gesamten Implementierungsprozess anhand von Beispielen demonstrieren, einschließlich Dokumentenverarbeitung, Vektorspeicherung, Modellaufrufe und andere wichtige Schritte. Dieses Tutorium verwendet DeepSeek-R1 1.5B als Basissprachmodell. In Anbetracht der Tatsache, dass verschiedene Modelle ihre eigenen Merkmale und ihre eigene Leistung haben, können die Leser andere geeignete Modelle wählen, um sie je nach den tatsächlichen Bedürfnissen des Projekts zu implementieren. RAG System.
Hinweis: Dieses Dokument enthält wichtige Codeschnipsel und ausführliche Erläuterungen. Der vollständige Code ist zu finden unter Notizbuch .
vorläufige Vorbereitung
Zunächst müssen wir Ollama herunterladen und die Umgebung konfigurieren.
Das GitHub-Repository von Ollama enthält eine detaillierte Beschreibung, die im Folgenden kurz zusammengefasst wird.
Schritt1: Ollama herunterladen.
Herunterladen von und doppelklicken Sie darauf, um die Ollama-Anwendung auszuführen.

Schritt 2: Überprüfen Sie die Installation.
Geben Sie in die Befehlszeile ein ollamaWenn die folgende Meldung erscheint, wurde Ollama erfolgreich installiert.

Schritt 3: Ziehen Sie das Modell.
- In der Befehlszeile finden Sie unter Ollama Modell Liste im Gesang antworten Liste der Modelle zur Texteinbettung Ziehen des Modells. In diesem Lernprogramm nehmen wir die
deepseek-r1:1.5bim Gesang antwortennomic-embed-textBeispiel.- Kommandozeileneingabe
ollama pull deepseek-r1:1.5bGenerische Open-Source-Modelle für große Sprachen abrufendeepseek-r1:1.5b(Beim Ziehen von Modellen kann es langsam sein. Wenn es einen Fehler beim Ziehen gibt, können Sie den Befehl zum Ziehen erneut eingeben) - Kommandozeileneingabe
ollama pull nomic-embed-textziehen Modell der Texteinbettungnomic-embed-text.
- Kommandozeileneingabe
- Wenn die Anwendung läuft, befinden sich alle Modelle automatisch in der
localhost:11434Zum Start. - Beachten Sie, dass Sie bei der Auswahl des Modells Ihre lokalen Hardware-Fähigkeiten, die Referenz-Videospeichergröße für dieses Tutorial
CPU Memory > 8GB.
Schritt 4: Einsatz des Modells.
Im Befehlszeilenfenster wird der folgende Befehl zur Bereitstellung des Modells ausgeführt.
ollama run deepseek-r1:1.5b

Es ist auch möglich, das Verteilungsmodell direkt von der Befehlszeile aus zu starten, zum Beispiel
ollama run deepseek-r1:1.5b.

Beachten Sie, dass die folgenden Schritte nicht erforderlich sind, wenn Sie nur DeepSeek R1-Modelle mit Ollama bereitstellen möchten.
Schritt 5: Installieren Sie die Abhängigkeiten.
# langchain_community
pip install langchain langchain_community
# Chroma
pip install langchain_chroma
# Ollama
pip install langchain_ollama
Nachdem das geklärt ist, beginnen wir mit dem schrittweisen Aufbau einer Lösung auf der Grundlage von LangChain, Ollama und DeepSeek R1 Es folgt eine detaillierte Beschreibung der Implementierungsschritte. Die Implementierungsschritte werden im Folgenden detailliert beschrieben.
1. das Laden von Dokumenten
Laden Sie PDF-Dokumente und schneiden Sie sie in Textblöcke geeigneter Größe.
from langchain_community.document_loaders import PDFPlumberLoader
file = "DeepSeek_R1.pdf"
# Load the PDF
loader = PDFPlumberLoader(file)
docs = loader.load()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(docs)
2. die Initialisierung des Vektorspeichers
Verwenden Sie die Chroma-Datenbank, um die Dokumentvektoren zu speichern, und konfigurieren Sie das von Ollama bereitgestellte Einbettungsmodell.
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings
local_embeddings = OllamaEmbeddings(model="nomic-embed-text")
vectorstore = Chroma.from_documents(documents=all_splits, embedding=local_embeddings)
3. die Konstruktion von Kettenausdrücken
Richten Sie Modell- und Cue-Vorlagen ein, um Verarbeitungsketten zu erstellen.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import ChatOllama
model = ChatOllama(
model="deepseek-r1:1.5b",
)
prompt = ChatPromptTemplate.from_template(
"Summarize the main themes in these retrieved docs: {docs}"
)
# 将传入的文档转换成字符串的形式
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
chain = {"docs": format_docs} | prompt | model | StrOutputParser()
question = "What is the purpose of the DeepSeek project?"
docs = vectorstore.similarity_search(question)
chain.invoke(docs)
4) QA mit Suche
Integrieren Sie Such- und Q&A-Funktionen.
from langchain_core.runnables import RunnablePassthrough
RAG_TEMPLATE = """
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
<context>
{context}
</context>
Answer the following question:
{question}"""
rag_prompt = ChatPromptTemplate.from_template(RAG_TEMPLATE)
retriever = vectorstore.as_retriever()
qa_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| rag_prompt
| model
| StrOutputParser()
)
question = "What is the purpose of the DeepSeek project?"
# Run
qa_chain.invoke(question)
Zusammenfassungen
Dieses Tutorial zeigt, wie man eine lokalisierte RAG-Anwendung mit DeepSeek R1 und Ollama erstellt. Wir erreichen die volle Funktionalität in vier Hauptschritten:
- Dateiverarbeitung PDFPlumberLoader zum Laden von PDF-Dokumenten und RecursiveCharacterTextSplitter zum Aufteilen des Textes in Stücke geeigneter Größe verwenden.
- Vektorspeicher Ein Vektorspeichersystem, das die Chroma-Datenbank und das Einbettungsmodell von Ollama verwendet, um eine Grundlage für die anschließende Ähnlichkeitssuche zu schaffen.
- Kette bauen Entwurf und Implementierung einer Verarbeitungskette, die die Verarbeitung von Dokumenten, Cue-Templates und Modellantworten in einen Flow-Through-Prozess integriert.
- RAG-Umsetzung Durch die Integration von Such- und Frage- und Antwortfunktionen wird ein komplettes suchgestütztes Generierungssystem implementiert, das in der Lage ist, Benutzeranfragen auf der Grundlage des Dokumenteninhalts zu beantworten.
Mit Hilfe dieses Tutorials können Sie schnell Ihr eigenes lokales RAG-System aufbauen und es an Ihre tatsächlichen Bedürfnisse anpassen. Es wird empfohlen, verschiedene Modelle und Parameterkonfigurationen in der Praxis auszuprobieren, um das Beste daraus zu machen.
Hinweis: Mit Hilfe von Tools wie streamlit oder FastAPI ist es möglich, eine lokale RAG-Anwendung als Webservice bereitzustellen, was eine größere Bandbreite von Anwendungsszenarien ermöglicht.
Das Repository bietet außerdem
app.pyDatei können Sie die Datei direkt ausführen, um den Webdienst zu starten. Dokumentation Aufbau eines RAG-Systems mit DeepSeek R1 & Ollama. Hinweis: Führen Sie den Ollama-Dienst im Voraus aus, bevor Sie diesen Code ausführen.
Die Dialogseite sieht wie folgt aus:

© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...