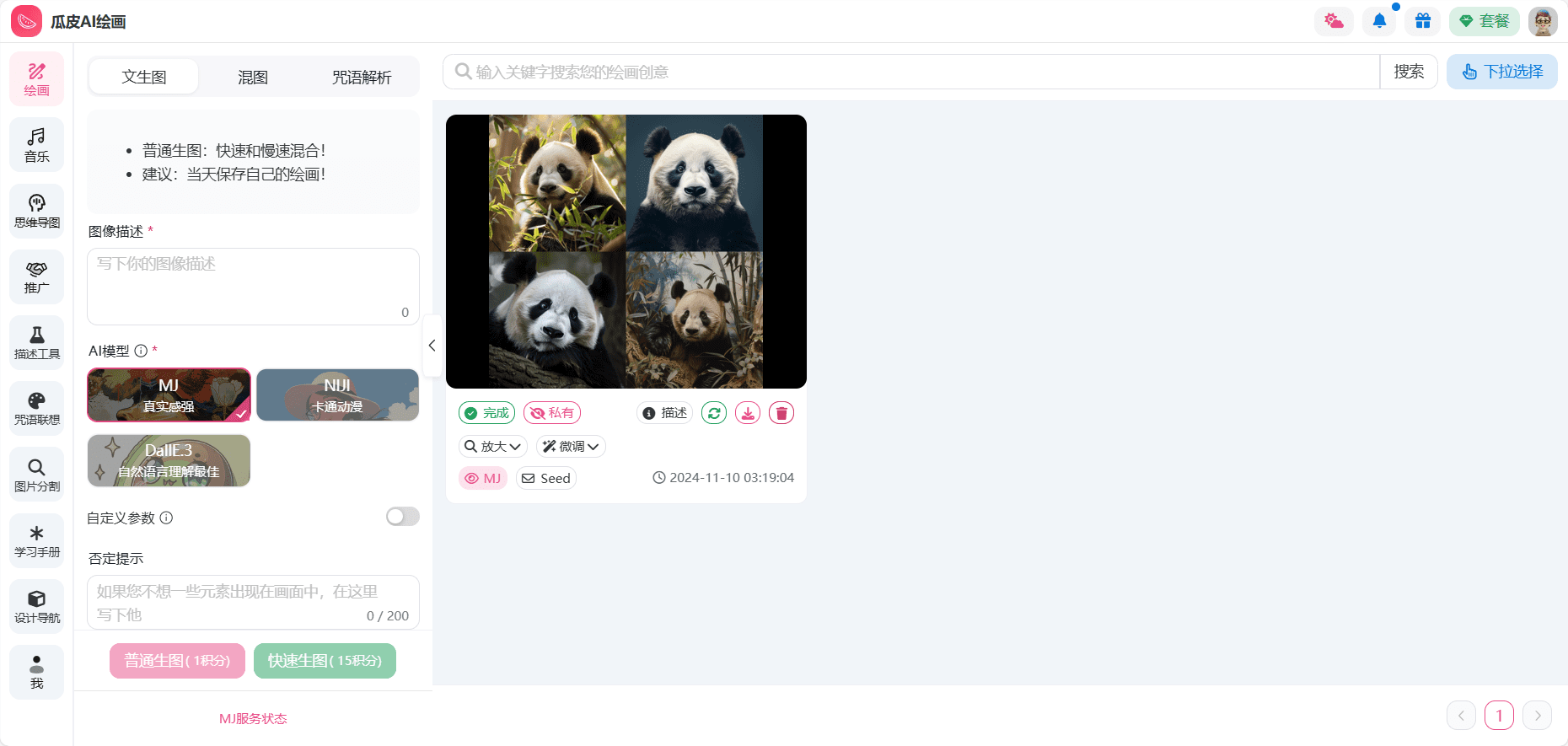
Sana: schnelle Erzeugung von hochauflösenden Bildern, 0,6B ultrakleines Modell, flacher Laptop-GPU-Betrieb

Allgemeine Einführung
Sana ist ein effizientes Framework für die Erzeugung hochauflösender Bilder, das in den NVIDIA Labs entwickelt wurde und Bilder mit einer Auflösung von bis zu 4096 × 4096 Pixeln in Sekundenschnelle erzeugt. Sana nutzt einen linearen Diffusionstransformator und eine Deep-Compression-Auto-Encoder-Technologie, um die Geschwindigkeit und Qualität der Bilderzeugung drastisch zu verbessern und gleichzeitig den Bedarf an Rechenressourcen zu reduzieren. Das Framework kann auf normalen Laptop-GPUs ausgeführt werden und ermöglicht so eine kostengünstige Erstellung von Inhalten.


Online-Erfahrung: https://nv-sana.mit.edu/
Funktionsliste
- Erzeugung hochauflösender BilderUnterstützt die Erstellung von Bildern mit einer Auflösung von bis zu 4096 × 4096.
- linearer DiffusionskonverterVerbesserung der Effizienz der Erzeugung hochauflösender Bilder durch einen linearen Aufmerksamkeitsmechanismus.
- Autoencoder für tiefe KompressionKomprimiert Bilder bis zum 32-fachen, reduziert die Anzahl potenzieller Marker und verbessert die Effizienz von Training und Generierung.
- Text zu Bild KonvertierungVerbesserte Bild-zu-Text-Ausrichtung durch Decoder nur Text-Encoder.
- Effiziente Ausbildung und ProbenahmeFlow-DPM-Solver wird verwendet, um Stichprobenschritte zu reduzieren und die Konvergenz zu beschleunigen.
- Kostengünstiger EinsatzUnterstützt den Betrieb auf 16GB Laptop-GPUs und erzeugt Bilder mit einer Auflösung von 1024 x 1024 in weniger als 1 Sekunde.
Hilfe verwenden
Einbauverfahren
- Stellen Sie sicher, dass die Python-Version >= 3.10.0 ist, Anaconda oder Miniconda wird empfohlen.
- Installieren Sie PyTorch Version >= 2.0.1+cu12.1.
- Klonen des Sana-Lagers:
git clone https://github.com/NVlabs/Sana.git cd Sana - Führen Sie das Skript zur Einrichtung der Umgebung aus:
./environment_setup.sh sanaoder wie bei
environment_setup.shInstallieren Sie die einzelnen Komponenten Schritt für Schritt wie unter
Verwendung
Hardware-Voraussetzung
- Das 0,6B-Modell benötigt 9 GB VRAM und das 1,6B-Modell 12 GB VRAM. Die quantisierte Version wird weniger als 8 GB Videospeicher für die Inferenz benötigen.
Schnellstart
- Starten Sie die offizielle Online-Demo mit Gradio:
DEMO_PORT=15432 \ python app/app_sana.py \ --config=configs/sana_config/1024ms/Sana_1600M_img1024.yaml \ --model_path=hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth - Führen Sie den Inferenzcode aus, um ein Bild zu erzeugen:
import torch from app.sana_pipeline import SanaPipeline from torchvision.utils import save_image device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") generator = torch.Generator(device=device).manual_seed(42) sana = SanaPipeline("configs/sana_config/1024ms/Sana_1600M_img1024.yaml") sana.from_pretrained("hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth") prompt = 'a cyberpunk cat with a neon sign that says "Sana"' image = sana(prompt=prompt, height=1024, width=1024, guidance_scale=5.0, pag_guidance_scale=2.0, num_inference_steps=18, generator=generator) save_image(image, 'output/sana.png', nrow=1, normalize=True, value_range=(-1, 1))
Ausbildungsmodelle
- Bereiten Sie den Datensatz in folgendem Format vor:
asset/example_data ├── AAA.txt ├── AAA.png ├── BCC.txt ├── BCC.png └── CCC.txt - Ausbildung einleiten:
bash train_scripts/train.sh \ configs/sana_config/512ms/Sana_600M_img512.yaml \ --data.data_dir="asset/example_data" \ --data.type=SanaImgDataset \ --model.multi_scale=false \ --train.train_batch_size=32
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...