
Wie wählt man das richtige Einbettungsmodell?
Retrieval Augmented Generation (RAG) ist eine Klasse von Anwendungen in der Generativen KI (GenAI), die die Verwendung eigener Daten zur Erweiterung des Wissens eines LLM-Modells (z.B. ChatGPT) unterstützt.
RAG Im Allgemeinen werden drei verschiedene KI-Modelle verwendet, nämlich das Einbettungsmodell, das Rerankear-Modell und das Big Language-Modell. In diesem Artikel geht es um die Auswahl des richtigen Einbettungsmodells auf der Grundlage Ihres Datentyps sowie Ihrer Sprache oder Ihres spezifischen Bereichs (z. B. Recht).
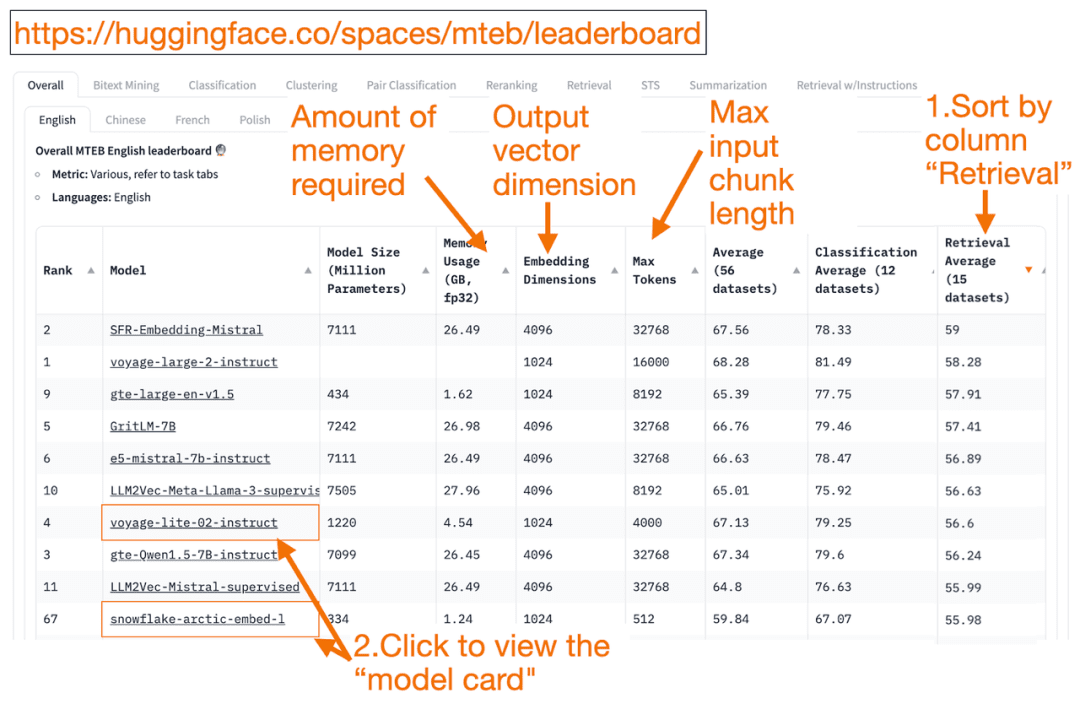
1. textliche Daten: MTEB-Ranking
HuggingFace MTEB-Rangliste ist eine umfassende Liste der Modelle zur Texteinbettung! Sie können die durchschnittliche Leistung der einzelnen Modelle herausfinden.
Sie können die Spalte "Retrieval Average" in absteigender Reihenfolge sortieren, da dies am besten zur Vektorsuchaufgabe passt. Suchen Sie dann nach dem Modell mit dem höchsten Rang und dem kleinsten Speicherbedarf.
- Die Dimension des Einbettungsvektors ist die Länge des Vektors, d. h. y in f(x)=y, den das Modell ausgeben wird.
- größte Token Die Zahl ist die Länge des Eingabetextblocks, d. h. x in f(x)=y , den Sie in das Modell eingeben können.
Zusätzlich zum Bestehen des Abruf Neben der Sortierung der Aufgaben können Sie auch nach den folgenden Kriterien filtern:
- Sprache: Französisch, Englisch, Chinesisch und Polnisch werden unterstützt. (z.B.: Aufgabe=Abruf.
Sprache=Chinesisch)
- Texte aus dem Bereich Recht.
(z.B. Aufgabe=Abruf, Sprache=Recht)
Da einige der Trainingsdaten erst seit kurzem öffentlich zugänglich sind, kann es sein, dass einige der Einbettungsmodelle in der MTEBscheinbar geeignetTatsächlich ungeeignete Modelle mit überhöhten Rankings können jedoch auch anders abschneiden. Aus diesem Grund hat HuggingFace eineBlog (Lehnwort)Sie beschreibt die wichtigsten Punkte, um festzustellen, ob ein Modell-Ranking glaubwürdig ist oder nicht. Nach dem Klicken auf einen Modell-Link (genannt "Modellkarte"):
- Suchen Sie nach Blogs und Artikeln, die erklären, wie Modelle trainiert und bewertet werden. Schauen Sie sich die Sprache, die Daten und die Aufgaben, die für die Modellschulung verwendet werden, genau an. Suchen Sie auch nach Modellen, die von bekannten Unternehmen erstellt wurden. Auf der Modellkarte voyage-lite-02-instruct sind beispielsweise andere VoyageAI-Modelle aufgeführt, aber nicht dieses. Dies ist ein Hinweis! Dieses Modell ist ein Overfitting-Modell und sollte nicht verwendet werden!
- Im folgenden Screenshot probiere ich das neue Modell "snowflake-arctic-embed-1" von Snowflake aus, weil es sehr gut bewertet ist, klein genug ist, um auf meinem Laptop zu laufen, und Links zu Blogs und Artikeln auf der Modellkarte enthält.
Der Vorteil der Verwendung von HuggingFace ist, dass Sie, wenn Sie das Modell nach der Auswahl des Einbettungsmodells ändern müssen, nur den model_name im Code ändern müssen!
import torch
from sentence_transformers import SentenceTransformer
# Initialize torch settings
torch.backends.cudnn.deterministic = True
DEVICE = torch.device('cuda:3' if torch.cuda.is_available() else 'cpu')
# Load the model from Huggingface
model_name = "WhereIsAI/UAE-Large-V1" # Just change model_name to use a different model!
encoder = SentenceTransformer(model_name, device=DEVICE)
# Get the model parameters and save for later
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# Print model parameters
print(f"model_name: {model_name}")
print(f"EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f"MAX_SEQ_LENGTH: {MAX_SEQ_LENGTH_IN_TOKENS}")

2. bilddaten: ResNet50
Manchmal möchten Sie vielleicht nach Bildern suchen, die dem eingegebenen Bild ähnlich sind. Zum Beispiel können Sie nach weiteren Bildern von Scottish Fold Cats suchen. In diesem Fall können Sie ein Bild von einer Scottish Fold Cat hochladen und die Suchmaschine bitten, ähnliche Bilder zu finden.
ResNet50 ist ein beliebtes CNN-Modell, das ursprünglich von Microsoft im Jahr 2015 mit ImageNet-Daten trainiert wurde.
Ähnlich verhält es sich beiVideo-SucheIn diesem Fall kann ResNet50 das Video trotzdem in Einbettungsvektoren umwandeln. Anschließend wird eine Ähnlichkeitssuche für die statischen Videobilder durchgeführt, und das ähnlichste Video wird dem Benutzer als beste Übereinstimmung angezeigt.
3. audiodaten: PANNs
Ähnlich wie bei der Bildersuche können Sie auch auf der Grundlage der eingegebenen Audioclips nach ähnlichen Audiodaten suchen.
PANNs(Pre-trained Audio Neural Networks) werden häufig als Einbettungsmodelle für die Audiosuche verwendet, da PANNs auf großen Audiodatensätzen vortrainiert sind und sich bei Aufgaben wie der Audioklassifizierung und -kennzeichnung auszeichnen.
4. multimodale Bild- und Textdaten:
SigLIP oder Unum
In den letzten Jahren ist eine Reihe von Einbettungsmodellen entstanden, die auf einer Mischung aus unstrukturierten Daten (Text, Bilder, Audio oder Video) trainiert wurden. Diese Modelle sind in der Lage, die Semantik mehrerer Arten von unstrukturierten Daten gleichzeitig im selben Vektorraum zu erfassen.
Das multimodale Einbettungsmodell unterstützt die Suche nach Bildern anhand von Text, die Erstellung von Textbeschreibungen für Bilder oder die Suche nach Bildern.
Start von OpenAI im Jahr 2021 CLIP ist das Standard-Einbettungsmodell. Da es jedoch schwierig zu verwenden war, da die Nutzer selbst eine Feinabstimmung vornehmen mussten, führte Google im Jahr 2024 das SigLIP(Sigmoidal-CLIP). Das Modell erzielte eine gute Leistung bei der Verwendung von Zero-Shot-Signalen.
Kleine LLM-Modelle werden heute immer beliebter. Dies liegt daran, dass diese Modelle keine großen Cloud-Cluster benötigen und auf Laptops ausgeführt werden können. Kleinere Modelle benötigen weniger Speicherplatz, haben eine geringere Latenz und laufen schneller als größere Modelle.Unum Es werden multimodale Mini-Embedding-Modelle bereitgestellt.
5. multimodale Text-, Audio- und Videodaten
Die meisten multimodalen Text-zu-Audio-RAG-Systeme verwenden multimodale generative LLMs, die zunächst Ton in Text umwandeln, Ton-Text-Paare erzeugen und dann den Text in Einbettungsvektoren umwandeln. Anschließend können Sie die RAG verwenden, um den Text wie gewohnt abzurufen. Im letzten Schritt wird der Text wieder in Audio umgewandelt.
OpenAI Flüstern kann Sprache in Text umwandeln. Darüber hinaus ist OpenAIs Text-to-Speech (TTS) Die Modelle können auch Text in Audio umwandeln.
Das multimodale Text-Video-RAG-System verwendet einen ähnlichen Ansatz, um zunächst ein Video in Text umzuwandeln, diesen in einen Einbettungsvektor zu konvertieren, den Text zu durchsuchen und das Video als Suchergebnis zurückzugeben.
OpenAI Sora Text kann in Video umgewandelt werden. Ähnlich wie bei Dall-e geben Sie Textanweisungen, während LLM das Video generiert.Sora kann auch Videos aus Standbildern oder anderen Videos generieren.
Milvus hat jetzt das Mainstream-Embedding-Modell integriert, das Sie gerne ausprobieren können:https://milvus.io/docs/embeddings.md
Beratung
MTEB-Rangliste: https://huggingface.co/spaces/mteb/leaderboard
MTEB Bewährte Praktiken: https://huggingface.co/blog/lyon-nlp-group/mteb-leaderboard-best-practices
Ähnliche Bildersuche: https://milvus.io/docs/image_similarity_search.md
Bild-Video-Suche: https://milvus.io/docs/video_similarity_search.md
Ähnliche Audiosuchen: https://milvus.io/docs/audio_similarity_search.md
Text-Bild-Suche: https://milvus.io/docs/text_image_search.md
2024 SigLIP (sigmoid loss CLIP) Papier: https://arxiv.org/pdf/2401.06167v1
Unum Multimodales Einbettungsmodell:
https://github.com/unum-cloud/uform
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel

Keine Kommentare...