Intelligenz in der Softwareentwicklung: Forschung, aktueller Stand und Perspektiven
Original: https://arxiv.org/abs/2409.09030
Abstracts
In den letzten Jahren haben große Sprachmodelle (Large Language Models, LLMs) einen bemerkenswerten Erfolg erzielt und wurden in einer Vielzahl von nachgelagerten Aufgaben eingesetzt, insbesondere bei Aufgaben im Bereich der Softwaretechnik (SE). Wir haben festgestellt, dass der Begriff der Intelligenz in vielen Studien, die LLMs mit SE kombinieren, explizit oder implizit verwendet wird. Es fehlt jedoch an einer fundierten Forschungsarbeit, die die Entwicklungslinie der bestehenden Arbeiten aufzeigt, analysiert, wie bestehende Arbeiten LLM-basierte intelligente Körpertechniken kombinieren, um verschiedene Aufgabentypen zu optimieren, und den Rahmen von LLM-basierten intelligenten Körpern im SE klärt. In diesem Beitrag geben wir einen ersten Überblick über die Forschung zur Kombination von LLM-Intelligenzen mit SE und schlagen einen Rahmen für LLM-Intelligenzen in SE vor, der drei Schlüsselmodule umfasst: Wahrnehmung, Gedächtnis und Handlung. Wir fassen auch die aktuellen Herausforderungen zusammen, die bei der Kombination der beiden Bereiche auftreten, und schlagen zukünftige Möglichkeiten vor, um diese zu bewältigen. Wir unterhalten ein GitHub-Repository mit verwandten Arbeiten unter:https://github.com/DeepSoftwareAnalytics/Awesome-Agent4SE.
1 Einleitung
In den letzten Jahren haben große Sprachmodelle (Large Language Models, LLMs) einen bemerkenswerten Erfolg erzielt und sind in vielen nachgelagerten Aufgaben weit verbreitet, insbesondere in einer Vielzahl von Aufgaben im Bereich der Softwareentwicklung (SE) Zheng et al.wie in dem Code Ahmed et al. zusammengefasst (2024); Sun et al. (2023b); Haldar und Hockenmaier (2024); Mao et al. (2024); Guo et al. (2023); Wang et al. (2021), Codegenerierung Jiang et al. (2023a); Hu et al. (2024b); Yang et al. (2023a); Tian und Chen (2023); Li et al. (2023e); Wang et al. (2024b), Code-Übersetzung Pan et al. (2024), Erkennung und Behebung von Sicherheitslücken Zhou et al. (2024); Islam und Najafirad (2024); de Fitero-Dominguez et al. (2024); Le et al. (2024); Liu et al. (2024b); Chen et al. (2023a), usw. In vielen Studien, die LLM mit SE kombinieren, wird das Konzept der Intelligenz aus dem Bereich der KI eingeführt, entweder explizit oder implizit. Die explizite Verwendung bedeutet, dass sich die Arbeit direkt auf die Anwendung von Technologien im Zusammenhang mit Intelligenz bezieht, während die implizite Verwendung darauf hindeutet, dass das Konzept der Intelligenz zwar verwendet wird, aber möglicherweise unter Verwendung einer anderen Terminologie oder in einer anderen Form dargestellt wird.
Intelligentsia Wang et al. (2024c) stellt eine intelligente Einheit dar, die in der Lage ist, wahrzunehmen, zu denken und Handlungen auszuführen. Sie dient als wichtige technologische Grundlage für die Bewältigung verschiedener Aufgaben und Ziele, indem sie den Zustand der Umgebung wahrnimmt und auf der Grundlage ihrer Ziele und ihres Designs Aktionen auswählt, um bestimmte Leistungskennzahlen zu maximieren. LLM-basierte Intelligenzen verwenden typischerweise LLMs als kognitiven Kern der Intelligenzen und zeichnen sich durch Szenarien wie Automatisierung, intelligente Steuerung und Mensch-Computer-Interaktion aus, indem sie die leistungsstarken Fähigkeiten von LLMs in den Bereichen Sprachverständnis und -generierung, Lernen und logisches Denken, Kontextbewusstsein und Gedächtnis sowie Multimodalität nutzen. Mit der Entwicklung verschiedener Bereiche werden die Konzepte der traditionellen und der auf LLM basierenden Intelligenzen allmählich geklärt und im Bereich der Verarbeitung natürlicher Sprache (NLP) weithin verwendet Xi et al.2023). Obwohl dieses Konzept in bestehenden Arbeiten explizit oder implizit verwendet wird, gibt es immer noch keine klare Definition von intelligiblen Körpern. Es fehlt ein ausführlicher Forschungsartikel, in dem analysiert wird, wie die bestehenden Arbeiten intelligente Körpertechniken zur Optimierung verschiedener Aufgaben einbeziehen, um die Entwicklungslinie der bestehenden Arbeiten zu sortieren und den Rahmen intelligenter Körper im SE zu klären.
In diesem Beitrag wird eine eingehende Analyse der Forschung zur Kombination von Large Language Model (LLM)-basierten Agenten mit Software-Engineering (SE) vorgenommen, die aktuellen Herausforderungen bei der Kombination der beiden Bereiche zusammengefasst und mögliche Möglichkeiten für die zukünftige Forschung als Antwort auf die bestehenden Herausforderungen vorgeschlagen. Wir haben zunächst Arbeiten gesammelt, die sich mit der Anwendung der LLM-basierten Agententechnologie im SE befassen, und nach Filterung und Qualitätsbewertung 115 Arbeiten erhalten. Dann, inspiriert von der traditionellen Agentendefinition (Wang et al.2024cXi et al.2023), stellen wir einen generischen konzeptionellen Rahmen für LLM-basierte Agenten in SE vor (siehe Abschnitt 2 Abschnitte), einschließlich der drei Schlüsselkomponenten Wahrnehmung, Gedächtnis und Handlung. Wir stellen zunächst das Wahrnehmungsmodul vor (siehe Abschnitt 2.1 Abschnitt), kann dieses Modul Eingaben aus verschiedenen Modalitäten verarbeiten, z. B. Texteingaben, visuelle Eingaben, auditive Eingaben usw. Als nächstes stellen wir das Speichermodul vor (siehe Abschnitt 2.2 Abschnitt) umfasst dieses Modul das semantische Gedächtnis, das Handlungsgedächtnis und das prozedurale Gedächtnis, um dem Agenten zu helfen, begründete Entscheidungen zu treffen. Schließlich führen wir das Handlungsmodul ein (siehe Abschnitt 2.3 Abschnitt), umfasst das Modul sowohl interne Aktionen wie Denken, Abrufen und Lernen als auch externe Aktionen wie die Interaktion mit der Umwelt.
Anschließend gehen wir auf die Herausforderungen und Möglichkeiten von LLM-basierten Agenten in SE ein (siehe Abschnitt 3 Abschnitte). Konkret schlagen wir die folgenden zukünftigen Forschungsmöglichkeiten für LLM-Agenten vor, um aktuelle Herausforderungen im Bereich SE anzugehen:
- Die meisten der vorhandenen Studien untersuchen hauptsächlich das Token-basierte Texteingabe-Wahrnehmungsmodul, während die Erforschung anderer Modalitäten fehlt.
- Viele neue Aufgaben bleiben außerhalb des Anwendungsbereichs des LLM-Lernens, und komplexe Aufgaben im SE-Bereich erfordern Agenten mit mehreren Fähigkeiten. Daher ist es von entscheidender Bedeutung zu erforschen, wie LLM-basierte Agenten neue Rollen übernehmen und die Fähigkeiten mehrerer Rollen effektiv ausgleichen können.
- Im Bereich SE fehlt eine maßgebliche und anerkannte Wissensbasis, die eine Fülle von codebezogenem Wissen als Grundlage für die externe Suche enthält.
- Die Entschärfung der Illusion von LLM-Agenten verbessert die Gesamtleistung des Agenten, und die Agentenoptimierung wiederum entschärft das Problem der LLM-Agenten-Illusion.
- Der Prozess der Zusammenarbeit mehrerer Agenten erfordert erhebliche Rechenressourcen und zusätzliche Kommunikationskosten aufgrund der Synchronisierung und der gemeinsamen Nutzung verschiedener Informationen. Die Erforschung von Techniken zur Verbesserung der Effizienz der Multi-Agenten-Zusammenarbeit ist ebenfalls eine Möglichkeit für zukünftige Arbeiten.
- Technologien im Bereich der Sozialwissenschaften können auch zur Entwicklung des Agentenbereichs beitragen, und es muss in Zukunft noch weiter erforscht werden, wie fortgeschrittene Technologien im Bereich der Sozialwissenschaften in den Agenten integriert werden können und wie die Weiterentwicklung sowohl des Agenten als auch des Bereichs der Sozialwissenschaften gefördert werden kann.
Darüber hinaus können Techniken des SE, insbesondere solche, die sich auf Code beziehen, auch den Bereich der Agenten voranbringen, was die sich gegenseitig verstärkende Beziehung zwischen diesen beiden sehr unterschiedlichen Bereichen zeigt. Allerdings wurde die Anwendung von SE-Techniken auf Agenten bisher kaum untersucht, und die Forschung konzentriert sich immer noch auf einfache Grundtechniken des SE, wie Funktionsaufrufe, HTTP-Anfragen und andere Werkzeuge. Daher konzentriert sich dieses Papier auf agentenbezogene Arbeiten im Bereich des SE, und in Abschnitt 3.6 AbschnittDie Anwendung von SE-Techniken auf Agenten wird kurz als Möglichkeit für künftige Forschung diskutiert.

2 SE-Agenten auf der Grundlage des Large Language Model (LLM)
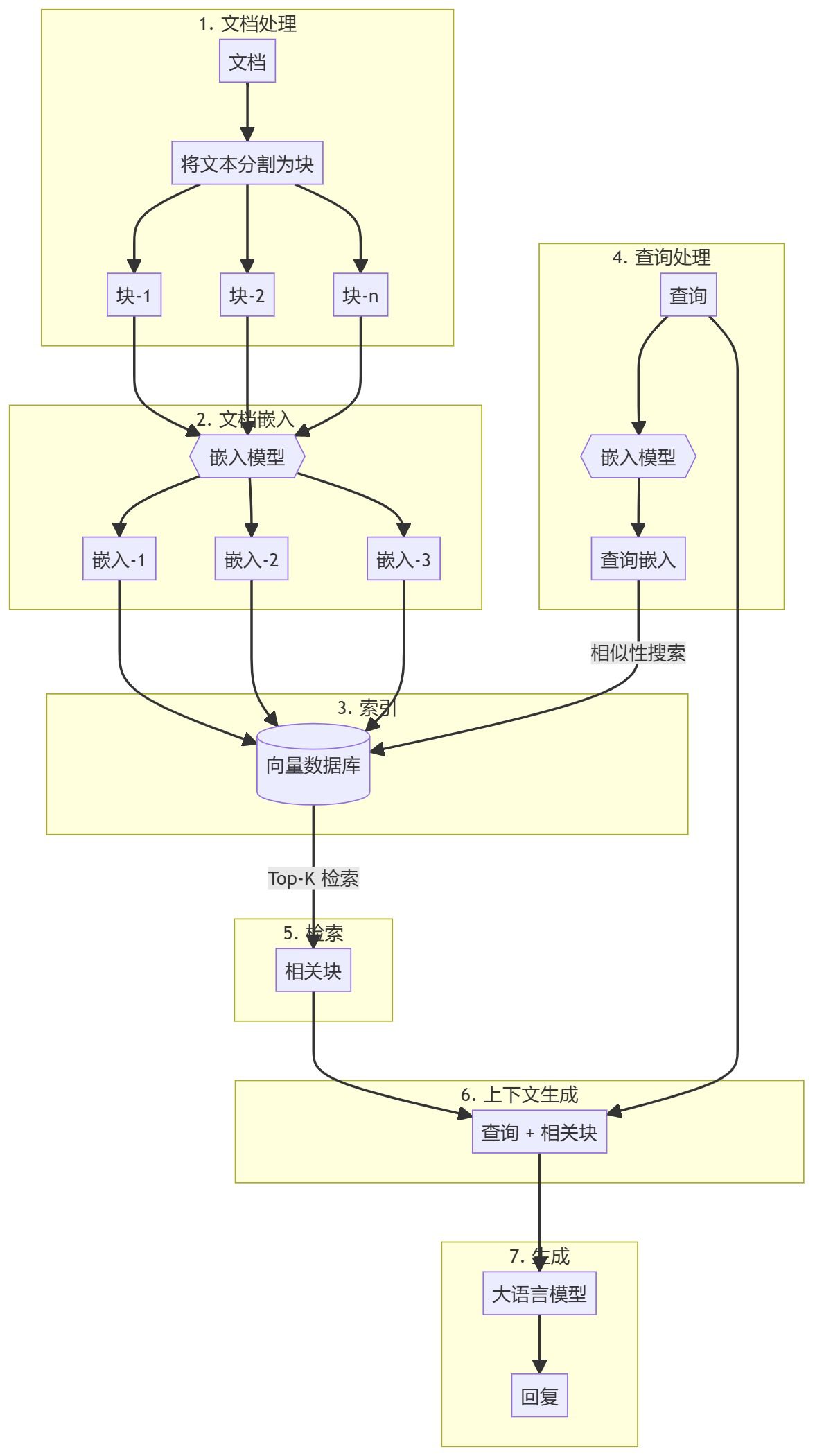
Nach der Zusammenstellung und Analyse der während des Datenerfassungszeitraums gewonnenen Forschungsergebnisse schlagen wir ein Software-Engineering (SE)-Agenten-Framework vor, das auf dem Large Language Model (LLM) basiert. Wie in Abb. 2 Ein einzelner Agent besteht aus drei Schlüsselmodulen: Wahrnehmung, Gedächtnis und Handlung. Das Wahrnehmungsmodul empfängt multimodale Informationen aus der äußeren Umgebung und wandelt sie in eine Form von Input um, die der LLM verstehen und verarbeiten kann. Das Aktionsmodul umfasst interne und externe Aktionen, die dafür verantwortlich sind, Entscheidungen auf der Grundlage von Eingaben des LLM zu begründen bzw. Entscheidungen auf der Grundlage von Rückmeldungen aus der Interaktion mit der externen Umgebung zu optimieren. Das Speichermodul umfasst semantische, situative und prozedurale Speicher, die zusätzliche nützliche Informationen liefern können, um dem LLM zu helfen, begründete Entscheidungen zu treffen. Außerdem kann das Aktionsmodul verschiedene Speicher im Speichermodul durch Lernaktionen aktualisieren, um effektivere Speicherinformationen für Schlussfolgerungen und Abrufoperationen bereitzustellen. Darüber hinaus besteht die Multi-Agenten-Kollaboration aus mehreren einzelnen Agenten, die für einen Teil der Aufgabe verantwortlich sind und zusammenarbeiten, um die Aufgabe durch kollaborative Zusammenarbeit zu erfüllen. In diesem Abschnitt werden die Details der einzelnen Module des LLM-basierten SE-Agentenrahmens vorgestellt.

Abbildung 2: Überblick über den Agentenrahmen in SE.
2.1 Wahrnehmung
Das Wahrnehmungsmodul verbindet den LLM-basierten Agenten mit der externen Umgebung und ist zentral für die Verarbeitung externer Eingaben. Es verarbeitet verschiedene modale Eingaben, wie z. B. textuelle, visuelle und auditive Eingaben, und wandelt sie in ein eingebettetes Format um, das vom LLM-Agenten verstanden und verarbeitet werden kann, wodurch die Grundlage für das Denk- und Entscheidungsverhalten des LLM-Agenten gelegt wird. Als nächstes stellen wir die Details der verschiedenen modalen Eingaben im Wahrnehmungsmodul vor.
2.1.1 Texteingabe
Im Gegensatz zu den Texteingabeformaten in der natürlichen Sprachverarbeitung (NLP), die die Eigenschaften des Codes berücksichtigen, enthalten die Texteingabeformate in SE den Text auf der Grundlage der Token Eingaben, baum-/graphenbasierte Eingaben und hybride Eingaben.
Token-basierte Eingaben. Token-basierte Eingaben (Ahmed et al. 2024Al-Kaswan et al. 2023Arakelyan et al. 2023Beurer-Kellner et al. 2023:: Alqarni und Azim. 2022Li et al. 2022bGu et al. 2022Du et al. 2021) ist der vorherrschende Eingabeansatz, der Code direkt als natürlichsprachlichen Text behandelt und Token-Sequenzen direkt als Eingabe für den LLM verwendet, wobei die Eigenschaften des Codes ignoriert werden.
Baum-/Diagramm-basierte Eingabe. Im Gegensatz zu natürlichen Sprachen haben Codes strenge strukturelle und syntaktische Regeln und werden in der Regel nach der Syntax einer bestimmten Programmiersprache geschrieben. Ausgehend von den Merkmalen von Codes ist die baum-/graphenbasierte Eingabe (Ma et al. 2023b, aZhang et al. 2023g:: Ochs et al. 2023Bi et al. 2024Shi et al. 2023a, 2021Wang und Li. 2021) können Code in Baumstrukturen wie abstrakte Syntaxbäume oder Graphstrukturen wie Kontrollflussgraphen umwandeln, um strukturierte Informationen über den Code zu modellieren. In den aktuellen Arbeiten zu LLM-basierten SE-Agenten wurden solche Modalitäten jedoch nicht untersucht, was sowohl Herausforderungen als auch Chancen mit sich bringt.
Hybride Eingaben. Gemischte Eingaben (Niu et al. 2022Hu et al. 2024aGuo et al. 2022) kombiniert mehrere Modalitäten, um dem LLM verschiedene Arten von Informationen zur Verfügung zu stellen. Zum Beispiel kann die Einbeziehung von hybriden Token-basierten und Baum-basierten Eingaben semantische und strukturelle Informationen über den Code kombinieren, was zu einer besseren Modellierung und einem besseren Verständnis des Codes führt. Die Arbeit an LLM-basierten Agenten im SE hat diese Modalität jedoch noch nicht erforscht.
2.1.2 Visuelle Eingabe
Bei der visuellen Eingabe werden visuelle Bilddaten, wie z. B. UI-Skizzen oder UML-Designdiagramme, als modale Eingabe verwendet und durch Modellierung und Analyse der Bilder inferenzielle Entscheidungen getroffen. Viele NLP-bezogene Arbeiten untersuchen diese Modalität. Zum Beispiel haben Driess et al. (2023) schlägt PaLM-E vor, ein verkörpertes multimodales Sprachmodell, dessen Eingaben aus multimodalen Sätzen bestehen, die mit visueller, kontinuierlicher Zustandseinschätzung und textueller Eingabekodierung verwoben sind. Traditionelle Software-Engineering-Domänen haben auch visuelle Eingabeaufgaben, wie die Suche nach UI-Code (Behrang et al.2018Reiss et al.2014Xie et al.2019), das UI-Skizzen als Abfragen verwendet, um nützliche Codeschnipsel zu finden. Es gibt jedoch noch weniger Arbeiten zur visuellen Modellierung als Input für LLM.
2.1.3 Auditiver Input
Auditive Eingaben interagieren mit LLMs in Form von Sprache, wobei auditive Daten wie Audio als Eingabe verwendet werden. Traditionelle Software-Engineering-Domänen haben Aufgaben für auditive Eingaben, wie die Programmierung von Videosuchen (Bao et al.2020), das Video als Quelle für nützliche Codeschnipsel verwendet. Es gibt jedoch auch einen relativen Mangel an Arbeiten, die sich mit auditivem Input für LLM befassen.
2.2 Speicher
Zu den Gedächtnismodulen gehören das semantische Gedächtnis, das situative Gedächtnis und das prozedurale Gedächtnis, die zusätzliche nützliche Informationen liefern können, um LLMs zu helfen, begründete Entscheidungen zu treffen. Im Folgenden werden wir die Einzelheiten dieser drei Gedächtnisarten vorstellen.
2.2.1 Semantisches Gedächtnis
Semantische Gedächtnisse speichern das anerkannte Weltwissen von LLM-Agenten, in der Regel in Form von externen Wissensrepositorien, die Dokumente, Bibliotheken, APIs oder anderes Wissen enthalten. Viele Studien haben die Anwendung des semantischen Gedächtnisses untersucht (Wang et al.2024bZhang et al.2024Eghbali und Pradel.2024; Patel et al.2023Zhou et al.2022Ren et al.2023Zhang et al.2023d). Insbesondere Dokumentation und APIs sind die am häufigsten in externen Wissensdatenbanken gefundenen Informationen. Zum Beispiel haben Zhou et al.2022) eine neuartige Methode zur Generierung von Code in natürlicher Sprache mit der Bezeichnung DocPrompting vor, die explizit Dokumente auf der Grundlage natürlichsprachlicher Absichten nutzt, indem sie relevante Dokumentfragmente abruft.Zhang et al.2024) einen manuellen Vergleichsbenchmark namens CODEAGENTBENCH für die Codegenerierung auf Codebase-Ebene entwickelt, der Dokumentations-, Codeabhängigkeits- und Laufzeitumgebungsinformationen enthält.Ren et al.2023) schlugen einen neuartigen wissensbasierten Prompt-basierten Ansatz zur verketteten Codegenerierung vor, der KPC genannt wird und der feinkörniges Wissen über die Behandlung von Ausnahmen aus der API-Dokumentation nutzt, um LLMs bei der Codegenerierung zu unterstützen. Neben der Dokumentation sind APIs auch eine gängige Information in externen Wissensdatenbanken. Zum Beispiel haben Eghbali und Pradel (2024) eine LLM-basierte Technik zur Codevervollständigung namens De-Hallucinator vor, die automatisch projektspezifische API-Referenzen im Zusammenhang mit Code-Präfixen und anfänglichen Vorhersagen des Modells identifiziert und Informationen über diese Referenzen zu den Hints hinzufügt.Zhang et al. (2023d) Durch die Integration eines API-Suchwerkzeugs in den Generierungsprozess kann das Modell automatisch APIs auswählen und das Suchwerkzeug nutzen, um Vorschläge zu erhalten. Darüber hinaus wurden in einigen Arbeiten auch andere Informationen berücksichtigt. Zum Beispiel haben Patel et al. (2023) untersuchten die Fähigkeiten und Grenzen verschiedener LLMs bei der Generierung von kontextbezogenem Code. Wang et al. (2024b) Feinabstimmung ausgewählter Code-LLMs mit Hilfe von Erweiterungsfunktionen und ihren entsprechenden Dokumentationsstrings.
2.2.2 Situationsbezogenes Gedächtnis
Das Situationsgedächtnis speichert Inhalte, die für den aktuellen Fall relevant sind, sowie empirische Informationen, die aus früheren Entscheidungsprozessen gewonnen wurden. Inhalte, die sich auf den aktuellen Fall beziehen (z.B. relevante Informationen, die in Suchdatenbanken gefunden wurden, Beispiele, die durch In-Context-Learning-Techniken (ICL) zur Verfügung gestellt wurden, usw.) können zusätzliches Wissen für LLM-Schlussfolgerungen liefern, und daher haben viele Studien diese Informationen in den Schlussfolgernden Prozess von LLM eingeführt (Zhong et al.2024Li et al.2023cFeng und Chen.2023Ahmed et al.2023Wei et al.2023aRen et al.2023Zhang et al.2023bEghbali und Pradel.2024Shi et al.2022). Zum Beispiel haben Li et al. (2023c) schlugen eine neue Hinting-Technik namens AceCoder vor, die ähnliche Programme als Beispiele in den Hints auswählt und eine große Menge an Inhalten (z. B. Algorithmen, APIs) zum Zielcode bereitstellt.Feng und Chen (2023) schlug AdbGPT vor, einen leichtgewichtigen Ansatz ohne Training und Hardcoding, der automatisch Fehler auf der Grundlage von Fehlerberichten mit Hilfe von In-Context-Lerntechniken reproduziert.Ahmed et al.2023) fanden heraus, dass die Einbeziehung semantischer Fakten dazu beitragen kann, die Leistung von LLM bei der Codezusammenfassung zu verbessern.Wei et al.2023a) schlägt ein neues Modell mit dem Namen Coeditor vor, das auf der Grundlage der jüngsten Änderungen an derselben Codebasis in einem automatischen Code-Editiersystem mit mehreren Runden Änderungen an Codebereichen vorhersagt. Darüber hinaus kann die Einführung empirischer Informationen, wie z.B. historische Interaktionsinformationen, LLM-basierten Agenten helfen, den Kontext besser zu verstehen und korrekte Entscheidungen zu treffen. Einige Arbeiten nutzen empirische Informationen aus vergangenen Argumentations- und Entscheidungsprozessen, um durch iteratives Abfragen und Modifizieren von Antworten genauere Antworten zu erhalten. Zum Beispiel haben Ren et al. (2023) schlug KPC vor, einen wissensbasierten Prompt Chained Code Generation-Ansatz, der die Codegenerierung in KI-Ketten mit iterativen Check-Rewrite-Schritten zerlegt.Zhang et al.2023b) schlug RepoCoder vor, ein einfaches, vielseitiges und effektives Framework zur effizienten Nutzung von Informationen auf Codebase-Ebene für die Code-Vervollständigung in einer iterativen Abrufgenerierungs-Pipeline.Eghbali und Pradel (2024) schlugen De-Hallucinator vor, eine LLM-basierte Technik zur Code-Vervollständigung, die geeignete API-Referenzen abruft, indem sie die Kontextinformationen in den Hints schrittweise erweitert und das Abfragemodell iteriert, um seine Vorhersagen genauer zu machen.
2.2.3 Prozedurales Gedächtnis
Das prozedurale Gedächtnis eines Agenten in der Softwareentwicklung besteht aus implizitem Wissen, das in den Gewichten des Large Language Model (LLM) gespeichert ist, und explizitem Wissen, das im Code des Agenten geschrieben ist.
Das implizite Wissen ist in den Parametern des LLM gespeichert. Bestehende Studien schlagen in der Regel neue LLMs mit reichhaltigem implizitem Wissen für verschiedene nachgelagerte Aufgaben vor, indem sie Modelle mit großen Datenmengen trainieren.Zheng et al.2023) hat das LLM von Code im Bereich SE nach der Art der Zugehörigkeit (einschließlich Unternehmen, Universitäten, Forschungsteams und Open-Source-Gemeinschaften, Einzelpersonen und anonyme Mitwirkende) organisiert.
Explizites Wissen, das in den Code des Agenten geschrieben wird, damit der Agent automatisch arbeiten kann. Mehrere Arbeiten, wie Patel et al. (2023); Shin et al. (2023); Zhang et al. (2023a) untersuchten verschiedene Möglichkeiten der Konstruktion von Agentencode. Insbesondere Patel et al. (2023) verwenden drei Arten von kontextbezogener Überwachung, um Bibliotheksfunktionen zu spezifizieren, einschließlich Demos, Beschreibungen und Implementierungen.Shin et al. (2023) untersuchten die Wirksamkeit von drei verschiedenen Cue-Engineering-Techniken (d.h. Basis-Cueing, kontextuelles Lernen und aufgabenspezifisches Cueing) mit fein abgestimmtem LLM bei drei typischen ASE-Aufgaben. Zhang et al. (2023a) untersuchten die Verwendung verschiedener Cue-Designs (d. h. grundlegende Cues, unterstützende Informations-Cues und Cues für das Kettendenken) mit Hilfe des ChatGPT Leistung bei der Erkennung von Softwareschwachstellen.
2.3 Bewegung
Das Aktionsmodul besteht aus zwei Typen: interne und externe Aktionen. Externe Aktionen interagieren mit der externen Umgebung, um Feedback zu erhalten, einschließlich des Dialogs mit Menschen/Agenten und der Interaktion mit der digitalen Umgebung, während interne Aktionen auf der Grundlage von Eingaben aus dem LLM Überlegungen anstellen und Entscheidungen treffen und die Entscheidungen auf der Grundlage des erhaltenen Feedbacks optimieren, einschließlich Inferenz-, Abruf- und Lernaktionen. Im Folgenden wird jede Aktion im Detail beschrieben.
2.3.1 Interne Maßnahmen
Zu den internen Aktionen gehören Denk-, Abruf- und Lernaktionen. Getrennt davon ist die Schlussfolgerungsaktion für die Analyse des Problems, die Schlussfolgerung und das Treffen von Entscheidungen auf der Grundlage der Eingaben des LLM-Agenten verantwortlich. Abrufaktionen rufen relevante Informationen aus der Wissensbasis ab und helfen den Argumentationsaktionen, korrekte Entscheidungen zu treffen. Lernende Aktionen hingegen lernen und aktualisieren kontinuierlich Wissen, indem sie semantische, prozedurale und situative Erinnerungen erlernen und aktualisieren und so die Qualität und Effizienz der Argumentation und Entscheidungsfindung verbessern.
Denkende Handlungen. Ein rigoroser Denkprozess ist der Schlüssel für LLM-Agenten, um Aufgaben zu erfüllen, und Chained Thinking (CoT) ist eine effektive Art des Denkens. Mit Hilfe von CoT können LLMs Probleme tiefgreifend verstehen, komplexe Aufgaben zerlegen und hochwertige Antworten generieren. Wie in der Abbildung gezeigt 3 Wie gezeigt, wurden in der bisherigen Forschung verschiedene Formen von CoT untersucht, darunter einfache CoT/Planung, SCoT, Brainstorming und Baum-CoT. Bei einem einfachen CoT/Plan handelt es sich um einen Absatz in der Aufforderung, der den Denkprozess des Problems beschreibt. In früheren Arbeiten wurde ein einfacher Satz in die Aufforderung aufgenommen, um das LLM anzuleiten, Kettendenken für eine bessere Problemlösung zu entwickeln. Hu et al. zum Beispiel (2024bEs wird ein kontextbezogener Lernansatz vorgeschlagen, um die LLM-Fehlersuche mit Hilfe der "Print Debugging"-Methode anzuleiten. Mit der Entwicklung der LLM-Technologie ist der Entwurf von CoTs komplexer geworden. Inspiriert durch den Prozess der Entwickler, die Durchführbarkeit von Testszenarien zu überprüfen, haben Su et al.2023) entwickelten Chain of Thought (CoT) Reasoning, um humanoides Wissen und logisches Denken aus LLM zu extrahieren.2023) schlugen ein neues System namens CodeChain vor, das selbstkorrigierende Ketten erzeugt, die sich an einer Reihe von repräsentativen Teilmodulen orientieren, die in früheren Iterationen erzeugt wurden.Huang et al.2024) schlug CodeCoT vor, das Testfälle generiert, um den Code während der Ausführung auf Syntaxfehler zu überprüfen, und dann das Kettendenken mit dem Selbstüberprüfungsprozess der Codegenerierung durch eine Selbstüberprüfungsphase kombiniert.Tian und Chen (2023) stellt eine neuartige Prompting-Technik vor, entwirft ausgefeilte gedankengeleitete Prompts und prompt-basiertes Feedback und untersucht zum ersten Mal, wie die Codegenerierungsleistung von LLMs verbessert werden kann.
In Anbetracht der Merkmale des Codes haben einige Forscher eine strukturierte CoT (Chain of Thought) vorgeschlagen, um strukturelle Informationen des Codes einzuführen. Wie in Abb. gezeigt. 3 Wie in (b) gezeigt, stellt die strukturierte CoT den Argumentationsprozess in einer pseudocodeähnlichen Form dar, die Schleifen, Verzweigungen und andere Strukturen enthält. Zum Beispiel haben Li et al. (2023a) schlugen Structured CoTs (SCoTs) vor, die die reichhaltigen strukturellen Informationen im Quellcode effektiv nutzen können, sowie eine neue Technik zur Codegenerierung, SCoT Hinting.Christianos et al. (2023) schlägt ein allgemeines Rahmenmodell vor, das die Konstruktion von intrinsischen und extrinsischen Funktionen nutzt, um das Verständnis der Argumentationsstruktur zu verbessern und strukturiertes Denken in die Strategien von KI-Intelligenzen einzubeziehen. Darüber hinaus haben mehrere Studien andere Formen von CoT vorgeschlagen, wie z. B. Brainstorming und Tree CoT, wie in Abbildung 3 (c) und (d) im Folgenden. Das Brainstorming basiert auf der Generierung relevanter Schlüsselwörter auf der Grundlage der Eingaben. Zum Beispiel haben Li et al. (2023e) ein neuartiges Brainstorming-Framework für die Codegenerierung vor, das Brainstorming-Schritte zur Generierung und Auswahl verschiedener Ideen verwendet und so die algorithmische Argumentation vor der Codegenerierung erleichtert. Tree CoT ist ein Beispiel von Feng und Chen (2023) vorgeschlagen, das den CoT dynamisch erkundet und aktualisiert, wobei sich die Knoten im Baum in verschiedenen Zuständen befinden, darunter abgeschlossene, neue, neu abgeleitete und ausstehende Knoten.
Darüber hinaus wurden in mehreren Studien andere Techniken zur Verbesserung der Argumentationsfähigkeit und -effizienz von Intelligenzen auf der Grundlage von großen Sprachmodellen erforscht. Zum Beispiel haben Wang et al. (2024a) schlug TOOLGEN vor, das aus einer Phase der Triggereinfügung und der Feinabstimmung des Modells (offline) und einer Phase der Codegenerierung für die Toolintegration (online) besteht.TOOLGEN nutzt Erweiterungen im gegebenen Codekorpus, um abzuleiten, wo die Autovervollständigung von Tools ausgelöst werden soll, und um spezielle Token zu markieren.Yang et al. (2023a) eine neue Methode, COTTON, entwickelt, die mit Hilfe eines leichtgewichtigen Sprachmodells automatisch Code-generierte CoTs erzeugt. Zhang et al. (2023c) schlugen eine Selbstinferenzdekodierung vor, ein neuartiges Inferenzverfahren, das Token-Entwürfe erzeugt und dann die Token-Ausgabe aus diesen Entwürfen unter Verwendung des ursprünglichen Bigram-Modells in einem einzigen Vorwärtsdurchlauf verifiziert.Zhou et al.2023) führt einen adaptiven Lösungsrahmen ein, der die Lösungsstrategie strategisch an die Schwierigkeit des Problems anpasst, was nicht nur die Berechnungseffizienz, sondern auch die Gesamtleistung verbessert.

Abbildung 3: Verschiedene CoTs für verschiedene Ansätze, wobei (a) ein nativer CoT/Plan ist, der dadurch entsteht, dass man das Biglanguage-Modell Schritt für Schritt auf Hinweise hin denken lässt, und der einen detaillierten Prozess der Problemanalyse und Lösungsschritte enthält. (b) ist die strukturierte CoT (SCoT), die Code-Merkmale kombiniert, um einen Code-Rahmen zu erzeugen, der die Verzweigungs- und Schleifenstrukturen im Diagramm enthält. Die Zusammenfassung in blauer Schrift fasst die Beschreibung des großen Sprachmodells zusammen, das konkreten Code auf der Grundlage von SCoT erzeugt. (c) ist das Ergebnis eines Brainstormings, bei dem die Problembeschreibung analysiert und das Wissen über Algorithmen, Datenstrukturen und Mathematik genutzt wird, um Lösungsideen zu liefern. (d) ist ein Beispiel für eine Baum-CoT, die dynamisch erforscht und iterativ aktualisiert wird, um das Problem schrittweise zu zerlegen und zu vervollständigen.
Abrufoperationen. Durch Abrufoperationen werden relevante Informationen aus der Wissensbasis abgerufen, um die richtigen Entscheidungen zu treffen. Die für den Abruf verwendeten Eingaben und die Art der durch den Abruf erhaltenen Ausgabeinhalte sind unterschiedlich. Wie in Tabelle 1 Wie gezeigt, kann es sich bei den Ein- und Ausgängen um Text, Code oder gemischte Nachrichten handeln, die Text und Code enthalten. Sie lassen sich insbesondere in folgende Kategorien einteilen: (1) Text-Code. Normalerweise werden Anforderungen als Eingaben verwendet, um relevanten Code oder verwendete APIs abzurufen, die zu den Aufforderungen hinzugefügt werden, um Antwortcodes zu erzeugen. Zum Beispiel haben Zan et al. (2022a) schlagen einen neuen Rahmen vor, der die Module APIRetriever und APICoder umfasst. APIRetriever ruft nützliche APIs ab, und APICoder verwendet diese abgerufenen APIs zur Codegenerierung. de-Hallucinator Eghbali und Pradel (2024) Abrufen geeigneter API-Referenzen über Hinweise und Verwendung der erhaltenen Hinweise zur iterativen Abfrage des Modells. (2) Text-Text. Manchmal werden Anforderungen auch als Eingabe verwendet, um relevante Dokumente oder ähnliche Fragen zu finden, die bei der Lösung der Aufgabe helfen. Zum Beispiel haben Zhou et al. (2022) stellten DocPrompting vor, eine Methode zur Generierung von Code in natürlicher Sprache, die explizit auf eine gegebene NL-Intention reagiert, indem sie relevante Dokumentfragmente abruft. Zhang et al. (2024) schlägt CodeAgent vor, ein neuartiges Agenten-Framework auf der Grundlage eines großen Sprachmodells, das externe Werkzeuge integriert, um relevante Informationen für eine effiziente Code-Generierung auf der Ebene der Codebasis abzurufen, und das die Interaktion mit Software-Artefakten für die Informationsabfrage, die Navigation in der Code-Notation und das Testen von Code unterstützt. (3) Code-Code. Code kann auch als Eingabe verwendet werden, um ähnlichen oder verwandten Code zu finden, der als Referenz für die Generierung von Zielcode dient. Zum Beispiel haben Zhang et al. (2023b) schlägt RepoCoder vor, ein einfaches, generisches und effektives System, das einen iterativen Abrufprozess verwendet, um auf Ähnlichkeit basierende Informationen auf Codebasis abzurufen. (4) Hybrid-Code. Neben der Verwendung eines einzigen Informationstyps (z. B. Text oder Code) als Eingabe zum Auffinden relevanter Codes können mehrere Informationstypen zu hybriden Informationen kombiniert werden, um die Auffindungsgenauigkeit zu verbessern. Zum Beispiel haben Li et al. (2022a) nutzt ein leistungsfähiges Modell zur Codegenerierung, indem es eine Dokumentenabfrage mit Codeschnipseln erweitert, die vom Generierungsmodell generiert wurden (Generierung von Peer-to-Peer-Abschnitten), und dann die erweiterte Abfrage verwendet, um den Code abzurufen.ToolCoder Zhang et al. (2023d) Verwenden Sie Online-Suchmaschinen und Dokumentations-Suchwerkzeuge, um geeignete API-Empfehlungen zu erhalten, die bei der API-Auswahl und der Codegenerierung helfen. Darüber hinaus ist die Suche nicht auf eine bestimmte Art von Informationen beschränkt. (5) Code-Hybrid. Sie verwendet Code als Eingabe und ruft eine Vielzahl von relevanten Informationen ab. Zum Beispiel haben Nashid et al. (2023) eine neue Technik namens CEDAR für die Erstellung von Eingabeaufforderungen vor, die automatisch Codepräsentationen abruft, die für die Aufgabe des Entwicklers relevant sind, und zwar auf der Grundlage einer Einbettungs- oder Häufigkeitsanalyse.Geng et al.2023) Verwendung eines kontextuellen Lernparadigmas zur Erzeugung von Multi-Intent-Annotationen für Code durch Auswahl verschiedener Code-Annotationsbeispiele aus einem Pool von Beispielen. (6) Text-Mixing. Es verwendet Anforderungen als Input, um relevanten Code und ähnliche Probleme als Referenz zu finden. Zum Beispiel haben Li et al. (2023b) schlugen LAIL (LLM-Aware In-context Learning) vor, eine neue lernbasierte Auswahlmethode für die Auswahl von Beispielen, die für die Codegenerierung verwendet werden sollen.Li et al.2023c) führt einen neuen Mechanismus namens AceCoder ein, der die Abfrage ähnlicher Programme als Beispiele in den Eingabeaufforderungen nutzt, um eine große Menge relevanter Inhalte (z. B. Algorithmen, APIs) bereitzustellen.
Einer früheren Studie zufolge haben Li et al.2022c); Zhao et al. (2024); Hu et al. (2023a) lassen sich die bestehenden Suchmethoden in die spärliche Suche und die dichte Suche einteilen, wobei Wang et al.2024e), und andere Methoden Hayati et al. (2018); Zhang et al. (2020); Poesia et al. (2022); Ye et al. (2021); Shu et al. (2022). Abb. 4 zeigt die Pipeline der spärlichen und dichten Abfrage. Bei der dichten Retrieval-Methode wird die Eingabe in einen hochdimensionalen Vektor umgewandelt und die k Proben mit der höchsten Ähnlichkeit werden durch den Vergleich der semantischen Ähnlichkeiten ausgewählt, während bei der spärlichen Retrieval-Methode die BM25 oder Metriken wie TF-IDF zur Bewertung der Textähnlichkeit zwischen Proben. Darüber hinaus wurden verschiedene alternative Suchmethoden erforscht. So haben sich einige Studien auf die Berechnung der Editierdistanz zwischen natürlichsprachigen Texten konzentriert Hayati et al. (2018), oder ein abstrakter Syntaxbaum (AST) von Codefragmenten Zhang et al. (2020); Poesia et al. (2022). Es gibt auch Methoden, die Wissensgraphen für die Abfrage nutzen Ye et al. (2021); Shu et al. (2022).
Dichte und spärliche Retrievalmethoden sind die beiden vorherrschenden Retrievalmethoden. Von diesen sind dichte Retrievalverfahren in der Regel leistungsfähiger als spärliche Retrievalverfahren. Allerdings ist das Sparse Retrieval tendenziell effizienter und kann in einigen Fällen eine vergleichbare Leistung wie das Dense Retrieval erzielen. Daher entscheiden sich viele Studien aus Gründen der Effizienz für spärliche Retrievalverfahren.

Tabelle 1: Verschiedene Arten von Abrufvorgängen, gegliedert nach Eingabe und Ausgabe.

Abbildung 4: Flussdiagramm der verschiedenen Retrievalmethoden. Der linke Teil ist der Fluss der dichten Retrievalmethode, die verschiedene Modelle verwenden kann, um den Text in einen hochdimensionalen Einbettungsvektor umzuwandeln und die ähnlichsten Proben durch Vergleich der semantischen Ähnlichkeit zu finden. Der rechte Teil zeigt den Ablauf der Sparse-Retrieval-Methode, die nur die Textähnlichkeit vergleicht und die Semantik ignoriert.
Lernverhalten. Lernverhalten ist das kontinuierliche Lernen und Aktualisieren von Wissen durch das Erlernen und Aktualisieren des semantischen und prozeduralen Gedächtnisses, um die Qualität und Effizienz der Argumentation und Entscheidungsfindung zu verbessern. (1) Nutzung von Wissen zur Aktualisierung des semantischen Gedächtnisses. Das semantische Gedächtnis besteht hauptsächlich aus einer Wissensbasis, in der das zugrundeliegende Weltwissen gespeichert ist, das durch die Aktualisierung der Wissensbasis anhand des erkannten Codewissens oder durch den Aufbau einer neuen Wissensbasis aktualisiert werden kann. Zum Beispiel haben Liao et al. (2023) ein neuartiges Rahmenwerk für die Codegenerierung mit der Bezeichnung A3-CodGen vor, das durch die Nutzung von drei Arten von Informationen aus abgerufenen Bibliotheken (lokale Informationen aus der aktuellen Codedatei, globale Informationen aus anderen Codedateien und Bibliotheksinformationen von Drittanbietern) eine höhere Codequalität erzeugt.Du et al.2024) schlugen eine neue Technik zur Erkennung von Schwachstellen Vul-RAG vor, die auf großen Sprachmodellen (LLMs) basiert und mehrdimensionales Wissen aus bestehenden CVE-Instanzen über LLMs extrahiert, um eine Wissensbasis über Schwachstellen zu erstellen. (2) Aktualisierung von implizitem Wissen. Da implizites Wissen in den Parametern eines großen Sprachmodells gespeichert ist, können die LLM-Parameter durch Feinabstimmung des Modells aktualisiert werden. In früheren Arbeiten wurden typischerweise neue Daten konstruiert, um die Feinabstimmung von vortrainierten Modellen zu überwachen, wodurch die vollständigen Parameter der Modelle aktualisiert wurden.2023b); Wei et al. (2023a(math.) Gattungb); Tao et al. (2024); Wang et al. (2024d); Liu et al. (2023a); Wang et al. (2023d); Shi et al. (2023b). Die Kosten für die Feinabstimmung des Modells steigen jedoch mit zunehmender Größe der Parameter. In einigen Arbeiten wurde versucht, parameter-effiziente Feinabstimmungstechniken zu erforschen Weyssow et al. (2023); Shi et al. (2023c). Zum Beispiel haben Weyssow et al. (2023) führten eine umfassende Studie über parametereffiziente Feinabstimmungstechniken (PEFT) für große Sprachmodelle für automatisierte Codegenerierungsszenarien durch.Wang et al.2023b) eingefügt und den effizient feinabgestimmten Strukturadapter feinabgestimmt, anstatt das vortrainierte Modell feinabzustimmen. Die meisten der aktuellen Arbeiten verwenden effiziente Feinabstimmungstechniken zur Feinabstimmung des Modells Guo et al.2024); Shi et al. (2023d).
(3) Aktualisierung des Agentencodes. Agentencode bezieht sich auf die Programme oder Algorithmen, die ein Agent ausführt, um sein Verhalten und seinen Entscheidungsprozess zu steuern. Agenten, die auf großen Sprachmodellen basieren, tun dies, indem sie geeignete Aufforderungen als Agentencode konstruieren, um zu regeln, wie sie die Umgebung wahrnehmen, Schlussfolgerungen und Entscheidungen treffen und Operationen durchführen. Ein Großteil der Arbeiten verwendet Techniken zur Anweisungsanpassung, um die Ausgabe des großen Sprachmodells mit den Eingabeanweisungen abzugleichen. Zum Beispiel haben Muennighoff et al. (2023) nutzt die natürliche Struktur von Git-Commits, um Codeänderungen mit menschlichen Anweisungen zu verknüpfen und diese Anweisungen für Anpassungen zu verwenden.Hu et al.2023b) haben den ersten Datensatz zur Anweisungsoptimierung, InstructCoder, entwickelt, um große Sprachmodelle an die allgemeine Codebearbeitung anzupassen. Diese qualitativ hochwertigen Daten können neues Wissen in größere Sprachmodelle einbringen und das semantische Gedächtnis aktualisieren.Zan et al.2023) führten umfangreiche Experimente mit acht beliebten Programmiersprachen auf StarCoder durch, um zu untersuchen, ob sich Programmiersprachen durch Befehlsabstimmung gegenseitig verbessern können.
2.3.2 Externe Maßnahmen
Dialog mit Menschen/Agenten Agenten können mit Menschen oder anderen Agenten interagieren und während der Interaktion reichhaltige Informationen als Feedback erhalten, wodurch das Wissen des Agenten erweitert und die Antworten des großen Sprachmodells genauer werden. Insbesondere wurden viele Arbeiten durchgeführt, die große Sprachmodelle als Agenten für die Interaktion verwenden, z. B. Lu et al.2024); Jain et al. (2023); Paul et al. (2023); Shojaee et al. (2023); Liu et al. (2023b); Wang et al. (2023e); Mu et al. (2023); Madaan et al. (2023Jain et al. (2023) schlug RLCF vor, das Feedback von verschiedenen großen Sprachmodellen verwendet, um den generierten Code mit dem Referenzcode zu vergleichen, um vortrainierte große Sprachmodelle durch Verstärkungslernen weiter zu trainieren.REFINER Paul et al.2023) ist ein Rahmen für die Interaktion mit kritischen Modellen, die automatische Rückmeldungen liefern.Yang et al.2023b) untersuchten und erläuterten, wie große Sprachmodelle von der Diskriminanzmodellierung profitieren.Moon et al.2023) konstruierten einen neuen Datensatz, der speziell für die Code-Reparatur entwickelt wurde, und nutzten ihn, um ein Modell zu erhalten, das automatisch nützliches Feedback durch präferenzoptimierte Abstimmung und Auswahl generieren kann: PPOCoder Shojaee et al.2023) besteht aus zwei Komponenten, dem Kritiker und dem Ausführenden, und wird mit PPO durch die Interaktion zwischen diesen beiden Modellen optimiert.RLTF Liu et al.2023b) interagiert mit anderen Modellen, die reale Daten und online zwischengespeicherte Daten nutzen, die durch Interaktion mit dem Compiler erzeugt werden, um Verluste zu berechnen und Modellgewichte durch Gradientenrückkopplung zu aktualisieren.Wang et al.2023e) schlugen ChatCoder vor, eine Methode zur Verfeinerung von Anforderungen durch Chatten mit einem großen Sprachmodell. Sun et al.2023a) schlug Clover vor, ein Werkzeug, das die Konsistenz zwischen Code, Dokumentationsstrings und formalen Kommentaren überprüft.ClarifyGPT Mu et al. (2023) veranlasst ein weiteres großes Sprachmodell, gezielte Klärungsfragen zu generieren, um die mehrdeutigen Anforderungen der Benutzereingabe zu präzisieren.Reflexion Shinn et al. (2023) können mit Menschen und anderen Agenten interagieren, um externes Feedback zu generieren Madaan et al.2023) verwendet ein einziges großes Sprachmodell als Generator, Korrektor und Feedbackgeber ohne überwachte Trainingsdaten, zusätzliches Training oder Verstärkungslernen.Repilot Wei et al. (2023c) synthetisiert durch die Interaktion zwischen dem großen Sprachmodell und der Vervollständigungsmaschine Kandidatenpatches. Repilot schneidet insbesondere nicht realisierbare Token auf der Grundlage der Vorschläge des großen Sprachmodells aus.Wang et al.2023c) stellten MINT vor, einen Benchmark-Test, mit dem die Fähigkeit eines großen Sprachmodells zur Lösung interaktiver Mehrrundenaufgaben anhand von natürlichem Sprachfeedback von mit GPT-4 simulierten Nutzern bewertet werden kann. Hong et al. (2023b) schlugen MetaGPT vor, ein innovatives Metaprogrammierungssystem, das auf der Grundlage eines großen Sprachmodells effiziente menschliche Arbeitsabläufe in die Zusammenarbeit mit Multiagenten einbezieht.Huang et al.2023a) stellte AgentCoder vor, eine neuartige Lösung zur Codegenerierung, die ein Multi-Agenten-Framework mit spezialisierten Agenten umfasst: einen Programmierer-Agenten, einen Testdesigner-Agenten und einen Testausführungs-Agenten.
Die digitale Umgebung Agenten können mit digitalen Systemen wie der OJ-Plattform, Webseiten, Compilern und anderen externen Werkzeugen interagieren, und die während der Interaktion gewonnenen Informationen können als Feedback zur eigenen Optimierung genutzt werden. Insbesondere Compiler sind die gängigsten externen Werkzeuge, wie Jain et al (2023); Shojaee et al. (2023); Liu et al. (2023b); Wang et al. (2022); Zhang et al.2023e). Zum Beispiel, RLCF Jain et al. (2023) prüft, ob der von ihm erzeugte Code eine Reihe von Korrektheitsprüfungen besteht, indem er ein vorab trainiertes umfangreiches Sprachmodell mit Hilfe des vom Compiler abgeleiteten Feedbacks trainiert.PPOCoder Shojaee et al. (2023) kann Compiler-Feedback und strukturellen Abgleich als zusätzliches Wissen für die Modelloptimierung einbeziehen, um das Code-Generierungsmodell durch Deep Reinforcement Learning (RL) fein abzustimmen.RLTF Liu et al.2023b) interagiert mit dem Compiler, um Trainingsdatenpaare zu erzeugen, und speichert sie in einem Online-Cache.Wang et al.2022) schlugen COMPCODER vor, das Compiler-Feedback für die Generierung von kompilierbarem Code verwendet.Zhang et al.2023e) schlugen Self-Edit vor, ein Generierungs- und Editierungsverfahren zur Verbesserung der Codequalität bei wettbewerbsorientierten Programmieraufgaben unter Verwendung von Ausführungsergebnissen aus Code, der aus einem großen Sprachmodell generiert wurde. Darüber hinaus wurden in vielen Arbeiten Werkzeuge wie Suchmaschinen, Komplementärmaschinen usw. entwickelt, um die Fähigkeiten intelligenter Agenten zu erweitern.2024a); Zhang et al.2024); Agrawal et al. (2023); Wei et al.2023c); Zhang et al.2023fWang et al. (2024a) stellten TOOLGEN vor, eine Methode zur Integration von Autovervollständigungswerkzeugen in den Codegenerierungsprozess für große Sprachmodelle, um Abhängigkeitsfehler wie undefinierte Variablen und fehlende Mitglieder zu beheben.Zhang et al.2024) stellten CodeAgent vor, ein neuartiges Agenten-Framework für die Modellierung großer Sprachen, das fünf Programmierwerkzeuge integriert, um die Interaktion mit der Softwaredokumentation zu Informationszwecken, die Navigation in Codesymbolen und das Testen von Code für eine effektive Codegenerierung auf Repository-Ebene zu ermöglichen.Agrawal et al.2023) schlugen MGD vor, ein monitorgesteuertes Dekodierungsverfahren, bei dem der Monitor die statische Analyse zur Steuerung der Dekodierung verwendet.Repilot Wei et al.2023c) synthetisiert durch die Interaktion zwischen dem großen Sprachmodell und der Vervollständigungsmaschine Kandidaten-Patches. Konkret vervollständigt Repilot Token auf der Grundlage der von der Vervollständigungsmaschine gelieferten Vorschläge.
3 Herausforderungen und Chancen
Nach der Analyse des Inhalts im Zusammenhang mit der Arbeit an Large Language Model (LLM)-basierten Agenten im Software-Engineering ist es offensichtlich, dass die Integration dieser beiden Bereiche immer noch vor vielen Herausforderungen steht, die ihre Entwicklung einschränken. In diesem Abschnitt werden die aktuellen Herausforderungen, mit denen LLM-basierte Agenten in der Softwareentwicklung konfrontiert sind, im Detail erörtert und Möglichkeiten für zukünftige Arbeiten auf der Grundlage der Analyse der bestehenden Herausforderungen diskutiert.
3.1 Unzureichende Erkundung der sensorischen Module
z.B. Nr. 1 2.1 Wie im Abschnitt beschrieben, sind LLM-basierte Agenten für Wahrnehmungsmodule in der Softwareentwicklung noch nicht ausreichend erforscht. Im Gegensatz zu natürlicher Sprache ist Code eine besondere Art der Darstellung, die als gewöhnlicher Text behandelt oder in Zwischendarstellungen mit Code-Merkmalen wie abstrakte Syntaxbäume (ASTs), Kontrollflussgraphen (CFGs) usw. umgewandelt werden kann. Bestehende Arbeiten wie die von Ahmed et al. (2024); Al-Kaswan et al. (2023); Arakelyan et al. (2023); Beurer-Kellner et al. (2023); Alqarni und Azim (2022) Code wird in der Regel als Text betrachtet und es gibt immer noch einen Mangel an Forschung, die baum- oder grafikbasierte Eingabemodalitäten in LLM-basierten Agenten, die in der Softwareentwicklung arbeiten, untersucht. Darüber hinaus sind visuelle und auditive Eingabemodalitäten ebenfalls noch nicht ausreichend erforscht.
3.2 Fähigkeiten im Rollenspiel
LLM-basierte Agenten müssen oft verschiedene Rollen in einer Vielzahl von Aufgaben übernehmen, die jeweils spezifische Fähigkeiten erfordern. Zum Beispiel kann ein Agent als Code-Generator agieren, wenn er aufgefordert wird, Code zu generieren, und als Code-Tester, wenn er Code-Tests durchführt. Darüber hinaus müssen diese Agenten in einigen Szenarien möglicherweise mehr als eine Fähigkeit gleichzeitig besitzen. In Szenarien zur Codegenerierung muss der Agent beispielsweise sowohl als Codegenerator als auch als Tester fungieren und muss daher die Fähigkeit haben, Code zu generieren und zu testen (Huang et al. 2023b). Im Bereich der Softwareentwicklung gibt es viele Nischenaufgaben, für die LLM-Lernen nicht ausreicht, und komplexe Aufgaben, die von Agenten mehrere Fähigkeiten erfordern, wie z. B. Szenarien für die Testerstellung, Front-End-Entwicklung und Problemlösung auf Repository-Ebene. Daher ist die weitere Erforschung der Frage, wie Agenten in die Lage versetzt werden können, effektiv neue Rollen zu übernehmen und die Anforderungen der Multi-Rollen-Performance zu bewältigen, eine vielversprechende Richtung für zukünftige Arbeiten.
3.3 Unzureichende Basis für die Wissensabfrage
Externe Wissensdatenbanken sind ein wichtiger Teil des semantischen Speichers im Speichermodul des Agenten und ein wichtiges externes Werkzeug, mit dem Agenten interagieren können. Im Bereich der natürlichen Sprachverarbeitung (Natural Language Processing, NLP) gibt es Wissensdatenbanken wie Wikipedia als externe Abfragebasen (Zhao et al. 2023). Im Bereich der Softwaretechnik gibt es jedoch keine verbindliche und anerkannte Wissensbasis, die eine Fülle von codebezogenem Wissen enthält, wie z. B. die grundlegende Syntax verschiedener Programmiersprachen, häufig verwendete Algorithmen, Wissen über Datenstrukturen und Betriebssysteme. In der künftigen Forschung können Anstrengungen unternommen werden, um eine umfassende Code-Wissensbasis zu entwickeln, die als Grundlage für den externen Abruf von Agenten verwendet werden kann. Diese Wissensbasis wird die verfügbaren Informationen bereichern und so die Qualität und Effizienz des Denk- und Entscheidungsprozesses verbessern.
3.4 Illusorische Phänomene in LLM-basierten Agenten
Viele Studien, die sich mit LLM-basierten Agenten befassen, betrachten das LLM als den kognitiven Kern des Agenten, und die Gesamtleistung des Agenten ist eng mit den Fähigkeiten des zugrunde liegenden LLM verbunden. Bestehende Studien (Pan et al. 2024Liu et al. 2024a) deutet darauf hin, dass LLM-basierte Agenten Halluzinationen hervorrufen können, wie z. B. die Generierung nicht vorhandener APIs bei der Durchführung von Softwareentwicklungsaufgaben. Die Verringerung dieser Halluzinationen kann die Gesamtleistung des Agenten verbessern. Gleichzeitig kann die Optimierung des Agenten auch umgekehrt die Halluzinationen von LLM-basierten Agenten abschwächen, was eine bidirektionale Beziehung zwischen Agentenleistung und Halluzinationsabschwächung verdeutlicht. Obwohl mehrere Studien das Phänomen der Halluzinationen bei LLM erforscht haben, gibt es noch erhebliche Herausforderungen bei der Behandlung von Halluzinationen bei LLM-basierten Agenten. Die Erforschung der Arten von Halluzinationen, die in LLM-basierten Agenten auftreten, die eingehende Analyse der Ursachen dieser Halluzinationen und der Vorschlag effektiver Methoden zur Linderung von Halluzinationen sind wichtige Möglichkeiten für zukünftige Forschung.
3.5 Effizienz der Zusammenarbeit zwischen mehreren Geheimdiensten
Bei der Zusammenarbeit mehrerer Intelligenzen muss jede einzelne Intelligenz eine andere Rolle spielen, um eine bestimmte Aufgabe zu erfüllen, und dann werden die Ergebnisse der Entscheidungen der einzelnen Intelligenzen kombiniert, um gemeinsam komplexere Ziele zu erreichen Chen et al.2023b); Hong et al. (2023a); Huang et al. (2023b); Wang et al. (2023a). Dieser Prozess erfordert jedoch in der Regel eine große Menge an Rechenressourcen für jede Intelligenz, was zu einer Verschwendung von Ressourcen und einer geringeren Effizienz führt. Darüber hinaus muss jede einzelne Intelligenz verschiedene Informationen synchronisieren und austauschen, was zusätzliche Kommunikationskosten verursacht und die Echtzeit und Reaktionsfähigkeit der Zusammenarbeit beeinträchtigt. Die effiziente Verwaltung und Zuweisung von Rechenressourcen, die Minimierung der Kommunikationskosten zwischen den einzelnen Intelligenzen und die Verringerung des Rechenaufwands der einzelnen Intelligenzen sind die wichtigsten Herausforderungen bei der Verbesserung der Effizienz der Zusammenarbeit mehrerer Intelligenzen. Die Bewältigung dieser Probleme bietet bedeutende Möglichkeiten für die künftige Forschung.
3.6 Anwendung von Software-Engineering-Techniken auf Intelligenzia auf der Grundlage großer Sprachmodelle
Technologien im Bereich der Softwaretechnik, insbesondere der Kodierung, haben das Potenzial, den Bereich der Intelligenz erheblich voranzubringen, was eine für beide Seiten vorteilhafte Beziehung zwischen den beiden Bereichen nahelegt. So können z. B. Software-Testverfahren angepasst werden, um anomale Verhaltensweisen und potenzielle Fehler in intelligenten Systemen auf der Grundlage großer Sprachmodelle zu erkennen. Darüber hinaus können Verbesserungen bei den Softwarewerkzeugen (z. B. APIs und Bibliotheken) die Leistung von intelligenten Systemen auf der Grundlage großer Sprachmodelle erhöhen, insbesondere bei intelligenten Systemen, die Werkzeuge nutzen können. Darüber hinaus können Techniken zur Paketverwaltung angepasst werden, um das intelligente Körpersystem effizient zu verwalten. Beispielsweise kann die Versionskontrolle zur Überwachung und Koordinierung von Aktualisierungen verschiedener Intelligenzen in einem intelligenten Körpersystem eingesetzt werden, um die Kompatibilität und Systemintegrität zu verbessern.
Die Forschung in diesem Bereich ist jedoch noch begrenzt. Daher stellt die Erforschung der Einbeziehung komplexerer SE-Techniken in intelligente Körpersysteme eine vielversprechende Richtung für die künftige Forschung dar, die den Fortschritt in beiden Bereichen vorantreiben kann.
4 Schlussfolgerung
Um die Arbeiten zur Kombination von auf großen Sprachmodellen basierenden Intelligenzen mit Software-Engineering eingehend zu analysieren, haben wir zunächst zahlreiche Studien zur Kombination von auf großen Sprachmodellen basierenden Intelligenzen mit Aufgaben im Bereich Software-Engineering gesammelt. Nach der Zusammenstellung und Analyse der Studien, die wir während des Zeitraums der Datenerhebung erhalten haben, stellen wir einen Rahmen für große, auf Sprachmodellen basierende Intelligenzen in der Softwaretechnik vor, der drei Schlüsselmodule enthält: Wahrnehmung, Gedächtnis und Handlung. Abschließend stellen wir detaillierte Informationen zu jedem Modul des Rahmens vor, analysieren die aktuellen Herausforderungen, denen sich die auf großen Sprachmodellen basierende Intelligenz im Software-Engineering gegenübersieht, und zeigen einige Möglichkeiten für zukünftige Arbeiten auf.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel

Keine Kommentare...