:边查边写的检索策略,适合查询实时数据-1")
:边查边写的检索策略,适合查询实时数据-2")
:边查边写的检索策略,适合查询实时数据-3")
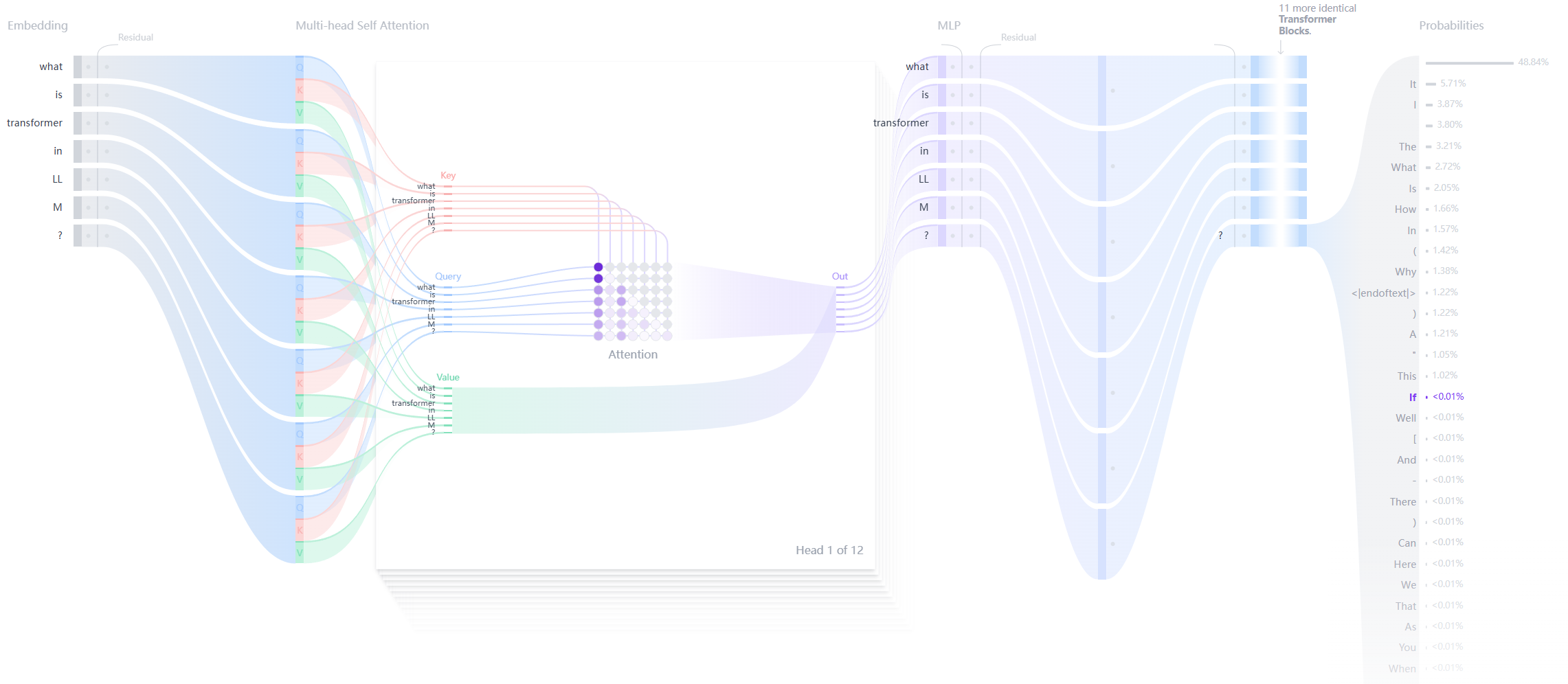
RIG (Retrieval Interleaved Generation): eine Retrieval-Strategie des Schreibens während der Suche, geeignet für die Abfrage von Echtzeitdaten

Technologischer Kern: Interleaved Retrieval Generation (RIG)
- Was ist RIG?
RIG ist eine innovative generative Methodik, die das Problem der Halluzinationen bei der Verarbeitung statistischer Daten durch große Sprachmodelle lösen soll. Während herkömmliche Modelle ungenaue Zahlen oder Fakten aus dem Nichts generieren können, gewährleistet RIG die Authentizität der Daten, indem es Abfragen an externe Datenquellen in den Generierungsprozess einfügt. - Arbeitsprinzip ::
- Wenn das Modell eine Frage erhält, die Statistiken erfordert, ruft es dynamisch Data Commons auf (eine von Google betriebene Wissensdatenbank für öffentliche Daten), während es die Antwort generiert.
- Die Ergebnisse der Abfrage werden in die Ausgabe in natürlicher Sprache eingebettet, zum Beispiel:[DC("Wie hoch ist die Einwohnerzahl von Frankreich?") --> "67 Millionen"].
- Diese "Verschränkung von Abruf und Erzeugung" ermöglicht es dem Modell, die Sprachflüssigkeit zu erhalten und gleichzeitig validierte statistische Informationen zu liefern.
Details zum Modell
- Grundmodell Gemma 2 (27B-Parameter-Version), ein effizientes Open-Source-Sprachmodell, das für Forschung und Experimente entwickelt wurde.
- Feinabstimmung der Ziele Data Commons: Speziell geschult, um zu erkennen, wann Data Commons abgefragt werden muss und um diese Daten nahtlos in den Generierungsprozess zu integrieren.
- Eingänge und Ausgänge ::
- Eingabe: Eine beliebige Texteingabe (z. B. eine Frage oder Aussage).
- Ausgabe: Englischer Text, kann eingebettete Data Commons-Abfrageergebnisse enthalten.
- Mehrsprachigkeit Hauptsächlich wird Englisch unterstützt ("it" kann "instruction-tuned" bedeuten, d. h. eine auf die Anweisungen abgestimmte Version, aber die Seite gibt die Sprachpalette nicht an).
Anwendungsszenario
- Zielbenutzer : Akademische Forscher, Datenwissenschaftler.
- verwenden. Geeignet für Szenarien, in denen genaue Statistiken benötigt werden, z. B. Antworten auf "die Bevölkerung eines Landes", "weltweite CO2-Emissionen in einem bestimmten Jahr" usw.
- Einschränkung Derzeit eine frühe Version und nur für vertrauenswürdige Tester, nicht empfohlen für Produktionsumgebungen oder kommerzielle Nutzung.
Modelle:https://huggingface.co/google/datagemma-rig-27b-it
Ursprünglicher Text:https://arxiv.org/abs/2409.13741
RIG-Realisierungsprozess
RIG ist ein Ansatz, der Abfrage und Generierung miteinander verschränkt und darauf abzielt, die Genauigkeit der generierten Ergebnisse zu verbessern, indem LLM natürlichsprachliche Abfragen generiert, um Daten aus Data Commons abzurufen. Im Folgenden werden die einzelnen Schritte der Implementierung von RIG beschrieben:
1. Modell-Feinabstimmung (Modell-Feinabstimmung)
ZieleLLM soll lernen, Abfragen in natürlicher Sprache zu erstellen, die zum Abrufen von Statistiken aus Data Commons verwendet werden können.
umziehen::
- Erste Abfrage und GenerierungWenn LLM eine statistische Anfrage erhält, generiert es normalerweise einen Text, der eine numerische Antwort enthält. Wir werden diese numerische Antwort bezeichnen alsVom LLM erzeugte statistische Werte (LLM-SV)Zum Beispiel für die Abfrage "Wie hoch ist die Gesamtbevölkerung von Kalifornien? Zum Beispiel für die Abfrage "Wie hoch ist die Gesamtbevölkerung von Kalifornien?" könnte LLM "Die Gesamtbevölkerung von Kalifornien beträgt etwa 39 Millionen" generieren.
- Identifizierung der relevanten DatenAus dem vom LLM generierten Text müssen wir die relevantesten Daten aus der Data-Commons-Datenbank ermitteln, um sie den Nutzern als Faktenprüfungsmechanismus zur Verfügung zu stellen. Wir bezeichnen diesen abgerufenen Wert alsData Commons Statistische Werte (DC-SV).
- Generierung von Abfragen in natürlicher SpracheUm dies zu erreichen, stimmen wir LLM so ab, dass es eine natürlichsprachliche Abfrage generiert, die LLM-SV zusammen mit LLM-SV beschreibt. Diese Abfrage wird verwendet, um Daten von Data Commons abzurufen.
:边查边写的检索策略,适合查询实时数据-1")
Abbildung 1: Vergleich der Antworten auf Abfragen; Baseline Gemma (Gemma 7B IT, Gemma 2 27B IT) ohne Schnittstelle zu Data Commons und Retrieve Interleaved Generation (RIG) Antworten.Abbildung 1Ein Vergleich der Antworten des Gemma-Basismodells und des RIG-Modells zeigt, dass das RIG-Modell nicht nur die statistischen Werte, sondern auch die für das Retrieval verwendeten Abfragen generiert.
- TrainingsdatensatzWir verwenden einen Befehl-Antwort-Datensatz mit etwa 700 Benutzeranfragen für die Feinabstimmung. Für jede Anfrage wählen wir Antworten aus, die vom Basismodell mit statistischen Daten generiert wurden (etwa 400 Beispiele), und verwenden ein leistungsfähigeres LLM (z. B. Gemini 1.5 Pro), um natürlichsprachliche Data Commons-Aufrufe zu generieren.
typisches Beispiel::
- (ein Dokument usw.) einsehenNennen Sie mir eine Statistik über Kalifornien, San Francisco, Alabama und die USA.
- rohe Antwort::
- Kalifornien ist der bevölkerungsreichste Staat der Nation und wird im Jahr 2020 etwa 39 Millionen Einwohner haben.
- In San Francisco liegt die Diabetesrate bei 9,2 Fällen pro 10000 Einwohner.
- ...
- Feinabgestimmte Reaktion::
- Kalifornien ist der bevölkerungsreichste Staat der Nation, mit etwa [DC("Wie hoch war die Einwohnerzahl Kaliforniens im Jahr 2020?") --> "39 Millionen"] Menschen.
- In San Francisco ist die Diabetesrate [DC("Wie hoch ist die Prävalenz von Diabetes in San Francisco?") --> "9,2 Fälle pro 10000 Einwohner"].
- ...
2. Abfrage-Konvertierung
ZieleKonvertiert von LLM generierte Abfragen in natürlicher Sprache in strukturierte Abfragen zum Abruf von Daten aus Data Commons.
umziehen::
- eine Abfrage zerlegenZerlegen Sie die natürlichsprachliche Anfrage in die folgenden Komponenten:
- Statistische Variablen oder Themen:: z.B. "Arbeitslosenquote", "Demographie", usw.
- StandorteZum Beispiel: "Kalifornien".
- Kausalität:: z.B. "Rangfolge", "Vergleich", "Veränderungsrate", usw.
- Kartierung und IdentifizierungAbbilden dieser Komponenten auf die entsprechenden IDs in Data Commons, z. B. durch einbettungsbasierte semantische Suchindizierung zur Identifizierung statistischer Variablen und stringbasierte Named-Entity-Identifizierung zur Identifizierung von Standorten.
- Kategorie- und VorlagenabgleichKlassifizierung: Klassifizierung von Abfragen in einen festen Satz von Abfragevorlagen auf der Grundlage der identifizierten Komponenten. Beispiel:
- Wie viele XX in YY(YY有多少XX))
- Wie ist die Korrelation zwischen XX und YY über ZZ in AA (Wie ist die Korrelation zwischen XX und YY über ZZ in AA)
- Welche XX in YY haben die höchste Anzahl von ZZ (YY中哪些XX的ZZ数量最多)
- Was sind die wichtigsten XX in YY(YY中最显著的XX是什么 35 was sind die wichtigsten XX in YY 34)
Abbildung 2: Vergleich der Baseline-, RIG- und RAG-Methoden zur Erstellung von Antworten mit Statistiken. Der Baseline-Ansatz berichtet direkt Statistiken, ohne Beweise zu liefern, während RIG und RAG Data Commons nutzen, um maßgebliche Daten zu liefern.Abbildung 2Der RIG-Ansatz generiert statistische Tags, indem er sie mit natürlichsprachlichen Fragen verknüpft, die für die Abfrage von Data Commons geeignet sind.
- Ausführung der AbfrageStrukturierte Daten: Rufen Sie die strukturierte Daten-API von Data Commons auf, um Daten auf der Grundlage von Abfragevorlagen und IDs von Variablen und Orten abzurufen.
3. Erfüllung
ZieleDie abgerufenen Daten werden dem Benutzer zusammen mit den vom LLM generierten statistischen Werten präsentiert.
umziehen::
- Präsentation der DatenDie von Data Commons zurückgegebenen Antworten werden dem Nutzer zusammen mit den vom ursprünglichen LLM generierten Statistiken präsentiert. Dies gibt den Nutzern die Möglichkeit, den LLM auf seine Richtigkeit zu überprüfen.
Abbildung 3: RIG-Bewertungstool. Diese Abbildung zeigt Screenshots der beiden Bewertungsphasen, die nebeneinander angezeigt werden. Für jede Phase gibt es zwei Bereiche. Auf der linken Seite wird dem Benutzer die gesamte zu bewertende Antwort angezeigt (aus Platzgründen in der obigen Abbildung ausgeschlossen). Auf der rechten Seite befindet sich die Bewertungsaufgabe. In Stufe 1 führt der Bewerter eine Schnellprüfung auf offensichtliche Fehler durch. In Stufe 2 bewertet der Bewerter jede Statistik in der Antwort.Abbildung 3Zeigt den Prozess der Verwendung des RIG-Bewertungstools. Der Bewerter kann schnell auf offensichtliche Fehler prüfen und jede Statistik in der Antwort auswerten.
- BenutzererfahrungEs gibt eine Vielzahl von Möglichkeiten, dieses neue Ergebnis zu präsentieren, wie z. B. Nebeneinanderstellung, Hervorhebung von Unterschieden, Fußnoten, Hover-Aktionen usw., die im Rahmen künftiger Arbeiten erforscht werden können.
Zusammenfassungen
Der RIG-Implementierungsprozess umfasst die folgenden wichtigen Schritte:
- Feinabstimmung der ModelleLLM: Lassen Sie LLM natürlichsprachliche Abfragen generieren, die die von LLM generierten statistischen Werte beschreiben.
- Abfrage-KonvertierungKonvertierung von Abfragen in natürlicher Sprache in strukturierte Abfragen zum Abrufen von Daten aus Data Commons.
- Datenabfrage und -darstellungAbruf von Daten aus Data Commons und Präsentation der abgerufenen Daten für den Benutzer zusammen mit den vom LLM generierten Statistiken.
Durch diese Schritte kombiniert die RIG-Methode effektiv die generativen Fähigkeiten von LLM mit den Datenressourcen von Data Commons und verbessert so die Genauigkeit von LLM bei der Verarbeitung statistischer Abfragen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...