Qwen3-ASR-Flash - eine Reihe von Spracherkennungsmodellen, die von Ali Tongyi Qianqian entwickelt wurden

Was ist Qwen3-ASR-Flash?
Qwen3-ASR-Flash ist das neueste hochpräzise Spracherkennungsmodell von Alibaba, das auf dem Qwen3 Basismodell, trainiert mit umfangreichen multimodalen Daten. Es unterstützt 11 Sprachen und mehrere Akzente, darunter Dialekte wie Mandarin, Sichuan, Minnan, Wu, Kantonesisch sowie britisches und amerikanisches Englisch. Zu den Hauptmerkmalen gehören die führende Erkennungsgenauigkeit, die erstaunliche Fähigkeit zur Erkennung von Liedern (Fehlerrate unter 8%), die benutzerdefinierte Erkennung (Benutzer können Hintergrundtext bereitstellen, um benutzerdefinierte Ergebnisse zu erhalten), die Spracherkennung mit Unterdrückung von Nicht-Vokalen und die hohe Robustheit in komplexen akustischen Umgebungen. Nutzer können das Modell kostenlos über ModelScope, Hugging Face und die AliCloud Hundred Refinements API testen.
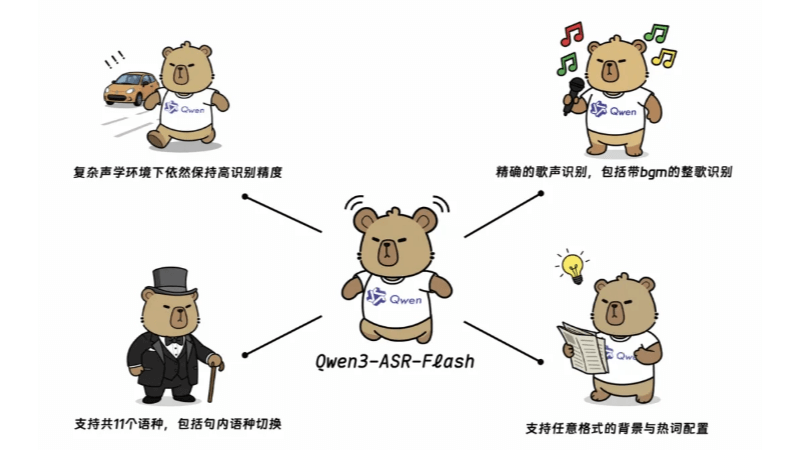
Qwen3-ASR-Flash Funktionsmerkmale
- Hochpräzise ErkennungDie beste Leistung in englischen, chinesischen und mehrsprachigen Benchmarks, mit genauer Erkennung mehrerer Sprachen und Dialekte.
- Song-ErkennungDas System unterstützt reines Singen und die Erkennung ganzer Lieder mit Hintergrundmusik, und die gemessene Fehlerrate ist niedriger als 8%.
- Kundenspezifische IdentifizierungDer Benutzer kann den Hintergrundtext in einem beliebigen Format zur Verfügung stellen, und das Modell kann die Erkennungsergebnisse entsprechend anpassen, ohne dass eine Vorverarbeitung erforderlich ist.
- Spracherkennung und nicht-vokale AblehnungPräzise Unterscheidung von Sprachen und automatisches Herausfiltern von Nicht-Sprachsegmenten wie Stille und Hintergrundgeräusche.
- hohe RobustheitBehält eine hohe Genauigkeit in komplexen akustischen Umgebungen und bei schwierigen Textmustern wie langen und schwierigen Sätzen und Sprachwechsel mitten im Satz bei.
Die wichtigsten Vorteile von Qwen3-ASR-Flash
- Hochpräzise ErkennungHervorragende Leistung bei Tests zur Erkennung von mehreren Sprachen und Dialekten, mit niedrigeren Fehlerquoten als bei vergleichbaren Wettbewerbern.
- Unterstützung mehrerer SprachenDas einzige Modell unterstützt 11 Sprachen und mehrere Dialekte, darunter Mandarin, Englisch, Französisch und Deutsch.
- Kundenspezifische IdentifizierungBenutzer können Hintergrundtexte in beliebigen Formaten bereitstellen, und das Modell kann die Kontextinformationen intelligent nutzen, um individuelle Erkennungsergebnisse auszugeben.
- Song-ErkennungDie gemessene Fehlerrate ist niedriger als 8%, was eine hervorragende Leistung im Bereich der Liederkennung darstellt.
- Spracherkennung und nicht-vokale AblehnungDie Fähigkeit, Sprachen genau zu unterscheiden und Nicht-Sprach-Segmente wie Stille und Hintergrundgeräusche automatisch herauszufiltern, verbessert die Erkennungseffizienz.
- hohe RobustheitBehält eine hohe Genauigkeit in komplexen akustischen Umgebungen und bei schwierigen Textmustern wie langen und schwierigen Sätzen und Sprachwechsel mitten im Satz bei.
Was ist die offizielle Website für Qwen3-ASR-Flash?
- Projekt-Website: https://bailian.console.aliyun.com/?spm=5176.29597918.J_tAwMEW-mKC1CPxlfy227s.1.4f007b08aWhTjW&tab=model#/model-market/detail /group-qwen3-asr-flash?modelGroup=group-qwen3-asr-flash
- Online-Erlebnis-Demo:: https://huggingface.co/spaces/Qwen/Qwen3-ASR-Demo
Personen, für die Qwen3-ASR-Flash bestimmt ist
- Benutzer, die eine hochpräzise Sprachtranskription benötigen: z.B. Journalisten, Konferenzschreiber, Forscher, etc. können schnell und präzise Sprachinhalte in Text umwandeln.
- mehrsprachig: z. B. Fremdsprachenlerner, Mitarbeiter multinationaler Unternehmen, Teilnehmer an internationalen Konferenzen usw., können dazu beitragen, Sprachbarrieren zu überwinden.
- Ersteller von Inhalten: z.B. Video-Blogger, Podcast-Hosts, etc. können effizient Untertitel und Transkripte erstellen.
- Fachleute auf diesem GebietSo können z. B. Fachleute aus dem medizinischen, finanziellen und juristischen Bereich maßgeschneiderte Erkennungsfunktionen nutzen, um Terminologie genau zu identifizieren.
- Menschen mit besonderen Anforderungen an die SpracherkennungSo zum Beispiel Hörgeschädigte, die mit Hilfe des Modells Sprachinformationen besser verstehen können, und Nutzer, die in lauten Umgebungen Spracherkennung benötigen, wie Kundendienstmitarbeiter und Journalisten vor Ort.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...