
Qwen2.5-VL veröffentlicht: Unterstützt langes Videoverstehen, visuelle Lokalisierung, strukturierte Ausgabe, Open Source Feinabstimmung

1.Modell Einführung
In den fünf Monaten seit der Veröffentlichung von Qwen2-VL haben zahlreiche Entwickler neue Modelle auf der Grundlage des visuellen Sprachmodells Qwen2-VL erstellt und dem Qwen-Team wertvolles Feedback gegeben. Während dieser Zeit hat sich das Qwen-Team darauf konzentriert, noch nützlichere visuelle Sprachmodelle zu entwickeln. Heute freut sich das Qwen-Team, das neueste Mitglied der Qwen-Familie vorstellen zu können: Qwen2.5-VL.
Wichtige Verbesserungen:
- Visuelles Verständnis: Qwen 2.5-VL ist nicht nur in der Lage, gewöhnliche Objekte wie Blumen, Vögel, Fische und Insekten zu erkennen, sondern auch Texte, Diagramme, Icons, Grafiken und Layouts in Bildern zu analysieren.
- Agentizität: Qwen2.5-VL spielt direkt die Rolle eines visuellen Agenten, mit der Funktionalität eines schlussfolgernden und dynamischen Befehlstools, das auf Computern und Mobiltelefonen verwendet werden kann.
- Verstehen langer Videos und Erfassen von Ereignissen: Qwen 2.5-VL kann Videos verstehen, die länger als 1 Stunde sind, und verfügt nun über die neue Fähigkeit, Ereignisse zu erfassen, indem relevante Videoclips lokalisiert werden.
- Visuelle Lokalisierung in verschiedenen Formaten: Qwen2.5-VL kann Objekte in einem Bild genau lokalisieren, indem es Begrenzungsrahmen oder Punkte generiert und stabile JSON-Ausgaben für Koordinaten und Attribute liefert.
- Strukturierte Ausgabe: Für gescannte Daten wie Rechnungen, Formulare, Tabellen usw. unterstützt Qwen 2.5-VL die strukturierte Ausgabe ihrer Inhalte, was für den Einsatz im Finanzwesen, in der Wirtschaft und anderen Bereichen von Vorteil ist.
Modell der Architektur:
- Training der dynamischen Auflösung und Bildrate für das Verstehen von Videos:
Durch die Ausweitung der dynamischen Auflösung auf die zeitliche Dimension mittels dynamischer FPS-Abtastung kann das Modell Videos mit verschiedenen Abtastraten verstehen. Dementsprechend aktualisierte das Qwen-Team mRoPE mit ID und absoluter Zeitausrichtung in der zeitlichen Dimension, so dass das Modell die zeitliche Reihenfolge und Geschwindigkeit erlernen kann und letztendlich die Fähigkeit erhält, bestimmte Momente genau zu bestimmen.
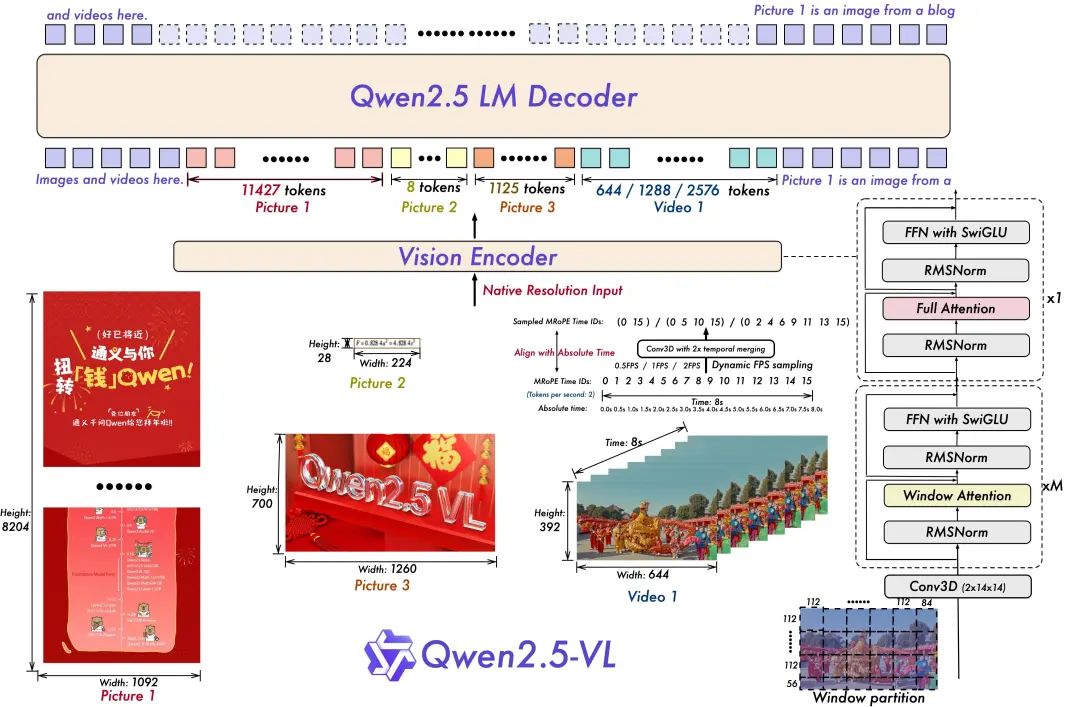
- Schlanker und effizienter visueller Codierer
Das Qwen-Team hat die Trainings- und Inferenzgeschwindigkeit durch die strategische Einführung des fensterbasierten Aufmerksamkeitsmechanismus in ViT verbessert. Die ViT-Architektur wurde mit SwiGLU und RMSNorm weiter optimiert, um sie an die Struktur des Qwen 2.5 LLM anzupassen.
Es gibt drei Modelle in dieser offenen Quelle, mit Parametern von 3 Milliarden, 7 Milliarden und 72 Milliarden. Dieses Repo enthält das kommandoangepasste 72B Qwen2.5-VL Modelle.
Modell Ensemble:
https://www.modelscope.cn/collections/Qwen25-VL-58fbb5d31f1d47
Erfahrung im Modellieren:
https://chat.qwenlm.ai/
Tech-Blog:
https://qwenlm.github.io/blog/qwen2.5-vl/
Code Adresse:
https://github.com/QwenLM/Qwen2.5-VL
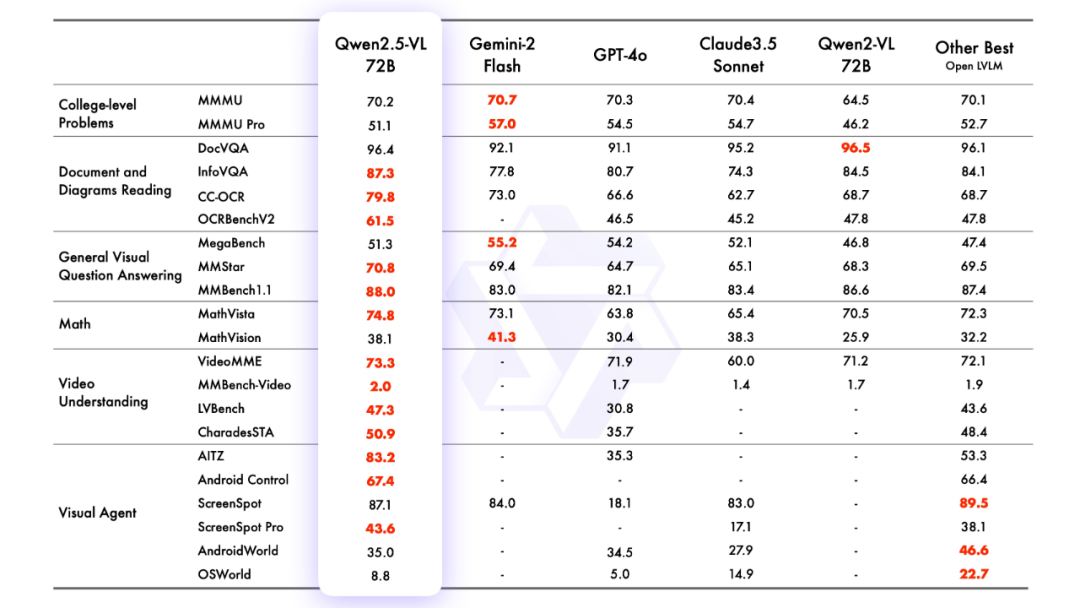
2.Modellierungseffekt
Modellierungsbewertung
Herr José María González
3.modellhafte Argumentation
Rechnen mit Transformatoren
Der Code für Qwen2.5-VL ist in den neuesten Transformatoren enthalten, und es wird empfohlen, den Quellcode mit dem Befehl zu erstellen:
pip install git+https://github.com/huggingface/transformersEs wird ein Toolkit bereitgestellt, das die Arbeit mit verschiedenen Arten von visuellen Eingaben erleichtert, so wie Sie es auch mit einer API tun würden. Dazu gehören base64, URLs und verschachtelte Bilder und Videos. Es kann mit dem folgenden Befehl installiert werden:
pip install qwen-vl-utils[decord]==0.0.8Überlegungen zum Code:
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
from modelscope import snapshot_download
# Download and load the model
model_dir = snapshot_download("Qwen/Qwen2.5-VL-3B-Instruct")
# Default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_dir, torch_dtype="auto", device_map="auto"
)
# Optional: Enable flash_attention_2 for better acceleration and memory saving
# model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-VL-3B-Instruct",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# Load the default processor
processor = AutoProcessor.from_pretrained(model_dir)
# Optional: Set custom min and max pixels for visual token range
# min_pixels = 256 * 28 * 28
# max_pixels = 1280 * 28 * 28
# processor = AutoProcessor.from_pretrained(
# "Qwen/Qwen2.5-VL-3B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels
# )
# Define input messages
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Prepare inputs for inference
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generate output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
# Print the generated output
print(output_text)
Direkter Aufruf über die Magic Hitch API-Inferenz
Die API-Inferenz der Magic Match-Plattform ist auch die erste, die Unterstützung für die Qwen2.5-VL-Modellreihe bietet. Benutzer von Magic Match können sie direkt über API-Aufrufe nutzen. Die spezifische Art der Nutzung von API-Inference ist auf der Modellseite zu finden (z.B. https://www.modelscope.cn/models/Qwen/Qwen2.5-VL-72B-Instruct):

Oder lesen Sie die Dokumentation zur API-Inferenz:
https://www.modelscope.cn/docs/model-service/API-Inference/intro
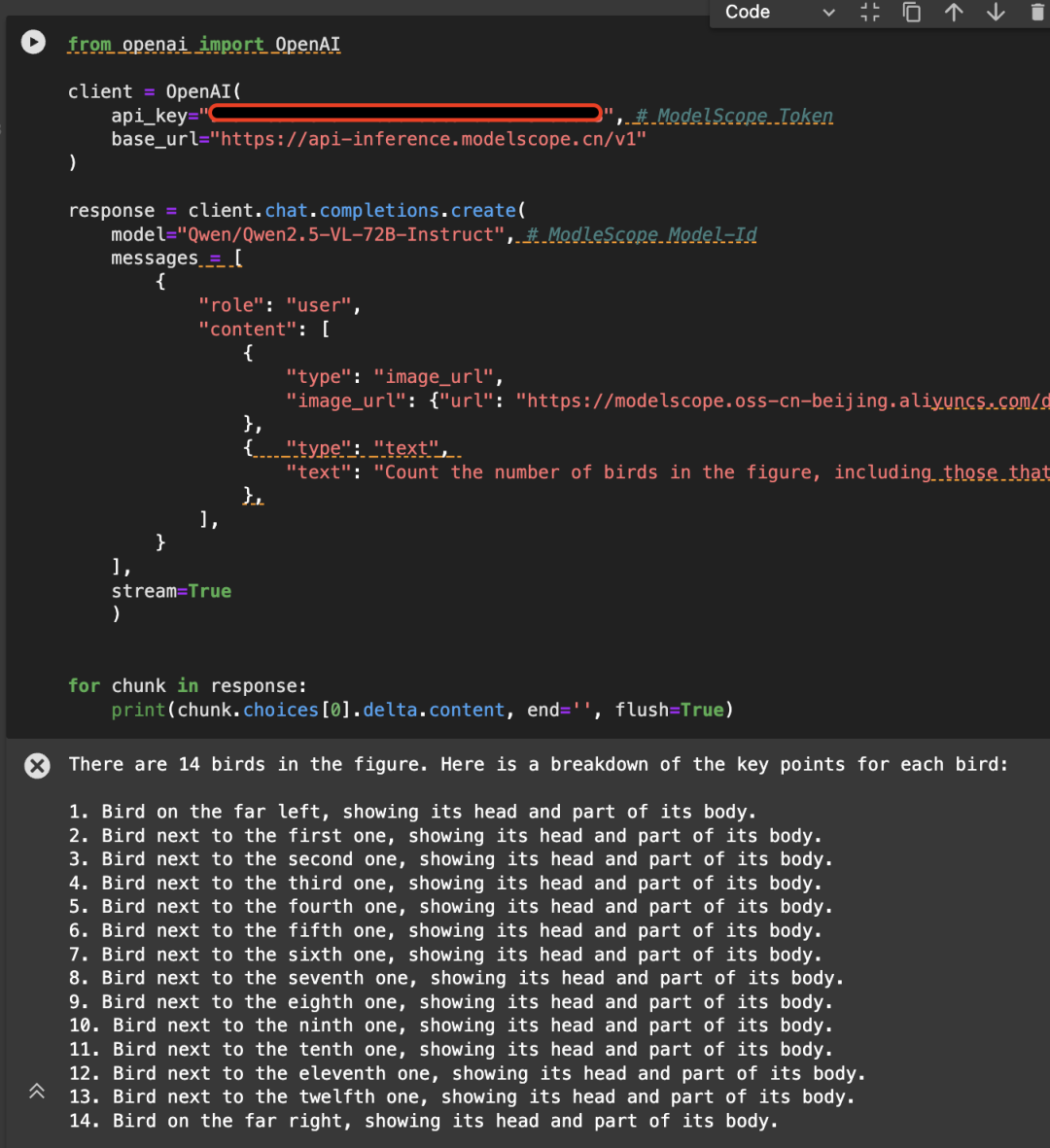
Hier ist ein Beispiel für das folgende Bild, das die API unter Verwendung des Qwen/Qwen2.5-VL-72B-Instruct-Modells aufruft:

from openai import OpenAI
# Initialize the OpenAI client
client = OpenAI(
api_key="<MODELSCOPE_SDK_TOKEN>", # ModelScope Token
base_url="https://api-inference.modelscope.cn/v1"
)
# Create a chat completion request
response = client.chat.completions.create(
model="Qwen/Qwen2.5-VL-72B-Instruct", # ModelScope Model-Id
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://modelscope.oss-cn-beijing.aliyuncs.com/demo/images/bird-vl.jpg"
}
},
{
"type": "text",
"text": (
"Count the number of birds in the figure, including those that "
"are only showing their heads. To ensure accuracy, first detect "
"their key points, then give the total number."
)
},
],
}
],
stream=True
)
# Stream the response
for chunk in response:
print(chunk.choices[0].delta.content, end='', flush=True)
4. die Feinabstimmung des Modells
Wir stellen die Verwendung von ms-swift auf Qwen/Qwen2.5-VL-7B-Instruct Feinabstimmung. ms-swift ist die magische Fahrt Gemeinschaft offiziell von der großen Modell und multi-modale große Modell Feinabstimmung Bereitstellung Framework zur Verfügung gestellt. ms-swift Open-Source-Adresse:
https://github.com/modelscope/ms-swift
Hier werden wir lauffähige Feinabstimmungsdemos zeigen und das Format des selbst definierten Datensatzes angeben.
Stellen Sie sicher, dass Ihre Umgebung bereit ist, bevor Sie mit der Feinabstimmung beginnen.
git clone https://github.com/modelscope/ms-swift.git cd ms-swift pip install -e .
Das Skript für die OCR-Feinabstimmung von Bildern sieht folgendermaßen aus:
MAX_PIXELS=1003520 \
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model Qwen/Qwen2.5-VL-7B-Instruct \
--dataset AI-ModelScope/LaTeX_OCR:human_handwrite#20000 \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4
Training der Videospeicherressourcen:

Das Skript für die Video-Feinabstimmung finden Sie unten:
# VIDEO_MAX_PIXELS等参数含义可以查看:
# https://swift.readthedocs.io/zh-cn/latest/Instruction/%E5%91%BD%E4%BB%A4%E8%A1%8C%E5%8F%82%E6%95%B0.html#id18
nproc_per_node=2
CUDA_VISIBLE_DEVICES=0,1 \
NPROC_PER_NODE=$nproc_per_node \
VIDEO_MAX_PIXELS=100352 \
FPS_MAX_FRAMES=24 \
swift sft \
--model Qwen/Qwen2.5-VL-7B-Instruct \
--dataset swift/VideoChatGPT:all \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps $(expr 16 / $nproc_per_node) \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--deepspeed zero2
Training der Videospeicherressourcen:

Das Format des benutzerdefinierten Datensatzes ist wie folgt (das Systemfeld ist optional), geben Sie einfach `--dataset ` an:
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "浙江的省会在杭州。"}]}
{"messages": [{"role": "user", "content": "<image><image>两张图片有什么区别"}, {"role": "assistant", "content": "前一张是小猫,后一张是小狗"}], "images": ["/xxx/x.jpg", "xxx/x.png"]}
{"messages": [{"role": "system", "content": "你是个有用无害的助手"}, {"role": "user", "content": "<video>视频中是什么"}, {"role": "assistant", "content": "视频中是一只小狗在草地上奔跑"}], "videos": ["/xxx/x.mp4"]}
Das Skript für die Feinabstimmung der Erdungsaufgabe sieht folgendermaßen aus:
CUDA_VISIBLE_DEVICES=0 \
MAX_PIXELS=1003520 \
swift sft \
--model Qwen/Qwen2.5-VL-7B-Instruct \
--dataset 'AI-ModelScope/coco#20000' \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 16 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--dataset_num_proc 4
Training der Videospeicherressourcen:

Das Format des benutzerdefinierten Datensatzes für die Erdungsaufgabe ist wie folgt:
{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "<image>描述图像"}, {"role": "assistant", "content": "<ref-object><bbox>和<ref-object><bbox>正在沙滩上玩耍"}], "images": ["/xxx/x.jpg"], "objects": {"ref": ["一只狗", "一个女人"], "bbox": [[331.5, 761.4, 853.5, 1594.8], [676.5, 685.8, 1099.5, 1427.4]]}}
{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "<image>找到图像中的<ref-object>"}, {"role": "assistant", "content": "<bbox><bbox>"}], "images": ["/xxx/x.jpg"], "objects": {"ref": ["羊"], "bbox": [[90.9, 160.8, 135, 212.8], [360.9, 480.8, 495, 532.8]]}}
Sobald das Training abgeschlossen ist, wird die Validierungsmenge aus dem Training mit dem folgenden Befehl abgeleitet.
Hier muss `--adapters` durch den letzten vom Training erzeugten Checkpoint-Ordner ersetzt werden. Da der Ordner "adapters" die Parameterdateien für das Training enthält, ist es nicht notwendig, zusätzlich "--model" anzugeben:
CUDA_VISIBLE_DEVICES=0swift infer--adapters output/vx-xxx/checkpoint-xxx--stream false--max_batch_size 1--load_data_args true--max_new_tokens 2048
Schieben Sie das Modell in ModelScope:
CUDA_VISIBLE_DEVICES=0swift export--adapters output/vx-xxx/checkpoint-xxx--push_to_hub true--hub_model_id '<your-model-id>'--hub_token '<your-sdk-token>'
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel




Keine Kommentare...