
Qwen2.5-1M: Ein Open Source Qwen Modell mit Unterstützung für 1 Million Token-Kontexte

1. einleitung
Vor zwei Monaten hat das Qwen-Team Qwen2.5-Turbo aktualisiert, um Kontextlängen von bis zu einer Million Token zu unterstützen. Heute hat Qwen offiziell das Open-Source-Modell Qwen2.5-1M und die entsprechende Unterstützung für das Inferenz-Framework veröffentlicht. Hier sind die Highlights des Releases:
Open-Source-Modelle: Zwei neue Open-Source-Modelle wurden veröffentlicht, und zwar Qwen2.5-7B-Instruct-1M im Gesang antworten Qwen2.5-14B-Instruct-1MDies ist das erste Mal, dass Qwen den Kontext des quelloffenen Qwen-Modells auf eine Länge von 1M erweitert hat.
Begründungsrahmen: Um Entwicklern zu helfen, die Qwen2.5-1M-Modellfamilie effizienter einzusetzen, hat das Qwen-Team das Qwen 2.5-1M-Modell auf der Grundlage der vLLM Inferenzrahmens mit einem integrierten Ansatz für spärliche Aufmerksamkeit, der den Rahmen bei der Verarbeitung von 1M markierten Eingaben um 3x bis 7x.
Technischer Bericht: Das Qwen-Team erläuterte auch die technischen Details der Qwen2.5-1M-Serie, einschließlich der Konzeption des Trainings- und Inferenz-Frameworks und der Ergebnisse der Ablationsexperimente.
Modell Link:https://www.modelscope.cn/collections/Qwen25-1M-d6cf9fd33f0a40
Technischer Bericht:https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-1M/Qwen2_5_1M_Technical_Report.pdf
Links erleben:https://modelscope.cn/studios/Qwen/Qwen2.5-1M-Demo
2. die Leistung des Modells
Betrachten wir zunächst die Leistung der Qwen2.5-1M-Modellfamilie bei langen Kontextaufgaben und kurzen Textaufgaben.
lange Kontextaufgabe
Mit einer Kontextlänge von 1 Million Wertmarken In der Aufgabe "Passkey Retrieval" konnten die Modelle der Qwen2.5-1M-Familie verborgene Informationen aus Dokumenten mit einer Länge von 1M korrekt abrufen, mit nur wenigen Fehlern im 7B-Modell.
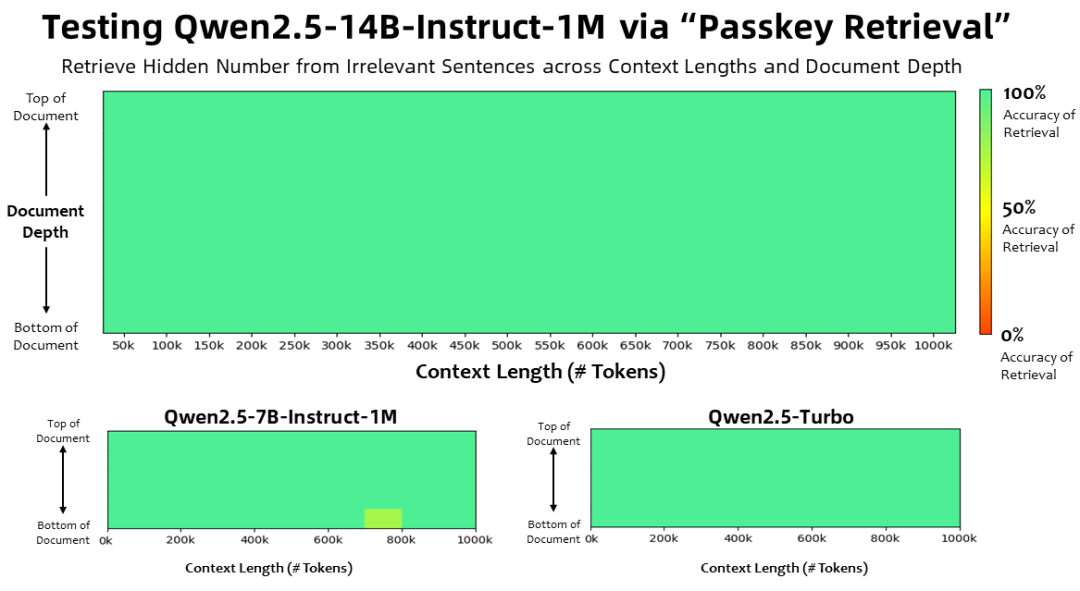
Für komplexere Aufgaben zum Verstehen langer Kontexte wurden die Testsätze RULER, LV-Eval und LongbenchChat ausgewählt.
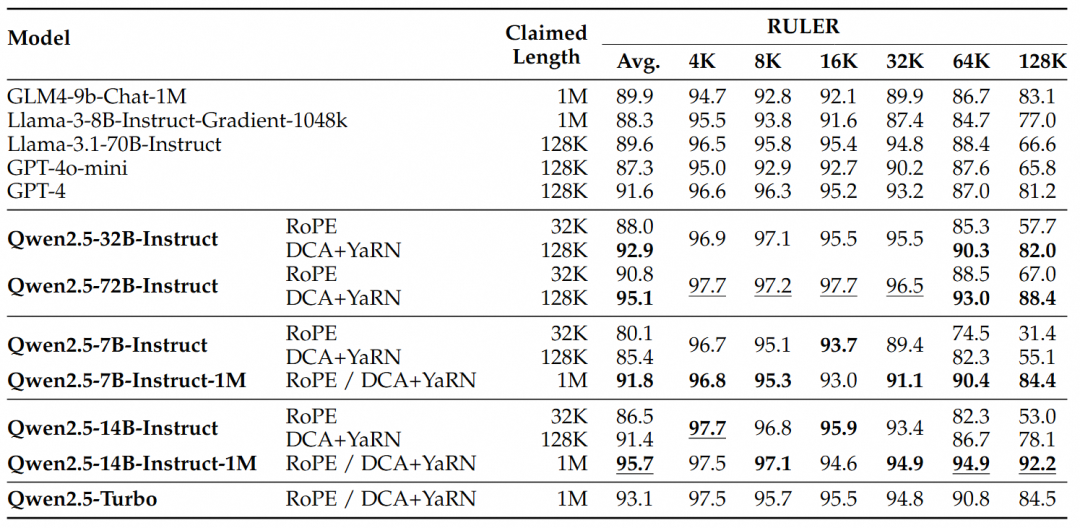
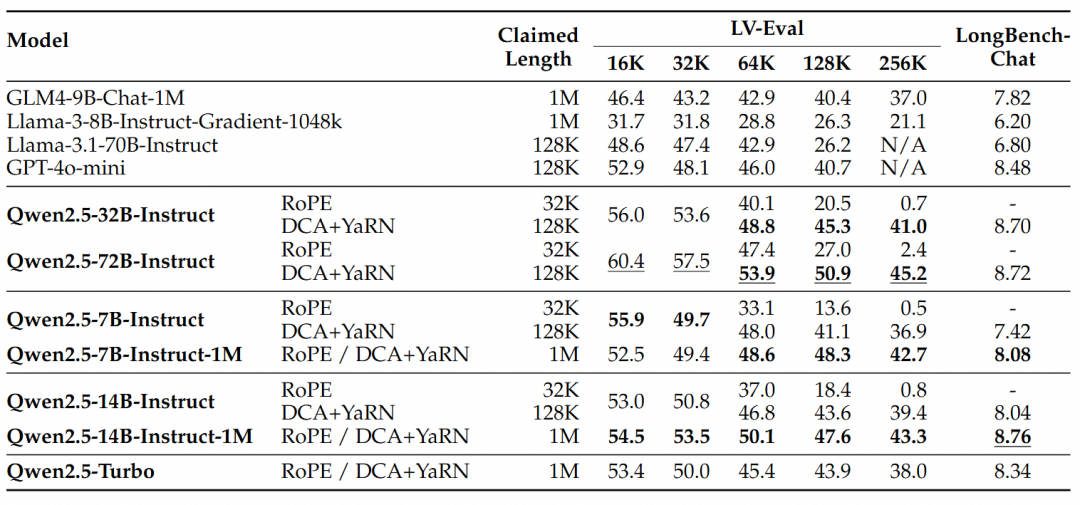
Aus diesen Ergebnissen lassen sich die folgenden wichtigen Schlussfolgerungen ziehen:
- Deutlich bessere Leistung als die 128K-Version:Die Qwen2.5-1M-Modellfamilie übertrifft die vorherige 128K-Version bei den meisten Aufgaben mit langem Kontext erheblich, insbesondere bei Aufgaben mit einer Länge von mehr als 64K.
- Die Leistungsvorteile liegen auf der Hand:Das Modell Qwen2.5-14B-Instruct-1M schlägt nicht nur Qwen2.5-Turbo, sondern übertrifft auch durchgängig GPT-4o-mini in mehreren Datensätzen und ist damit das Open-Source-Modell der Wahl für Aufgaben mit langem Kontext.
kurze fortlaufende Aufgabe
Neben der Leistung bei langen Sequenzen ist die Leistung der Modelle bei kurzen Sequenzen ebenso wichtig. Die Modelle der Qwen2.5-1M-Serie und die früheren 128K-Versionen wurden in weit verbreiteten akademischen Benchmarks verglichen, wobei GPT-4o-mini zum Vergleich hinzugefügt wurde. 
Sie kann gefunden werden:
- Die Leistung von Qwen2.5-7B-Instruct-1M und Qwen2.5-14B-Instruct-1M bei der Kurztextaufgabe ist mit der ihrer 128K-Versionen vergleichbar, so dass sichergestellt ist, dass die grundlegenden Fähigkeiten nicht durch das Hinzufügen von Fähigkeiten zur Verarbeitung langer Sequenzen beeinträchtigt wurden.
- Im Vergleich zu GPT-4o-mini erreichen Qwen2.5-14B-Instruct-1M und Qwen2.5-Turbo eine ähnliche Leistung bei der Kurztextaufgabe, während die Kontextlänge achtmal so lang ist wie bei GPT-4o-mini.
3) Schlüsseltechnologien
Langes Kontexttraining
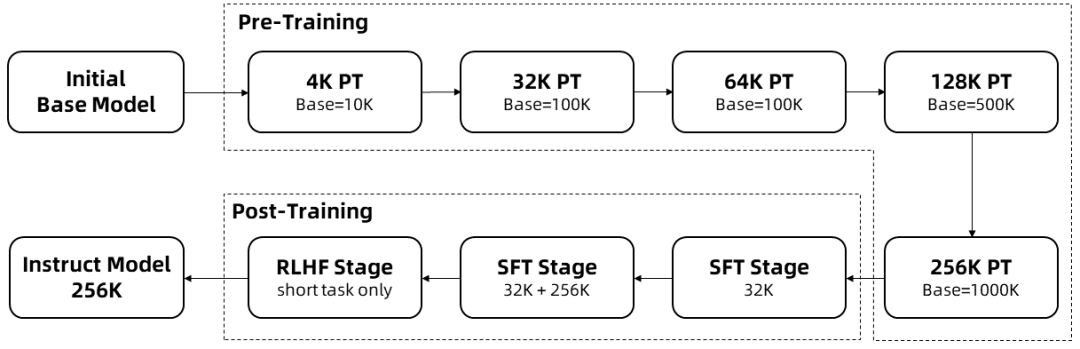
Da das Training langer Sequenzen sehr rechenaufwändig ist, wurde die Kontextlänge von Qwen2.5-1M in mehreren Schritten von 4K auf 256K erweitert:
Ausgehend von einem Zwischen-Checkpoint des vortrainierten Qwen 2.5 beträgt die Kontextlänge an diesem Punkt 4K.
Während der VorschulungsphaseAußerdem wurde die Kontextlänge schrittweise von 4K auf 256K erhöht, während die RoPE-Basisfrequenz nach dem Schema der angepassten Basisfrequenz von 10.000 auf 10.000.000 erhöht wurde.
In der Phase der Feinabstimmung der Überwachungin zwei Stufen, um die Leistung bei kurzen Sequenzen zu erhalten:
Phase I: Die Feinabstimmung erfolgt nur bei kurzen Befehlen (bis zu 32K Länge), wobei dieselben Daten und dieselbe Anzahl von Schritten verwendet werden wie in der 128K-Version von Qwen2.5.
Phase II: Eine Mischung aus kurzen (bis zu 32K) und langen (bis zu 256K) Befehlen wird implementiert, um die Leistung langer Aufgaben zu verbessern und gleichzeitig die Qualität kurzer Aufgaben zu erhalten.
In der intensiven Lernphasedie das Modell auf kurzen Texten (bis zu 8K Token) trainiert. Wir haben herausgefunden, dass selbst beim Training auf kurzen Textbüchern die Steigerung der vom Menschen bevorzugten Ausrichtung gut auf lange Kontextaufgaben übertragbar ist. Mit dem oben beschriebenen Training erhalten wir ein Instruct-Modell, das Sequenzen mit einer Länge von bis zu 256K Token verarbeiten kann.
Mit dem oben beschriebenen Training erhält man ein Feinabstimmungsmodell für Befehle mit 256K Kontextlänge.
Extrapolation der Länge
Im obigen Trainingsverfahren beträgt die Kontextlänge des Modells nur 256K Token. Um es auf 1M Token zu skalieren, wurde eine Längenextrapolationstechnik verwendet.
Derzeit führen groß angelegte Sprachmodelle, die auf rotatorischer Positionskodierung basieren, zu einer Leistungsverschlechterung bei Aufgaben mit langem Kontext, was hauptsächlich auf den großen relativen Positionsabstand zwischen Abfrage und Schlüssel zurückzuführen ist, der während des Trainingsprozesses bei der Berechnung der Aufmerksamkeitsgewichte nicht gesehen wird. Um dieses Problem zu lösen, verwendet Qwen2.5-1M den Dual Chunk Attention (DCA)-Ansatz, der diese Herausforderung löst, indem er die übermäßig großen relativen Positionen auf kleinere Werte umrechnet.
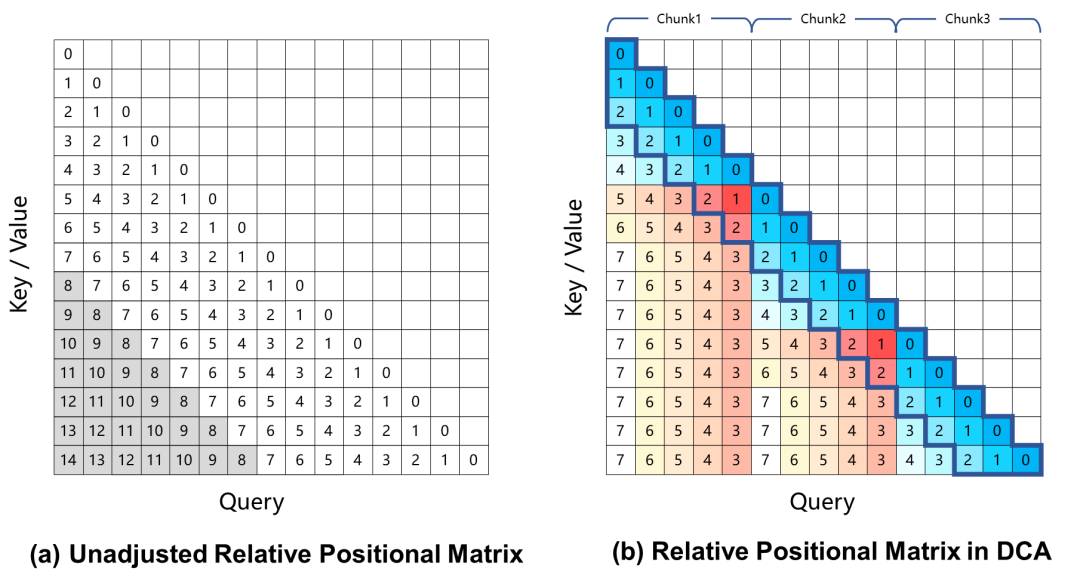
Das Modell Qwen2.5-1M und die vorherige 128K-Version wurden mit und ohne die Methode der Längenextrapolation bewertet.
Die Ergebnisse zeigen, dass selbst Modelle, die nur auf 32K Token trainiert wurden, wie z.B. Qwen2.5-7B-Instruct, nicht in der Lage sind, mit dem 1M-Token-Kontext des Passkey Abruf Die Aufgabe erreicht außerdem eine nahezu perfekte Genauigkeit. Dies zeigt die Leistungsfähigkeit von DCA, die Länge der unterstützten Kontexte ohne zusätzliches Training erheblich zu erweitern.
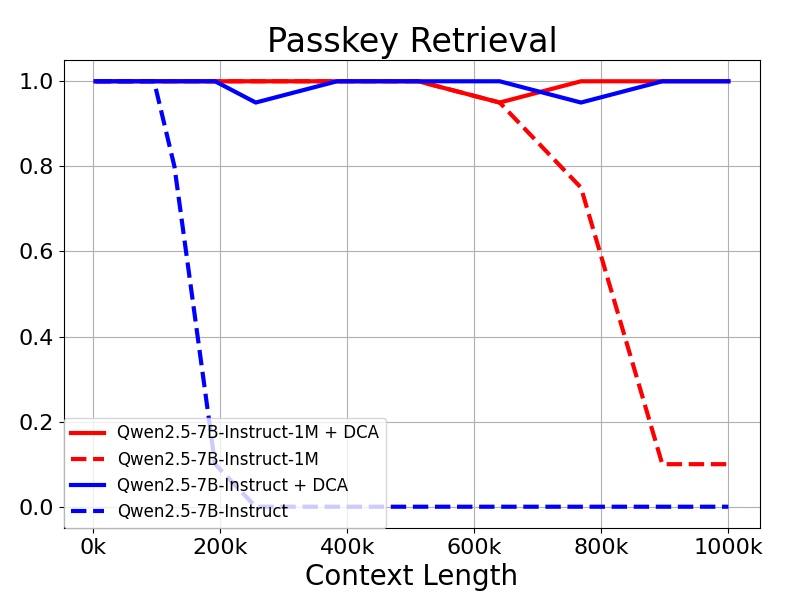
Mechanismus der spärlichen Aufmerksamkeit (in der Teilchenphysik)
Bei Sprachmodellen mit langem Kontext ist die Geschwindigkeit der Inferenz entscheidend für die Benutzerfreundlichkeit. Um die Prä-Populationsphase zu beschleunigen, hat das Forschungsteam einen auf MInference basierenden Mechanismus für spärliche Aufmerksamkeit eingeführt. Darüber hinaus werden mehrere Verbesserungen vorgeschlagen:
- Chunked Prefill: Wenn das Modell direkt zur Verarbeitung von Sequenzen mit einer Länge von bis zu 1 Million verwendet wird, verursachen die Aktivierungsgewichte der MLP-Schicht einen enormen Speicher-Overhead, im Fall von Qwen2-5-7B bis zu 71 GB. Am Beispiel von Qwen2.5-7B beträgt dieser Teil des Overheads sogar 71 GB. Durch die Anpassung von Chunked Prefill mit Sparse Attention kann die Eingabesequenz in 32768 Längen gechunked und einzeln vorausgefüllt werden, und die Speichernutzung der Aktivierungsgewichte auf der MLP-Schicht kann um 96,71 TP3T reduziert werden, was den Speicherbedarf des Geräts erheblich verringert.
- Integriertes Längenextrapolationsschema: Wir integrieren ein DCA-basiertes Längenextrapolationsschema in den Sparse-Attention-Mechanismus, der es unserem Inferenzrahmen ermöglicht, sowohl eine höhere Inferenzeffizienz als auch eine höhere Genauigkeit für lange Sequenzaufgaben zu erzielen.
- Optimierung der Sparsamkeit: Die ursprüngliche MInference-Methode erfordert eine Offline-Suche, um die optimale Sparsamkeitskonfiguration für jeden Aufmerksamkeitskopf zu bestimmen. Diese Suche wird in der Regel bei kurzen Sequenzen durchgeführt und funktioniert bei längeren Sequenzen aufgrund des großen Speicherbedarfs der vollständigen Aufmerksamkeitsgewichte nicht unbedingt gut. Wir schlagen eine Methode vor, mit der die Sparsifizierungskonfiguration für Sequenzen von 1 Million Länge optimiert werden kann, wodurch der Genauigkeitsverlust aufgrund der spärlichen Aufmerksamkeit erheblich verringert wird.
- Weitere Optimierungen: Wir haben weitere Optimierungen eingeführt, wie z. B. die Optimierung der Operator-Effizienz und das dynamische Chunking der Pipeline-Parallelität, um das volle Potenzial des gesamten Frameworks auszuschöpfen.
Mit diesen Verbesserungen ist der Inferenzrahmen in der Lage, die Anzahl der 1M Token Die Geschwindigkeit der Vorpopulation von Sequenzen der Länge wurde von 3,2-fach auf 6,7-fach erhöht.
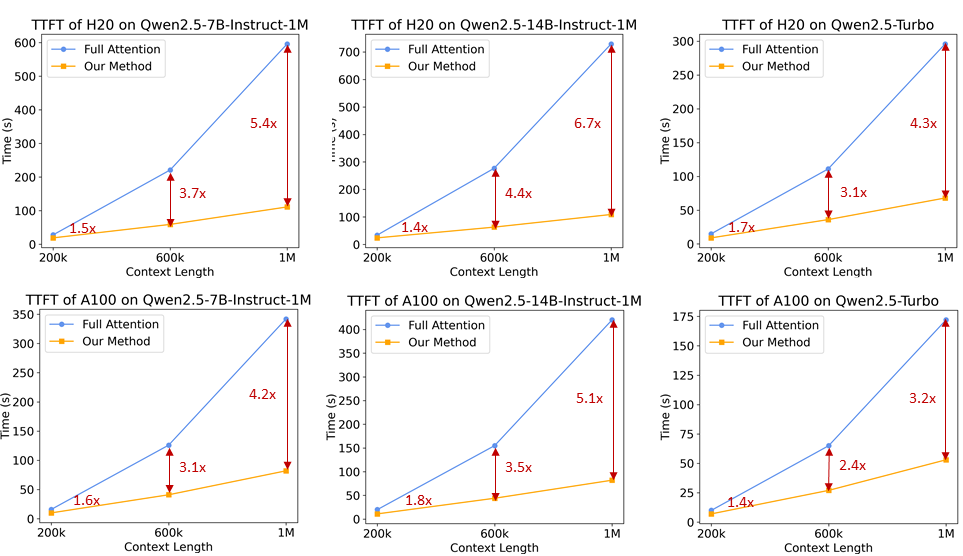
4. modellhafter Einsatz
Vorbereitung des Systems
Für eine optimale Leistung wird empfohlen, einen Grafikprozessor mit einer Ampere- oder Hopper-Architektur zu verwenden, der optimierte Kerne unterstützt.
Bitte stellen Sie sicher, dass die folgenden Anforderungen erfüllt sind:
- CUDA-Version: 12.1 oder 12.3
- Python-Version: >=3.9 und <=3.12
Speicherbedarf für die Verarbeitung von Sequenzen der Länge 1M:
- Qwen2.5-7B-Instruct-1M: Erfordert mindestens 120 GB Videospeicher (Multi-GPU-Summe).
- Qwen2.5-14B-Instruct-1M: Erfordert mindestens 320 GB Videospeicher (Multi-GPU-Summe).
Wenn der GPU-Speicher diese Anforderungen nicht erfüllt, können Sie Qwen2.5-1M trotzdem für kürzere Aufgaben verwenden.
Installieren von Abhängigkeiten
Im Moment müssen Sie das vLLM-Repository aus einem benutzerdefinierten Zweig klonen und es manuell installieren. Das Forschungsteam arbeitet daran, diesen Zweig in das vLLM-Projekt einzubinden.
git clone -b dev/dual-chunk-attn git@github.com:QwenLM/vllm.git cd vllm pip install -e . -v
Starten eines OpenAI-kompatiblen API-Dienstes
Gibt an, dass das Modell von ModelScope heruntergeladen werden soll
export VLLM_USE_MODELSCOPE=True
Veröffentlichung von OpenAI-kompatiblen API-Diensten
vllm serve Qwen/Qwen2.5-7B-Instruct-1M \ --tensor-parallel-size 4 \ --max-model-len 1010000 \ --enable-chunked-prefill --max-num-batched-tokens 131072 \ --enforce-eager \ --max-num-seqs 1
Parameter Beschreibung:
--tensor-parallel-size- Die Einstellung ist die Anzahl der von Ihnen verwendeten GPUs. 7B-Modelle unterstützen bis zu 4 GPUs und 14B-Modelle unterstützen bis zu 8 GPUs.
--max-model-len- Legt die maximale Länge der Eingabesequenz fest. Verringern Sie diesen Wert, wenn Sie Probleme mit der Speicherkapazität bekommen.
--max-num-batched-tokens- Legt die Blockgröße des Chunked Prefill fest. Ein kleinerer Wert verringert die Speichernutzung bei der Aktivierung, kann aber die Argumentation verlangsamen.
- Der empfohlene Wert für eine optimale Leistung ist 131072.
--max-num-seqs- Begrenzen Sie die Anzahl der gleichzeitig verarbeiteten Sequenzen.
Interaktion mit Modellen
Die folgenden Methoden können zur Interaktion mit dem bereitgestellten Modell verwendet werden:
Option 1.
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-7B-Instruct-1M",
"messages": [
{
"role": "user",
"content": "Tell me something about large language models."
}
],
"temperature": 0.7,
"top_p": 0.8,
"repetition_penalty": 1.05,
"max_tokens": 512
}'
Option 2: Python verwenden
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
prompt = (
"""There is an important info hidden inside a lot of irrelevant text.
Find it and memorize them. I will quiz you about the important information there.\n\n
The pass key is 28884. Remember it. 28884 is the pass key.\n"""
+ "The grass is green. The sky is blue. The sun is yellow. Here we go. There and back again. " * 800
+ "\nWhat is the pass key?"
)
# The prompt is 20k long. You can try a longer prompt by replacing 800 with 40000.
chat_response = client.chat.completions.create(
model="Qwen/Qwen2.5-7B-Instruct-1M",
messages=[
{"role": "user", "content": prompt},
],
temperature=0.7,
top_p=0.8,
max_tokens=512,
extra_body={
"repetition_penalty": 1.05,
},
)
print("Chat response:", chat_response)
Sie können auch andere Frameworks wie Qwen-Agent untersuchen, um Modelle zum Lesen von PDF-Dateien usw. zu befähigen.
5. verwenden Sie die Magic Hitch API-Inferenz, um direkt die
Die API-Inferenz der Magic Match Plattform bietet erstmals auch Unterstützung für die Modelle Qwen2.5-7B-Instruct-1M und Qwen2.5-14B-Instruct-1M. Nutzer von Magic Hitch können das Modell direkt über API-Aufrufe nutzen. Die spezifische Verwendung von API-Inferenzen kann auf der Modellseite beschrieben werden (z.B. https://modelscope.cn/models/Qwen/Qwen2.5-14B-Instruct-1M ):

Oder siehe die API-Inferenz-Dokumentation: https://www.modelscope.cn/docs/model-service/API-Inference/intro
Vielen Dank an AliCloud Hundred Refinement Platform für die Bereitstellung von arithmetischer Unterstützung hinter den Kulissen.
Verwendung von Ollama und Llamafile
Um Ihnen die lokale Nutzung zu erleichtern, stellt Magic Hitch die GGUF-Version und die Llamafile-Version des Qwen2.5-7B-Instruct-1M-Modells zur Verfügung. Es kann vom Ollama-Framework aufgerufen werden, oder Sie können llamafile direkt aufrufen.
1. ollama-Ruf
Richten Sie zunächst ollama unter enable ein:
ollama serve
Sie können dann das GGUF-Modell direkt auf dem Magic Hitch mit dem Befehl ollama run ausführen:
ollama run modelscope.cn/modelscope/Qwen2.5-7B-Instruct-1M-GGUFLaufergebnisse:
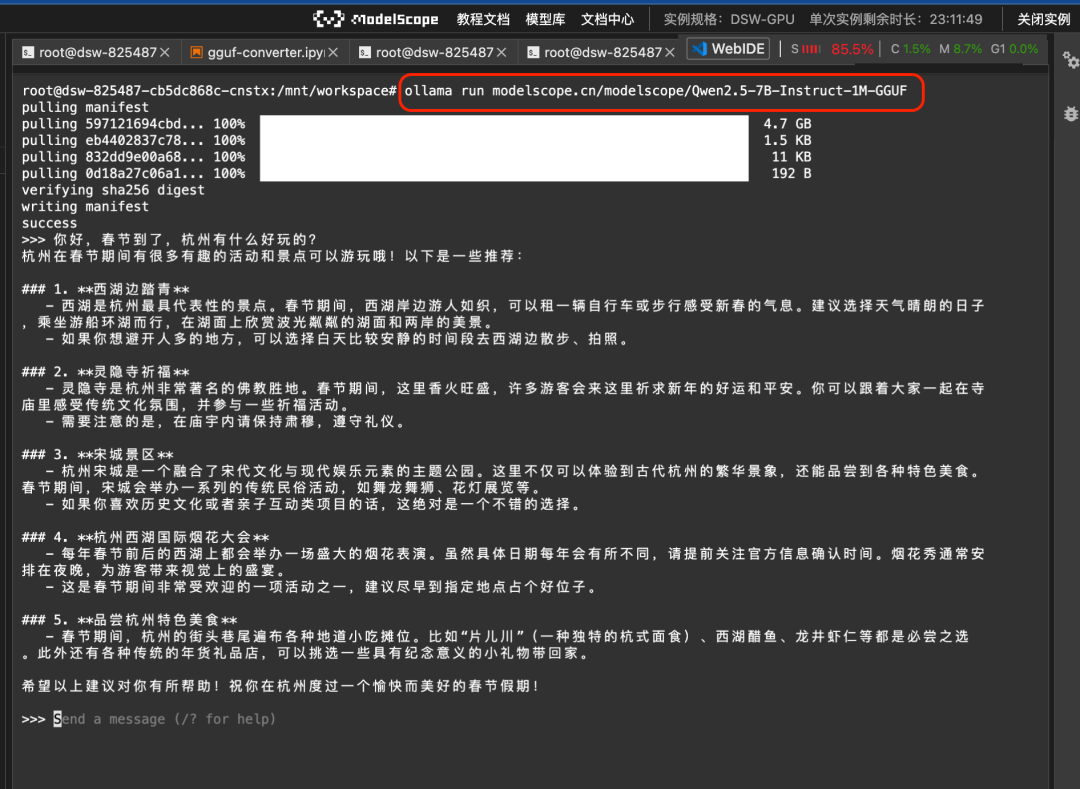
2. llamafile Modell direkt hochziehen
Llamafile Bietet eine Lösung, bei der das große Modell und die Laufzeitumgebung in einer einzigen ausführbaren Datei gekapselt sind. Durch die Integration von Magic Ride Kommandozeile und llamafile können Sie das große Modell wirklich mit einem Klick in verschiedenen Betriebssystemumgebungen wie Linux/Mac/Windows ausführen:
modelscope llamafile --model Qwen-Llamafile/Qwen2.5-7B-Instruct-1M-llamafileLaufergebnisse:
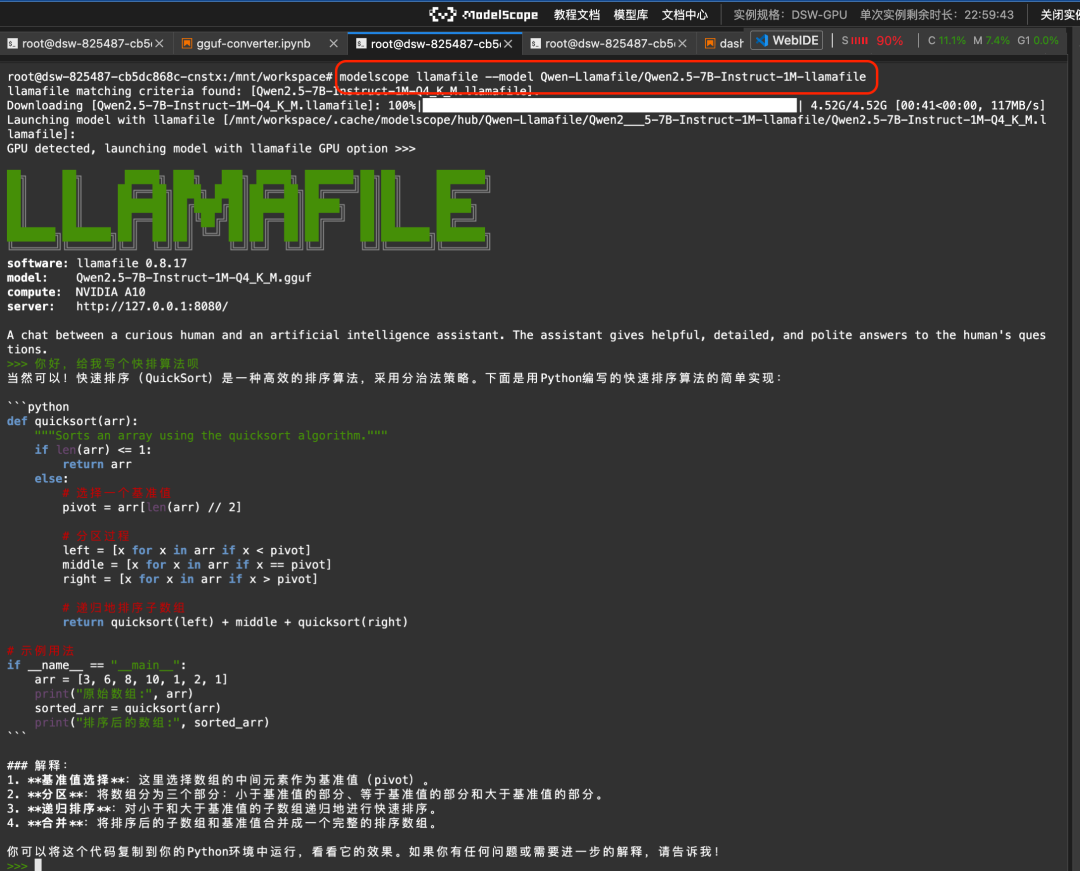
Weitere Unterlagen finden Sie unter https://www.modelscope.cn/docs/models/advanced-usage/llamafile.
6. die Feinabstimmung des Modells
Hier stellen wir die Feinabstimmung von Qwen/Qwen2.5-7B-Instruct-1M mit ms-swift vor.
Bevor Sie mit der Feinabstimmung beginnen, sollten Sie sicherstellen, dass Ihre Umgebung ordnungsgemäß installiert ist:
# 安装ms-swift git clone https://github.com/modelscope/ms-swift.git cd ms-swift pip install -e .
Wir bieten lauffähige Demos für die Feinabstimmung und Stile für benutzerdefinierte Datensätze, und die Skripte für die Feinabstimmung sind wie folgt:
CUDA_VISIBLE_DEVICES=0
swift sft \
--model Qwen/Qwen2.5-7B-Instruct-1M \
--train_type lora \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \
'AI-ModelScope/alpaca-gpt4-data-en#500' \
'swift/self-cognition#500' \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--model_author swift \
--model_name swift-robot
Nutzung des Videospeichers beim Training:

Benutzerdefiniertes Datensatzformat: (geben Sie es einfach direkt mit `--dataset ` an)
{"messages": [{"role": "user", "content": "<query>"}, {"role": "assistant", "content": "<response>"}, {"role": "user", "content": "<query2>"}, {"role": "assistant", "content": "<response2>"}]}
Begründungsschrift:
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--max_new_tokens 2048
Schieben Sie das Modell in ModelScope:
CUDA_VISIBLE_DEVICES=0 swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '' \
--hub_token ''
7. wie geht es weiter?
Obwohl die Qwen2.5-1M-Familie hervorragende Open-Source-Optionen für die Verarbeitung langer Sequenzen bietet, ist sich das Forschungsteam darüber im Klaren, dass die Modelle für lange Kontexte noch viel Raum für Verbesserungen haben. Unser Ziel ist es, Modelle zu entwickeln, die sich sowohl bei langen als auch bei kurzen Aufgaben auszeichnen, um sicherzustellen, dass sie in realen Anwendungsszenarien wirklich nützlich sind. Zu diesem Zweck arbeitet das Team an effizienteren Trainingsmethoden, Modellarchitekturen und Schlussfolgerungsansätzen, um einen effizienten Einsatz und eine optimale Leistung dieser Modelle auch in ressourcenbeschränkten Umgebungen zu ermöglichen. Das Team ist zuversichtlich, dass diese Bemühungen neue Möglichkeiten für lange Kontextmodelle eröffnen, ihren Anwendungsbereich drastisch erweitern und die Grenzen des Feldes weiter verschieben werden - bleiben Sie also dran!
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...