
Prompt Advanced Tips: Präzise Kontrolle der LLM-Ausgabe und Definition der Ausführungslogik mit Pseudo-Code
Wie wir alle wissen, müssen wir, wenn wir ein großes Sprachmodell eine Aufgabe ausführen lassen wollen, eine Eingabeaufforderung (Prompt) eingeben, um die Ausführung zu steuern, die mit natürlicher Sprache beschrieben wird. Einfache Aufgaben können mit natürlicher Sprache klar beschrieben werden, wie z. B.: "Bitte übersetzen Sie das Folgende ins vereinfachte Chinesisch:", "Bitte erstellen Sie eine Zusammenfassung des Folgenden:" und so weiter.
Wenn wir jedoch auf komplexe Aufgaben stoßen, wie z. B. die Anforderung, dass das Modell ein bestimmtes JSON-Format generieren muss, oder wenn die Aufgabe mehrere Zweige hat, jeder Zweig mehrere Teilaufgaben ausführen muss und die Teilaufgaben miteinander verknüpft sind, dann sind natürlichsprachliche Beschreibungen nicht ausreichend.
Diskussionsthema
Hier sind zwei Fragen, die zum Nachdenken anregen sollen, bevor Sie weiter lesen:
- Es gibt mehrere lange Sätze, von denen jeder in kürzere Sätze von höchstens 80 Zeichen aufgeteilt und dann in ein JSON-Format ausgegeben werden muss, das die Entsprechung zwischen den langen und kurzen Sätzen klar beschreibt.
Zum Beispiel:
[
{
"long": "This is a long sentence that needs to be split into shorter sentences.",
"short": [
"This is a long sentence",
"that needs to be split",
"into shorter sentences."
]
},
{
"long": "Another long sentence that should be split into shorter sentences.",
"short": [
"Another long sentence",
"that should be split",
"into shorter sentences."
]
}
]
- Ein Originaltext mit Untertiteln, der nur Dialoginformationen enthält, aus denen Sie nun Kapitel und Sprecher extrahieren und die Dialoge nach Kapitel und Absatz auflisten müssen. Wenn es mehrere Sprecher gibt, muss jedem Dialog der jeweilige Sprecher vorangestellt werden, nicht aber, wenn derselbe Sprecher nacheinander spricht. (Dies ist eigentlich ein GPT, das ich selbst verwende, um Videoskripte zu organisieren. Zusammenstellung von Videoskripten GPT)
Beispiel Eingabe:
所以我要引用一下埃隆·马斯克的话,希望你不要介意。 我向你道歉。 但他并不认同这是一个保障隐私和安全的模型。 他将这种集成称为"令人毛骨悚然的间谍软件"。你对此有什么回应? 不在意? 那是他的观点。 显然,我不这么认为。 我们也不这么认为。 Mira,感谢你能和我们在一起。 我知道你可能稍微有点忙。 我有许多问题想向 Mira 提问,但我们只有 20 分钟。 所以我想先设定一下大家的期望。 我们会专注于一些主题, 包括一些近期的新闻和 Mira 作为首席技术官所负责的一些领域。 希望我们能深入探讨其中的一些话题。 我想我第一个问题是, 考虑到你现在极其忙碌, 以及新闻的攻击, 有些好有些坏, 你大约六年前加入了这个公司。 那时,它是一个截然不同的组织。 你相对低调,不太为人知晓。 你是否怀念那些能够全神贯注工作的日子? 我想说,我们依旧全神贯注在工作中。 只不过工作的内容已经发展变化了,它不仅仅关乎研究。 也是因为,你知道,研究已经得到了很大的进展。 这也是关于我们如何以一种有益且安全的方式将这种技术引入到世界中所以,使命依然如一, 我们在研究上也已经取得了很多进展,工作领域也在不断扩大。 公众对此的关注度也很高, 这对于我们这些正在研究技术和开发产品的人来说可能会感到有些不同寻常。 但你要知道, 鉴于我们所做的事情的重要性,这种关注是非常必要的, 而且这是积极的。
Beispielhafte Ausgabe:
### 引言 **主持人**: 所以我要引用一下埃隆·马斯克的话,希望你不要介意。我向你道歉,但他并不认同这是一个保障隐私和安全的模型。他将这种集成称为"令人毛骨悚然的间谍软件"。你对此有什么回应? **Mira**: 那是他的观点。显然,我不这么认为。我们也不这么认为。 ### 欢迎与介绍 **主持人**: Mira,感谢你能和我们在一起。我知道你可能稍微有点忙。我有许多问题想向你提问,但我们只有 20 分钟。所以我想先设定一下大家的期望。我们会专注于一些主题,包括一些近期的新闻和你作为首席技术官所负责的一些领域。希望我们能深入探讨其中的一些话题。 ### 职业生涯回顾 **主持人**: 我想我第一个问题是,考虑到你现在极其忙碌,以及新闻的攻击,有些好有些坏,你大约六年前加入了这个公司。那时,它是一个截然不同的组织。你相对低调,不太为人知晓。你是否怀念那些能够全神贯注工作的日子? **Mira**: 我想说,我们依旧全神贯注在工作中。只不过工作的内容已经发展变化了,它不仅仅关乎研究。也是因为,研究已经得到了很大的进展。这也是关于我们如何以一种有益且安全的方式将这种技术引入到世界中。所以,使命依然如一,我们在研究上也已经取得了很多进展,工作领域也在不断扩大。公众对此的关注度也很高,这对于我们这些正在研究技术和开发产品的人来说可能会感到有些不同寻常。但你要知道,鉴于我们所做的事情的重要性,这种关注是非常必要的,而且这是积极的。
Die Essenz von Prompt
Vielleicht haben Sie im Internet viele Artikel darüber gelesen, wie man Prompt-Techniken schreibt, und viele Prompt-Vorlagen auswendig gelernt, aber was ist das Wesentliche an Prompt? Warum brauchen wir Prompt?
Prompt ist im Wesentlichen eine Steueranweisung an den LLM, die in natürlicher Sprache beschrieben ist und es dem LLM ermöglicht, unsere Anforderungen zu verstehen und dann die Eingaben in die gewünschten Ausgaben zu verwandeln.
Die häufig verwendete "few-shot"-Technik besteht zum Beispiel darin, den LLM unsere Anforderungen anhand von Beispielen verstehen zu lassen und sich dann auf die Beispiele zu beziehen, um unsere gewünschten Ergebnisse auszugeben. CoT (Chain of Thought) z.B. bedeutet, die Aufgabe künstlich zu zerlegen und den Ausführungsprozess zu begrenzen, so dass der LLM dem von uns spezifizierten Prozess und den Schritten folgen kann, ohne zu diffus zu sein oder Schlüsselschritte zu überspringen, und somit bessere Ergebnisse zu erzielen.
Es ist wie in der Schule: Wenn der Lehrer über mathematische Theoreme sprach, musste er uns Beispiele geben, anhand derer wir die Bedeutung der Theoreme verstehen konnten; wenn wir Experimente durchführten, musste er uns die Schritte der Experimente erklären, und selbst wenn wir die Prinzipien der Experimente nicht verstanden, aber die Experimente gemäß den Schritten durchführen konnten, konnten wir immer noch mehr oder weniger die gleichen Ergebnisse erzielen.
Woran liegt es, dass die Ergebnisse von Prompt manchmal nicht optimal sind?
Dies liegt daran, dass der LLM unsere Anforderungen nicht genau verstehen kann, was einerseits durch die Fähigkeit des LLM, Anweisungen zu verstehen und zu befolgen, und andererseits durch die Klarheit und Genauigkeit unserer Prompt-Beschreibung begrenzt ist.
Wie man die Ausgabe des LLM präzise steuert und seine Ausführungslogik mit Hilfe von Pseudocode definiert
Da Prompt im Wesentlichen eine Steueranweisung für den LLM ist, können wir Prompt schreiben, ohne uns auf traditionelle Beschreibungen in natürlicher Sprache zu beschränken, sondern können auch Pseudocode verwenden, um die Ausgabe des LLM genau zu steuern und seine Ausführungslogik zu definieren.
Was ist Pseudocode?
Pseudocode ist eine formale Beschreibungsmethode zur Beschreibung von Algorithmen, eine Art Beschreibungsmethode zwischen natürlicher Sprache und Programmiersprache zur Beschreibung von Algorithmusschritten und -prozessen. In verschiedenen Algorithmus-Büchern und -Aufsätzen sehen wir oft die Beschreibung von Pseudocode, auch wenn man nicht in eine Sprache einsteigen muss, sondern auch durch den Pseudocode den Ausführungsprozess des Algorithmus verstehen kann.
Wie gut versteht der LLM also Pseudocode? Tatsächlich ist das Verständnis des LLM für Pseudocode ziemlich stark. Der LLM wurde mit einer Menge Qualitätscode geschult und kann die Bedeutung von Pseudocode leicht verstehen.
Wie schreibt man Pseudocode Prompt?
Pseudocode ist Programmierern sehr vertraut, und auch Nicht-Programmierer können einfachen Pseudocode schreiben, indem sie sich einige Grundregeln merken. Ein paar Beispiele:
- Variablen, die zum Speichern von Daten verwendet werden, z. B. um Eingaben oder Zwischenergebnisse mit bestimmten Symbolen darzustellen
- Typ, zur Definition des Datentyps, z. B. Strings, Zahlen, Arrays usw.
- Funktion, die die Ausführungslogik für eine bestimmte Teilaufgabe definiert
- Kontrollfluss, der zur Steuerung des Ausführungsprozesses des Programms verwendet wird, wie Schleifen, bedingte Entscheidungen usw.
- if-else-Anweisung: Wenn Bedingung A erfüllt ist, wird Aufgabe A ausgeführt, andernfalls wird Aufgabe B ausgeführt.
- Eine for-Schleife, die für jedes Element im Array eine Aufgabe ausführt.
- while-Schleife, wenn die Bedingung A erfüllt ist, wird die Aufgabe B kontinuierlich ausgeführt.
Schreiben wir nun den Pseudocode Prompt, wobei wir die beiden vorherigen Reflexionsfragen als Beispiel verwenden.
Pseudocode zur Ausgabe eines bestimmten JSON-Formats
Das gewünschte JSON-Format kann mit Hilfe eines Pseudocodes ähnlich der TypeScript-Typdefinition eindeutig beschrieben werden:
Please split the sentences into short segments, no more than 1 line (less than 80 characters, ~10 English words) each.
Please keep each segment meaningful, e.g. split from punctuations, "and", "that", "where", "what", "when", "who", "which" or "or" etc if possible, but keep those punctuations or words for splitting.
Do not add or remove any words or punctuation marks.
Input is an array of strings.
Output should be a valid json array of objects, each object contains a sentence and its segments.
Array<{
sentence: string;
segments: string[]
}>
Organisieren von Untertitel-Skripten mit Pseudocode
Die Aufgabe, untertitelte Texte zusammenzustellen, ist relativ komplex. Wenn man sich vorstellt, ein Programm zu schreiben, um diese Aufgabe zu erfüllen, kann es viele Schritte geben, wie z. B. das Extrahieren von Kapiteln, dann das Extrahieren von Sprechern und schließlich das Zusammenstellen von Dialogen nach Kapiteln und Sprechern. Mit Hilfe von Pseudocode können wir diese Aufgabe in mehrere Teilaufgaben zerlegen, für die es nicht einmal notwendig ist, speziellen Code zu schreiben, sondern nur die Ausführungslogik der Teilaufgaben klar zu beschreiben. Dann führen wir diese Teilaufgaben Schritt für Schritt aus und integrieren schließlich die Ergebnisausgabe.
Wir können einige Variablen zum Speichern verwenden, wie z. B. subjectundspeakersundchaptersundparagraphs usw.
Bei der Ausgabe können wir auch For-Schleifen verwenden, um durch Kapitel und Absätze zu iterieren, und If-else-Anweisungen, um festzustellen, ob wir den Namen des Sprechers ausgeben müssen.
Ihre Aufgabe ist es, Videotranskripte neu zu organisieren, damit sie lesbar sind, und Sprecher für Dialoge mit mehreren Personen zu erkennen. Hier sind die Pseudocodes, wie man es macht Hier sind die Pseudo-Codes, wie man es macht
def extract_subject(transcript):
# Find the subject in the transcript and return it as a string.
def extract_chapters(transcript):
# Find the chapters in the transcript and return them as a list of strings.
def extract_speakers(transcript):
# Find the speakers in the transcript and return them as a list of strings.
def find_paragraphs_and_speakers_in_chapter(chapter):
# Find the paragraphs and speakers in a chapter and return them as a list of tuples.
# Each tuple contains the speaker and their paragraphs.
def format_transcript(transcript):
# extract the subject, speakers, chapters and print them
subject = extract_subject(transcript)
print("Subject:", subject)
speakers = extract_speakers(transcript)
print("Speakers:", speakers)
chapters = extract_chapters(transcript)
print("Chapters:", chapters)
# format the transcript
formatted_transcript = f"# {subject}\n\n"
for chapter in chapters:
formatted_transcript += f"## {chapter}\n\n"
paragraphs_and_speakers = find_paragraphs_and_speakers_in_chapter(chapter)
for speaker, paragraphs in paragraphs_and_speakers:
# if there are multiple speakers, print the speaker's name before each paragraph
if speakers.size() > 1:
formatted_transcript += f"{speaker}:"
formatted_transcript += f"{speaker}:"
for paragraph in paragraphs:
formatted_transcript += f" {paragraph}\n\n"
formatted_transcript += "\n\n"
return formatted_transcript
print(format_transcript($user_input))
Mal sehen, wie es sich entwickelt:
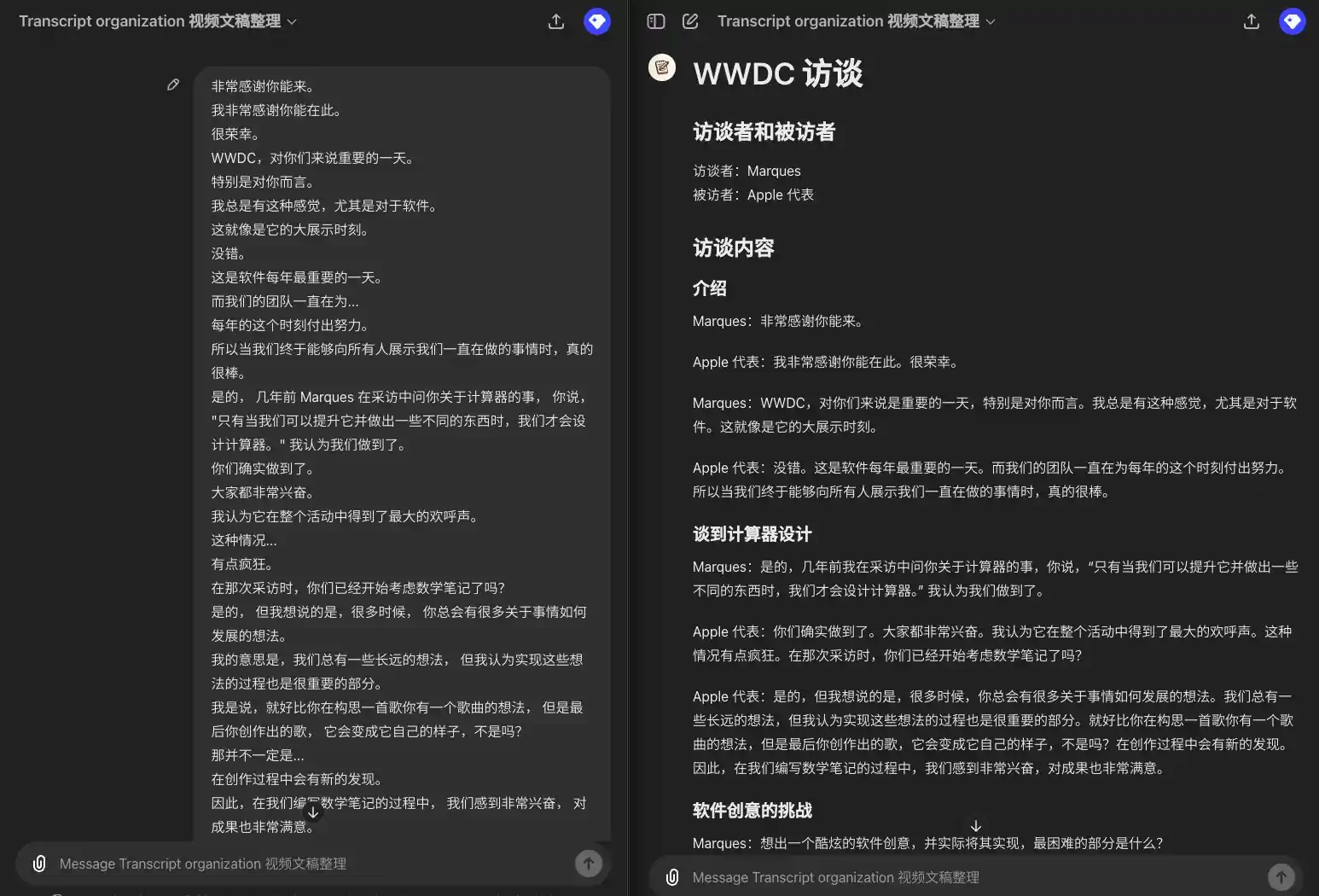
Zusammenstellung von WWDC-Zugangsprotokollen
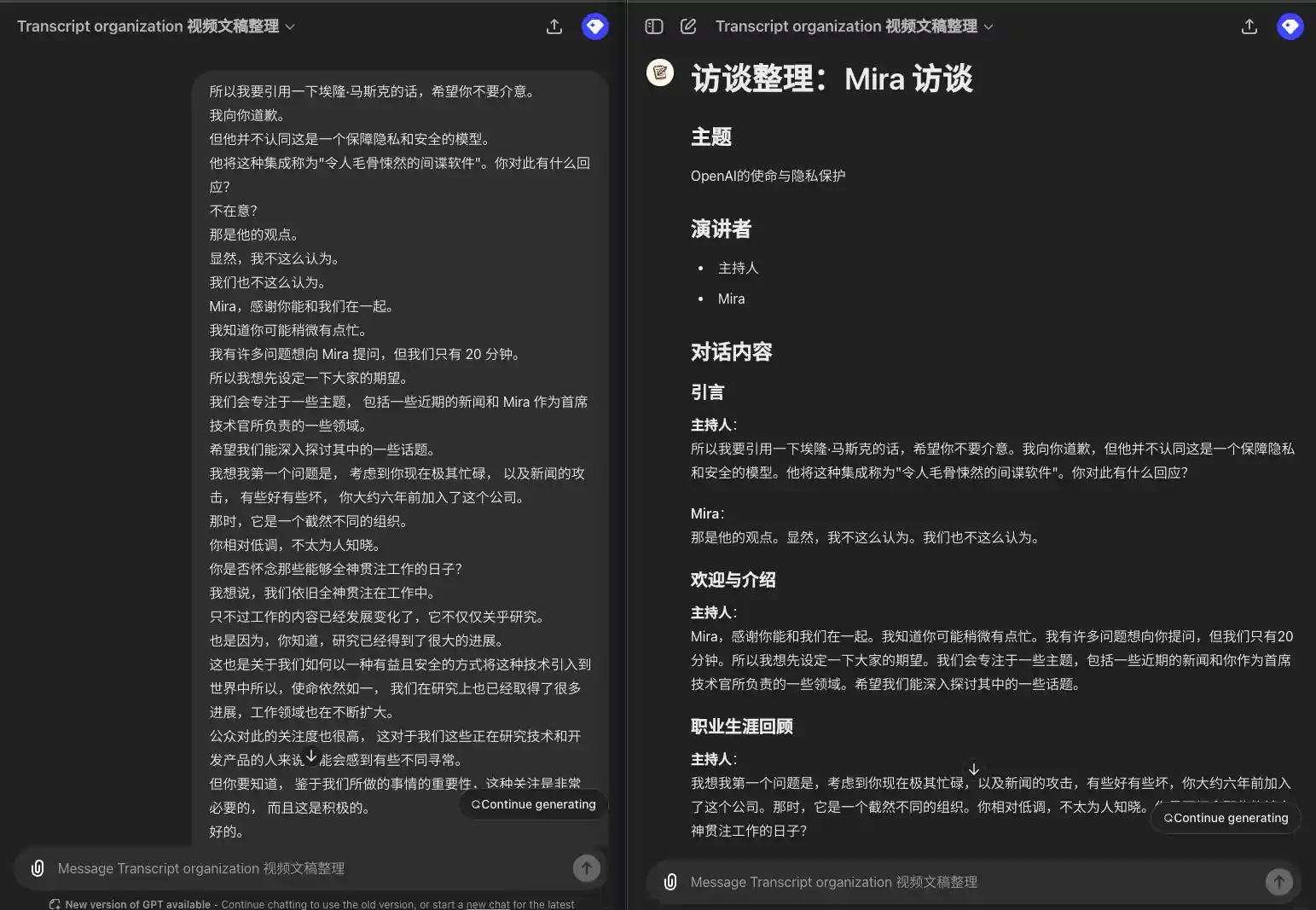
Mehrere Redner, Show Redner
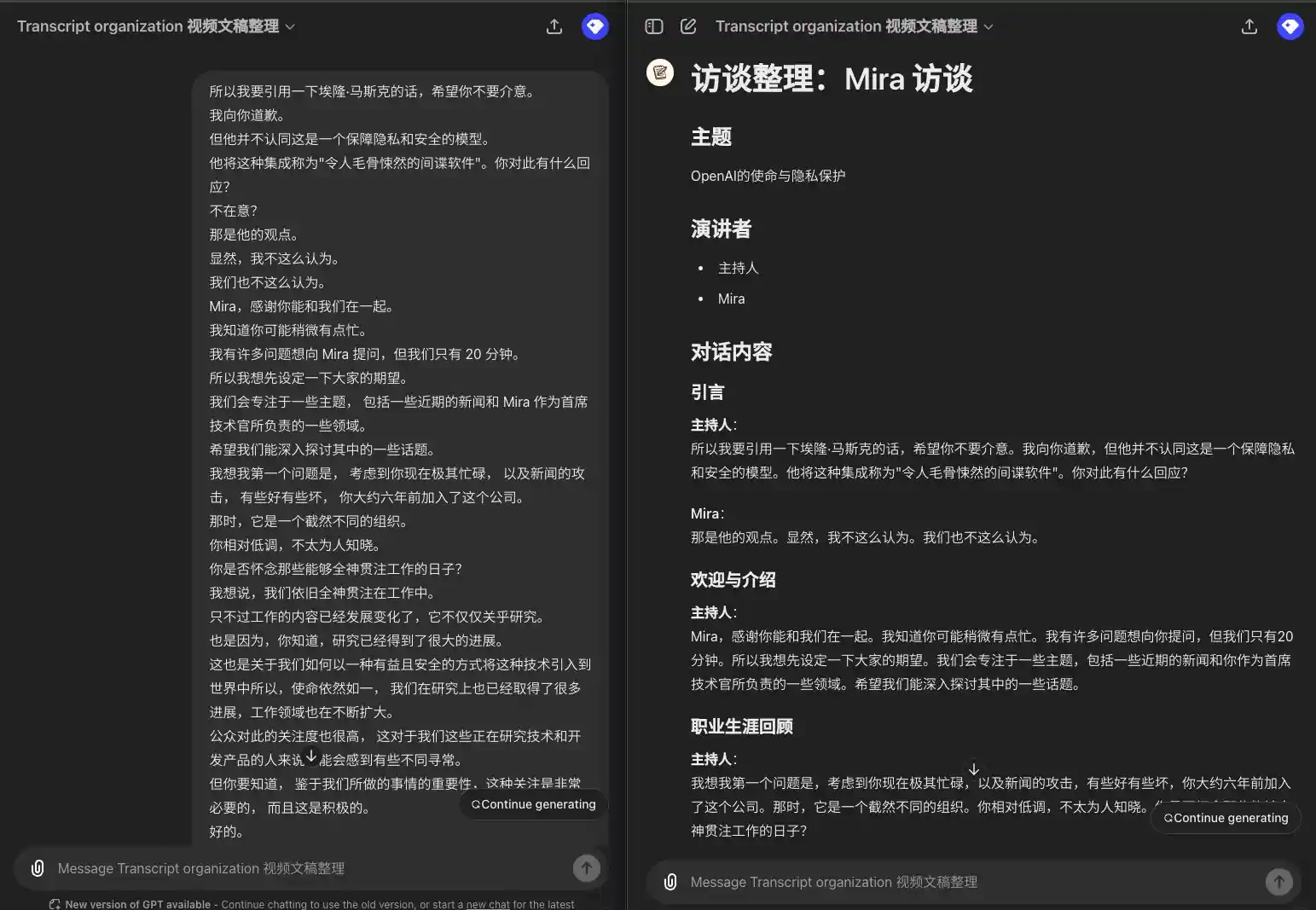
1 Lautsprecher, kein Lautsprecher abgebildet
Sie können auch einfach das GPT verwenden, das ich mit dieser Eingabeaufforderung erstellt habe:Abschriftorganisation GPT
ChatGPT zeichnen mehrere Bilder auf einmal mit Pseudo-Code
Kürzlich habe ich auch eine sehr interessante Verwendung des Begriffs von einem taiwanesischen Netizen, Sensei Yoon Sang-chi, erfahren.ChatGPT kann mit Pseudocode mehrere Bilder auf einmal zeichnen.
Wenn Sie nun Folgendes machen wollen ChatGPT Wenn Sie mehr als ein Bild auf einmal generieren möchten, können Sie Pseudocode verwenden, um die Aufgabe der Generierung mehrerer Bilder in mehrere Teilaufgaben aufzuteilen und dann mehrere Teilaufgaben auf einmal auszuführen und schließlich die Ergebnisausgabe zu integrieren.
下面是一段画图的伪代码,请按照伪代码的逻辑,用DALL-E画图:
images_prompts = [
{
style: "Kawaii",
prompt: "Draw a cute dog",
aspectRatio: "Wide"
},
{
style: "Realistic",
prompt: "Draw a realistic dog",
aspectRatio: "Square"
}
]
images_prompts.forEach((image_prompt) =>{
print("Generating image with style: " + image_prompt.style + " and prompt: " + image_prompt.prompt + " and aspect ratio: " + image_prompt.aspectRatio)
image_generation(image_prompt.style, image_prompt.prompt, image_prompt.aspectRatio);
})

Zusammenfassungen
Anhand des obigen Beispiels können wir sehen, dass wir mit Hilfe von Pseudocode das Ausgabeergebnis des LLM genauer kontrollieren und seine Ausführungslogik definieren können, anstatt uns nur auf die Beschreibung in natürlicher Sprache zu beschränken. Wenn wir auf komplexe Aufgaben oder Aufgaben mit mehreren Zweigen stoßen, bei denen jeder Zweig mehrere Teilaufgaben ausführen muss und die Teilaufgaben miteinander verbunden sind, dann wird die Verwendung von Pseudocode zur Beschreibung der Eingabeaufforderung klarer und genauer sein.
Wenn wir einen Prompt schreiben, denken wir daran, dass ein Prompt im Wesentlichen eine in natürlicher Sprache beschriebene Steueranweisung an den LLM ist, die es dem LLM ermöglicht, zu verstehen, was wir wollen, und dann die Eingaben in die von uns erwarteten Ausgaben zu verwandeln. Was die Form der Beschreibung der Eingabeaufforderung betrifft, so kann sie in vielen Formen flexibel sein, wie z.B. few-shot, CoT, Pseudocode, etc.
Weitere Beispiele:
Generierung von "Pseudocode"-Meta-Prompts zur präzisen Steuerung der Ausgabeformatierung
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...