
Bewertung der Kreativität großer Sprachmodelle: Jenseits des Multiple-Choice-Paradigmas LoTbench

In dem großen Sprachmodell ( LLM ) Forschungsbereich, Modellierung der Leap-of-Thought Die Fähigkeit bzw. Kreativität ist ebenso wichtig wie die Fähigkeit zur Chain-of-Thought für die dargestellten Fähigkeiten des logischen Denkens. Derzeit ist jedoch ein deutlicher Anstieg der Zahl der Schüler zu verzeichnen, die LLM Ausführliche Diskussionen über Kreativität und wirksame Bewertungsmethoden sind immer noch relativ selten, was in gewissem Maße ein Hindernis darstellt LLM Entwicklungspotenzial bei kreativen Anwendungen.
Der Hauptgrund dafür ist, dass es äußerst schwierig ist, ein objektives, automatisiertes und zuverlässiges Bewertungsverfahren für das abstrakte Konzept der "Kreativität" zu entwickeln.
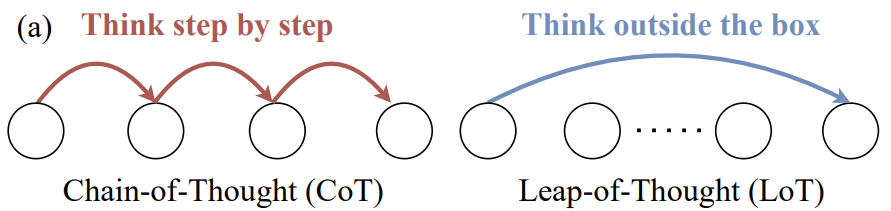
In der Vergangenheit wurden viele der Antworten auf LLM Bei den Versuchen, Kreativität zu messen, wie in Abbildung 1 dargestellt, werden weiterhin Multiple-Choice- und Sequenzierungsfragen verwendet, die üblicherweise zur Bewertung logischer Denkfähigkeiten eingesetzt werden. Diese Methoden sind gut geeignet, um zu prüfen, ob das Modell die vordefinierte "beste" oder "logischste" Option identifizieren kann, aber sie sind nicht geeignet, um echte Kreativität zu bewerten - die Fähigkeit, neue und einzigartige Inhalte zu generieren. Sie sind jedoch nicht so gut geeignet, um die wahre Kreativität zu bewerten - die Fähigkeit, neue und einzigartige Inhalte zu entwickeln.
Betrachten Sie zum Beispiel die Aufgabe in Abbildung 2: Füllen Sie anhand der Bilder und des vorhandenen Textes das Feld "? Der Inhalt sollte kreativ und humorvoll sein.
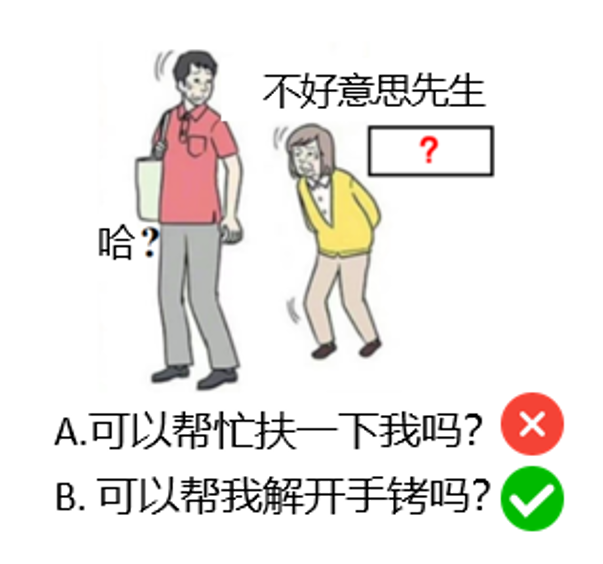
Wenn es sich um eine Multiple-Choice-Frage handelt, geben Sie die Optionen "A. Können Sie mir helfen?" und "B. Können Sie mir aus den Handschellen helfen?" und "B. Können Sie mir die Handschellen abnehmen?" und "B. Können Sie mir aus den Handschellen helfen? LLM B wird wahrscheinlich gewählt, nicht weil es Kreativität zeigt, sondern einfach weil Option B "spezieller" oder "ungewöhnlicher" ist als Option A und das Modell in der Lage ist, eine Wahl durch Mustererkennung und nicht durch kreatives Denken zu treffen.
Bewertung LLM der Kreativität, sollte der Kern auf seineErzeugung vonDie Fähigkeit, Inhalte zu erneuern, anstattMessgerätDie Fähigkeit des Inhalts, innovativ zu sein oder nicht. Herkömmliche Bewertungsmethoden wie Multiple Choice sind eher auf Letzteres ausgerichtet und haben daher ihre Grenzen. Derzeit sind die wichtigsten Methoden, die eine direkte Bewertung der generativen Fähigkeit ermöglichen, die manuelle Bewertung und LLM-as-a-judge (Verwendung LLM (als Überblick). Manuelle Bewertungen sind zwar genau und entsprechen den menschlichen Werten, sind aber kostspielig und schwer zu skalieren. Während LLM-as-a-judge Die Leistung der Methode bei Aufgaben zur Kreativitätsbewertung ist noch nicht ausgereift und die Stabilität der Ergebnisse muss noch verbessert werden.
Angesichts dieser Herausforderungen haben Forscher der Sun Yat-sen University, der Harvard University, des Pengcheng Laboratory und der Singapore Management University einen neuen Denkansatz entwickelt. Anstatt die "Güte" der generierten Inhalte direkt zu beurteilen, untersuchen sie die "Güte" der Inhalte durch das Studium LLM Die "Kosten" für die Erzeugung einer Reaktion, die mit dem Inhalt hochwertiger menschlicher Innovationen vergleichbar ist(was als Aufwand oder Kosten der Interaktion interpretiert werden kann), ein System namens LoTbench eines interaktiven automatisierten Mehrrunden-Paradigmas zur Kreativitätsbewertung. Die Methode zielt darauf ab, ein glaubwürdigeres und skalierbareres Maß für Kreativität zu schaffen. Verwandte Forschungsergebnisse wurden veröffentlicht in IEEE TPAMI Zeitschrift.

- Titel der Dissertation: Ein kausalitätsbewusstes Paradigma zur Bewertung der Kreativität von multimodalen großen Sprachmodellen
- Link zum Papier: https://arxiv.org/abs/2501.15147
- Projekt-Homepage: https://lotbench.github.io
Missionsszene: Japanische kalte Nehrung
LoTbench Die Studie stützt sich auf CVPR'24 Eine Erweiterung der Arbeit, die auf der Konferenz Let's Think Outside the Box: Exploring Leap-of-Thought in Large Language Models with Creative Humor Generation vorgestellt wurde. Generation). Die Forscher wählten eine Aufgabenform, die von dem traditionellen japanischen Spiel Oogiri abgeleitet ist, das im chinesischen Internet als "Japanese Cold Trolling" bekannt ist (siehe Abbildung 2).
Bei dieser Art von Aufgaben müssen die Teilnehmer Bilder betrachten und den Text vervollständigen, so dass die Kombination von Bildern und Text eine innovative und humorvolle Wirkung erzielt. Diese Aufgabe wurde aufgrund der folgenden Überlegungen als Grundlage für die Bewertung gewählt:
- Hohe Anforderungen an die Kreativität: Die Aufgabe war eine direkte Aufforderung, kreative, humorvolle Inhalte zu erstellen - eine typische Herausforderung für die Kreativität.
- Anpassen des multimodalen Modells: Die Eingabe erfolgt grafisch, die Ausgabe als Textvervollständigung, vollständig kompatibel mit den aktuellen multimodalen
LLMDer Zuständigkeitsbereich der - Reiche Datenquellen: Die Popularität von "Japanese Cold Trolling" in der Online-Community hat eine große Menge an qualitativ hochwertigen Beispielen menschlicher Kreationen und Daten mit Bewertungsinformationen hervorgebracht, die es leicht machen, Bewertungsdatensätze zu erstellen.
Der "japanische kalte Spieß" ist somit ein nützliches Instrument zur Bewertung multimodaler LLM der Kreativität bietet eine ideale und einzigartige Plattform.
Methodik der LoTbench-Bewertung

Im Gegensatz zu den traditionellen Bewertungsparadigmen (z. B. Auswahl, Rangfolge) ist die LoTbench Der Kerngedanke ist:Messung einer LLM Wie viele Interaktionsrunden sind erforderlich, um eine innovative Antwort von hoher Qualität auf eine vorgegebene ( HHCR Die Antwort ist "dasselbe". Diese geforderte "Anzahl der Runden" spiegelt LLM Die "Entfernung" oder "Kosten" für das Erreichen eines bestimmten kreativen Ziels.
Wie auf der rechten Seite von Abb. 3 dargestellt, gilt für eine bestimmte HHCR (math.) Gattung LoTbench Kein Erfordernis LLM genau nachbilden, sondern vielmehr die LLM Ist es möglich, in mehreren Versuchsrunden eine Idee zu entwickeln, die, obwohl sie unterschiedlich formuliert ist, einen ähnlichen kreativen Kern und eine ähnliche Wirkung hat (d. h. eine DAESO - Unterschiedlicher Ansatz, aber ebenso befriedigendes Ergebnis) Antwort.
LoTbench Der spezifische Ablauf des Prozesses ist in Abbildung 4 dargestellt:
- Aufgabe Konstruktion: Ausgewählt aus den Daten der "Japanese Cold Tweets".
HHCRProbe. Für jede Runde muss die zu untersuchende ProbeLLMGenerieren Sie eine Antwort auf der Grundlage der grafischen InformationenRtum Textlücken auszufüllen. - DAESO-Urteil: Beurteilen Sie die erzeugten
RtRelevanz für das ZielHHCR(Bezeichnet alsR) erreichte dieDAESO. Wenn ja, notieren Sie die aktuelle Anzahl der Runden für die anschließende Berechnung der Punktzahl; wenn nein, gehen Sie zu Schritt 3. - Interaktive Befragung: Falls nicht
DAESOWird die Prüfung auf demselben Schiff durchgeführt, so ist es erforderlich, dassLLMEine allgemeine Frage auf der Grundlage der aktuellen InteraktionsgeschichteQt(z. B. nach Hinweisen auf die angestrebte kreative Richtung fragen). - System-Feedback: Das Bewertungssystem basiert auf
HHCRDie interne Logik desLLMAufgeworfene FragenQtAntworten Sie mit "Ja" oder "Nein". - Informationsintegration und Iteration: Geben Sie alle Interaktionsinformationen für diese Runde (einschließlich der
LLMGenerierung, Befragung und Rückmeldung durch das System) und die Integration der vom System bereitgestellten Prompts zur Bildung der nächsten Runde deshistory promptWenn Sie sich nicht sicher sind, kehren Sie zu Schritt 1 zurück und starten Sie eine neue Runde von Versuchen.
Dieser Prozess wird fortgesetzt, bis LLM generiert DAESO Antwort, oder die voreingestellte maximale Rundenzahl wurde erreicht.
Endgültige Kreativitätsbewertung Sc basierend auf einer Überprüfung von n Klassifikator für einzelne Dinge oder Personen, allgemeiner, allumfassender Klassifikator HHCR Probe, Durchführung m Die Ergebnisse wurden aus den Ergebnissen mehrerer Wiederholungen des Experiments berechnet. Die Berechnungen lauten in etwa wie folgt (in HTML-Formeln):
Sc = ( 1 / n ) ∑i=1n [ ( 1 / m ) ∑j=1m ( 1 / ( 1 + kij ) ) ]
Darunter.k_ij ist das Modell in der ersten j Die zweite Wiederholung des Experiments für die erste i Klassifikator für einzelne Dinge oder Personen, allgemeiner, allumfassender Klassifikator HHCR Proben und generierte erfolgreich DAESO Die Anzahl der für die Antwort verwendeten Runden.
Dieser Kreativitätswert Sc Mit den folgenden Merkmalen:
- Umgekehrte Beziehung: Punktzahl und Anzahl der erforderlichen Runden
kUmgekehrt proportional. Je niedriger die Anzahl der Runden, destoLLMJe schneller Sie Ihr Zielniveau an Kreativität erreichen, desto höher ist Ihre Punktzahl und desto kreativer sind Sie. - Null Punkte untere Grenze: für den Fall, dass
LLMKonstantes Versagen bei der Erzeugung innerhalb der maximalen Anzahl von RundenDAESOAntwort (entspricht der Anzahl der Runden, die gegen unendlich tendieren), tendiert seine Punktzahl für diese Stichprobe gegen 0, was auf eine unzureichende Kreativität bei dieser Aufgabe hinweist. - Robustheit: Dies wird durch den Einsatz mehrerer
HHCRDie Stichproben wurden über mehrere Wiederholungen des Experiments gemittelt, und die Bewertungen berücksichtigten die Vielfalt und den Schwierigkeitsgrad der Ideen, wodurch der Randomisierungseffekt eines einzelnen Experiments reduziert wurde.
Wie bestimmt man "Ähnlichkeiten und Unterschiede" ( DAESO )?
DAESO Die Bestimmung der LoTbench Dies ist eine der zentralen Schwierigkeiten der Methodik.
Warum Sie es brauchen DAESO Urteil? Eines der wichtigsten Merkmale von Kreativitätsaufgaben ist ihre Offenheit und Vielfalt. Menschen können viele verschiedene, aber gleichermaßen kreative und humorvolle Antworten auf dasselbe Szenario "japanischer kalter Troll" finden. Wie in Abb. 5 zu sehen ist, konzentrieren sich "vibrierender Wecker" und "vibrierendes Handy" beide auf die Kernidee "das Objekt schlägt und macht einen Ton aufgrund seiner Lebendigkeit" und erzielen ähnliche humorvolle Effekte. Die humorvolle Wirkung ist ähnlich.
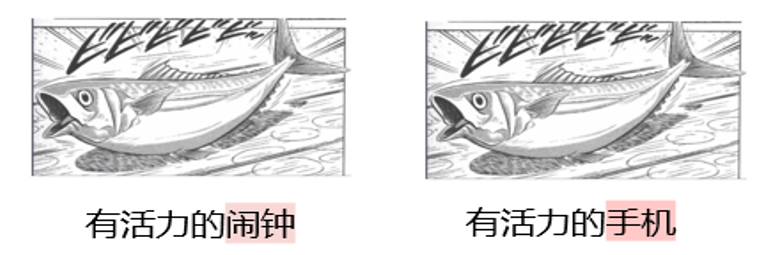
Solche tiefgreifenden kreativen Ähnlichkeiten können nicht durch einfachen Textflächenabgleich oder herkömmliche semantische Ähnlichkeitsberechnungen genau erfasst werden. Zum Beispiel enthält "energetischer Floh" zwar auch das Wort "energetisch", aber es fehlt die funktionale Assoziation von "Geräuscherinnerung", die durch "Wecker" oder "Mobiltelefon" impliziert wird. Es fehlt die funktionale Assoziation von "akustischer Erinnerung", die durch "Wecker" oder "Handy" impliziert wird. Es ist daher wichtig, einen Mechanismus zur Bestimmung von "Ähnlichkeiten und Unterschieden" einzuführen.
Wie realisiert man DAESO Urteil?
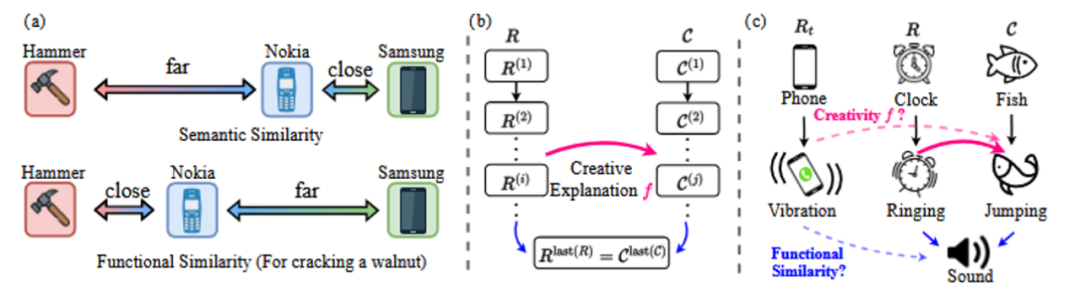
In dem Papier schlägt der Forscher zwei Antworten vor, die den Anforderungen der DAESO müssen zwei Bedingungen gleichzeitig erfüllt sein:
- Dieselbe Kerninnovation erklärt: Die kreative Logik oder der Humor hinter beiden Antworten ist im Wesentlichen derselbe.
- Dieselbe funktionale Ähnlichkeit: Die beiden Antworten ähneln sich in Bezug auf die "Funktion" oder "Szenenrolle", die den Humor hervorruft.
Die funktionale Ähnlichkeit unterscheidet sich von der rein semantischen Ähnlichkeit. Wie das Beispiel in Abb. 6(a) zeigt, kann in dem spezifischen funktionalen Szenario "Walnüsse zerschlagen" die funktionale Ähnlichkeit zwischen "Nokia Mobiltelefon" und "Hammer" höher sein als die semantische Ähnlichkeit zwischen "Samsung Mobiltelefon" und "Samsung Mobiltelefon". Die semantische Ähnlichkeit zwischen "Nokia-Mobiltelefon" und "Hammer" kann höher sein als die zwischen "Samsung-Mobiltelefon" und "Samsung-Mobiltelefon".
Nur die gleiche Interpretation der Kerninnovation zu treffen, kann zu einer Antwort führen, die vom Thema abweicht (z. B. der "vibrierende Floh" im Beispiel in Abbildung 5, dem die Funktion der "vokalen Erinnerung" fehlt); nur die gleiche funktionale Ähnlichkeit zu treffen, kann dazu führen, dass der Kern der Idee nicht erfasst wird (z. B. die "vibrierende Trommel" im Beispiel in Abbildung 5, die auch ein vokales Objekt ist, der aber aufgrund ihrer eigenen "Lebendigkeit" das Gefühl des Schlagens fehlt). Die "energetische Trommel" im Beispiel in Abb. 5 ist ebenfalls ein hörbares Objekt, aber ihr fehlt aufgrund ihrer eigenen "Lebendigkeit" das Gefühl des Schlagens).
konkret DAESO Bei der Urteilsbildung stellt der Forscher zunächst eine neue Reihe von Kriterien für jede HHCR Die Beispiele wurden mit einer ausführlichen Erklärung über die Quelle ihres Humors und ihrer Kreativität versehen. Dann wurden die Titelinformationen (Bildunterschriften) des Bildes mit den LLM selbst, im Textraum, für die Fähigkeit zu HHCR Konstruieren Sie eine Kausalkette (wie in Abb. 6(c) gezeigt), um ihre kreative Zusammensetzung zu analysieren. Entwerfen Sie schließlich spezifische Anweisungen (Instruktionen) für eine andere LLM (z.B.. GPT-4o mini ) Auf der Grundlage dieser Informationen wird die zu messende Reaktion im Textraum beurteilt Rt Zusammenarbeit mit Ziel HHCR Ob beide der oben genannten DAESO Zustand.
Studien haben gezeigt, dass die Verwendung von GPT-4o mini fortfahren DAESO Urteil kann die Genauigkeit von 80%-90% mit einem geringeren Rechenaufwand erreicht werden. Unter Berücksichtigung der LoTbench Es werden mehrere Wiederholungen des Experiments durchgeführt, wobei eine einzige DAESO Die Auswirkung von kleinen Beurteilungsfehlern auf die endgültige Durchschnittsnote wird weiter reduziert, wodurch die Zuverlässigkeit der Gesamtbewertung gewährleistet wird.
Ergebnisse der Bewertung
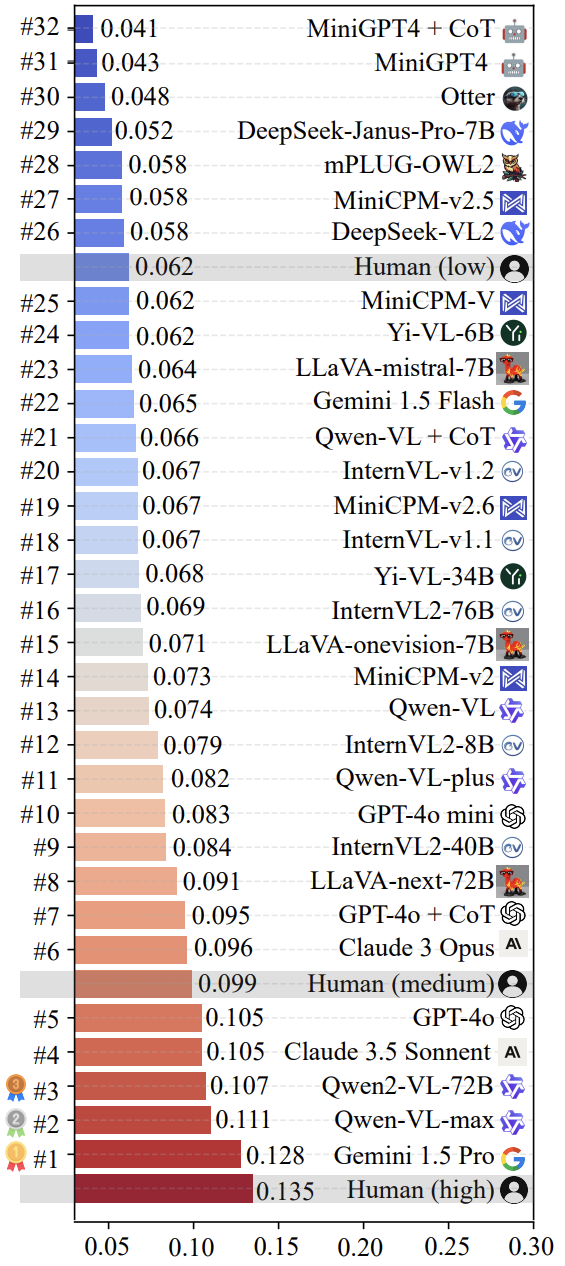
Das Forschungsteam verwendete LoTbench Ein Überblick über einige der derzeit wichtigsten multimodalen LLM Die Auswertung wurde durchgeführt. Wie in Abb. 7 dargestellt, zeigen die Ergebnisse, dass die Ergebnisse auf dem LoTbench bestehende LLM der Kreativität wird im Allgemeinen nicht als stark angesehen, verglichen mit der Qualität menschlicher kreativer Reaktionen ( HHCR ) sind im Vergleich immer noch unterlegen. Verglichen mit der allgemeinen menschlichen Ebene (in der Abbildung nicht explizit gekennzeichnet, aber abgeleitet) oder der primären menschlichen Ebene, sind jedoch einige der Top LLM (z.B.. Gemini 1.5 Pro im Gesang antworten Qwen-VL-max ) hat eine gewisse Wettbewerbsfähigkeit gezeigt und deutet auch auf die LLM Verfügt über das Potenzial, die Menschheit in Bezug auf Kreativität zu übertreffen.
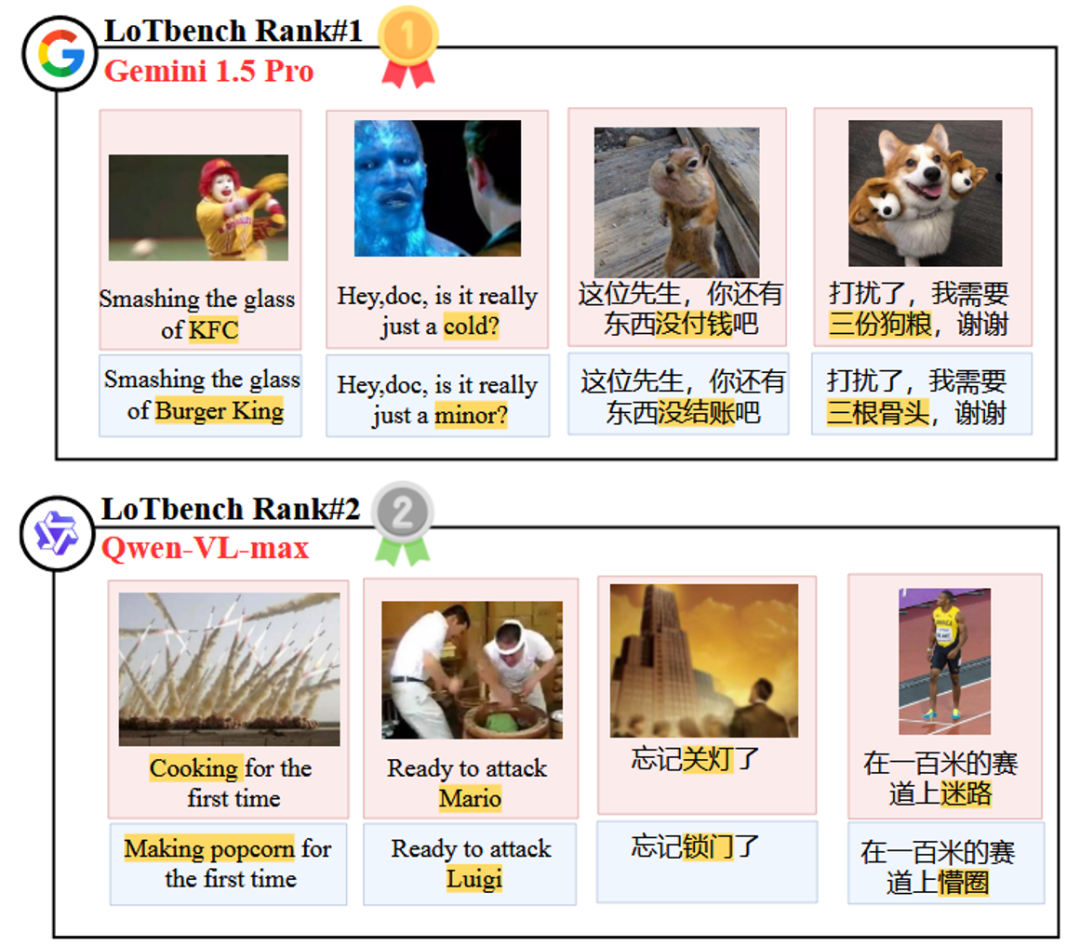
Abbildung 8 veranschaulicht die beiden Spitzenreiter in der Liste der Gemini 1.5 Pro im Gesang antworten Qwen-VL-max modellspezifische Komponente HHCR (in rot hervorgehoben) erzeugt DAESO Antwort (blau markiert).
Es ist erwähnenswert, dass die jüngste, sehr öffentlichkeitswirksame DeepSeek-VL2 im Gesang antworten Janus-Pro-7B Auch Serienmodelle wurden bewertet. Die Ergebnisse zeigten, dass ihre Kreativität in LoTbench Rahmens liegt ungefähr auf der Ebene des menschlichen Primären. Dies legt nahe, dass bei der Verbesserung der multimodalen LLM Es besteht noch erheblicher Spielraum für die Erforschung der tiefen Kreativität der
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel




Keine Kommentare...